【2023 · CANN训练营第一季】——Ascend C算子开发入门——第二次课(并行编程范式、流水线,任务间通信与同步)

前言:昇腾AI处理器的算子开发增加了一种新的方式,称之为TIK2,正式名称是Ascend C算子开发。不同于采用Python的DSL和TIK方式,Ascend C使用C/C++作为前端语言的算子开发工具,通过四层接口抽象、并行编程范式、孪生调试等技术,极大提高了算子的开发效率,助力AI开发者低成本完成算子开发和模型调优部署。为了帮助开发者快速掌握这一新的技术,2023 CANN训练营第一季同步开设了相关课程,总共有三节课。
本次是第二节课,讲述了流水线,任务间通信与同步,快速和标准两种算子开发模式,并讲述基于内核调用方式的快速开发流程的实例。
课程地址:CANN训练营2023年第一季_TIK2算子开发入门
https://www.hiascend.com/zh/developer/courses/detail/1627494761683783682
课程视频:发布在B站“昇腾Ascend”:
第1次课:【2023 CANN训练营第一季】-TIKC++算子开发入门(上)
https://www.bilibili.com/video/BV1ha4y1V7vK
第2次课:【2023 CANN训练营第一季】-TIKC++算子开发入门(中)
https://www.bilibili.com/video/BV1Pa4y157RG/
第3次课:【2023 CANN训练营第一季】-TIKC++算子开发入门(下)
