操作系统——内存管理

其他文章
操作系统——概述
操作系统——内存管理
操作系统——进程和线程
操作系统——进程间通信
操作系统——文件系统
操作系统——设备管理
操作系统——网络系统
虚拟内存
如果你是电子相关专业的,肯定在大学里捣鼓过单片机。
单片机是没有操作系统的,所以每次写完代码,都需要借助工具把程序烧录进去,这样程序才能跑起来。
另外,单片机的 CPU 是直接操作内存的「物理地址」。
在这种情况下,要想在内存中同时运行两个程序是不可能的。如果第一个程序在 2000 的位置写入一个新的值,将会擦掉第二个程序存放在相同位置上的所有内容,所以同时运行两个程序是根本行不通的,这两个程序会立刻崩溃。
操作系统如何解决这个问题呢?
这里关键的问题是这两个程序都引用了绝对物理地址,而这正是我们最需要避免的。
我们可以把进程所使用的地址「隔离」开来,即让操作系统为每个进程分配独立的一套「虚拟地址」,人人都有,大家自己玩自己的地址就行,互不干涉。但是有个前提每个进程都不能访问物理地址,至于虚拟地址最终怎么落到物理内存里,对进程来说是透明的,操作系统已经把这些都安排的明明白白了。

操作系统会提供一种机制,将不同进程的虚拟地址和不同内存的物理地址映射起来。
如果程序要访问虚拟地址的时候,由操作系统转换成不同的物理地址,这样不同的进程运行的时候,写入的是不同的物理地址,这样就不会冲突了。
于是,这里就引出了两种地址的概念:
- 我们程序所使用的内存地址叫做虚拟内存地址(Virtual Memory Address)
- 实际存在硬件里面的空间地址叫物理内存地址(Physical Memory Address)。
操作系统引入了虚拟内存,进程持有的虚拟地址会通过 CPU 芯片中的内存管理单元(MMU)的映射关系,来转换变成物理地址,然后再通过物理地址访问内存,如下图所示:
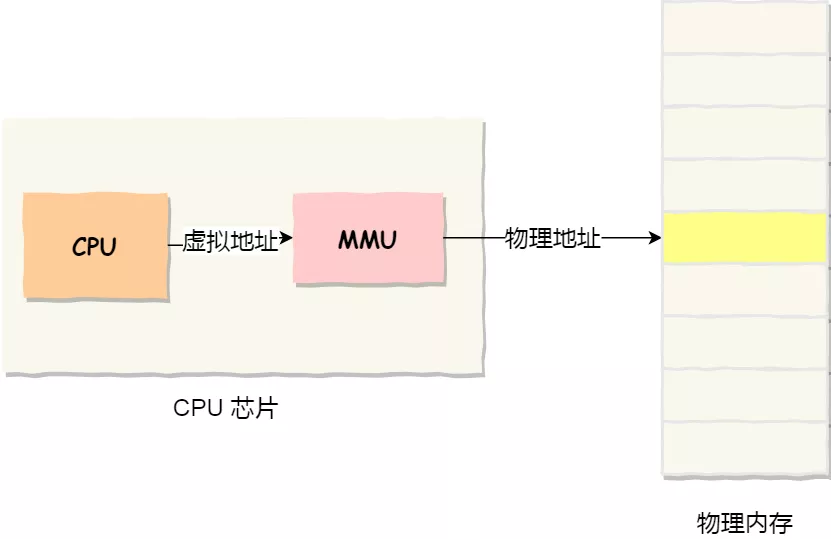
操作系统如何管理虚拟地址和物理地址之间的关系呢?
主要有两种方式,分别是内存分段和内存分页,分段是比较早提出的,我们先来看看内存分段。
内存分段
程序是由若干个逻辑分段组成的,如可由代码分段、数据分段、栈段、堆段组成。不同的段是有不同的属性的,所以就用分段(Segmentation)的形式把这些段分离出来。
分段机制下,虚拟地址和物理地址如何映射?
