GaussDB(DWS)高可用之CM告警与问题定位

前言
本文主要内容分三块内容,1. CM的主要运行流程 2. CM告警机制 3. 故障排查与解决
GaussDB for DWS 的内核侧组件为DN, CN, GTM,内核侧组件是通过集群管理组件CM server、CM agent 来进行管理的。内核组件和集群管理组件共同组成了GaussDB for DWS 集群。
一、CM的主要运行流程
参考链接:
GaussDB (DWS) 集群管理系列:CM组件介绍(架构和部署形态)
GaussDB (DWS) 集群管理系列:CM组件介绍(核心功能)
1.1 cm_server功能
cm_server是集群 管理的大 脑,整个管理系统的仲裁者,系统中只有一个,主备架构,系统中常驻的服务进程,多线程架构。主要收集cm_agent返回的各个实例(GTM主备、CN、DN主备从)状态信息,从而通过分析给出谁是主谁是备,什么时候需要failover切换,什么时候需要重建DN。cm_server的另一个作用就是接收客户端cm_ctl发送的命令,使得cm_ctl可以管理整个集群。
1.2 cm_agent功能
cm_agent负责收集本地物理机中内核端各个组件的状态信息,并上报给CMserver,由于CMagent只管理本地物理机,如果单节点故障(如断电,机器故障)后,该物理机上实例均故障,无法管理,因此也不需要备机。且CMagent本地并不存储任何信息,是一个无状态的组件,进程故障后,可以立刻拉起。
1.3 om_monitor功能
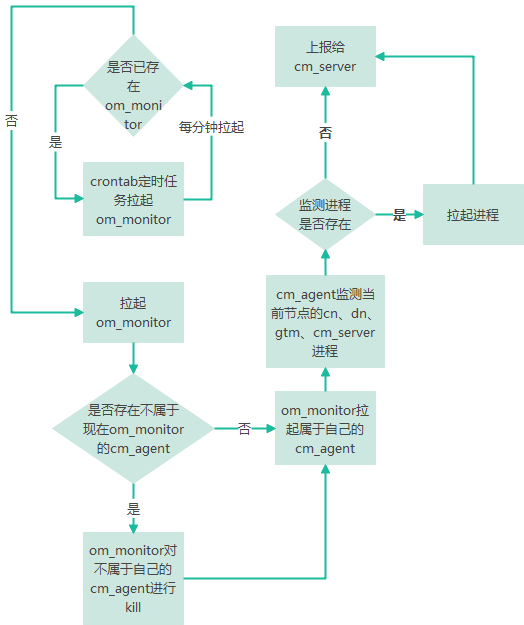
om_monitor进程负责拉起cm_agent 以及杀掉非自己启动的cm_agent。om_monitor为了保活,每分钟都会被系统定时任务crontab拉起,后拉起的进程在发现已经有om_monitor进程时,会自己退出。
下图为CM模块的主要运行流程:
二、CM告警机制
cm_agent会实时检测cn、dn、gtm、cm_server状态,固定间隔1秒上报实例状态给cm_server。
心跳是在cm_server上累计的。没有上报消息,心跳就会+1,超时就会仲裁。只有cm_agent成功连接并上报节点信息,才会刷新心跳状态。
当启动集群、节点、实例时,会删除启停文件,当停止集群、节点、实例时,会生成启停文件。
集群启停文件 cluster_manual_start
实例启停文件 instance_manual_start_X(X是实例编号,例如instance_manual_start_6001)
启停文件存在与否标志着实例或集群的启停状态。
2.1 根据启停文件判断
正常情况下,根据启停标志文件是否存在做进一步判断,
如果启停文件不存在且磁盘、网卡正常 ->cm_agent检查实例进程是否存在 如果存在则正常,如果不存在则拉起实例
如果启停文件存在且磁盘、网卡正常 ->cm_agent检查实例进程是否存在 如果存在则杀死所有实例,如果不存在则则正常
2.2 根据心跳判断
当cm_agent检测到dn\gtm实例状态异常并上报给cm_server之后,会做一些检查以及启动实例,会根据实例心跳超时时间(instance_heartbeat_timeout)进行判定,当超过实例心跳时间之后实例无法恢复,cm_server会给cm_agent下发仲裁命令,将相应实例的状态置为 Unknown。
当cm_agent检测到cn实例状态异常之后,会做一些检查以及启动实例,会根据cm_server在CN故障后仲裁自动剔除的触发时间(coordinator_heartbeat_timeout),当超过该时间实例无法恢复,自动剔除cn。
当cm_server未收到cm_agent的上报,会根据实例心跳超时时间(instance_heartbeat_timeout)进行判定,当超过实例心跳时间之后依旧无法恢复cm_server与cm_agent的连接,cm_server会给当前安全环其他cm_agent下发主备切换,将相应实例的状态置为 Unknown。
单节点故障RTO机制分析:https://bbs.huaweicloud.com/blogs/248077
2.3 cm_server进程故障
cm_agent会检测cm_server进程是否正常(进程存在或者正常停止),如果不正常则会停止或者拉起
cm_server只有检测到启停文件存在时才会杀死cm_server进程,而磁盘、网卡有故障时并不会杀死cm_server进程
如果cm_server因故障无法被拉起cm_agent会一直执行拉起cm_server的命令并输出日志
cm_server主备是自仲裁。cm_server主备会相互连接进行通讯,当对端连接异常且超过超时时间后会触发自仲裁选主
三、故障判断及解决方案
3.1 故障类型