https://www.bilibili.com/video/BV1yM411g7nw
技术文档:“文档首页>CANN社区版>6.3.RC2.alpha001>算子开发>TIK C++算子开发>TIK C++简介”https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/63RC2alpha001/operatordevelopment/tik2opdevg/atlastik2_10_0001.html
本次课的内容要点如下:

文档首页>CANN社区版>6.3.RC2.alpha001>算子开发>TIK C++算子开发>编程模型>编程范式>简介https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/63RC2alpha001/operatordevelopment/tik2opdevg/atlastik2_10_0009.html
TIK C++编程范式把算子内部的处理程序,分成多个流水任务( stage ),以张量( Tensor)为数据载体,以队列 ( Queue ) 进行任务之间的通信与同步,以内存管理模块( Pipe ) 管理任务间的通信内存.
一、流水任务
流水任务指的是单核处理程序中主程序调度的并行任务。在核函数内部,可以通过流水任务实现数据的并行处理,进一步提升性能。下面举例来说明,流水任务如何进行并行调度。以下面的流水任务示意图为例,单核处理程序的功能被拆分成3个流水任务:Stage1、Stage2、Stage3,每个任务专注于完成单一功能;需要处理的数据被切分成n片,使用Progress1~n表示,每个任务需要依次完成n个数据切片的处理。