《深度学习笔记》五 - 从分类到目标检测

退化问题不解决,深度学习就无法Go Deeper。
于是残差网络ResNet提出来了。
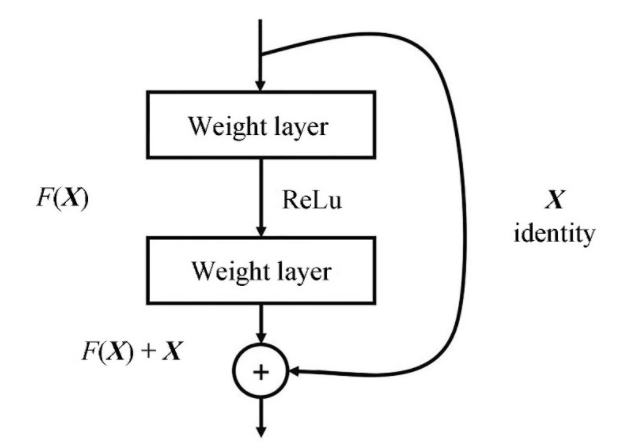
要理解残差网络,就要理解残差块(Residual Block)这个结构,因为残差块是残差网络的基本组成部分。
之前的各种卷积网络结构(LeNet5、AlexNet、VGG),通常结构就是卷积池化再卷积池化,中间的卷积池化操作可以有很多层。类似这样的网络结构何恺明在论文中将其称为普通网络(Plain Network)。
普通网络解决不了退化问题,因此需要在网络结构上做出创新。何恺明给出的创新在于给网络之间添加一个捷径(Shortcuts)或跳跃连接(Skip Connection),可以让捷径之间的网络能够学习一个恒等函数,使得在加深网络的情形下训练效果至少不会变差。
残差块

2017年的冠军方案SENet的错误率已经降至2.25%,这个精度已经超过人类视觉水平。
ILSVRC竞赛也在这一年停办。
但针对深度学习和计算机视觉的研究仍然继续向前发展。
这叫急流勇退、事了拂衣去。图像分类作为人类用于AI探索的基础功能,搞的已经是非常透彻,基本也到天花板了。
ILSVRC竞赛于2017年停办。因为错误率已经降至2.25%,已经超过人类视觉水平。
这个方向再办下去,没有太大意义了。
但是计算机视觉的研究仍然继续向前发展。
2017年,刘壮等人在ResNet的基础上提出了DenseNet网络,作为2017年CVPR的最佳论文,作者通过大量使用跨层的密集连接,强化了卷积过程中特征的重要性,另外也缩减了模型参数,进一步提高了深度卷积网络的性能。
而后提出的SqueezeNet、MobileNet、ShuffleNet、NASNet和Xception等深度网络则致力于让CNN走出实验室达到工业应用的目地。
而大家知道,计算机视觉是AI工业应用落地比较好的领域了。
EfficientNet是最好的吗?
2019年5月谷歌大脑发布了号称当时最好的CNN分类网络的EfficientNet。
EfficientNet在吸取此前各种网络优化经验的基础上提出了更加泛化的解决方法。
EfficientNet作者认为,之前关于网络性能优化要么是从网络深度、要么是从网络宽度(通道数)、要么是从输入图像的分辨率单独来进行模型缩放调优的。
但实际上网络性能在这3个维度上并不是相互独立的。EfficientNet的核心在于提出了一种混合模型缩放(Compound Model Scaling)方法来综合优化网络深度、宽度和分辨率,通过这种思想设计出来的网络能够在达到当前最优精度的同时,大大减少参数数量和提高计算速度。
这样看来,EfficientNet就是集大成者。
目标检测任务,就是要让计算机不仅能够识别出输入图像中的目标物体,还能够给出目标物体在图像中的位置。
在深度学习正式成为计算机视觉领域的主题之前,传统的手工特征图像算法一直是目标检测的主要方法。
在早期计算资源不充足的背景下,研究人员的图像特征表达方法有限,只能尽可能地设计更加多元化的检测算法进行弥补,包括早期的尺度不变特征变换(SIFT)检测法、方向梯度直方图(HOG)检测算法、超级位置模型(SPM)和可变型部件模型(DPM)等。
当然,现在时代已经变了。2012年AlexNet提出之后,神经网络和深度学习逐渐取代了传统目标检测算法而成为目标检测的主流方法。
RCNN作为将深度学习引入目标检测算法的开山之作,在目标检测算法的发展历史上具有重大意义。
RCNN算法是两步走算法的代表,即先生成候选区域(Region Proposal),然后再利用CNN进行识别分类。
由于候选区域对于算法的成败起着关踺作用,所以该算法就以Region开头首字母R加CNN进行命名。

