SkyPilot:构建在多云之上的 ML 和数据科学,可节约 3 倍以上成本

作者:Zongheng Yang(在加州大学伯克利分校研发 SkyPilot)
整理:高现起
导读:用于 ML 和数据科学的云计算已经比较困难,如果你想要通过成本优化削减成本,你的整体成本包括资源和人力,可能会不降反增。不想在机器闲置时停止?因为这样你可能需要反复的启停,并且重新配置环境或者准备数据。想要通过使用抢占实例降低成本?解决抢占实例的调度问题也可能会花上几周时间。如何很好的利用地区之间的巨大价格差异,或者不同云厂商之间更大的价格差异来降低成本?
如果云上有一个简单、统一的 ML 和数据科学接口,具有成本效益、容错性、多区域和多云,是不是会更好?今天就给大家介绍一个项目,会从以下几个方面展开:
- SkyPilot 项目介绍
- SkyPilot 工作原理
- SkyPilot 使用场景为什么多云成为新常态?
- 尝试 SkyPilot
以下为详细内容。
SkyPilot 项目介绍
SkyPilot,由加州大学伯克利分校的 Sky Computing 实验室主导研发的一个开源框架,用于在任何云上无缝且经济高效地运行 ML 和数据科学批处理作业。它的目标是让云比以往任何时候都更容易使用,成本更低,并且全程不需要云计算相关的专业知识。

近一年多来,SkyPilot 一直在加州大学伯克利分校的天空计算实验室积极开发。它被 10 多个组织用于各种用例,包括:GPU/TPU 模型训练(成本节省 3 倍)、分布式超参数调优以及 100 多个 CPU 抢占实例上的生物信息学批处理作业(在持续使用的基础上成本节省 6.5 倍)。
SkyPilot 工作原理
给定一个作业及其资源需求(CPU/GPU/TPU),SkyPilot 会自动找出哪些位置(可用区/区域/云厂商)具有运行该作业的计算能力,然后将其发送到成本最低的位置执行。
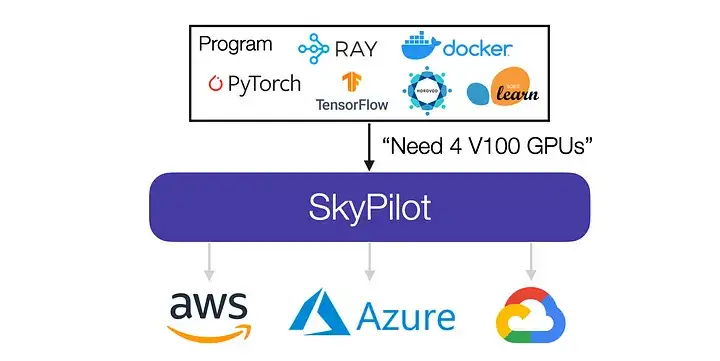
SkyPilot 将作业发送到最佳位置(可用区、区域、云厂商)以获得更好的价格和性能。
SkyPilot 自动执行云上正在运行的作业的繁重工作:
- 可靠地配置集群,如果发生容量或配额错误,自动故障转移到其他位置
- 将用户代码和文件(从本地或云存储桶)同步到集群
- 管理作业排队和执行
SkyPilot 还大大减少了不断增长的云费用,通常减少 3 倍以上:
- 自动找到所需资源的最便宜的可用区/区域/云厂商(节省约 2 倍的成本)
- Managed Spot,通过使用抢占实例节省约 3-6 倍的成本,并自动从抢占中恢复
- Autostop,自动清理空闲集群——可避免的云超支的最大贡献者
SkyPilot 的使用场景
在过去的几个月里,逐渐向来自 10 多个组织的数十名 ML/数据科学从业者和研究人员推荐了 SkyPilot。从用户反馈中,看到该系统确实解决了他们遇到的常见痛点。
出现了几种使用场景,从交互式开发到跨区域或跨云厂商运行许多的项目,再到横向扩展:

