《深度学习笔记》四 - NLP部分

计算机刚诞生不久,人们就用它来开始解析人类的自然语言。
而这一需求的来源,是尝试着利用计算机将大量俄语资料自动翻译成英语。其用处你应该是懂的。
而研究者的思路是从破译军事密码中得到了启示,简单的认为语言之间的差异只不过是对同一语义的不同编码而已。
于是想当然的采用译码技术解析不同的语言,这就是最早机器翻译理论的思想。
这个思想现在看来,还是太嫩了点。但是看上去还是蛮有道理的。
1954年1月7日,研究有了进展:成功的将60多句俄语自动翻译成了英语。
于是研究者充满信心的声称:在3~5年之内就能够完全解决从一种语言到另一种语言的自动翻译问题。
研究工作形成了自己的理论基础:“形式语言理论”(Formal Language Theory)
10年之后,机器翻译没有取得本质性突破。
1964年美国科学院成立了语言自动处理咨询委员会ALPAC,委员会做了2年的研究,发布了一个报告,否定了机器翻译的可行性。它是机器翻译时代的终结者。
但是有否定才有肯定。
有一个时代的终结,才有一个新时代的开启。
所以,终结者也是开拓者。
汉语自然语言处理的第一个部分是中文分词。(Chinese Word Segmentation)
英文没有这个问题。因为英文序列中,词和词之间都有空格…
如果涉及到未标点的古文,还要断句。ohmygod
而中文分词的算法,可以分为二大类。
基于条件随机场(CRF)的
基于张平华NShort的
NShort是目前大规模中文分词的主流算法。结巴分词器就是该算法的Python实现。
Part-of-Speech Tagging
判断出在一个句子中每个词所扮演的语法角色。
如名词、动词、形容词等。
在汉语中,常用词的词性都不是固定的,也就是说,一个词可能具有多个词性,并且对于每个不同的词性,汉语词汇都没有形态的变化,这就为确定中文词性带来困难;
但在另一方面,从整体上看,大多数词语,特别是实词,一般只有一两个词性,而且位于第一位词性的频次远远高于第二位的词性,即使选取最高词频作为唯一词频,系统也可实现80%准确率。
因此,中文词性标注中影响词性标注精度的因素主要是要正确判断文本中那些常用词的词性。
算法大多数都用 HMM(隐马尔科夫模型)或最大熵算法
有一些中文标注集可以使用。
命名实体识别用于识别文本中具有特定意义的实体,常见的实体主要包括人名、地名、机构名及其他专有名词等。
命名实体识别不仅需要标注词的语法信息(名词),更重要的是要指示词的语义信息(人名还是组织机构名等)。
需要注意的是,需要识别的命名实体一般不是指己知名词(词典中的登录词),而是指新词(或称未登录词)。
更具体的命名实体识别任务还要识别出文本中三大类(实体类、时间类和数字类)、七小类(人名、机构名、地名、时间、日期、货币和百分比)。
—不知道这个分类是不是完整和合理…
句法分析是根据给定的语法体系推导出句子的语法结构,分析句子所包含的语法单元和这些语法单元之间的关系,将句子转化为一棵结构化的语法树。句法分析是所有自然语言处理的核心模块。
句法分析的开源系统也很多,但仍旧很难找到高精度处理中文的句法解析系统。
首先介绍一个网站,看名字你就知道它是做什么用的:象形字典 www_dot_vividict_dot_com
总结中文的造字方法的最重要的成果就是六书。
它根据汉字的构成和使用方式归纳成的六种模式,总称为六书。
六书是指:“象形”、“指事”、“会意”、“转注”、“假借”、“形声”。
以许慎的《说文解字》为例,结合象形词典来学习这六种模式。
- 象形
“象形者,画成其物,随体诘诎,日月是也。”这句话说的是,所谓的象形字是把具体的物体以绘画的形式表现出来,形成文字,根据物体的不同绘画形式也不同,比如:
日 月 山
- 指事
“指事者,视而可识,察而见意,上下是也。”这句话说的是,一眼看上去就可以识别出整体(本字),仔细观察就能发现意义所在。比如:
上 下 刃
字虽少,但码字不易,所以分为2个帖子,下面继续六书中的“会意”、“转注”、“假借”、“形声”。
- 会意
“会意者,比类合谊,以见指什么,武、信是也。”这个造字法,是将两个或两个以上的字根组合起来,使之形成一个新字,并衍生出新的含意。这是一种更高级的认知形式。比如:
武 信 休 盗
- 形声
“形声者,以事为名,取譬相成,江河是也.”
