OpenPose:实时多人2D姿态估计

原文地址:https://zhuanlan.zhihu.com/p/37526892
前言
前段时间很火的感人动画短片《Changing Batteries》讲了这样一个故事:独居的老奶奶收到儿子寄来的一个机器人,虽然鲜有语言的沟通,但是小机器人善于察言观色,不仅能在老奶奶口渴时为她端水、在老奶奶扫地时接过老奶奶的扫把,做力所能及的家务活,如果老奶奶在椅子上看电视睡着了,机器人还为她轻轻盖上毯子。有了它,老奶奶又重新感受到久违的快乐,过上了更轻松的生活。
那么,机器人是怎么察言观色的呢?

AI识别人的五重境界
AI识别人可以分成五个层次,依次为:
1.有没有人?->object detection (YOLO SSD Faster-RCNN)
2.人在哪里?->object localization & semantic segmentation(Mask-RCNN)
3.这个人是谁?->face identification(相对独立的一个领域,暂且不表)
4.这个人此刻处于什么状态?->pose estimation
5.这个人在当前一段时间里在做什么?->Sequence action recognition (水比较深,后续慢慢介绍)

五个层次由简单到复杂,4&5两个high level的视觉识别中,有一项很关键的先决技术-骨骼关键点提取,后者的检测的精度会直接影响姿态检测的准确度以及动作识别及预测的精度。下面就介绍下骨骼关键点提取及人体姿态估计。
什么是人体姿态估计?
人体姿态估计,pose estimation,就是通过将图片中已检测到的人体关键点正确的联系起来,从而估计人体姿态。
人体关键点通常对应人体上有一定自由度的关节,比如颈、肩、肘、腕、腰、膝、踝等,如下图。
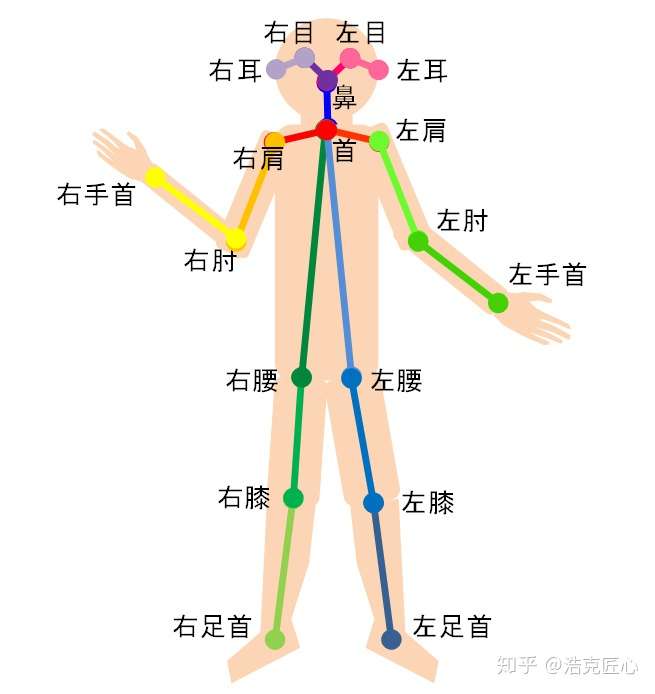
通过对人体关键点在三维空间相对位置的计算,来估计人体当前的姿态。
进一步,增加时间序列,看一段时间范围内人体关键点的位置变化,可以更加准确的检测姿态,估计目标未来时刻姿态,以及做更抽象的人体行为分析,比如判断一个人是否在打电话等等。
姿态检测的挑战:
- 每张图片中包含的人的数量是未知的。
2. 人与人之间的相互作用是非常复杂的,比如接触、遮挡等,这使得联合各个肢体,即确定一个人有哪些部分变得困难。
3. 图像中人越多,计算复杂度越大(计算量与人的数量正相关),这使得real time变得困难。
OpenPose三大亮点
OpenPose是基于卷积神经网络和监督学习并以caffe为框架写成的开源库,可以实现人的面部表情、躯干和四肢甚至手指的跟踪,不仅适用于单人也适用于多人,同时具有较好的鲁棒性。可以称是世界上第一个基于深度学习的实时多人二维姿态估计,是人机交互上的一个里程碑,为机器理解人提供了一个高质量的信息维度。