Stage间的箭头表达数据间的依赖关系,比如Stage1处理完Progress1之后,Stage2才能对Progress1进行处理。
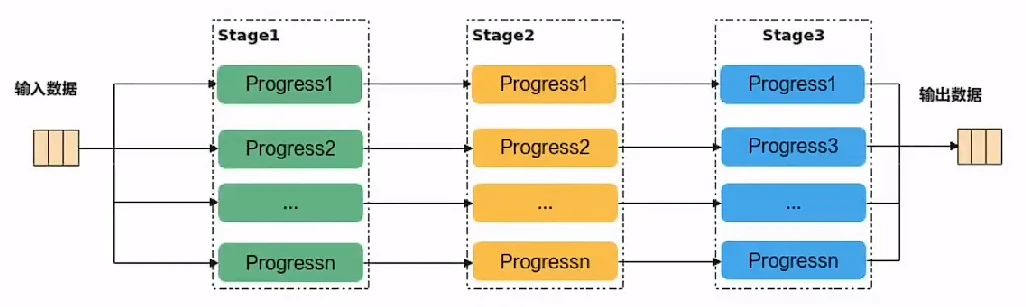
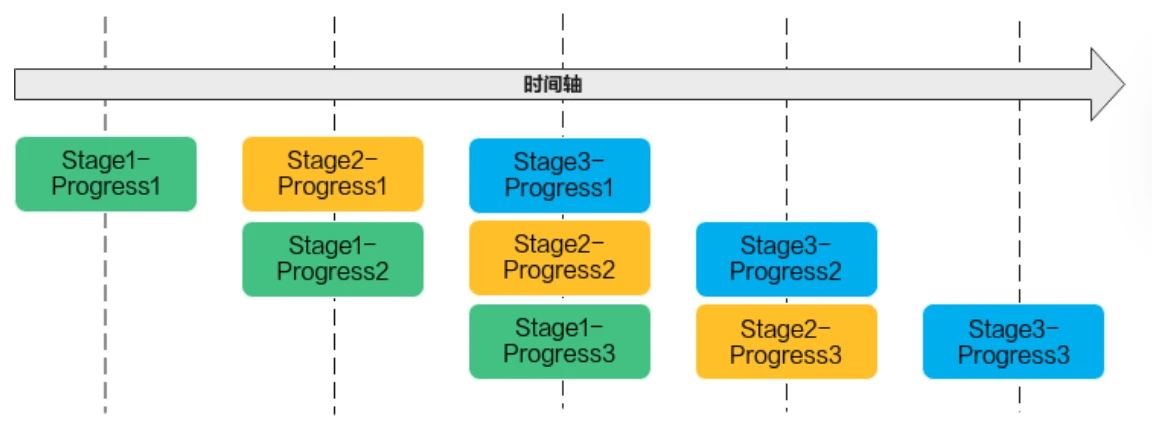
若n=3,即待处理的数据被切分成3片,则上图中的流水任务运行起来的示意图如下,从运行图中可以看出,对于同一片数据,Stage1、Stage2、Stage3之间的处理具有依赖关系,需要串行处理;不同的数据切片,同一时间点,可以有多个任务在并行处理,由此达到任务并行、提升性能的目的。
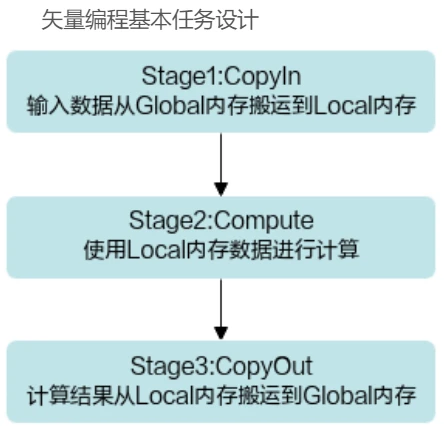
矢量(Vector)编程范式把算子的实现流程分为3个基本任务:CopyIn,Compute,CopyOut。CopyIn负责搬入操作,Compute负责矢量计算操作,CopyOut负责搬出操作。
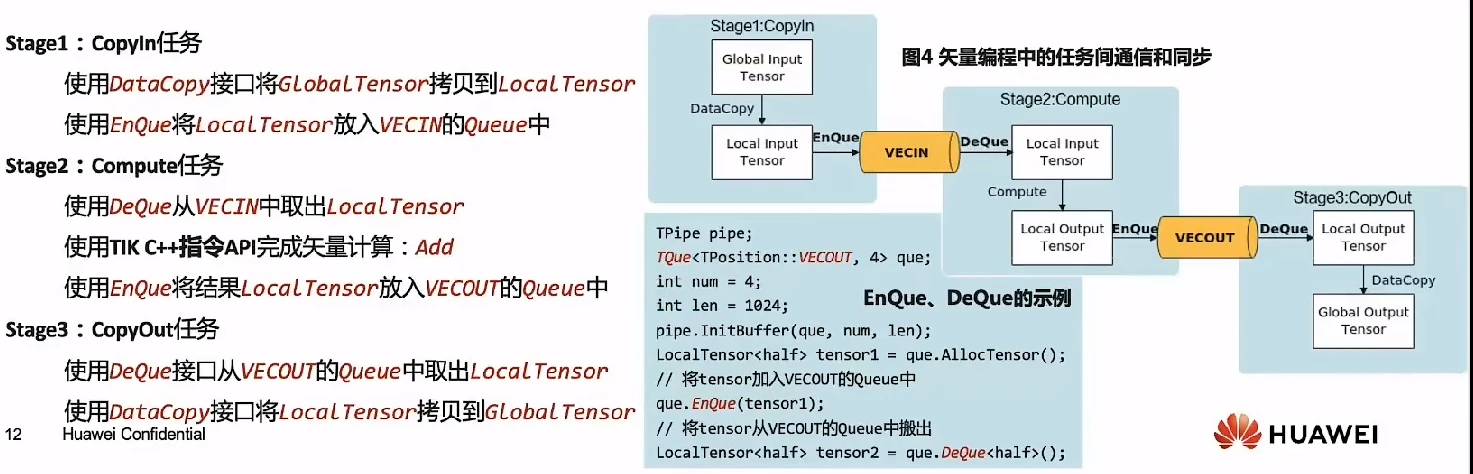
二、任务间通信与同步
1、数据通信与同步的管理者
不同的流水任务之间存在数据依赖,需要进行数据传递。Ascend C算子中使用Queue队列完成任务之间的数据通信和同步,提供EnQue、DeQue等基础API。Queue队列管理NPU上不同层级的物理内存时,用一种抽象的逻辑位置(QuePosition)来表达各级别的存储,代替了片上物理存储的概念,开发者无需感知硬件架构。
