《百问机器学习》第一问:为什么要对数值类型的特征做归一化?

【摘要】 目录
0. Normalization简单解释
1. 常用的归一化方法
(1)线性函数归一化(Min-Max Scaling)
(2)零均值归一化(Z-Score Normalization)
2. 为什么说数据归一化不是万能的?有哪些 适用哪些不适用?
0. Normalization简单解释
为了消除数据特征之间的量纲的影响,所以需要进行归一化的处理,...
目录
(2)零均值归一化(Z-Score Normalization)
2. 为什么说数据归一化不是万能的?有哪些 适用哪些不适用?
0. Normalization简单解释
为了消除数据特征之间的量纲的影响,所以需要进行归一化的处理,使得可比性
我联想了一下现实生活中比较常见的归一化:
四六级成绩,托福成绩,雅思成绩等等, 这其实都是归一化了,不管什么时候考的,都能够对比
1. 常用的归一化方法
(1)线性函数归一化(Min-Max Scaling)
对原始数据进行线性变换,使其结果映射到[0,1]之间,实现对原始数据的等比缩放。
归一化公式

(2)零均值归一化(Z-Score Normalization)
将原始数据映射到均值为0、标准差为1的 分布上,归一化公式:
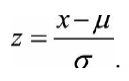
2. 为什么说数据归一化不是万能的?有哪些 适用哪些不适用?
实际应用中,通过梯度下降法求解的模型,通常需要归一化,包括线性回归、逻辑回归、支持向量机、神经网络。
但是对于决策树模型并不适用,决策树在进行节点分裂时主要依据数据集D关于特征x的信息增益比,而信息增益比与是否归一化无关,归一化不会改变样本在特征x上的 信息增益。
文章来源: kings.blog.csdn.net,作者:人工智能博士,版权归原作者所有,如需转载,请联系作者。
原文链接:kings.blog.csdn.net/article/details/96003307

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)