【DigSci 科学数据挖掘大赛】冠军方案关键技术解析

前言
本文根据在cncc会议中演讲的PPT内容,给出了完整的技术方案,主要从赛题难点、候选集自动生成、自动特征抽取与选择、文本匹配模型构建、模型融合等方面去进行阐述。本次比赛的难点在于给定描述段落匹配的一篇论文(正样本),在没有负样本的情况下要求参赛者给出一个段落最匹配的三篇论文。参赛者需要从大规模论文库中匹配最相关的论文,涉及到语义表示、语义检索等技术难点。
赛题背景
科学研究已经成为现代社会创新的主要动力。大量科研数据的积累也让我们可以理解和预测科研发展,并能用来指导未来的研究。论文是人类最前沿知识的媒介,因此如果可以理解论文中的数据,可以极大地扩充计算机理解知识的能力和范围。
在论文中,作者经常会引用其他论文,并对被引论文做出对应描述。如果我们可以自动地理解、识别描述对应的被引论文,不仅可以加深对科研脉络的理解,还能在科研知识图谱、科研自动问答系统和自动摘要系统等领域有所进步。
赛题任务
本次比赛将提供一个论文库(约含20万篇论文),同时提供对论文的描述段落,来自论文中对同类研究的介绍。参赛选手需要为描述段落匹配三篇最相关的论文。
例子:
描述:
An efficient implementation based on BERT [1] and graph neural network (GNN) [2] is introduced.
相关论文:
[1] BERT: Pre-training of deep bidirectional transformers for language understanding.[2] Relational inductive biases, deep learning, and graph networks.
评测方案
准确率(Precision): 提交结果的准确性通过 Mean Average Precision @ 3 (MAP@3) 打分,具体公式如下:
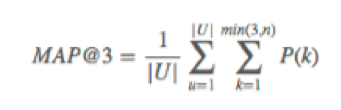
其中,|U|是需要预测的press_id总个数,P(k)是在k处的精度,n是paper个数。具体来说,如果在第一个位置预测正确,得分为1;第二个位置预测正确,得分为1/2;第三个位置预测正确,得分为1/3。
赛题分析
本赛题任务是需要为描述段落匹配三篇最相关的论文,很明显这是一个匹配的问题,实际上可以转化为是否匹配的二分类问题,在构建模型的时候模型不可能在这么大范围(20万篇论文)内去搜索查找,为此如何缩小搜索范围,构造合理的候选论文集,将问题转化为二分类问题,是模型得分的关键。
整体方案
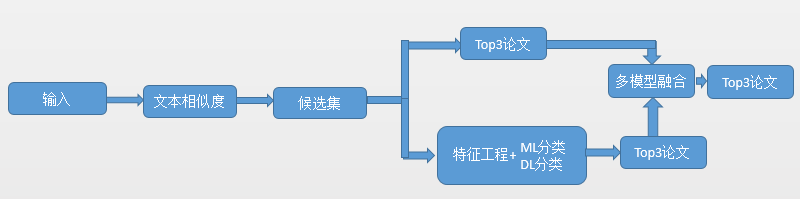
首先根据文本相似度,构造候选集,再在候选集中选出top3的论文。具体而言,利用候选集构造训练样本集,分别用特征工程+模型的方式计算出两种匹配方案的top3论文,再结合原候选集中的top3论文,对三种方式的输出结果做多模型的融合得到最终的top3论文。
候选集生成

在构造候选集方面,我们按照如下步骤进行:
在数据描述中,发现引用论文描述在[[**##**]]之前,所以我们选取描述中[[**##**]]之前的句子作为描述关键句,例如:Rat brain membrane preparation and opioid binding was performed as described previously by Loukas et al. [[**##**]]. Briefly, binding was performed in Tris-HCl buffer (10 mM, pH 7.4), in a final volume of 1.0 ml. The protein concentration was 300 μg/assay.
只选择特定的期刊,训练集匹配论文的journal描述字段都是no-content,故而只选取journal为no-content的论文。
经过1,2处理后,分别运用bm25和tfidf的方式召回前20篇论文,取并后set(考虑召回数量和正负比),得到最终的候选集,训练集正负比为:1:34,训练集召回比例(覆盖率):0.6657 。
特征抽取与选择
在特征抽取方面,我们根据文档信息抽取了如下一些特征:
l论文关键字在描述关键句、原描述出现的次数.
l描述关键句、原描述分别与论文title和摘要的BM25.
l描述关键句、原描述分别与论文title和摘要的基于TFIDF的余弦距离,欧式距离,曼哈顿距离.
l描述关键句、原描述分别与论文title和摘要的基于Word2vec词向量余弦距离,欧式距离,曼哈顿距离.
l描述关键句、原描述分别与论文title和摘要的编辑距离.
l描述关键句、原描述分别与论文title和摘要的共现词,共现词占的比例.
l描述关键句、原描述分别与论文title和摘要的 2-gram Jaccard相似系数 .
l描述关键句、原描述分别与论文title和摘要的长度.
…………………
匹配模型构建
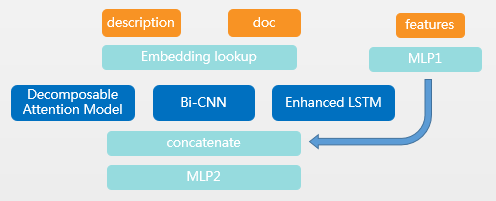
在模型构建方面我们把匹配问题转化为是否匹配的二分类问题,主要采用了传统的特征+机器学习模型以及深度学习模型两种方案,传统的机器学习模型分类方案直接采用lightgbm模型,在构建深度学习模型方案时,我们主要利用了深度学习模型中间层的输出信息,具体方法:首先将描述和文档输入进词嵌入层,然后分别接入 Decomposable Attention Model , Bi-cnn, Esim,取三个模型隐藏层输出结果与用特征工程构建的特征进行拼接,最后接入多层感知机。
模型融合
用规则的方式、lightgbm以及深度学习模型匹配的方式得到的三种结果,以lightgbm的结果为基准进行模型融合得到最终的结果。
感悟
本次比赛是在过完国庆之后来做的,由于时间比较短,许多方法还没有来得及试验,例如:目前比较热门的bert模型,运用bert模型应该会有较大的提高。比赛中运用的部分能力源自华为云NLP服务,目前我们也在把一些新的模型优化落地,实践是检验真理的唯一标准,长路漫漫,我们坚信在后续的服务中我们会越做越好。最后欢迎大家留言,相互探讨,一起学习。

- 点赞
- 收藏
- 关注作者
评论(0)