相较于传统的利用滑动卷积窗囗来判断目标的可能区域,RCNN采用选择性搜索(Selective Search)的方法来预先提取一些较可能是目标物体的候选区域,速度大大提升,计算成本也显著缩小。
总体而言,RCNN算法分为4个步骤:一是生成候选区域;二是对候选区域利用CNN进行特征提取;三是将提取的特征送入SVM分类器;四是使用回归对目标位置进行修正。
虽然RCNN在2013年可谓是横空出世,但是它也存在许多缺陷。
-
采用选择性搜索方法生成训练网络的正负样本候选区域,在速度上非常慢,影响了算法的整体速度;–当然,这个快和慢是相对的。前面说了它比较快,是效果比较好的意思。
-
CNN需要分别对每一个生成的候选区域进行一次特征提取,存在着大量的重复运算,制约了算法性能。
针对RCNN的问题,提出ResNet的何恺明又提出了SPPNet。
该方法通过在网络的卷积层和全连接层之间加入空间金字塔池化层(Spatial Pyramid Pooling, SPP)来对候选区域进行裁剪和缩放,使CNN的输入图像尺寸一致。
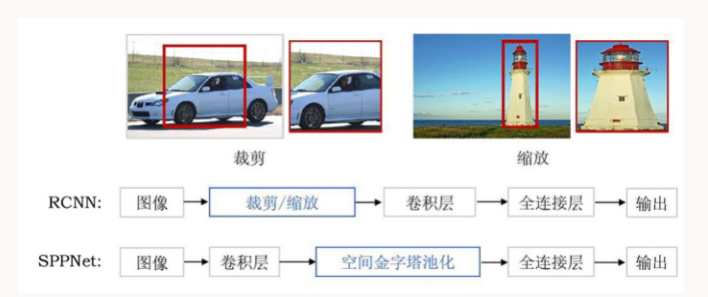
优点:减少了RCNN中的重复计算。这个不是很理解。
缺点:经过空间金字塔层的处理后,虽然CNN的输入尺寸一致了,但是候选框的感受野变得很大,使得卷积神经网络在训练时无法有效更新模型权重。
于是2015年MS亚洲研究院在借鉴了SPPNet的空间金字塔层的基础之上,对RCNN算法进行了改进。
FastRCNN的改进之处在于设计了一种兴趣区域(Region of Interest,RoI)池化的池化层结构,有效地解决了RCNN算法必须将图像区域剪裁、缩放到相同尺寸大小的操作;
另外,提出了多任务损失函数,每一个RoI都有两个输出向量:softmax概率输出向量和每一类的边界框回归位置向量。

FastRCNN虽然借鉴了SPPNet的思想对RCNN进行了改进,但是对于RCNN的选择性探索的候选框生成方法依然没有改进。
于是,RCNN系列的几位作者一起提出了Faster RCNN方法。
Faster RCNN的关键在于设计了区域候选网络(Region Proposal Network,RPN),将候选框的选择和判断交给RPN进行处理,将RPN处理之后的候选区域进行基于多任务损失的分类定位。
Faster RCNN的优点在于CNN提取的特征信息能够做到全网络的权值共享,解决了之前的大量候选框导致速度慢的问题。但是由于RPN可在固定尺寸的卷积特征图中生成多尺寸的候选框,导致出现可变目标尺寸和固定感受野不一致的肩况。