SkyPilot 已被用于交互式开发(例如,运行 Jupyter 的 CPU 服务器)、管理许多项目(可以在不同的云厂商)或扩展数百个作业。
在 GPU 和 TPU 上进行 ML 训练和超参数调整
伯克利人工智能研究所 ( BAIR ) 和斯坦福大学的领先机器学习团队一直在使用 SkyPilot 在云端运行机器学习训练。用户通常在不更改代码的情况下启动他们现有的 ML 项目。可靠地配置 GPU 实例、在集群上排队许多作业以及同时运行约 100 个超参数试验是用户反馈的主要优点。此外,用户在 AWS 上运行的相同作业只需更改一个参数就可以在 GCP/Azure 上运行。
用户还使用 SkyPilot 在谷歌的 TPU 上训练大模型。研究人员可以通过 TRC 程序申请免费的 TPU 访问权限,然后使用 SkyPilot 快速上手 TPU。
CPU 抢占实例上的生物信息学批处理作业,成本节省 6.5 倍
生物研究所 Salk 的科学家们一直在使用 SkyPilot 在抢占实例上运行每周定期执行的批处理作业任务。这些作业分别操作序列的不同部分,之前一直以一种令人尴尬的情况并行。使用 SkyPilot 的 Managed Spot 功能之后,Salk 的科学家们可以在数百个 CPU 抢占实例上进行计算,与使用按需实例相比成本降低了 6.5 倍,并且与使用繁忙的本地集群相比显著缩短了任务处理时间。Salk 用户反馈到,通过抽象化云计算技术,SkyPilot 让他们能够更专注于科学研究而非云端技术细节问题。
使用 SkyPilot 构建基于多云的应用
一些行业合作伙伴已经在 SkyPilot 的 API 之上构建了更多云厂商的 lib 库。SkyPilot 使更多应用从第一天起就可以使用与云厂商无关的界面在不同的云上运行(这与 Terraform 等工具形成对比,后者虽然功能强大,但专注于较低级别的基础设施而不是作业,并且需要特定于云厂商的模板)。开发人员喜欢开箱即用地在不同云厂商可靠地配置和运行作业的能力,这样他们就可以专注于应用的业务逻辑,而不是熟悉各个云厂商的功能操作。
为什么多云成为新常态?
多云和多区域的增长趋势促使构建了 SkyPilot。出于战略原因,企业组织越来越多地使用多个公有云,例如更高的可靠性、避免云供应商锁定、更强的议价能力等。
即使从用户(例如,机器学习工程师或数据科学家)的角度来看,也有很多理由可以根据工作负载使用多云:
减少开支
使用相同/相似硬件的最优惠价格的云厂商可以自动节省大量成本。以 GPU 为例。在 2022 年底时,Azure 拥有最便宜的 NVIDIA A100 GPU 实例,GCP 和 AWS 分别收取 8% 和 20% 的溢价。
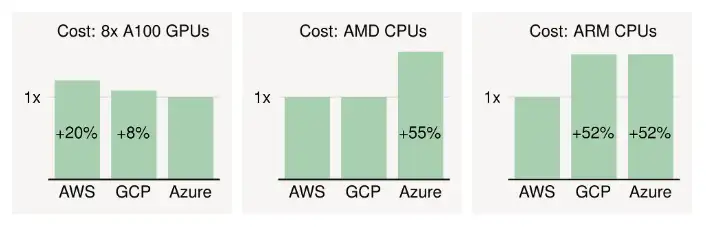
相同配置硬件的云价格差异。每个云最便宜区域的按需价格。
CPU 也存在价格差异。对于最新的通用实例(相同的 vCPU/内存),差异可能超过 50%(见上图)。
利用一流的硬件
正处于计算机体系结构的新黄金时代,专用硬件正在推动性能和效率的大幅提升。毫不奇怪,云厂商越来越多地提供定制硬件以从竞争中脱颖而出。例子包括:
- GCP 用于高性能 ML 训练的 TPU
- 用于经济高效的 ML 推理的 AWS Inferentia 和用于 CPU 工作负载的 Graviton 处理器
- 用于机密计算的 Azure 英特尔 SGX
使用更适合工作负载的硬件,可以显著的降低成本或提高性能,一般这些硬件位于不同的云厂商那里。
增加稀缺资源的可用性
理想的云实例很难获得。使用 NVIDIA V100 和 A100 等高端 GPU 的按需实例经常售罄。具有 GPU 或大量 CPU 的抢占实例甚至几乎不可能获得。根据经验,一般需要等待几小时或者几天的时间才能获取这些稀缺资源。
为了提高成功获取此类资源的机会,一种自然的方法是使用多云。(假设每个云有 40% 的机会提供资源;使用 3 个云将机会增加到 1–0.6³ = 78%。)
单云用户也想要多个区域
有趣的是,上述所有好处也都适用于单云的多个区域:
(1) 不同可用区/区域的价格差异也很大。对于普通的 GPU/CPU,跨区按需价格差异可能高达20%(见下图)。对于现货实例,价格差异很容易超过 3 倍。简单地说:用户可以通过在同一个云厂商跨多个可用区/区域购买来降低成本。
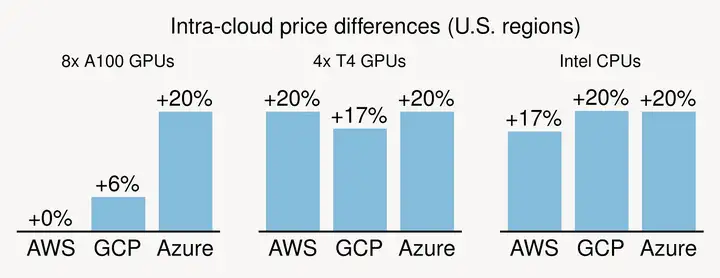
云内价格差异。(“+20%”表示最贵的区域收费是最便宜的区域的 1.2 倍。)
(2) 硬件/服务产品因云区域而异。例如,GCP 的 TPU V3 仅在其 35 个全球区域中的 2 个区域可用。
(3) 分散从多个区域获取稀缺资源更容易成功。
尝试 SkyPilot
项目地址:https://github.com/skypilot-org/skypilot
以上是文章的主要内容,作为融合云/多云管理/私有云/FinOps 厂商,云联壹云会持续关注这些领域的动态,分享相关的信息和技术,可以通过的官网(yunion.cn)或关注的公众号(云联壹云)来获取最新的信息,感谢大家的时间。
原文地址:https://www.yunion.cn/article/html/20230515.html
其他推荐阅读

- 点赞
- 收藏
- 关注作者
评论(0)