分段机制下的虚拟地址由两部分组成,段选择子和段内偏移量。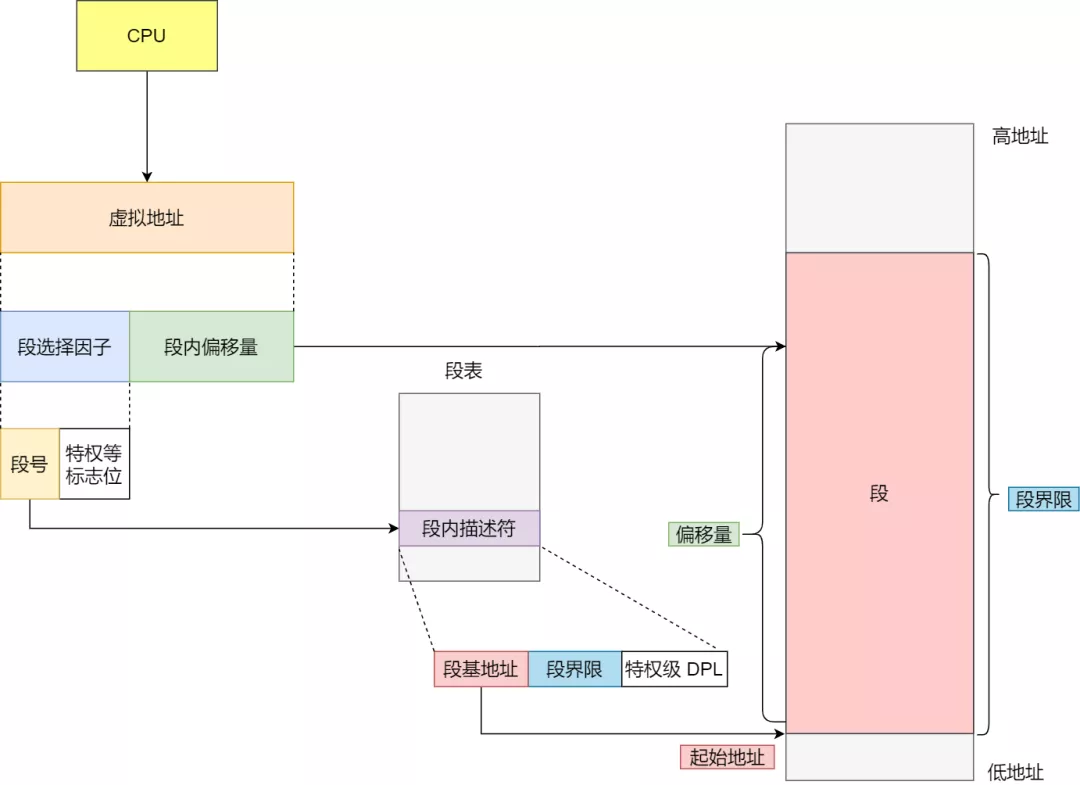
-
段选择子就保存在段寄存器里面。段选择子里面最重要的是段号,用作段表的索引。段表里面保存的是这个段的基地址、段的界限和特权等级等。
-
虚拟地址中的段内偏移量应该位于 0 和段界限之间,如果段内偏移量是合法的,就将段基地址加上段内偏移量得到物理内存地址。
在上面了,知道了虚拟地址是通过段表与物理地址进行映射的,分段机制会把程序的虚拟地址分成 4 个段,每个段在段表中有一个项,在这一项找到段的基地址,再加上偏移量,于是就能找到物理内存中的地址,如下图: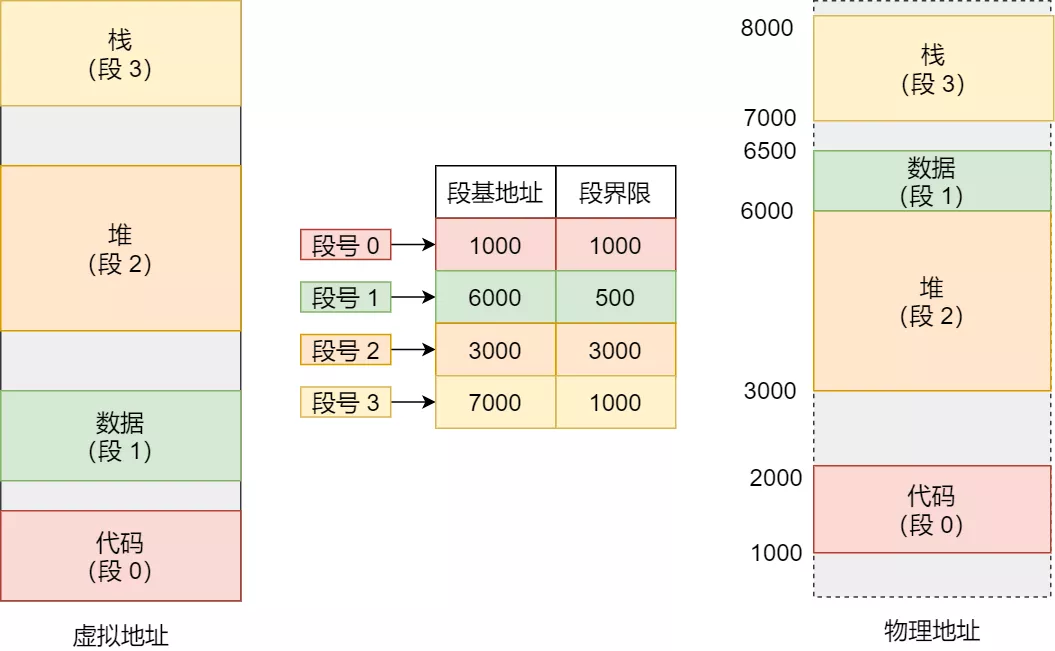
如果要访问段 3 中偏移量 500 的虚拟地址,我们可以计算出物理地址为,段 3 基地址 7000 + 偏移量 500 = 7500。
分段的办法很好,解决了程序本身不需要关心具体的物理内存地址的问题,但它也有一些不足之处:
- 第一个就是内存碎片的问题。
- 第二个就是内存交换的效率低的问题。
接下来,说说为什么会有这两个问题。
我们来看这样一个例子。我现在手头的这台电脑,有 1GB 的内存。我们先启动一个图形渲染程序,占用了 512MB 的内存,接着启动一个 Chrome 浏览器,占用了 128MB 内存,再启动一个 Python 程序,占用了 256MB 内存。这个时候,我们关掉 Chrome,于是空闲内存还有 1024 - 512 - 256 = 256MB。按理来说,我们有足够的空间再去装载一个 200MB 的程序。但是,这 256MB 的内存空间不是连续的,而是被分成了两段 128MB 的内存。因此,实际情况是,我们的程序没办法加载进来。
当然,这个我们也有办法解决。解决的办法叫内存交换(Memory Swapping)。
