基于深度学习的YOLO框架的7种交通场景识别项目系统【附完整源码+数据集】

基于深度学习的YOLO框架的7种交通场景识别项目系统【文末附完整源码+数据集】
支持识别对象类别:机动车、非机动车、行人、红灯、黄灯、绿灯、熄灭的交通灯
背景
在智慧交通和智能驾驶日益普及的今天,准确识别复杂交通场景中的关键元素已成为自动驾驶系统的核心能力之一。传统的图像处理技术难以适应高动态、复杂天气、多目标密集的交通环境,而基于深度学习的目标检测算法,尤其是YOLO(You Only Look Once)系列,因其检测速度快、精度高、可部署性强等特点,在交通场景识别中占据了重要地位。
为此,我们构建了一个基于YOLO框架的七类交通场景目标识别系统,涵盖机动车、非机动车、行人以及交通信号灯的状态(红、黄、绿、熄灭),以期为自动驾驶辅助、交通监控、信号灯状态判断等应用场景提供一体化解决方案。
功能
本系统具备以下核心功能:
-
多目标同步检测
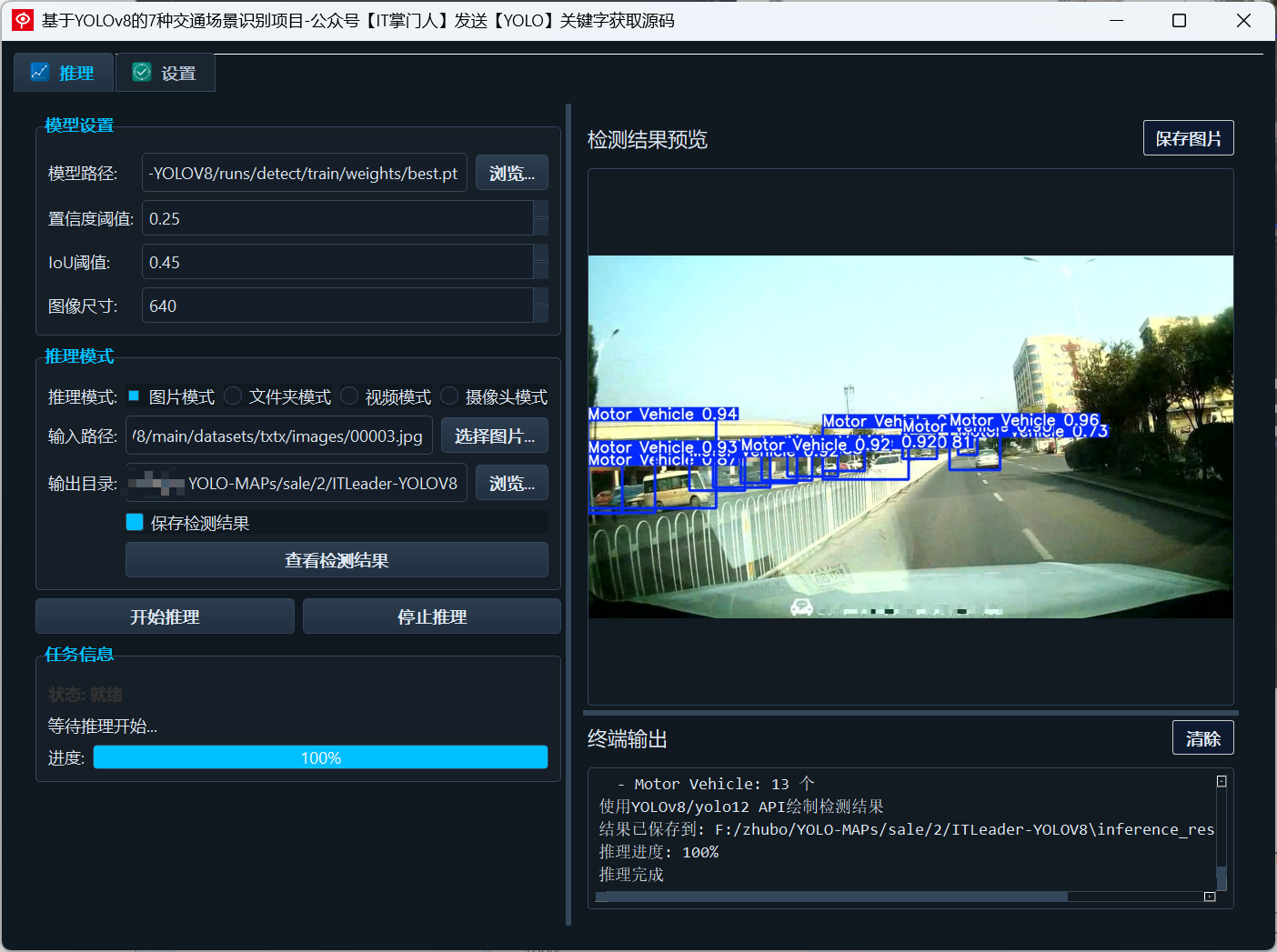
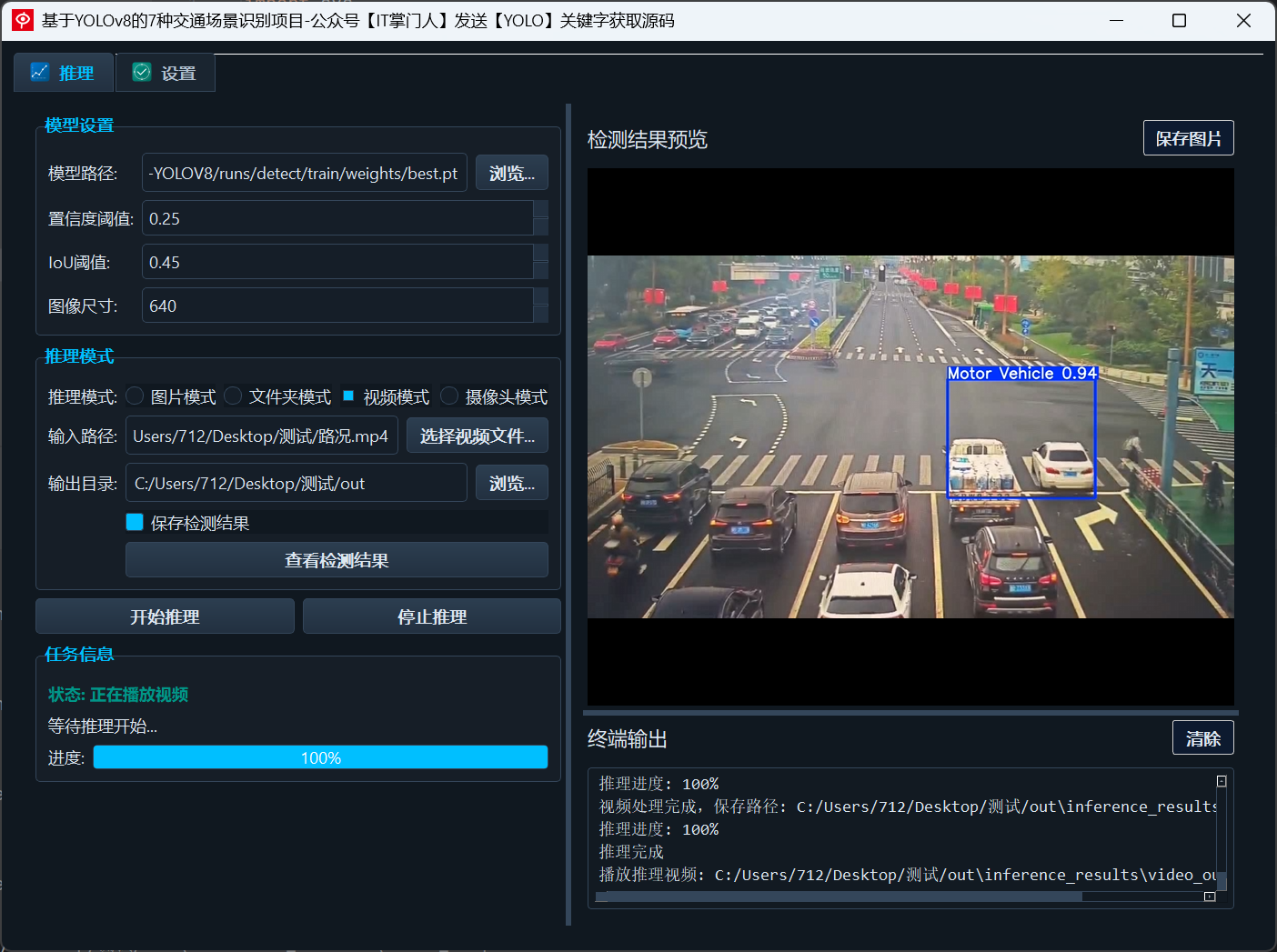
支持在一帧图像中同时检测机动车、非机动车、行人、交通灯(四种状态),实现复杂交通场景的综合感知。 -
实时识别能力
基于YOLOv8优化部署,具备较高帧率(在RTX3060上可达30FPS以上),满足边缘设备和车载系统实时运行需求。 -
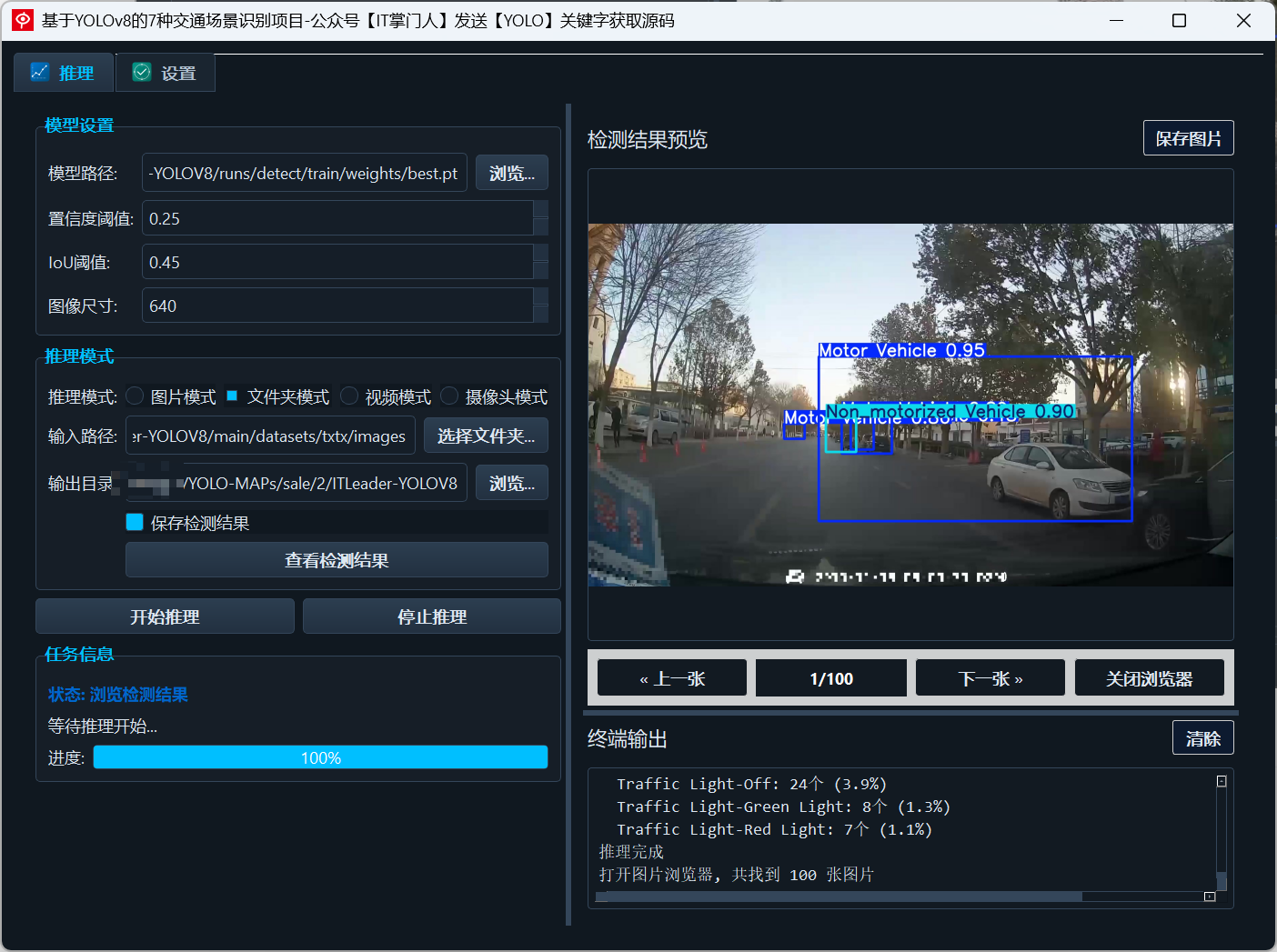
