【AI理论】ACL 2019 Best Long Paper 的理解与体会

中科院计算所自然语言处理团队的论文《Bridging the Gap between Training and Inference for Neural Machine Translation 》获得ACL 2019大会的最佳长文奖。
论文主要解决神经网络在翻译领域,训练和测试时所用的上文信息不同造成的偏差问题。
论文提出了新的训练方法,而非新的模型。读完之后,发现这种方法适用于许多领域的训练-测试不匹配的问题,如:阅读理解、语言模型。
论文地址:
Bridging the Gap between Training and Inference for Neural Machine Translation
随便贴一下实验室学长ACL2019的 Oral Paper
Incremental Transformer with Deliberation Decoder for Document Grounded Conversations
传统的神经机器翻译有两个问题:
exposure bias (训练和测试时所用的上文信息不同的问题)
overcorrection(过度矫正)
一、exposure bias
那么,什么叫‘训练和测试时所用的上文信息不同的问题’呢?
训练时:
 注意红色
注意红色
在训练时,无论模型的预测输出是什么,decoder模型的输入都是ground truth word的,即:模型的输入都是正确的,如:are 。
测试时:

在测试时,由于没有正确答案,所以用模型预测的上一个字的结果作为输入,如:is、 you 。
这就导致了在测试时,如果在某个地方预测错,那么之后模型的输入都是错误的,这就造成了错误会一直累积;或许模型在某个地方所预测的是另一种翻译的词,但是在训练时没有碰到过这种情况,所以模型无法进行处理。
这种偏差叫做‘exposure bias’。
二、overcorrection
训练翻译模型时,还会碰到另一个问题:overcorrection(过度矫正)
什么意思呢?
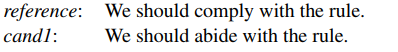
当模型在第三个位置预测出‘abide’时,为了让这句话的loss最小,模型之后会预测 ‘with the rule’,但是‘abide with the rule’是错误的;正确的应该是‘abide by the rule’。
核心!作者的解决办法:
在训练时,decoder的输入有时候是ground truth word,有时候是其他的。
这个‘其他’是什么?有两种,一种是模型的上一个输出(Word Level),另一种是从一句与译文类似的句子的对应位置选择 (Sentence-Level) 。
下面来讲讲这两种方法:
一、Word Level:
最直接的方法就是:对模型上一个 time step 的输出向量softmax后,取概率最高的词作为模型的输入。

o是模型的上一个输出向量,P是每一个词的概率,即: vocabulary size
需要注意的是,作者对这个向量加入了noise向量后才 softmax的,这对模型有很大帮助,之后会说,即:

二、Sentence-Level:
在每一次训练前,模型先用 beam search找到最好的 k 个候选翻译,然后将这 k 句话与正确答案计算 BLEU得分,取得分最高的当作备选句子。
有了备选句子后怎么办?比如,模型现在要预测第四个词,那么模型的输入是第三个词,这第三个词可以是正确译文的第三个词(传统做法)、可以是模型所预测的第三个词(Word Level)、也可以是这句备选句子的第三个词(Sentence-Level)。
现在有一个问题: 如果备选句子的长度与答案的长度不一样怎么办,这样备选句子与ground truth不是一一对应的了,那么这样的替换就没有意义了,因为我们希望这个词和对应答案的词是意思相近的或者是近义词。
作者给出了办法:
beam search在生成句子时,直到模型预测出结尾符<EOS>才结束。
假设ground truth的长度是 n :
1、若模型在 n 之前就预测出<EOS>结尾符,那么,我们选择概率第二的作为预测词。
2、若模型在 n 时没有预测出<EOS>结尾符,那么,我们选择<EOS>结尾符,并使用它的概率。
作者的思路就是这样,然后就是最小化每一个字与ground truth对应字的负似然对数。
是与原始的ground truth的词计算loss!!! 而不是与替换了的词,这个替换只发生在模型的输入。
需要注意的是!!!!
在模型刚开始训练时,如果频繁的用上文提到的方法替换输入时,会导致泛化能力过低、容易陷入局部最低点,因为刚开始模型还没有训练好,而且这时候模型生成的备选句子一般都不是人话;
在训练接近尾声时,若依然用ground truth word作为输入,那就没有解决上文提到的两个问题了。
所以,在训练前期,大概率选择ground truth word作为输入,在训练后期,小概率选择ground truth word作为输入。这个概率定义如下:

e是epoch,µ是超参
p是单调递减的,在epoch=0时,p是很大的,表示以概率p选择ground truth word作为输入。
实验效果:

word oracle就是word level替换
上文提到的在选择替换词时,加入noise,这个noise可以有效提高模型效果:

可以将这种noise看成一种 regularization,它使模型在选择替换词是更加健壮、可靠。

η 就是 Gumbel noise
该方法的实验细节和流程,论文写的很详细,有兴趣可以仔细看看。
以上!
转自:https://zhuanlan.zhihu.com/p/76227765

- 点赞
- 收藏
- 关注作者
评论(0)