我们可以把 Python 程序占用的那 256MB 内存写到硬盘上,然后再从硬盘上读回来到内存里面。不过读回来的时候,我们不再把它加载到原来的位置,而是紧紧跟在那已经被占用了的 512MB 内存后面。这样,我们就有了连续的 256MB 内存空间,就可以去加载一个新的 200MB 的程序。如果你自己安装过 Linux 操作系统,你应该遇到过分配一个 swap 硬盘分区的问题。这块分出来的磁盘空间,其实就是专门给 Linux 操作系统进行内存交换用的。
虚拟内存、分段,再加上内存交换,看起来似乎已经解决了计算机同时装载运行很多个程序的问题。不过,你千万不要大意,这三者的组合仍然会遇到一个性能瓶颈。硬盘的访问速度要比内存慢很多,而每一次内存交换,我们都需要把一大段连续的内存数据写到硬盘上。所以,如果内存交换的时候,交换的是一个很占内存空间的程序,这样整个机器都会显得卡顿。
为了解决内存分段的内存碎片和内存交换效率低的问题,就出现了内存分页。
内存分页
分段的好处就是能产生连续的内存空间,但是会出现内存碎片和内存交换的空间太大的问题。
要解决这些问题,那么就要想出能少出现一些内存碎片的办法。另外,当需要进行内存交换的时候,让需要交换写入或者从磁盘装载的数据更少一点,这样就可以解决问题了。这个办法,也就是内存分页(Paging)。
分页是把整个虚拟和物理内存空间切成一段段固定尺寸的大小。这样一个连续并且尺寸固定的内存空间,我们叫页(Page)。在 Linux 下,每一页的大小为 4KB。
虚拟地址与物理地址之间通过页表来映射,如下图:
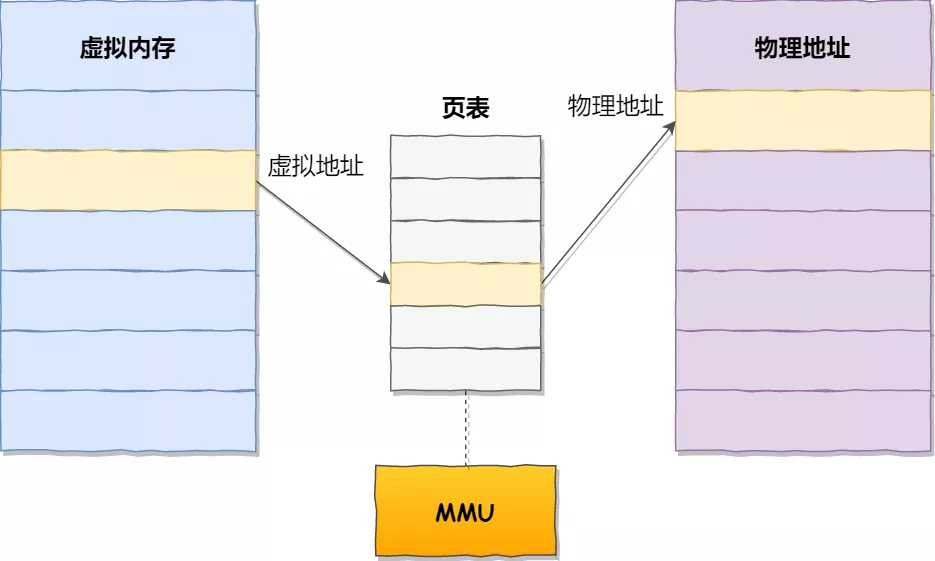
页表实际上存储在 CPU 的内存管理单元 (MMU) 中,于是 CPU 就可以直接通过 MMU,找出要实际要访问的物理内存地址。
而当进程访问的虚拟地址在页表中查不到时,系统会产生一个缺页异常,进入系统内核空间分配物理内存、更新进程页表,最后再返回用户空间,恢复进程的运行。
分页怎么解决分段的内存碎片、内存交换效率低的问题?