交通灯状态细分类
系统能准确区分红灯、黄灯、绿灯与熄灭的交通灯,为信号灯识别、路径规划提供基础感知能力。 -
目标高亮标注与输出
所有识别结果会通过BBOX标注、类别标签、置信度标识进行清晰可视化,并可输出为图片、视频或JSON格式。 -
完整训练与微调流程
提供自定义数据集训练支持,用户可根据自己采集的城市道路或交通场景快速微调模型。
数据集
本项目使用了自建与开源数据集结合的方式,构建了一个涵盖七种交通目标类别的高质量数据集。
数据集组成:
| 类别 | 标注名称 | 图片数量 | 说明 |
|---|---|---|---|
| 机动车 | vehicle |
3000张 | 包含小轿车、公交车、卡车等 |
| 非机动车 | non_motor |
2000张 | 包含自行车、电动车、三轮车等 |
| 行人 | pedestrian |
4000张 | 各类站立、走动行人 |
| 红灯 | traffic_red |
1500张 | 红灯亮状态 |
| 黄灯 | traffic_yellow |
1200张 | 黄灯亮状态 |
| 绿灯 | traffic_green |
1500张 | 绿灯亮状态 |
| 熄灭的交通灯 | traffic_off |
1000张 | 信号灯关闭或损坏状态 |
数据格式说明:
- 标注格式:YOLO格式(
txt文件,每行为[class_id x_center y_center width height],归一化坐标) - 图片尺寸:统一调整为 640x640
