GitHub开源:支持100多种语言的OCR文字识别

【摘要】 之前为给位朋友分享过:GitHub开源:17M超轻量级中文OCR模型、支持NCNN推理,该项目仅仅支持中文OCR识别,本篇博文将分享支持100多种语言的OCR文字识别项目:Tesseract OCR。
Tesseract是一款由HP实验室开发由Google维护的开源OCR(Optical Character Recognition , 光学字符识别)引擎。Tesseract...
之前为给位朋友分享过:GitHub开源:17M超轻量级中文OCR模型、支持NCNN推理,该项目仅仅支持中文OCR识别,本篇博文将分享支持100多种语言的OCR文字识别项目:Tesseract OCR。
Tesseract是一款由HP实验室开发由Google维护的开源OCR(Optical Character Recognition , 光学字符识别)引擎。Tesseract 支持 unicode(UTF-8),可以“开箱即用” 识别100多种语言。Tesseract 架构如下所示:
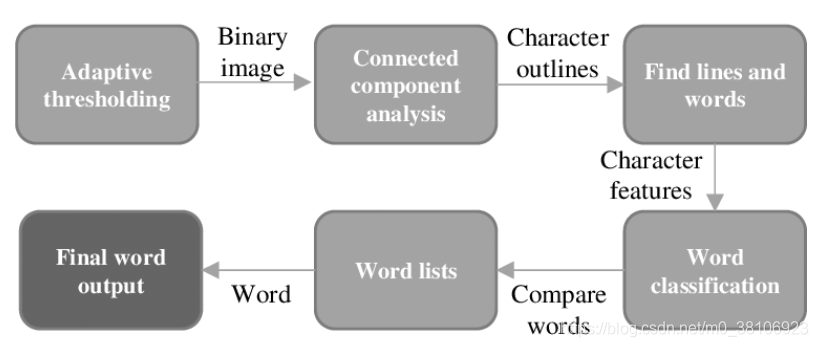
使用Tesseract项目识别中文,效果如下所示:

使用Tesseract项目识别英文,效果如下所示:

项目地址请参见:Tesseract OCR
文章来源: handsome-man.blog.csdn.net,作者:不脱发的程序猿,版权归原作者所有,如需转载,请联系作者。
原文链接:handsome-man.blog.csdn.net/article/details/108920159

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)