由于内存空间都是预先划分好的,也就不会像分段会产生间隙非常小的内存,这正是分段会产生内存碎片的原因。而采用了分页,那么释放的内存都是以页为单位释放的,也就不会产生无法给进程使用的小内存。
如果内存空间不够,操作系统会把其他正在运行的进程中的「最近没被使用」的内存页面给释放掉,也就是暂时写在硬盘上,称为换出(Swap Out)。一旦需要的时候,再加载进来,称为换入(Swap In)。所以,一次性写入磁盘的也只有少数的一个页或者几个页,不会花太多时间,内存交换的效率就相对比较高。
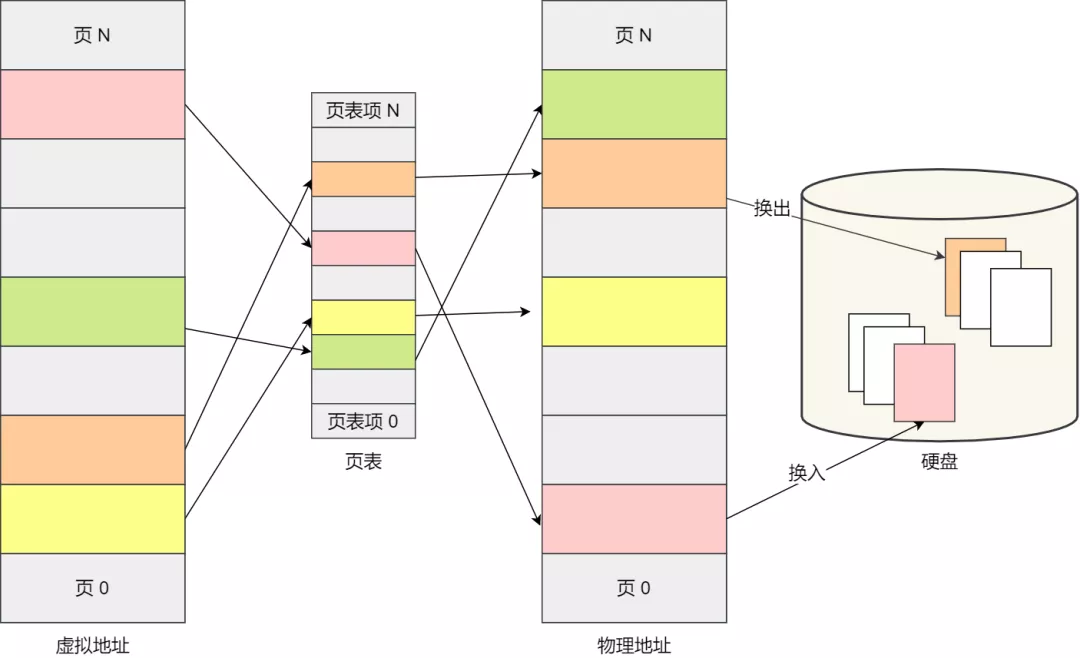
更进一步地,分页的方式使得我们在加载程序的时候,不再需要一次性都把程序加载到物理内存中。我们完全可以在进行虚拟内存和物理内存的页之间的映射之后,并不真的把页加载到物理内存里,而是只有在程序运行中,需要用到对应虚拟内存页里面的指令和数据时,再加载到物理内存里面去。
分页机制下,虚拟地址和物理地址是如何映射的?
在分页机制下,虚拟地址分为两部分,页号和页内偏移。页号作为页表的索引,页表包含物理页每页所在物理内存的基地址,这个基地址与页内偏移的组合就形成了物理内存地址,见下图。
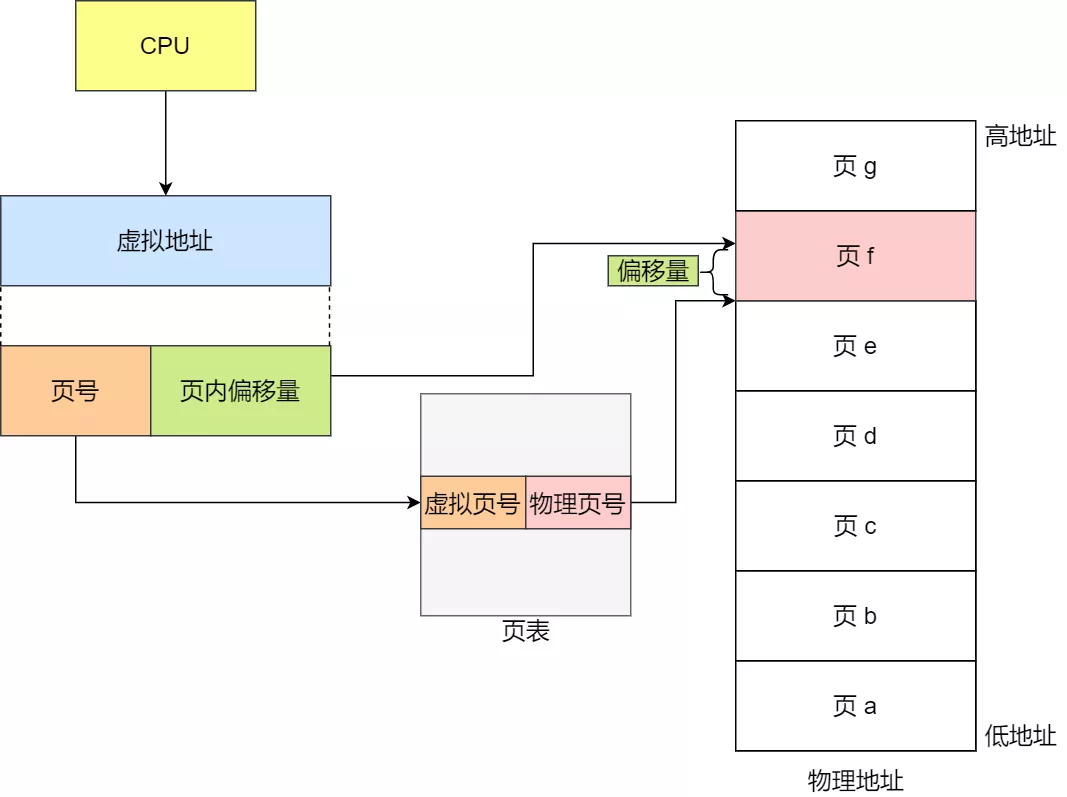
总结一下,对于一个内存地址转换,其实就是这样三个步骤:
- 把虚拟内存地址,切分成页号和偏移量;
- 根据页号,从页表里面,查询对应的物理页号;
- 直接拿物理页号,加上前面的偏移量,就得到了物理内存地址。
下面举个例子,虚拟内存中的页通过页表映射为了物理内存中的页,如下图: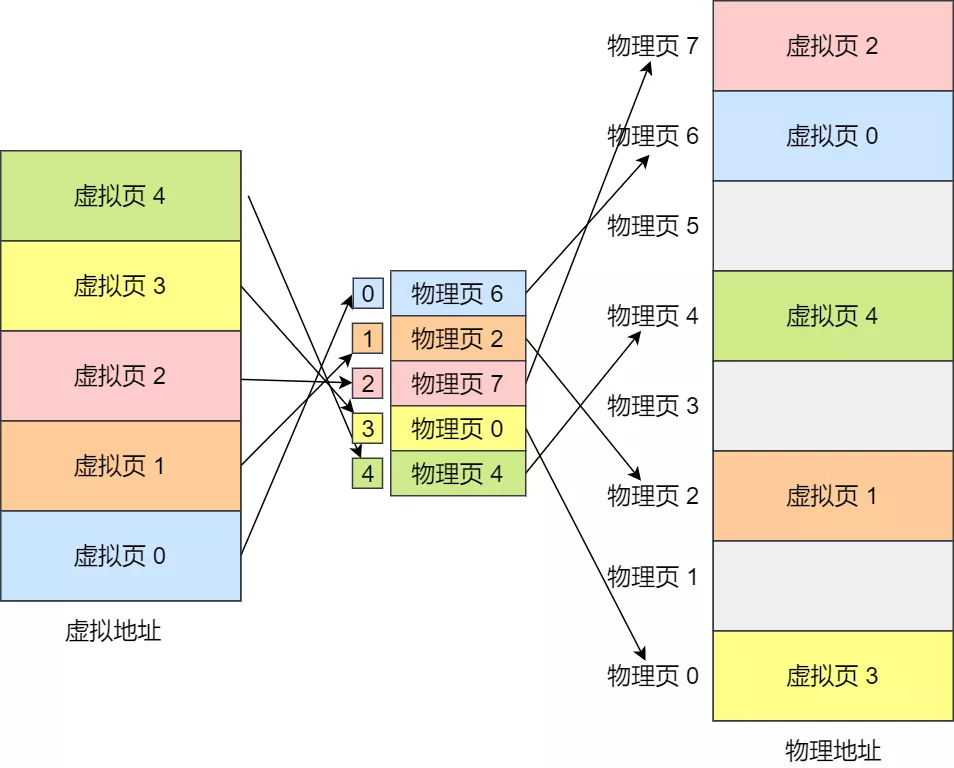
简单分页
简单的分页有什么缺陷呢?
有空间上的缺陷。
因为操作系统是可以同时运行非常多的进程的,那这不就意味着页表会非常的庞大。