- 划分比例:训练集:验证集:测试集 = 7:2:1
- 标签定义:
names: ['vehicle', 'non_motor', 'pedestrian', 'traffic_red', 'traffic_yellow', 'traffic_green', 'traffic_off']
nc: 7

数据集来源:
- 自采集城市道路场景图像
- 数据集中筛选部分车辆与交通灯
- 交通灯状态补充


YOLO框架原理
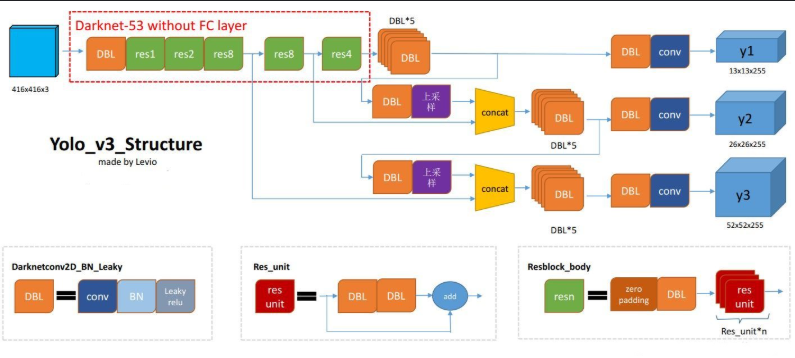
YOLO(You Only Look Once)是单阶段目标检测算法的代表,它将目标检测问题转换为一个回归问题,从图像中直接回归出物体的位置和类别,具有极高的速度优势。YOLOv8作为Ultralytics团队推出的最新版本,具备以下关键特点:
核心原理:
- 单阶段检测器:将整个检测任务在一个神经网络中完成,不依赖候选框生成;
- 端到端训练:输入图像直接输出检测框与分类结果;
- 高精度预测头:YOLOv8采用CSPDarknet主干 + 特征金字塔结构 + 解耦头,提升小目标检测能力;
- 动态标签分配:引入Anchor-free策略,优化标签匹配策略;
- 轻量化部署:可快速导出为ONNX、TorchScript、TensorRT等格式,便于边缘设备部署。

源码下载
完整项目已打包,包括数据集、模型训练、模型推理、PyQt5桌面GUI、预训练权重、详细部署文档。