3.2 实例重启

[1]故障类型:长连接断开无法接入导致的超时查杀
关键日志: ${GAUSSLOG}/cm/cm_server/cm_server_创建时间.log
关键词:heartbeat timeout

这种情况属于长连接断开直到超出心跳时间,cms将发送failover命令到备节点,导致主备切换。
[2]故障类型:cma和cms断连导致的超时查杀
关键日志: ${GAUSSLOG}/cm/cm_agent/cm_agent_创建时间.log
关键词:agent disconnect cm_server xx sec timeout

cms和cma之间的连接断开超时,导致cms无法接收到cma上报的消息,因此下发kill。
解决方案:需要排查网络以及负载情况,可能为网络连接超时或者业务量过大导致的负载过大,系统函数运行缓慢。
[3]故障类型:Hang检测查杀
关键日志:${GAUSSLOG}/cm/cm_agent/cm_agent_创建时间.log
关键词:phony dead

关键日志: ${GAUSSLOG}/cm/cm_server/cm_server_创建时间.log
关键词:phony dead

长连接依旧存在,但是短链接无法连接,被判定为操作系统hang死,将通过长连接对故障节点下发重启节点命令。
解决方案:联系华为工程师,给当前节点部署hang检测堆栈脚本,需要抓取hang时堆栈进行分析。
[4]故障类型:内存超过70%阈值导致重启
关键日志: ${GAUSSLOG}/cm/cm_server/cm_server_创建时间.log
关键词:bigger than 70%

内存使用率超过70%导致cms查杀,此阈值可以通过usage_threshold参数调整
解决方案:可依照以下链接的方式初步排查,联系华为工程师
内存定位三板斧:
https://bbs.huaweicloud.com/forum/thread-110215-1-1.html
[5]故障类型:内存不足导致系统的oom查杀
关键日志: /var/log/message
关键词:oom-killer

oom_killer(out of memory killer)是Linux内核的一种内存管理机制,在系统可用内存较少的情况下,内核为保证系统还能够继续运行下去,会选择杀掉一些进程释放掉一些内存。通常oom_killer的触发流程是:进程A想要分配物理内存(通常是当进程真正去读写一块内核已经“分配”给它的内存)→触发缺页异常→内核去分配物理内存→物理内存不够了,触发OOM。
解决方案:可依照以下链接的方式初步排查后,联系华为工程师
内存定位三板斧:
https://bbs.huaweicloud.com/forum/thread-110215-1-1.html
[6]故障类型:主线程postmaster收到fast shutdown
关键日志:
DN:${GAUSSLOG}/pg_log/dn_xxxx /postgresql-创建时间.log
CN:${GAUSSLOG}/pg_log/cn_xxxx /postgresql-创建时间.log
关键词:fast shutdown

主进程下发cancel信号导致实例退出。
解决方案:
检查${GAUSSLOG}/bin/gs_ctl/gs_ctl-创建时间.log

若存在stop操作,说明存在手动关闭实例的情况。
若不存在stop操作,请联系华为工程师。
[7]故障类型:core
首先需要确认是否配置core:

没有配置的话需要先行配置。OS core配置教程如下:
DWS-纯软core配置方案:
https://bbs.huaweicloud.com/forum/thread-182036-1-1.html
DWS-HC/HCS/HCSO配core方案:
https://bbs.huaweicloud.com/forum/thread-181948-1-1.html
请注意:core配置完成需要重启集群生效,请预留时间窗口,防止影响业务。
如果配置完成,但是异常的实例目录下不存在core文件检查bbox_core的开启情况以及生成目录:
show enable_bbox_dump;
show bbox_dump_path;

如果bbox_core开启且目录与实例目录不一致,到此目录下查看core文件是否存在。确认core文件存在后联系华为工程师。
3.3集群状态异常
[1]主备不均衡
DWS-纯软主备均衡:
https://bbs.huaweicloud.com/forum/thread-145786-1-1.html
DWS-HC/HCS/HCSO主备均衡:
https://bbs.huaweicloud.com/forum/thread-150166-1-1.html
集群均衡失败:
https://bbs.huaweicloud.com/blogs/203410
若执行以上步骤未成功,请联系华为工程师
[2]集群降级
DWS-纯软gs_replace修复实例:
https://bbs.huaweicloud.com/forum/thread-145788-1-1.html
DWS- HC/HCS/HCSO gs_replace修复实例:
https://bbs.huaweicloud.com/forum/thread-150101-1-1.html
若执行以上步骤未成功,请联系华为工程师
[3]集群不可用
互信丢失导致集群不可用:
https://bbs.huaweicloud.com/forum/thread-122604-1-1.html
磁盘使用率达100%导致集群不可用:
https://bbs.huaweicloud.com/forum/thread-89229-1-1.html
集群不可用,实例状态处于Promoting状态:
https://bbs.huaweicloud.com/forum/thread-116077-1-1.html
不符合以上场景,请联系华为工程师。
可选应急操作:
DWS-纯软重启集群:
https://bbs.huaweicloud.com/forum/thread-147701-1-1.html
DWS- HC/HCS/HCSO重启集群:
https://bbs.huaweicloud.com/forum/thread-150174-1-1.html
[4]集群只读
磁盘使用率相关问题定位:
https://bbs.huaweicloud.com/forum/thread-59485-1-1.html
不符合以上场景,请联系华为工程师。

- 点赞
- 收藏
- 关注作者
评论(0)