EAST、PSENET TensorFlow GPU To Ascend 迁移记录

一、EAST网络介绍
EAST,An Efficient and Accurate Scene Text Detector:https://arxiv.org/abs/1704.03155v2
EAST做文本检测只需要两步:先是一个全卷积的网络直接产生一个字符或者文本行的预测(可以是旋转的矩形或者不规则四边形),然后通过NMS(Non-Maximum Suppression)算法合并最后的结果。
EAST网络是一个全卷积网络,主要有三部分:特征提取层,特征融合层,输出层。由于在一张图片中,各个文字大小不一,所以需要融合不同层次的特征图,小文字的预测需要用到底层的语义信息,大文字的预测要用到高层的语义信息。EAST网络结构图参考下图

二、PESNET
PSENET:Shape Robust Text Detection with Progressive Scale Expansion Network:https://arxiv.org/abs/1806.02559
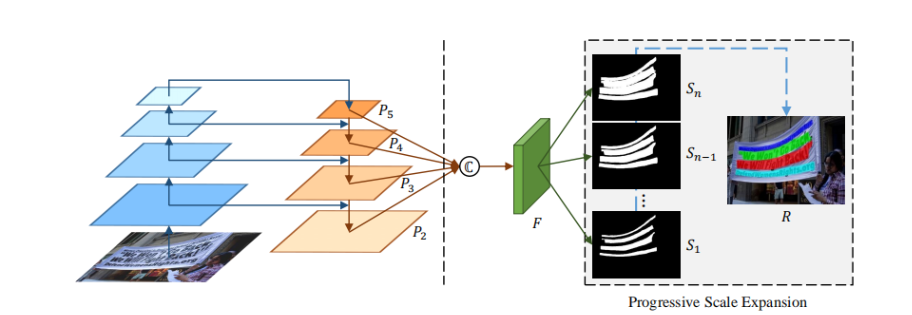
通常OCR中,文字检测都是由目标检测继承而来,目标检测大多都是基于先验框的(anchor base),近期出现的no-anchor模式本质上也是基于先验框的。anchor-base模式在目标检测衍生到OCR领域就有很多缺陷,比如:倾斜(或扭曲)文字检测不准、过长文字串检测不全、过短文字串容易遗漏、距离较近的无法分开等缺点。近期,渐进式扩展网络(PSENet)横空出世,以另一种思路解决了这些问题,下面我们来梳理一下该模型,不妥之处敬请指正。
PSENet是一种新的实例分割网络,它有两方面的优势。 首先,psenet作为一种基于分割的方法,能够对任意形状的文本进行定位.其次,该模型提出了一种渐进的尺度扩展算法,该算法可以成功地识别相邻文本实例。
三、数据集
ICDAR2015:从官网下载可以比较慢,这篇帖子里面有百度网盘的下载地址:https://blog.csdn.net/weixin_45779880/article/details/105642393
四、PSENET和EAST GPU To Ascend迁移代码修改详解
因为PSENET和EAST两个网络使用的数据集是相同的,代码也差不多,修改的地方也差不多,应该只需要两步就可以运行起来了。所以这两个网络的迁移就合并在一起写了
第一步:根据迁移手册:https://support.huaweicloud.com/ug-tf-training-tensorflow/atlasmprtg_13_0006.html 修改train.py文件进行sess.run的迁移
#引入包 from npu_bridge.estimator import npu_ops from tensorflow.core.protobuf.rewriter_config_pb2 import RewriterConfig
config = tf.ConfigProto(allow_soft_placement=True) custom_op = config.graph_options.rewrite_options.custom_optimizers.add() custom_op.name = "NpuOptimizer" custom_op.parameter_map["use_off_line"].b = True # 必须显示开启,在昇腾AI处理器执行训练 config.graph_options.rewrite_options.remapping = RewriterConfig.OFF # 必须显示关闭remap with tf.Session(config=config) as sess: #在这一行之前加入上面一代代码
第二步:因为数据集中的文本文件比图片文件多一个GT_前缀,所以我们需要修改一下读取数据集的代码
east为icdar.py文件
psenet网络为/utils/data_provider/data_provider.py
file_path, file_name = os.path.split(im_fn)
txt_fn = file_path + '/gt_' + file_name.replace('jpg', 'txt')
#txt_fn = im_fn.replace(os.path.basename(im_fn).split('.')[1], 'txt') #将原来的这行代码替换为上面两行
EAST和psenet只需要这两步应该就可以将模型运行起来了
五、运行结果
运行命令:+ python npu_train.py --checkpoint_path=./checkpoint/ --text_scale=512 --training_data_path=/data/dataset/storage/icdar/ --geometry=RBOX --learning_rate=0.0001 --num_readers=24 --max_steps=200 --pretrained_model_path=./pretrain/resnet_v1_50.ckpt --save_checkpoint_steps=10 > train.log 2>&1
运行完成后执行cat train.log | grep loss 看一下loss的值如下图:


- 点赞
- 收藏
- 关注作者
评论(0)