PrecisionFDA:多组学样本错标校正挑战赛

多组学联合分析是指对来自不同组学,如基因组学、转录组学、蛋白组学和代谢组学等的数据进行统一处理、比较分析,用以探究生物学问题。由于生物过程具有复杂性和整体性,多种物质共同影响生命系统的表型和性状,例如环境、基因、mRNA、调控因子、蛋白、代谢等,这些组学之间,既相互独立,又互相影响,既有很大的差别,又有相似之处。
多种多样的组学联合分析将不同层面之间信息进行整合,可从不同的组学角度共同探究生物体内潜在的调控网络机制,从而可以更深层次理解各个分子之间的调控及因果关系,更深入的认识生物进程和疾病过程中复杂性状的分子机理和遗传基础。

与传统的“大数据”机器学习问题不同,多组学的主要挑战在于其小样本、高维度的特质,即每个样本都有深层数据。Sentieon在多组学数据的联合分析应用中同样有着出色的表现。Sentieon 不断将机器学习和AI 应用到多组学分析中,以实现softPharma更广阔的视野。自2018年以来,Sentieon 参加并赢得了 PrecisionFDA的三项多组学 AI 建模挑战,展示了其解决这些问题的能力。

我们将分三期详细介绍Sentieon参加的多组学数据分析挑战赛。
- 2018-2019 Multi-omics Enabled Sample Mislabeling Correction Challenge;
- 2019-2020 Brain Cancer Predictive Modeling and Biomarker Discovery Challenge;
- 2020 COVID-19 Risk Factor Modeling Challenge.
2018-2019多组学样本错标校正挑战赛
在2018年的FDA多组学数据样本错误标记校正的挑战赛中,主办方共提供了160位病人的临床数据,记录了每个样本的临床特征(样本性别,肿瘤MSI评分),4118蛋白组表达量及17447 mRNA数据。其中以80个样本作为训练集,其余作测试集,每组数据集中包含12个错误标签。目的是通过分析不同组学数据之间的相关性,找出错误标签的数据并进行纠正。本次挑战赛的难点在于如何对缺失数据进行填充,以及在面临小样本,高维度问题时的解决方案。
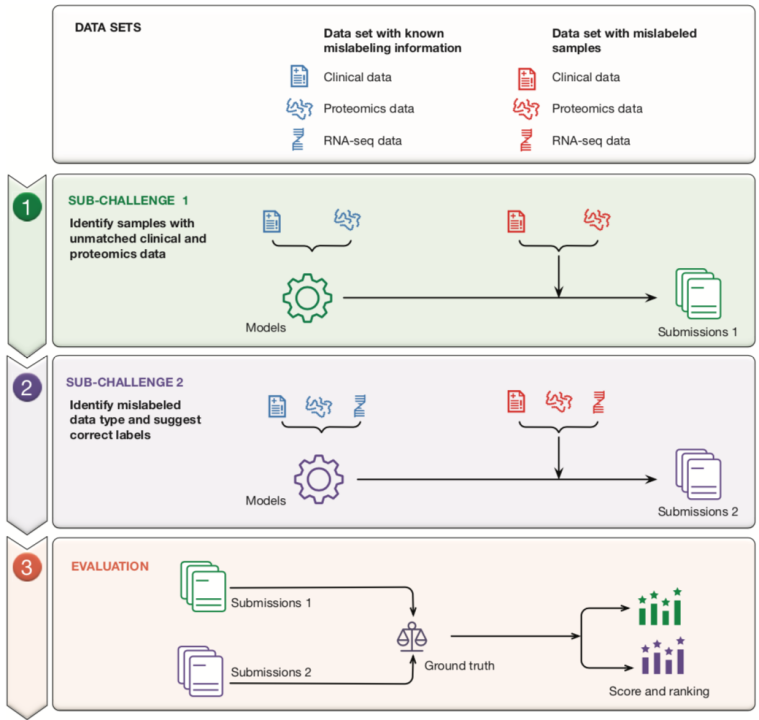
在数据预处理阶段,由于数据集存在部分标签缺失的问题,Sentieon是基于生物学知识将部分空白数据置为0,并结合nearest neighbor拟合的方法对组学数据进行清洗。
在特征筛选阶段,由于数据集存在“小样本,高维度”的问题,为避免模型过拟合,Sentieon使用了LASSO, NSC,ANOVA的方法,通过构建多个模型并对模型结果进行融合,以此评估每个基因与临床标签的相关性,从而有效的降低了数据特征维度,将特征维度从几万多个位点降到几百甚至几十个位点,筛选出与临床标签具有强相关性的基因列表。