其理论基础来自Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields ,是CVPR 2017的一篇论文,作者是来自CMU感知计算实验室的曹哲(http://people.eecs.berkeley.edu/~zhecao/#top),Tomas Simon,Shih-En Wei,Yaser Sheikh 。
主要流程
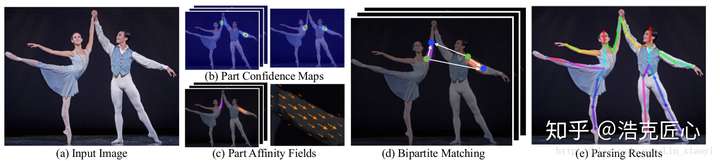
- 输入一幅图像,经过卷积网络提取特征,得到一组特征图,然后分成两个岔路,分别使用 CNN网络提取Part Confidence Maps 和 Part Affinity Fields;
- 得到这两个信息后,我们使用图论中的 Bipartite Matching(偶匹配) 求出Part Association,将同一个人的关节点连接起来,由于PAF自身的矢量性,使得生成的偶匹配很正确,最终合并为一个人的整体骨架;
- 最后基于PAFs求Multi-Person Parsing—>把Multi-person parsing问题转换成graphs问题—>Hungarian Algorithm(匈牙利算法)
(匈牙利算法是部图匹配最常见的算法,该算法的核心就是寻找增广路径,它是一种用增广路径求二分图最大匹配的算法。)
卷积网络
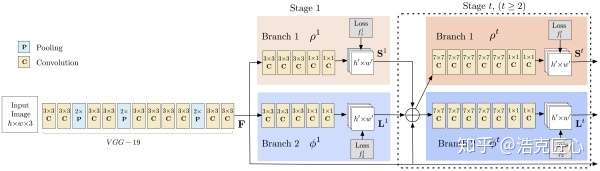
亮点1:PAF-Part Affinity Fields(本paper的核心贡献):
人体姿态检测,通常是top-down的思路,也就是先做行人检测,然后把每一个人分割出来,最后基于每一个独立个体,找出各自的手手脚脚(人体关键点)。这个办法有两个问题:
1.结果严重依赖第一步行人检测器的结果,如果人都没找到,就无从进行找手手脚脚这一步了。
2.计算时间和人数正相关,人越多越耗费时间。
OpenPose 使用了另一种思路,即bottom-up,先找出图中所有的手手脚脚,再用匹配的方法拼装成一个个人体骨架。这种办法有一个缺陷,就是没办法利用全局上下文的信息。
为了克服这个问题,本文想出了一个办法,就是PAF(Part Affinity Fields), 部分区域亲和。它负责在图像域编码着四肢位置和方向的2D矢量。同时,使用CMP(Part Detection Confidence Maps)标记每一个关键点的置信度(就是常说的“热图”)。通过两个分支,联合学习关键点位置和他们之间的联系。
同时推断这些自下而上的检测和关联的方式,利用贪婪分析算法(Greedy parsing Algorithm),能够对全局上下文进行足够的编码,获得高质量的结果,而只是消耗了一小部分计算成本。并行情况下基本达到实时,且耗时与图片中的人数无强关联。