2017年,何恺明等人在之前的基础上继续改善RCNN算法,提出了Mask RCNN。
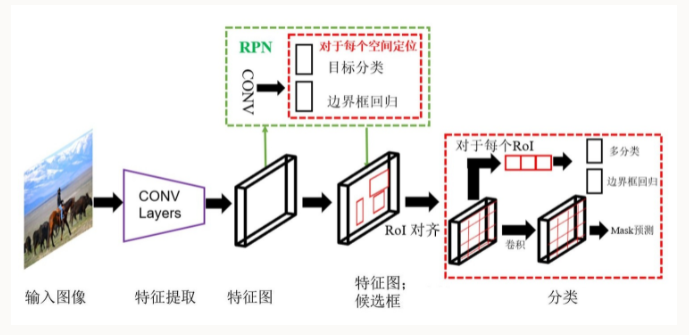
Mask RCNN将Fast RCNN的RoI池化层升级成了RoI对齐(Align)层,并且在边界框识别的基础上添加了分支全卷积网络(FCN)层,即Mask层,用于语义Mask识别。
通过RPN生成目标候选框,然后对每个目标候选框分类判断和边框回归,同时利用全卷积网络对每个目标候选框预测分割。
Mask RCNN本质上是一个实例分割算法(lnstance Segmentation),相较于语义分割(Semantic Segmentation),实例分割对同类物体有着更为精细的分割。
MaskRCNNECOCO测试集上的图像分割效果

两步走目标检测算法的大致发展历程:RCNN—>SPPNet—>FastRCNN—>FasterRCNN—>MaskRCNN
虽然两步走的目标检测算法在不断进化,但是在速度方面一直没有太大的突破。
所以不太适合实时的目标检测场景。
实时的目标检测场景的需求,有代表性的解决算法就是YOLO系列。
YOLO系列算法的主要思想就是直接从输入图像得到目标物体的类别和具体位置,不再像RCNN系列那样产生候选区域。这样做的直接效果便是速度快。

YOLO v1的核心思想就是将整张图像作为网络的输入,直接在网络的输出层输出目标物体的类别和边界框的具体位置坐标。
YOLO v1将输入图像划分为S*S的网格(Grid),每个网格预测两个边界框,如果目标物体落入相应的网格中,那么该网格就负责检测出该目标物体。

总体而言,YOLOvl算法分为3个步骤:一是缩放图像;二是运行卷积网络,三是非极大值抑制。
虽然速度快,但是它的缺点也很明显。
由于一个网格只能预测两个边界框,这使得YOLO对密集的小物体的检测效果并不好;
YOLO v1也存在着泛化性能较弱等问题。
针对YOLO v1的定位不够准确的问题,2016年底提出的单次多边框探测器(Single Shot MuItiBox Detector,SSD)算法的解决方案在于将YOLO的边界框回归方法和Faster RCNN的锚定框(Anchor Boxes)机制结合起来,通过在不同卷积层的特征图上预测目标物体区域,输出具备不同纵横比、多尺度、多比例的边界框坐标。

这些改进使得SSD能够在输入分辨率较低的图像时也能保证检测的精度。这也使得SSD的检测准确率超过了此前的YOLO v1
YOLOv2重点对v1的定位问题给出了解决方案:使用DarknetG19作为预训练网络,增加了BN(Batch NormaLization)层,提出了一种新的训练算法:联合训练算法,该算法可以把分类数据集和检测数据集混合到一起。
使用一种分层的观点对物体进行分类,用大量的分类数据集数据来扩充检测数据集,从而把两种不同的数据集混合起来。
另外,相较于v1直接用全连接层预测边界框坐标,YOLOv2则是借鉴了RCNN中的锚定框,使用锚定框虽然会让精确度稍微下降,但用了它能预测超过1000个框,同时召回率达到88%,平均精度均值(mAP)达到69.2%。
YOLO v3为了在保证速度的同时实现更高的定位准确率,采用了更为复杂的网络结构。
相较于此前的网络,YOLOv3的改进之处包括多尺度预测(FPN)、更复杂的网络结构DarknetG53、取消softmax作为候选框分类,这些都使得YOLO v3的速度更快,准确率也有相应提高。与需要数千张单一目标图像的RCNN不同,YOLOv3通过单一网络评估进行预测。这使得YOLOv3的速度非常快,同等条件下它比RCNN快1000倍、比FastRCNN快100倍。
以上便是一步走目标检测算法的大致发展历程。
目标检测算法的两大流派之间也在不断的借鉴和互相改进。不管使用哪种算法,最终还是需要在速度和精度之间找到一个平衡。

- 点赞
- 收藏
- 关注作者
评论(0)