通过上述方法,在本次挑战赛的Sub-challenge 1分项赛中,基于蛋白组学数据,Sentieon还引入Label-Weighted randomized k-NN模型对偏移数据进行校正,并同时训练多个分类器,分别计算蛋白表达量与性别,MSI的相关性,最后再对各分类器结果进行综合判断。测试结果显示,Sentieon的训练模型特异性达到100%,准确度得分为0.86,排名第一。
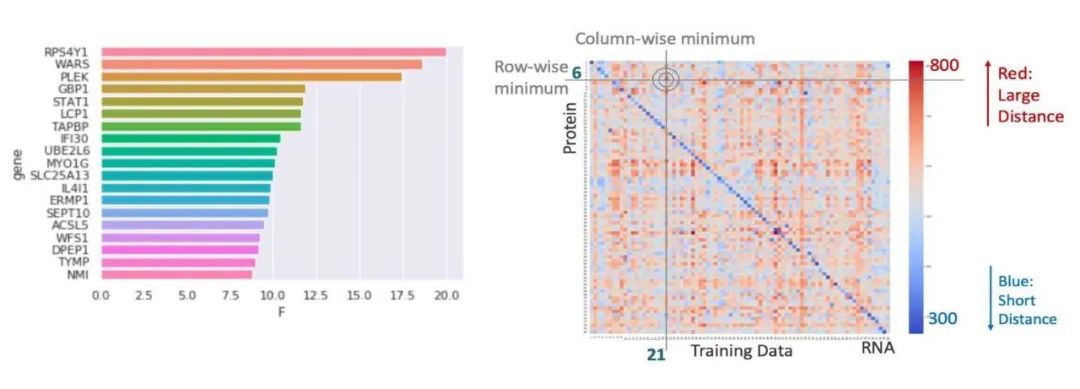
在Sub-challenge 2分项赛中,最大难点是如何融合分析蛋白组及mRNA数据。Sentieon通过回归模型将RNA-seq数据对应映射到蛋白组数据,将样本匹配问题转换为NxN矩阵的minimal distance问题。
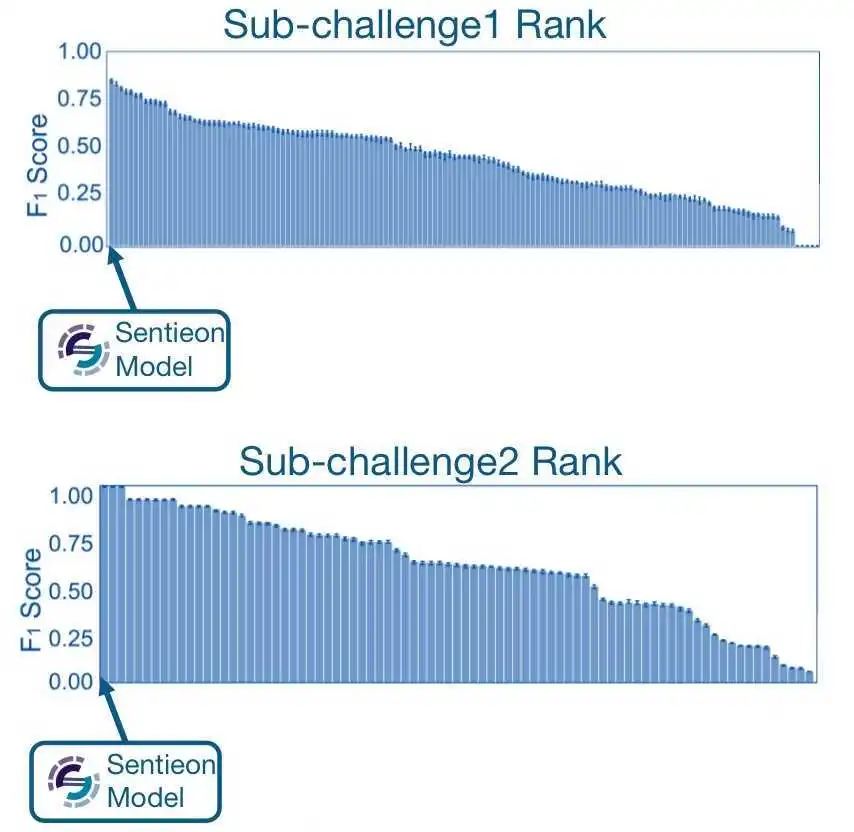
测试结果显示,Sentieon的训练模型可完美找出每个错标样本,并且将各个错标样本进行纠正,夺得挑战赛冠军。

- 点赞
- 收藏
- 关注作者
评论(0)