所谓以事为名,即依事类而定其名字。是说在经某个事物定名而造字时,先确定它在客观事物中的属类(范畴),属类确定后就用表示此属类的字来做新造字的语义部分;
所谓取譬相成,就是根据语音取一个读音相同或相近的字来做新造字的标声部分。
使用语义和标声的两个部分共同构成所造的新字。
形声法巧妙地把读音与语义结合起来。现在普遍认为,早期人类的语言形成于文字之前.一个事物往往先有读音,如果需要记录,再行造字。只要某个事物或概念有其属类(范畴),并有约定俗成的读音,就能自然地通过形声法构造出新字。因此,形声法一经出现,就成为最能产的造字形式。仅以甲骨文为例,形声字约占27%。现代汉语中的形声字己达90%以上,成为最主要的汉语造字方法。
比如:
江 河
- 转注
“转注:转注者,建类一首,同意相受,考老是也。”这句话说的是,用一个部首来表征部内的字,意义相同的字之间可以相互解释。比如:
考 老
母 女
- 假借
“假借者,本无其字,依声让事,令长是也。”意思是说,假借法是文字中为表达某一新事物,本来没有表示它的字,就依据读音去找一个音同或音近的现成字来赋予其新的词义,用以表达该种事物。比如:
令 长
以一句话为例:
I want a glass of orange _____。
现在要通过这句话的其他单词来预测划横线部分的单词。这是一个典型的NLP问题,将其作为有监督机器学习来看的话,模型的输入是上下文单词,输出是划横线的目标单词(或者说是目标单词的概率),这里需要一个语言模型来构建关于输入和输出之间的映射关系。
应用到深度学习上,这个模型就是神经网络。
在NLP中,计算机并不认识这些人类语言,计算机只认识0和1(可以对应到黄帝内经中的阴和阳,简简单单的阴和阳真的可以生万物啊~计算机也是这样),所以需要对以词汇为代表的自然语言进行数学上的表征(果然数学是科学中的科学)。简单来说,就是要将词汇转化为计算机可识别的数值形式,这种转化和表征方式目前主要有两种,我们先来看第一种:传统机器学习中的one-hot编码方式。
词汇的One-hot表示如下:
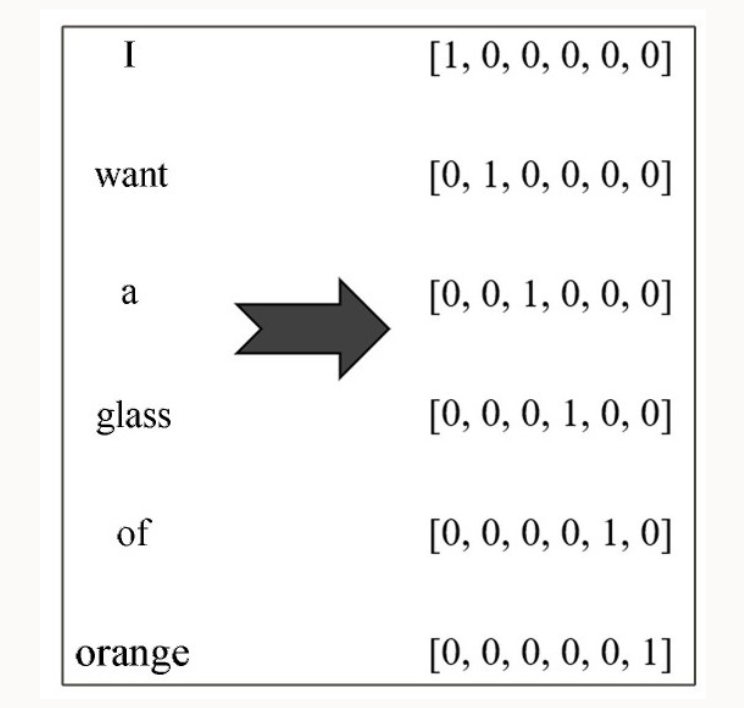
这种表示最后形成一种稀疏编码。
在深度学习出马之前,这种表征方法在传统的NLP模型中已经取得了很好的效果。
但是有两个缺陷:
一是容易造成维数灾难,10000个单词的词汇表不算多,但对于百万级、干万级的词汇表简直无法忍受;
二是不能很好地获取词汇与词汇之间的相似性。
例如,上述句子,如果我们已经学习到了I want a glass of orange juice,
但如果换成了I want a glass of apple _____,
模型仍然不会猜出目标词是juice。
因为基于one-hot的表征方法使得算法并不知道apple和orange之间的相似性,这主要是因为任意两个向量之间的内积都为零,很难区分两个单词之间的差别和联系。
因为one-hot表示词汇存在无法表示两个单词之间的差别和联系的缺陷,所以为了克服这个缺陷,就有了词嵌入、词向量表示。
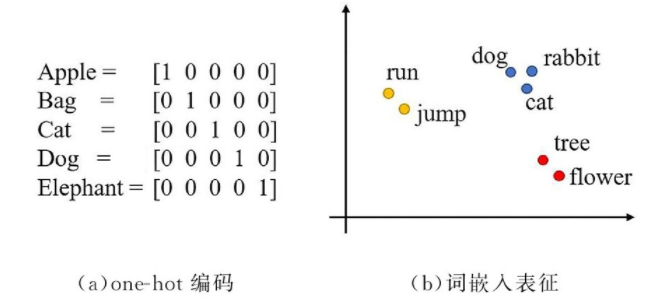
词嵌入(Word Embedding)