矢量编程中使用到的逻辑位置(QuePosition)定义如下:搬入数据的存放位置:VECIN;和搬出数据的存放位置:VECOUT。
矢量编程主要分为CopyIn、Compute、CopyOut三个任务:
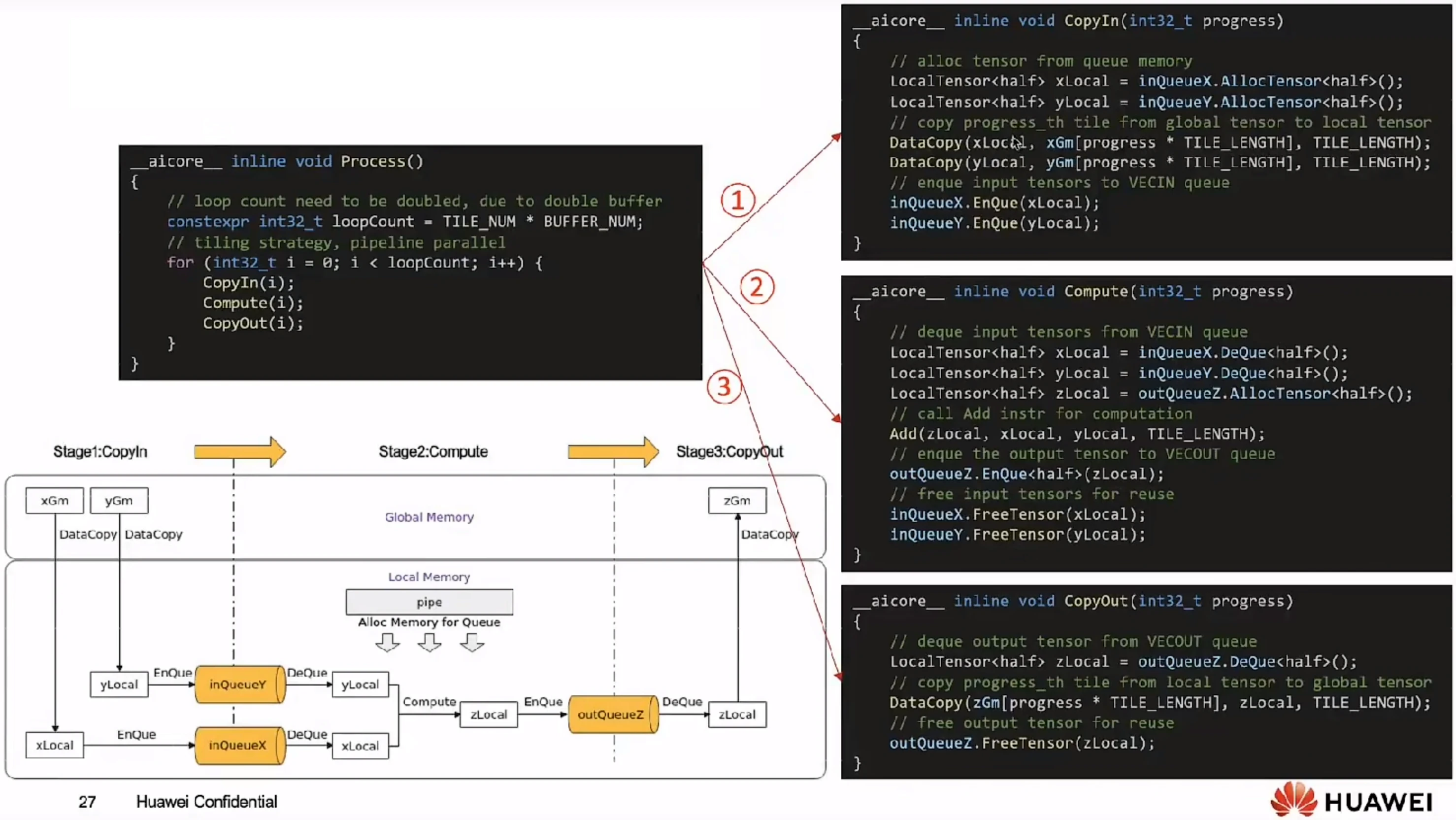
CopyIn任务中将输入数据从Global内存搬运至Local内存后,需要使用EnQue将LocalTensor放入VECIN的Queue中;
Compute任务等待VECIN的Queue中LocalTensor出队之后才可以完成矢量计算,计算完成后使用EnQue将计算结果LocalTensor放入到VECOUT的Queue中;
CopyOut任务等待VECOUT的Queue中LocalTensor出队,再将其拷贝到Global内存。
2、数据的载体
TIK C++使用GlobalTensor和LocalTensor作为数据的基本操作单元,它是各种指令API直接调用的对象,也是数据的载体。
三、内存管理机制
1、内存管理
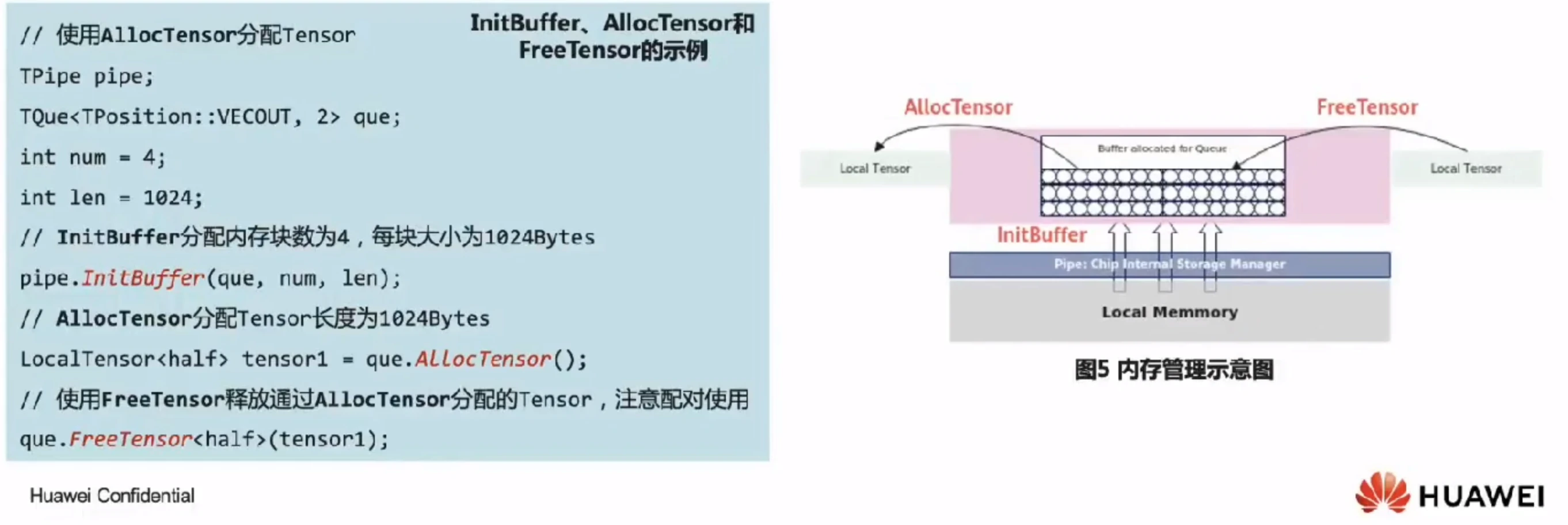
任务间数据传递使用到的内存统一由内存管理模块Pipe进行管理。Pipe作为片上内存管理者,通过InitBuffer接口对外提供Queue内存初始化功能,开发者可以通过该接口为指定的Queue分配内存。
Queue队列内存初始化完成后,需要使用内存时,通过调用AllocTensor来为LocalTensor分配内存,当创建的LocalTensor完成相关计算无需再使用时,再调用FreeTensor来回收LocalTensor的内存。
