《百问机器学习》第四问:有哪些文本表示模型?各有什么优缺点?

目录
1. 有哪些文本表示模型?
- 词袋模型(Bag of Words)
- TF-IDF(Term Frequency-Inverse Document Frequency)
- 主题模型(Topic Model)
- 词嵌入模型(Word Embedding)
1.1 词袋模型
这是最基础的文本表示模型。
将文章看成一袋子词,并忽略每个词出现的顺序。
具体讲,将整段文本以词为单位切分开,然后每篇文章可以表示一个向量了,向量中的每一个维度代表一个单词,而该维度对应的权重梵音了这个词在原文中的重要程度。
1.1.1 TF-IDF权重计算 公式:
![]()
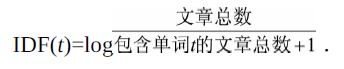
TF(t,d)表示单词t在文档d中出现的频率,IDF(t)是逆文档频率,用来衡量单词语义的重要性。
如果一个单词在非常多文章中出现,那可能是一个比较通用的词汇,对于区分 某一篇文章特殊语义贡献较小,因此权重降低。
但是将 单词一个一个划分未必正确,比如自然语言处理 natural language processing这3个词分别计算,结果就和实际语义偏离较大,于是可以将连续n个词 (n<=N)组成的词组(N-gram)作为一个 单独特征放到向量中表示,将构成N-gram模型。
同一个词有多种词性变换,却具有相似含义。实际中,会对单词进行词干抽取(Word Stemming),将不同词性的单词统一成同一词干的形式。
1.2 主题模型
主题模型用于从文本库中发现有代表性的主题,计算出每篇文章的主题分布
1.3 词嵌入与深度学习模型
词嵌入式一类将词向量化的模型统称,核心是将每个词都映射成低纬度空间(K=50~300维度)的稠密向量(Dense Vector)
K维空间每一维可以看做一个隐含的主题,只不过不想主题模型中的主题那样直观。
为什么深度学习有用?
由于词嵌入将每个词映射成一个K维的向量,如果一篇文档有N个词,就可以用一个N×K维的矩阵来表示这篇文档,但是这样的表示过于底层。在实际应用中,如果仅仅把这个矩阵作为原文本的表示特征输入到机器学习模型中,通常很难得到令人满意的结果。因此,还需要在此基础之上加工出更高层的特征。在传统的浅层机器学习模型中,一个好的特征工程往往可以带来算法效果的显著提升。而深度学习模型正好为我们提供了一种自动地进行特征工程的方式,模型中的每个隐层都可以认为对应着不同抽象层次的特征。从这个角度来讲,深度学习模型能够打败浅层模型也就顺理成章了。卷积神经网络和循环神经网络的结构在
文本表示中取得了很好的效果,主要是由于它们能够更好地对文本进行建模,抽取出一些高层的语义特征。与全连接的网络结构相比,卷积神经网络和循环神经网络一方面很好地抓住了文本的特性,另一方面又减少了网络中待学习的参数,提高了训练速度,并且降低了过拟合的风险。
文章来源: kings.blog.csdn.net,作者:人工智能博士,版权归原作者所有,如需转载,请联系作者。
原文链接:kings.blog.csdn.net/article/details/96172128

- 点赞
- 收藏
- 关注作者
评论(0)