在 32 位的环境下,虚拟地址空间共有 4GB,假设一个页的大小是 4KB(2^12),那么就需要大约 100 万 (2^20) 个页,每个「页表项」需要 4 个字节大小来存储,那么整个 4GB 空间的映射就需要有 4MB 的内存来存储页表。
这 4MB 大小的页表,看起来也不是很大。但是要知道每个进程都是有自己的虚拟地址空间的,也就说都有自己的页表。
那么,100 个进程的话,就需要 400MB 的内存来存储页表,这是非常大的内存了,更别说 64 位的环境了。
多级页表
要解决上面的问题,就需要采用的是一种叫作多级页表(Multi-Level Page Table)的解决方案。
在前面我们知道了,对于单页表的实现方式,在 32 位和页大小 4KB 的环境下,一个进程的页表需要装下 100 多万个「页表项」,并且每个页表项是占用 4 字节大小的,于是相当于每个页表需占用 4MB 大小的空间。
我们把这个 100 多万个「页表项」的单级页表再分页,将页表(一级页表)分为 1024 个页表(二级页表),每个表(二级页表)中包含 1024 个「页表项」,形成二级分页。如下图所示: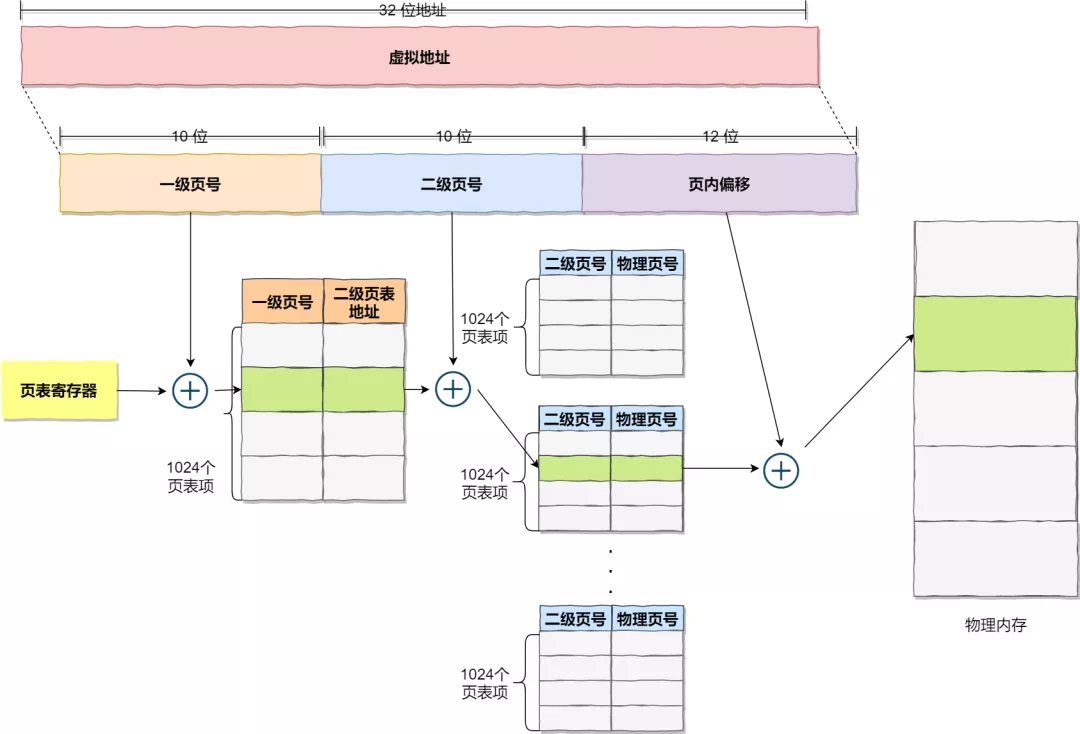
你可能会问,分了二级表,映射 4GB 地址空间就需要 4KB(一级页表)+ 4MB(二级页表)的内存,这样占用空间不是更大了吗?
当然如果 4GB 的虚拟地址全部都映射到了物理内上的,二级分页占用空间确实是更大了,但是,我们往往不会为一个进程分配那么多内存。
其实我们应该换个角度来看问题,还记得计算机组成原理里面无处不在的局部性原理么?
每个进程都有 4GB 的虚拟地址空间,而显然对于大多数程序来说,其使用到的空间远未达到 4GB,因为会存在部分对应的页表项都是空的,根本没有分配,对于已分配的页表项,如果存在最近一定时间未访问的页表,在物理内存紧张的情况下,操作系统会将页面换出到硬盘,也就是说不会占用物理内存。