词嵌入的基本思想就是将词汇表中的每个单词表示为一个普通向量,这个向量不像one-hot向量那样都是0或1,也没有one-hot向量那样长,大概就是很普通的向量,如[-0.8,1,2.9,-0.2,…]
这样的一种词汇表征方式就像是将词汇嵌入到了一种数学空间里,所以叫作词嵌入。著名的word2vec就是词嵌入技术的一种。
如何进行词嵌入?或者说如何才能将词汇表征成很普通的向量形式?
这需要通过神经网络进行训练,训练得到的网络权重形成的向量就是我们最终需要的,这种向量也叫作词向量,word2vec就是其中的典型技术。
word2vec作为现代NLP的核心思想和技术之一,有着非常广泛的影响。它有两种语言模型。
一种是根据上下文来预测中间词的CBOW(连续词袋模型)
另一种是根据中间词来预测上下文的Skip-gram(跳字模型)
来看3个句子:
I like deep learning.
I like NLP.
I enjoy flying.
(这3个句子来自于斯坦福大学《深度学习与自然语言处理》CS224d)
先来统计上述词汇的共现矩阵。
共现矩阵是指在一个非负矩阵中,矩阵的每一列表示一个指定的项或单词,而每一行则表示所有出现在该项或单词的文本或语言中的所有单词。并以当前词周边共现词次数作为当前词的向量。

比如上图中,like 共在 I 的周边出现了2次。
对共现矩阵进行SVD分解(奇异值分解)即可得到SVD词向量。经过SVD降维后,一些语义相近的词被聚到了一起。
然后是基于语言模型的词向量生成方法。语言模型,通俗来说就是把一些词语组成一句话来判断这句话是不是一句完整的话。
word2vec是google在2013年提出的一种NLP分析工具。
word2vec包括两种模型。
一种是给定上下文词,需要预测中间目标词,这种模型叫连续词袋模型(Continuous Bagof-Words Model,CBOW);
CBOW模型的应用场景是要根据上下文预测中间词,所以输入为上下文词,当然原始的单词是无法作为输入的,这的输入仍然是每个词汇的one-hot向量,输出Y为给定词汇表中每个词作为目标词的概率。
另一种是给定一个词,然后根据这个词来预测它的上下文词,这种模型叫作Skip-gram,也有种翻译称之为跳字模型。
这二者在输入、输出上有所不同外,基本上没有太大的区别。将CBOW的输入层换成输出层基本就变成了Skip-gram模型,二者可以理解为一种互为翻转的关系。
从有监督学习的角度来说,word2vec本质上是一个基于神经网络的多分类问题,当输出词语非常多时,则需要一些像分层softmax和负采样(Negative Sampling)之类的技巧来加速训练。
但从自然语言处理的角度来说,word2vec关注的并不是神经网络模型本身,而是训练之后得到的词汇的向量化表征。这种表征使得最后的词向量维度要远远小于词汇表大小,所以word2vec从本质上来说是一种降维操作。把数以万计的词汇从高维空间中降维到低维空间中,对下游NLP任务大有裨益。
这里我想到一个问题,word2vec是否也适用于中文呢?因为众所周知,汉字具有言简意赅的优点,所以常用汉字并不多,并不是数以万计,而是数以千计就足够了。
- 点赞
- 收藏
- 关注作者
评论(0)