情感分析之文本句内的“机械压缩”去重!

【摘要】 在做情感分析的时候,有时候需要对文本进行分词,做词频统计。上图是某个店铺的留言数据,对于第26条,只是为了说明“东西很好,很好用!”,但是为了凑字数留言,就写成了如图所示。但是我们在进行词频统计的时候,只统计“东西很好,很好用!”一次就够了,因此,就需要用到“数据的句内去重”。
目录
1、原理说明
2、“单字词”句内去重
3、“双字词”句内去重
4、“三字词”句内去重
5、将上述情况,封装成函数("三字词"以上句内去重)
1、原理说明
1)为什么要进行数据的句内去重?

在做情感分析的时候,有时候需要对文本进行分词,做词频统计。上图是某个店铺的留言数据,对于第26条,只是为了说明“东西很好,很好用!”,但是为了凑字数留言,就写成了如图所示。但是我们在进行词频统计的时候,只统计“东西很好,很好用!”一次就够了,因此,就需要用到“数据的句内去重”。
2)以“单字词”为例,进行原理说明
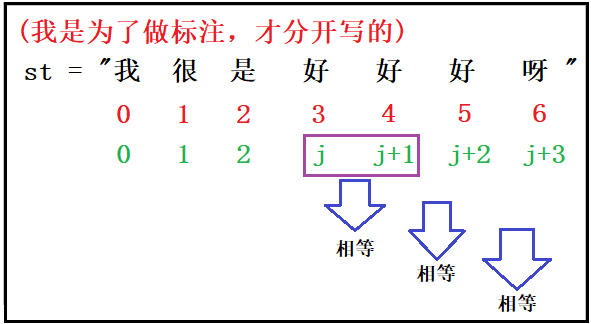
3)原理说明
通过上图可以发现,进行词语句内去重,首先判断位置j到j+1位置的元素是否相等,如果相等,再判断j+1处的元素和j+2处的元素是否相等,这样依次进行下去。
由于原理不好用语言,进行详细叙述,因此你可以好好琢磨一下下面的代码。对于不懂的地方,可以在博客中留言说明。
2、“单字词”句内去重
st = "我很是好好好好好好呀"
for j in range(len(st)):
if st[j:j+1] == st[j+1:j+2]:
k = j + 1
while st[k:k+1] == st[k+1:k+2] and k<len(st): # k<len(st)是为了退出这个while循环,否则一直循环
k = k + 1
st = st[:j] + st[k:]
st
结果如下:

3、“双字词”句内去重
st = "今天天气天气天气天气好哦"
for j in range(len(st)):
if st[j:j+2] == st[j+2:j+4]:
k = j + 2
while st[k:k+2] == st[k+2:k+4] and k<len(st):
k = k + 2
st = st[:j] + st[k:]
st
结果如下:

4、“三字词”句内去重
st = "我天气好天气好天气好哈"
for j in range(len(st)):
if st[j:j+3] == st[j+3:j+6]:
k = j + 3
while st[k:k+3] == st[k+3:k+6] and k<len(st):
k = k + 3
st = st[:j] + st[k:]
st
结果如下:

5、将上述情况,封装成函数
def func(st):
for i in range(1,int(len(st)/2)+1):
for j in range(len(st)):
if st[j:j+i] == st[j+i:j+2*i]:
k = j + i
while st[k:k+i] == st[k+i:k+2*i] and k<len(st):
k = k + i
st = st[:j] + st[k:]
return st
st = "我爱你我爱你我爱你好你好你好哈哈哈哈哈"
func(st)
结果如下:


【版权声明】本文为华为云社区用户原创内容,未经允许不得转载,如需转载请自行联系原作者进行授权。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)