亮点2: 高鲁棒性
这是CMU的研究成果。很多人好奇,为啥CMU的模型鲁棒性好,精度高?我觉得这主要归功于数据集规模大,质量好。
下图是CMU家的数据采集设备,一个封闭的大球,可以做到任意角度的人体数据采集。大球上面镶嵌了480 VGA cameras+31 HD cameras+10 Kinect Ⅱ Sensors+5 DLP Projectors. 并且,全部实现了硬件同步。
由于工作原因,笔者也接触过不少国内外的训练数据采集公司,但是这样的豪华配置,还是非常少见的。
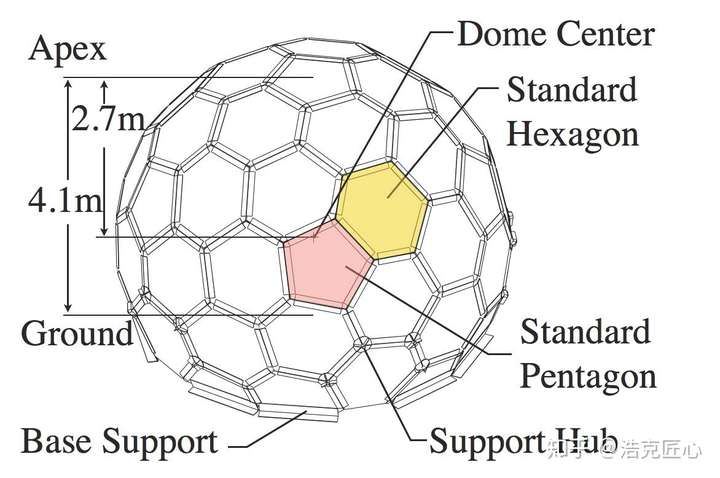
实物长这样:


海量高质量的数据,使得仅仅基于2D图像就可以实现鲁棒性很好的人体姿态检测。
这充分说明了,数据为王的时代,数据多就是硬道理。
亮点3:终于将人体、人手、人脸的landmarks三元归一
以前,人体骨骼关节点是行为分析动作识别的人做,人脸landmark提取是人脸识别或者美颜算法开发团队做,手部关节点是手势识别人机交互团队在做,属于不同的细分方向。
CMU的团队,因为前期的人体骨骼关节点识别取得了不错的成果,有了更大的目标(野心),于是把人脸人手都整合了进来,做成了一个统一的graph,效果也还可以。face alignment和pose alignment串起来了,而且根据人体头部的刚体属性及四肢的非刚体特性设计了一套基于caffe的点估计与扩散模型,并建立树状决策加速,据此再加之3D背景分割技术。
当然,如果野心再大一点点,做一个结合了表情识别和手势识别的人体行为识别方案就更了不起了,比如人在打架的时候,脸部表情通常是紧绷或者愤怒的,手部通常会攥成拳头,这样,整合脸和手的识别结果,都整体复杂行为的分析和预测会有帮助。
多人70关键点人脸估计:

多人2*21关键点手势估计:

有什么短板?
耗显存
计算量本来就很大,为了达到实时的目的,使用了高并行的策略。基于cuda加速,所以非常吃显存,基本劝退显存低于4G的机器了(GTX 980ti+)。
时间分析(仅作参考):
<基于GTX-1080 GPU>
原始图像尺寸是1080×1920, 为了适应GPU memory,resize成了 368×654;
包含是19个人的视频检测是8.8 fps;
对于9个人, parsing耗时0.58 ms, CNN耗时99.6 ms。
特殊场景下检测效果差
比如人体姿势比较诡异的时候,如下图(曾经对这个场景产生过心理阴影)

非直立向上朝向的人

其他情况,诸如图像分辨率低、运动模糊、低亮度、检测目标密集、遮挡严重、不完整目标等,效果都不是很理想。但是,这是全天下图像检测算法都会犯的错。
完整视频测试
有个日本人做过一段印度舞蹈的骨骼提取,这里我做了一段国产的:
<芳华,群舞片段>
<叶问,我要打十个片段>
有什么应用场景(脑洞时间)?
--------------------------2018.6.15更新--------------------------------
抖音尬舞机:经评论区知友提醒,活捉一个已经上线的人体姿态估计应用:
这是脑洞照进现实的时刻~~

---------------------------------------------------------------------------
3D 个人健身教练:

体育类教学(包括上面提到的武术舞蹈教学):