至项目实录视频下方获取:https://www.bilibili.com/video/BV1yajdzdEvu/
-
包含内容:
train.py:YOLOv8训练脚本(自定义配置)detect.py:推理检测脚本(支持图像/摄像头)ui_main.py:基于PyQt5的图形界面runs/weights/best.pt:训练完成的权重文件data/face_expression/:YOLO格式的数据集requirements.txt:项目依赖安装文件
📌 运行前请先配置环境:
conda create -n yoloui python=3.9
conda activate yoloui
pip install -r requirements.txt
📌 启动界面程序:
python ui_main.py
总结
本项目基于YOLOv8构建了一套完整的交通场景识别系统,支持识别包括机动车、非机动车、行人及交通灯状态在内的七种关键目标类别。通过深度学习算法的高效感知能力,系统在保持实时性的同时,具备良好的识别精度与扩展性。
系统的亮点包括:交通灯状态的精细识别、多类别目标的协同检测、完善的训练与部署流程,以及直观的可视化界面,为智慧交通、自动驾驶、城市管理等领域提供了可靠的感知基础和工程参考。
未来,我们计划进一步引入Transformer结构、轻量化检测头、跨模态融合机制等技术,提升系统在复杂天气、夜间场景下的鲁棒性与通用性,同时探索与车载控制系统的深度集成,推动交通感知技术走向实际应用。

- 点赞
- 收藏
- 关注作者
评论(0)