如果使用了二级分页,一级页表就可以覆盖整个 4GB 虚拟地址空间,但如果某个一级页表的页表项没有被用到,也就不需要创建这个页表项对应的二级页表了,即可以在需要时才创建二级页表。做个简单的计算,假设只有 20% 的一级页表项被用到了,那么页表占用的内存空间就只有 4KB(一级页表) + 20% * 4MB(二级页表)= 0.804MB
,这对比单级页表的 4MB 是不是一个巨大的节约?
那么为什么不分级的页表就做不到这样节约内存呢?我们从页表的性质来看,保存在内存中的页表承担的职责是将虚拟地址翻译成物理地址。假如虚拟地址在页表中找不到对应的页表项,计算机系统就不能工作了。所以页表一定要覆盖全部虚拟地址空间,不分级的页表就需要有 100 多万个页表项来映射,而二级分页则只需要 1024 个页表项(此时一级页表覆盖到了全部虚拟地址空间,二级页表在需要时创建)。
我们把二级分页再推广到多级页表,就会发现页表占用的内存空间更少了,这一切都要归功于对局部性原理的充分应用。
对于 64 位的系统,两级分页肯定不够了,就变成了四级目录,分别是:
- 全局页目录项 PGD(Page Global Directory);
- 上层页目录项 PUD(Page Upper Directory);
- 中间页目录项 PMD(Page Middle Directory);
- 页表项 PTE(Page Table Entry);
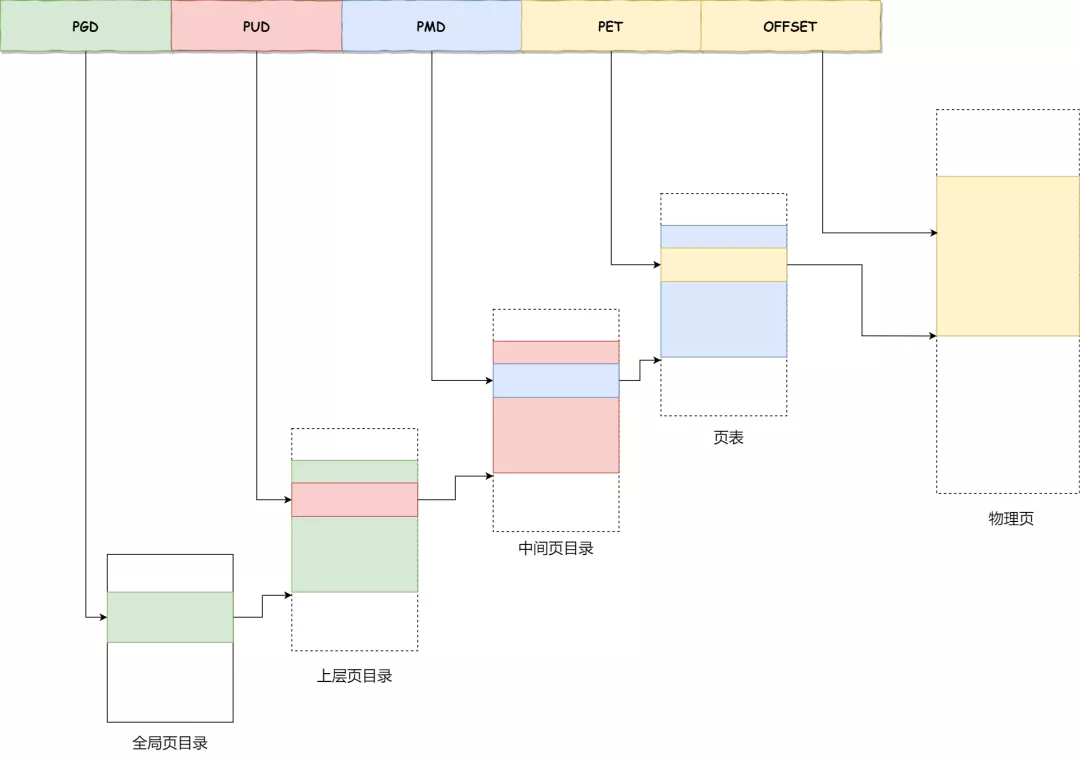
页表缓存TLB(Translation Lookaside Buffer)
多级页表虽然解决了空间上的问题,但是虚拟地址到物理地址的转换就多了几道转换的工序,这显然就降低了这俩地址转换的速度,也就是带来了时间上的开销。
程序是有局部性的,即在一段时间内,整个程序的执行仅限于程序中的某一部分。相应地,执行所访问的存储空间也局限于某个内存区域。
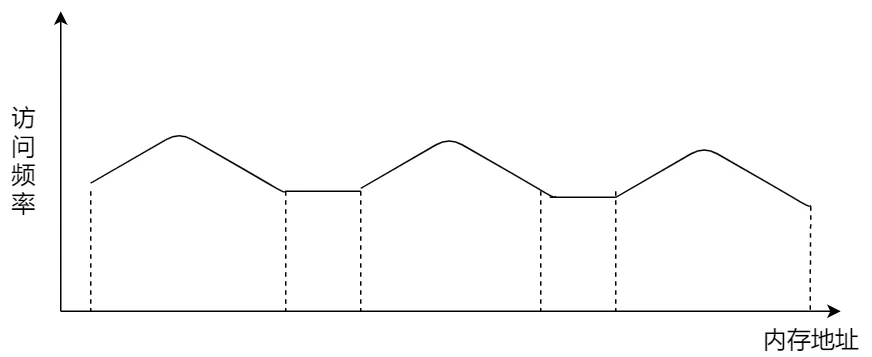