2、临时变量内存管理
编程过程中使用到的临时变量内存同样通过Pipe进行管理。临时变量可以使用TBuf数据结构来申请指定QuePosition上的存储空间,并使用Get()来将分配到的存储空间分配给新的LocaLTensor从TBuf上获取全部长度,或者获取指定长度的LocalTensor。

使用TBuf申请的内存空间只能参与计算,无法执行Queue队列的入队出队操作。
四、算子开发流程
一)算子开发流程
课程介绍了2种算子开发流程:快速开发和标准开发。
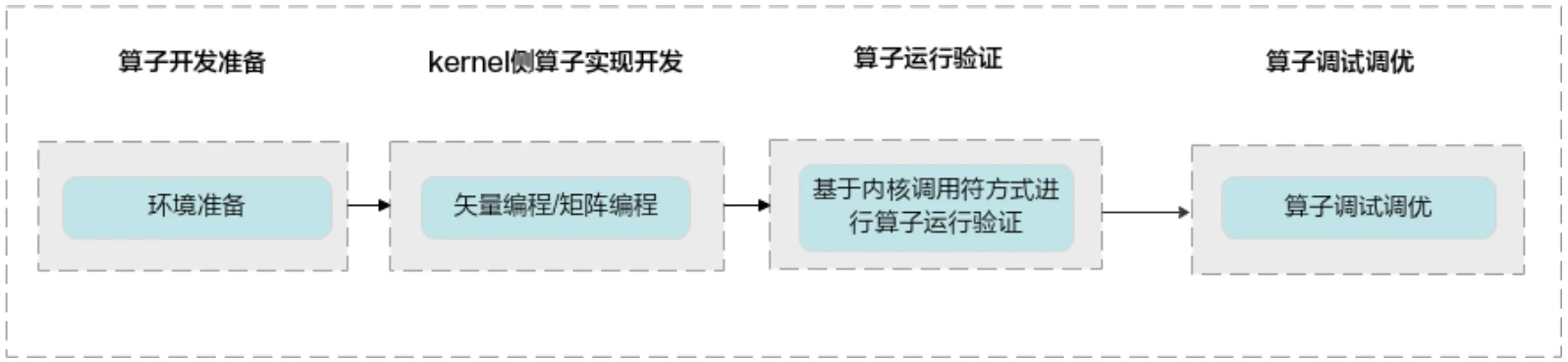
1、快速开发流程:完成kernel侧算子实现开发、通过内核调用符对算子进行调用验证
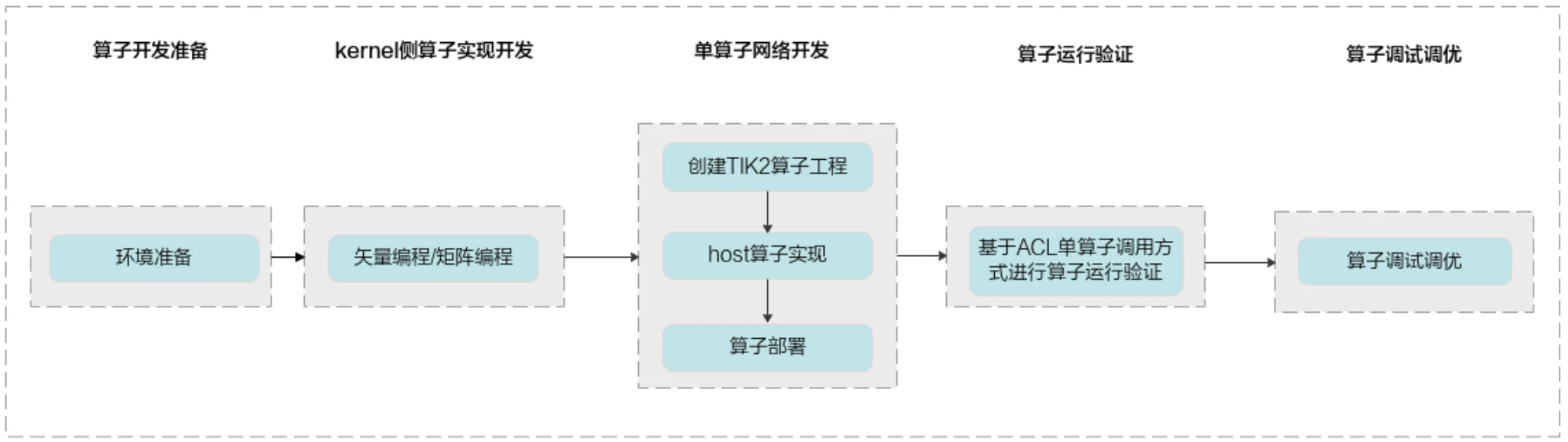
2、标准开发流程:完成kernel侧算子实现开发、host侧算子实现开发,对算子进行编译部署后,通过ACL单算子调用的方式,对算子进行运行验证。
快速开发模式和标准开发模式对比如下:

二)、Tik C++矢量算子的编程
矢量算子开发流程如下:
老师以add作为例子讲解了TIK C++矢量算子的快速开发流程。
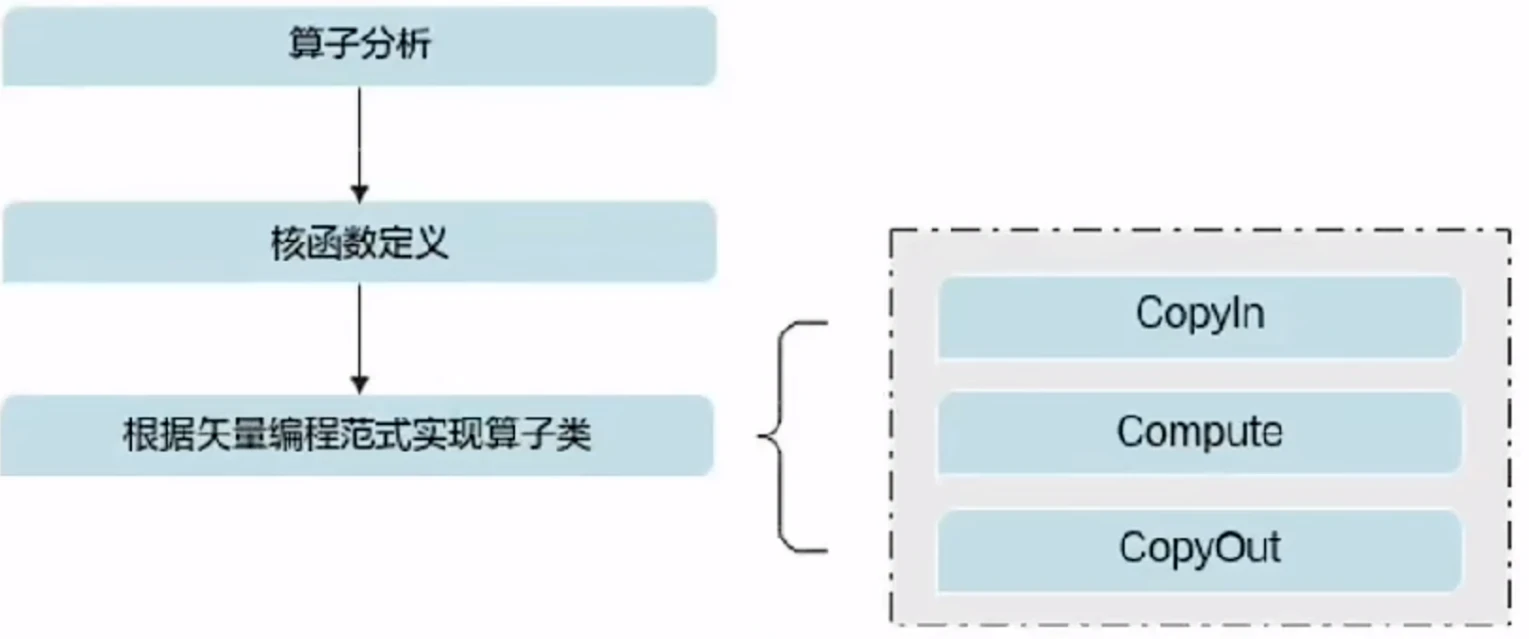
1、算子分析:分析算子的数学表达式、输入、输出以及计算逻辑的实现,明确需要调用的TIK C++接口。
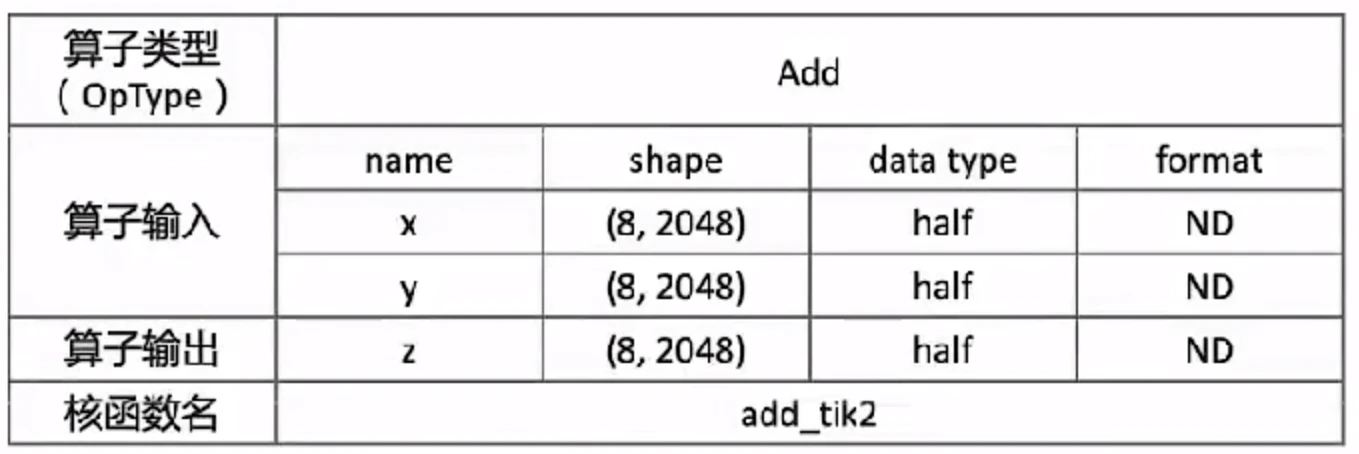