尤其像高尔夫这种固定位置且非常强调姿势正确的运动,很适合用姿态检测技术来辅助训练和错误姿势矫正。

3D试衣:现在也有,但是加入实时姿态检测,可以做到人动衣动的效果。

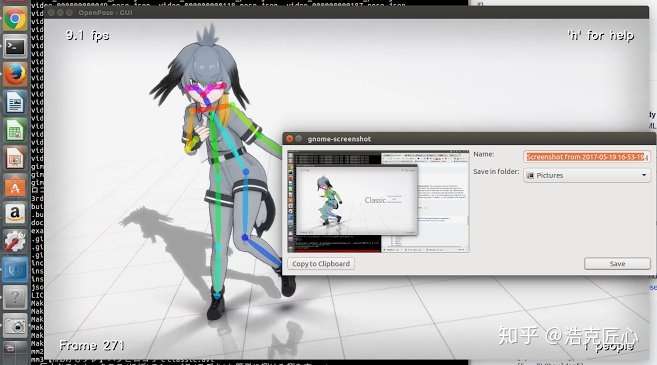
游戏人物动作设计(精度在高些,有潜力取代动作捕捉那套昂贵的设备):
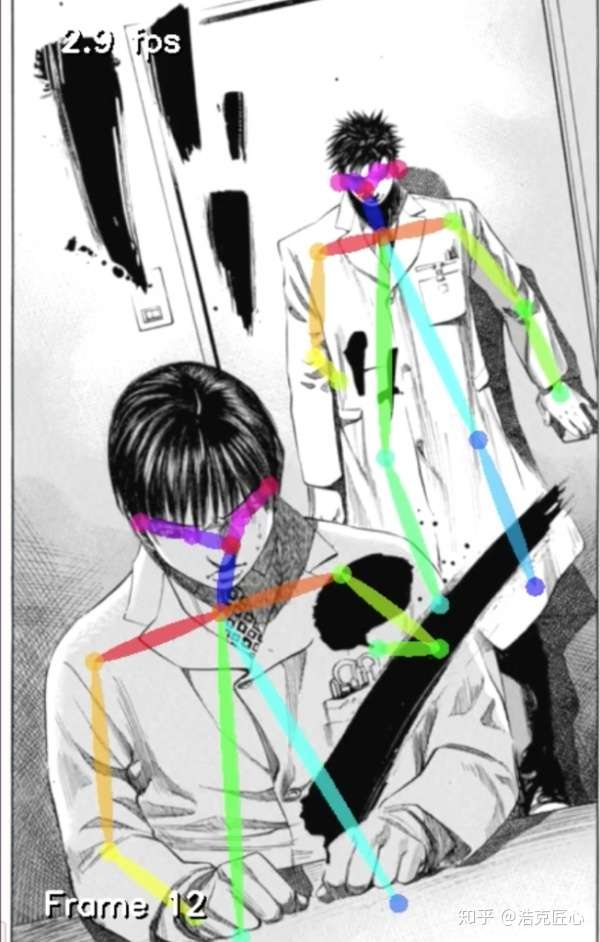
古画分析(美术学院教学辅助):

人体绘画教学(适用于初学者)
照相馆拍照姿势指南:

无意义的逗逼(抖x):

结语
效果无疑是很出众的。仅仅基于2D图像,廉价的普通摄像头,就可以实现多人的、实时的、鲁棒性很好的人体骨骼关节点提取与姿态检测。
但是问题也很明显。如果是离线检测的话,这个对终端的硬件配置是有很高要求的。一台监控设备,为了骨骼提取,配置一块几千大洋的NV独显,这产品基本被判死刑了。Intel的RealSense D400和Microsoft的kinect2等3D摄像头都可以实现实时人体骨骼提取,但是价格前者1000大洋,后者1500大洋,极具竞争力。
给创业者一点思路:如果把这套模型移植到ASIC或者FPGA上,速度和成本得到很好的平衡,会有一些机会。
机器会越来越了解我们,越来越熟悉我们的体态特征和行为方式,总有一天,人类在机器面前,如同naked,再无秘密可言。
目前看来,这是不可逆的趋势。
相关链接:
【1】论文:https://arxiv.org/pdf/1611.08050.pdf
【2】姿态检测视频制作源码:muyiguangda/caffe_rtpose
【3】开头视频:Changing Batteries 更换电池「中字」
【4】CMU训练数据集: CMU Panoptic Dataset
【4】匈牙利算法: Hungarian algorithm
文章来源: guo-pu.blog.csdn.net,作者:一颗小树x,版权归原作者所有,如需转载,请联系作者。
原文链接:guo-pu.blog.csdn.net/article/details/90656950

- 点赞
- 收藏
- 关注作者
评论(0)