我们就可以利用这一特性,把最常访问的几个页表项存储到访问速度更快的硬件,于是计算机科学家们,就在 CPU 芯片中,加入了一个专门存放程序最常访问的页表项的 Cache,这个 Cache 就是 TLB(Translation Lookaside Buffer) ,通常称为页表缓存、转址旁路缓存、快表等。
在 CPU 芯片里面,封装了内存管理单元(Memory Management Unit)芯片,它用来完成地址转换和 TLB 的访问与交互。
有了 TLB 后,那么 CPU 在寻址时,会先查 TLB,如果没找到,才会继续查常规的页表。
TLB 的命中率其实是很高的,因为程序最常访问的页就那么几个。
Linux内存管理

逻辑地址和线性地址:
- 程序所使用的地址,通常是没被段式内存管理映射的地址,称为逻辑地址;
- 通过段式内存管理映射的地址,称为线性地址,也叫虚拟地址;
逻辑地址是「段式内存管理」转换前的地址,线性地址则是「页式内存管理」转换前的地址。
Linux 内存主要采用的是页式内存管理,但同时也不可避免地涉及了段机制。
这主要是上面 Intel 处理器发展历史导致的,因为 Intel X86 CPU 一律对程序中使用的地址先进行段式映射,然后才能进行页式映射。既然 CPU 的硬件结构是这样,Linux 内核也只好服从 Intel 的选择。
但是事实上,Linux 内核所采取的办法是使段式映射的过程实际上不起什么作用。也就是说,“上有政策,下有对策”,若惹不起就躲着走。
Linux 系统中的每个段都是从 0 地址开始的整个 4GB 虚拟空间(32 位环境下),也就是所有的段的起始地址都是一样的。这意味着,Linux 系统中的代码,包括操作系统本身的代码和应用程序代码,所面对的地址空间都是线性地址空间(虚拟地址),这种做法相当于屏蔽了处理器中的逻辑地址概念,段只被用于访问控制和内存保护。
我们再来瞧一瞧,Linux 的虚拟地址空间是如何分布的?