例子以Add算子为例,数学公式: ,为简单起见,设定输入张量x, y,z为固定shape(8,2048),数据类型dtype为half类型,数据排布类型format为ND,核函数名称为add_tik2。
,为简单起见,设定输入张量x, y,z为固定shape(8,2048),数据类型dtype为half类型,数据排布类型format为ND,核函数名称为add_tik2。
1)算子的数学表达式及计算逻辑
Add算子的数学表达式为:,
计算逻辑:输入数据需要先搬入到片上存储,然后使用计算接口完成两个加法运算,得到最终结果,再搬出到外部存储。
2)输入和输出
Add算子有两个输入:与,输出为。输入数据类型为half,输出数据类型与输入数据类型相同。输入支持固定shape(8,2048)输出shape与输入shape相同,输入数据排布类型为ND。
3)确定核函数名称和参数
自定义核函数名,如add_tik2。根据输入输出,确定核函数有3个入参x,y,z。
x,y为输入在Global Memory上的内存地址,z为输出在Global Memory上的内存地址。
4)确定算子实现所需接口
涉及内外部存储间的数据搬运,使用数据搬移接口:Datacopy实现;
涉及矢量计算的加法操作,使用矢量双目指令:Add实现;
使用到LocalTensor,使用Queue队列管理,会使用到EnQue、DeQue等接口。
2、核函数定义:
在add tik2核函数的实现中实例化kerneLAdd算子类,调用Init()数完成内存初始化,调用Process()函数完成核心逻。

