ML之SL:监督学习(Supervised Learning)的简介、应用、经典案例之详细攻略

ML之SL:监督学习(Supervised Learning)的简介、应用、经典案例之详细攻略
目录
1、Model selection during prototyping phase
监督学习(Supervised Learning)的经典案例
参考文章:《2019中国人工智能发展报告》—清华大学中国工程院知识智能中心—201912
相关文章
ML之SL:监督学习(Supervised Learning)的简介、应用、经典案例之详细攻略
ML之UL:无监督学习Unsupervised Learning的概念、应用、经典案例之详细攻略
ML之SSL:Semi-Supervised Learning半监督学习的简介、应用、经典案例之详细攻略
监督学习(Supervised Learning)的简介
监督学习,是指利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程,也称为监督训练或有教师学习。
监督学习是从标记的训练数据来推断一个功能的机器学习任务。训练数据包括一套训练示例。在监督学习中,每个实例都是由一个输入对象(通常为矢量)和一个期望的输出值(也称为监督信号)组成。监督学习算法是分析该训练数据,并产生一个推断的功能,其可以用于映射出新的实例。一个最佳的方案将允许该算法来正确地决定那些看不见的实例的类标签。这就要求学习算法是在一种“合理”的方式从一种从训练数据到看不见的情况下形成。

监督学习中的数据集是有标签的,就是说对于给出的样本我们是知道答案的。如果机器学习的目标是通过建模样本的特征x和标签y之间的关系:f (x,θ)或p(y|x, θ),并且训练集中每个样本都有标签,那么这类机器学习称为监督学习。
1、监督学习问题的两大类—分类问题和回归问题
根据标签类型的不同,又可以将其分为分类问题和回归问题两类。前者是预测某一样东西所属的类别(离散的),比如给定一个人的身高、年龄、体重等信息,然后判断性别、是否健康等;后者则是预测某一样本所对应的实数输出(连续的),比如预测某一地区人的平均身高。我们大部分学到的模型都是属于监督学习,包括线性分类器、支持向量机等。
2、监督学习常见的算法
常见的监督学习算法有:k-近邻算法(k-Nearest Neighbors,kNN)、决策树(Decision Trees)、朴素贝叶斯(Naive Bayesian)等。
3、监督学习过程

1、Model selection during prototyping phase
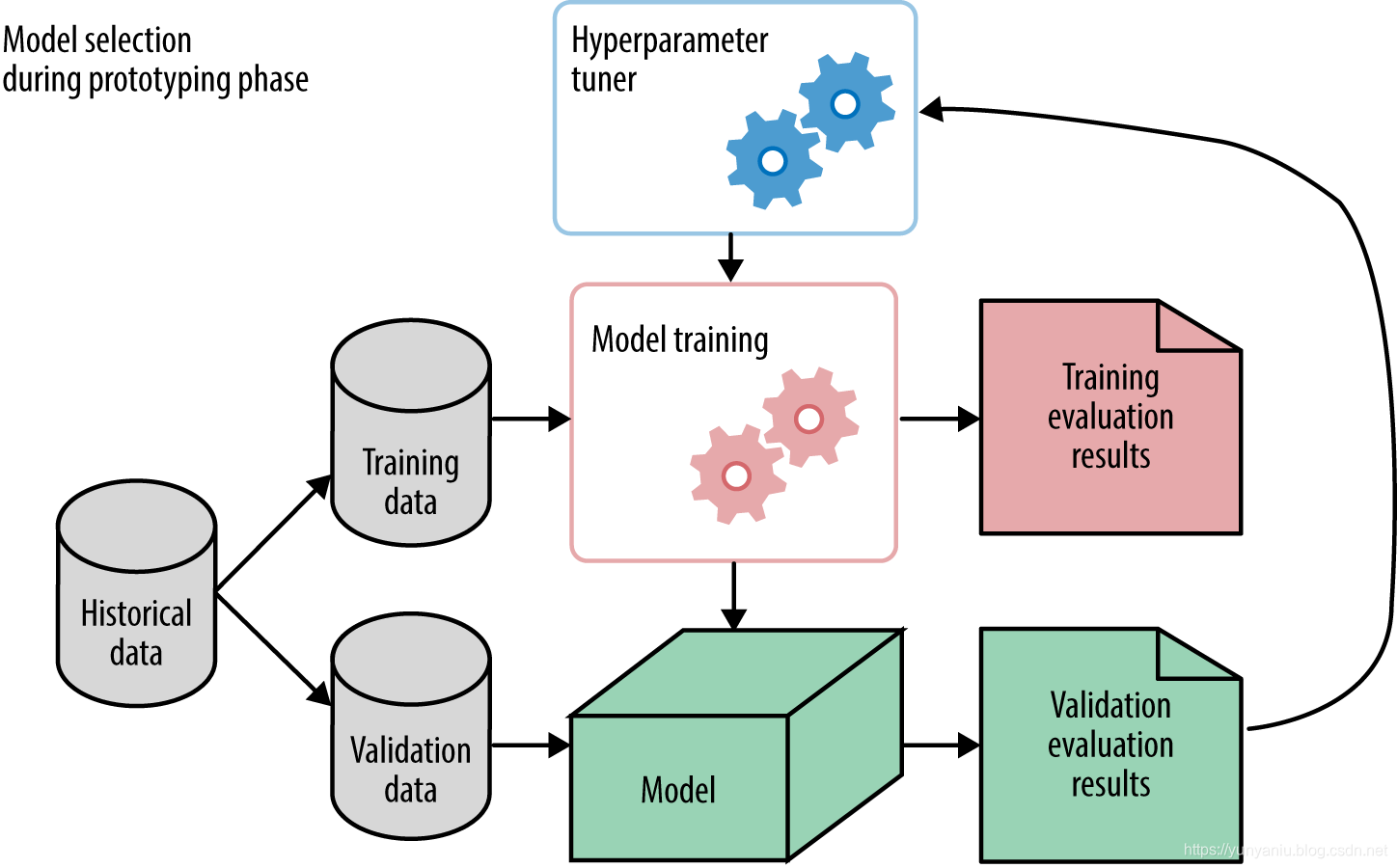
监督学习(Supervised Learning)的应用
1、监督学习、半监督学习和非监督学习之间的区别

可以看到,图2-7(a)中,红色三角形数据和蓝色圆点数据为标注数据;图2-7(b)中,绿色的小圆点为非标注数据。图2-7(c)显示监督学习将有标签的数据进行分类;而半监督学习如图2-7(d)中部分是有标签的,部分是没有标签的,一般而言,半监督学习侧重于在有监督的分类算法中加入无标记样本来实现半监督分类。
监督学习(Supervised Learning)的经典案例
本博客中,监督学习案例较多,自行查看即可。
文章来源: yunyaniu.blog.csdn.net,作者:一个处女座的程序猿,版权归原作者所有,如需转载,请联系作者。
原文链接:yunyaniu.blog.csdn.net/article/details/94771313

- 点赞
- 收藏
- 关注作者
评论(0)