在 Linux 操作系统中,虚拟地址空间的内部又被分为内核空间和用户空间两部分,不同位数的系统,地址空间的范围也不同。比如最常见的 32 位和 64 位系统,如下所示:
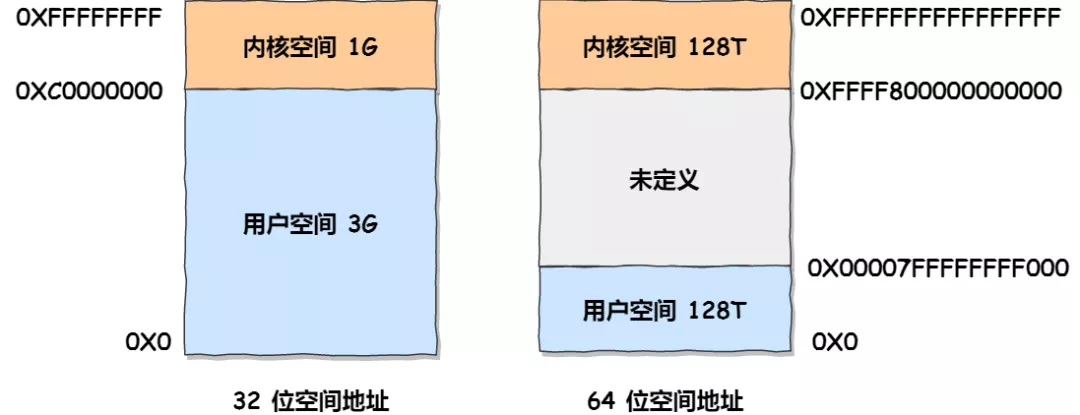
通过这里可以看出:
32位系统的内核空间占用1G,位于最高处,剩下的3G是用户空间;64位系统的内核空间和用户空间都是128T,分别占据整个内存空间的最高和最低处,剩下的中间部分是未定义的。
再来说说,内核空间与用户空间的区别:
- 进程在用户态时,只能访问用户空间内存;
- 只有进入内核态后,才可以访问内核空间的内存;
虽然每个进程都各自有独立的虚拟内存,但是每个虚拟内存中的内核地址,其实关联的都是相同的物理内存。这样,进程切换到内核态后,就可以很方便地访问内核空间内存。
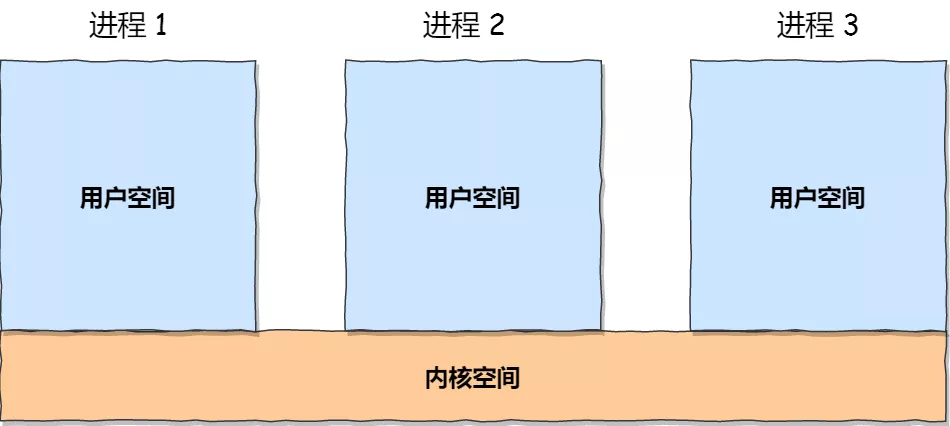
接下来,进一步了解虚拟空间的划分情况,用户空间和内核空间划分的方式是不同的,内核空间的分布情况就不多说了。
我们看看用户空间分布的情况,以 32 位系统为例,我画了一张图来表示它们的关系: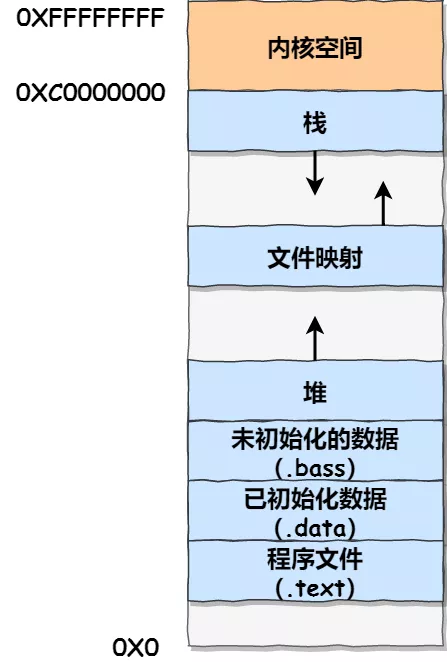
通过这张图你可以看到,用户空间内存,从低到高分别是 7 种不同的内存段:
- 程序文件段,包括二进制可执行代码;
- 已初始化数据段,包括静态常量;
- 未初始化数据段,包括未初始化的静态变量;
- 堆段,包括动态分配的内存,从低地址开始向上增长;
- 文件映射段,包括动态库、共享内存等,从低地址开始向上增长(跟硬件和内核版本有关)
- 栈段,包括局部变量和函数调用的上下文等。栈的大小是固定的,一般是
8 MB。当然系统也提供了参数,以便我们自定义大小;
在这 7 个内存段中,堆和文件映射段的内存是动态分配的。比如说,使用 C 标准库的 malloc() 或者 mmap() ,就可以分别在堆和文件映射段动态分配内存。
文章来源: blog.csdn.net,作者:zhz小白,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/zhouhengzhe/article/details/123320343

- 点赞
- 收藏
- 关注作者
评论(0)