3、根据矢量编程范式实现算子类
根据前面的知识,算子实现三个流水任务CopyIn、Compute、CopyOut。任务间通过队列VECIN、VECOUT进行通信和同步,由pipe内存管理对象对任务间交互使用到的内存、临时变量使用到的内存统一进行管理。如下图所示:
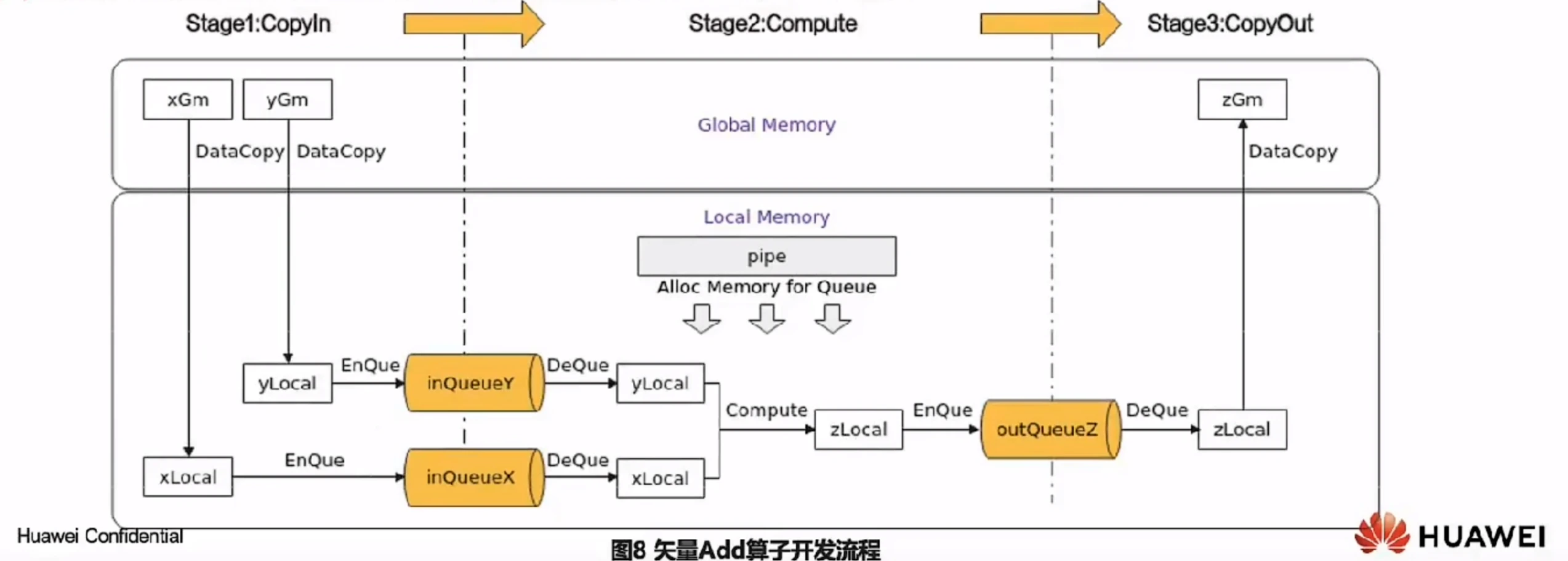
CopyIn任务:将Global Memory上的输入Tensor xGm和yGm搬运至Local Memory,分别存储在xLocal,yLocal;
Compute任务:对xLocal,yLocal执行加法操作,计算结果存储在zLocal中;
CopyOut任务:将输出数据从zLocal搬运至Global Memory上的输出Tensor zGm中
CopyIn,Compute任务间通过VECIN队列inQueuex,inQueuer进行通信和同步 compute,copyout任务间通过VECOUT队列outQueuez进行通信和同步
1)算子类定义
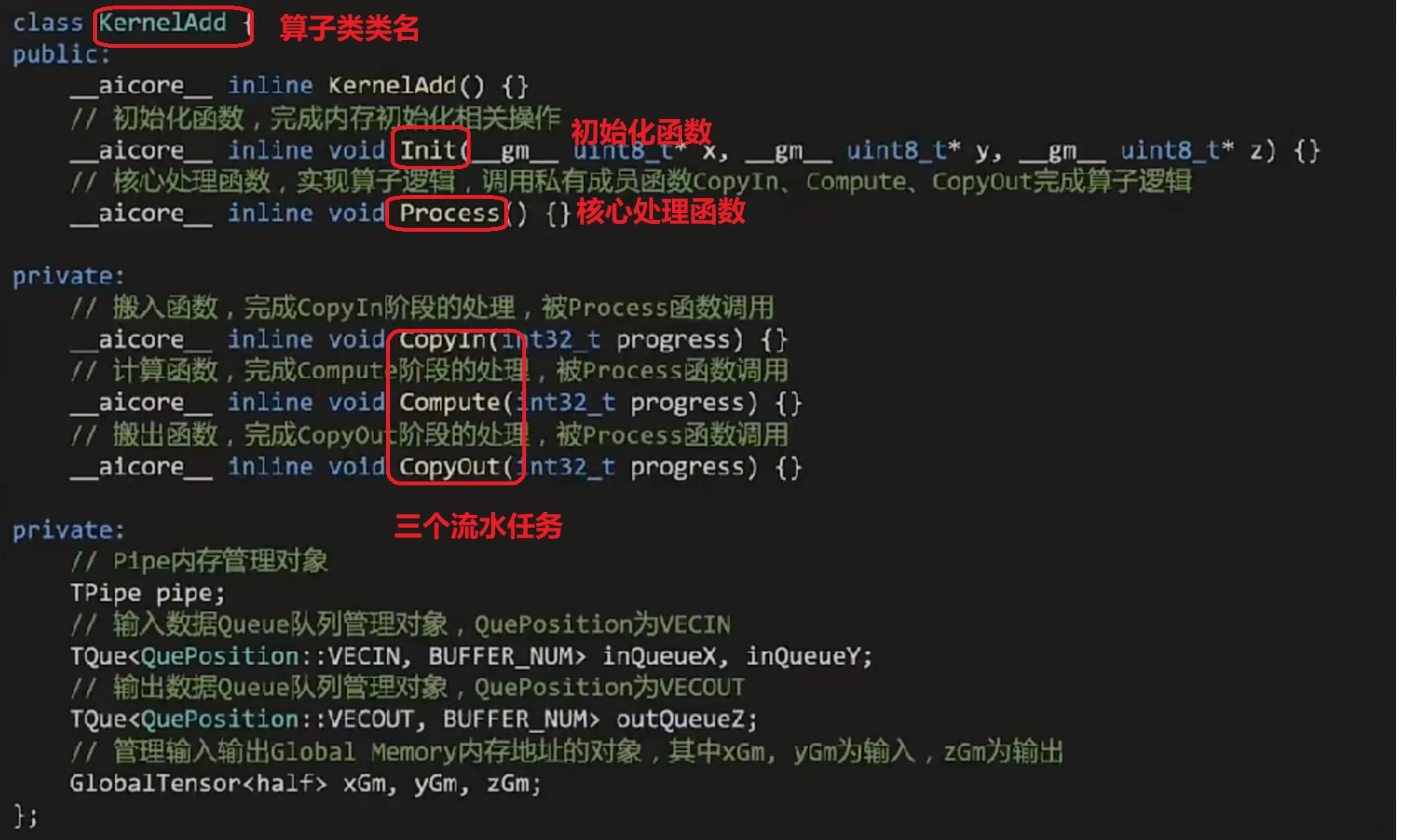
2)Init()函数实现:多核并行+单核处理数据

3)Process()函数的实现——CopyIn,Compute、CopyOut三个流水任务
4)double buffer机制
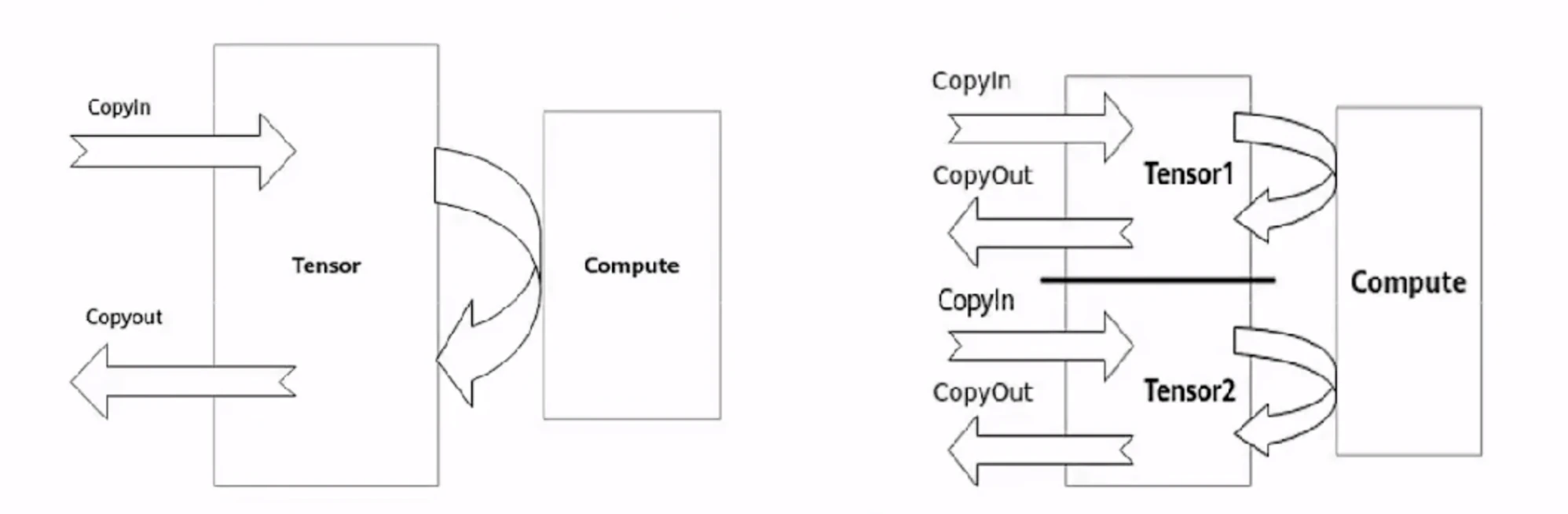
double buffer通过将数据搬运与矢量计算并行执行以隐藏数据搬运时间并降低矢量指令的等待时间,最终提高矢量计算单元的利用效率1个Tensor同一时间只能进行搬入、计算和搬出三个流水任务中的一个,其他两个流水任务涉及的硬件单元则处于ldle状态如果将待处理的数据一分为二,比如Tensor1、Tensor2:
当矢量计算单元对Tensor1进行Compute时,Tensor2可以执行CopvIn的任务
当矢量计算单元对Tensor2进行Compute时,Tensor1可以执行CopyOut的任务
当矢量计算单元对Tensor2进行CopyOut时Tensor1可以执行CopyIn的任务由此,数据的进出搬运和矢量计算之间实现并行,硬件单元闲置问题得以有效缓解
4、基于内核调用符方式验证
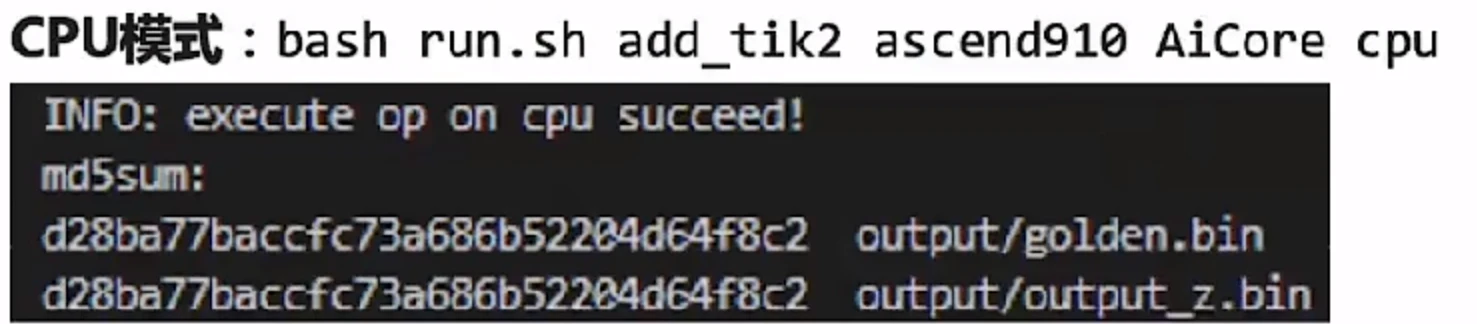
先使用python脚本生成x,y,并计算出z(golden)并落盘。然后再用相同的x,y,在cpu和npu模式下调用add算子,计算出结果z,并与python脚本采用计算md5sum的方式进行对比,完全一样,则表示结果正确。
为了运行方便,课程提供了一个run.sh,写有cpu和npu模式的编译命令,通过输入参数进行选择cpu或npu模式进行编译,运行。
1)CPU模式下:

运行结果:
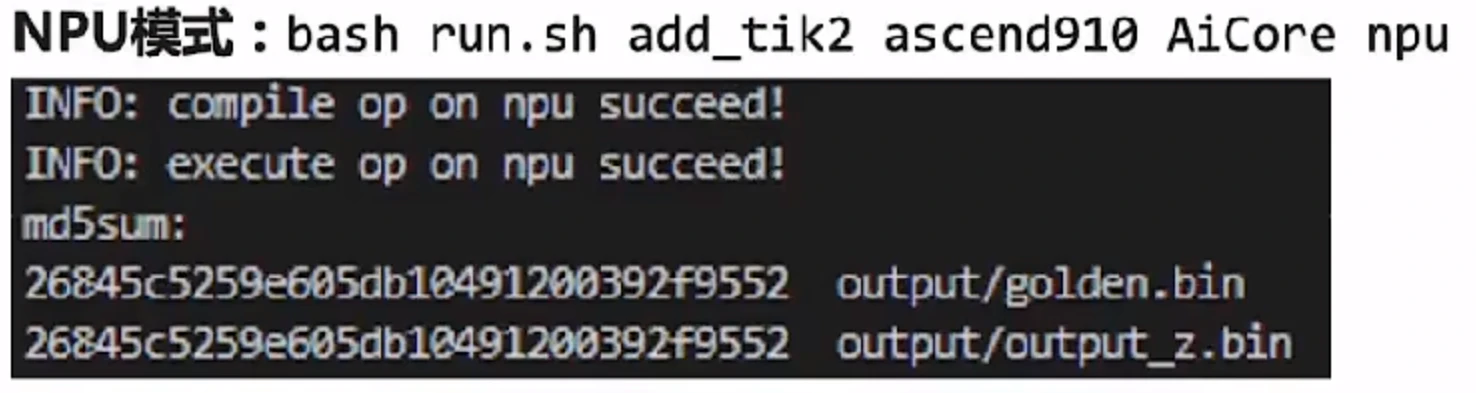
2)NPU模式下:
NPU模式使用<<<>>>方式调用,由于CPU模式g++没有<<<>>>的表达,需要使用内置宏 __CCE_KT_TEST。

运行结果如下:

- 点赞
- 收藏
- 关注作者
评论(0)