【Linux】Make/Makefile (自动化构建):从“是什么”到“会用它”

Make/Makefile 入门:从“是什么”到“会用它”
一、先搞懂:Make 和 Makefile 是啥?
简单说,这俩是“搭档”——一个负责“干活”,一个负责“指挥”: - make:是 Linux 里的一个命令,就像个“工人”,听指挥做事; - makefile:是一个文本文件,就像“施工图纸”,写清楚要做什么、怎么做、需要什么原材料。 它们的最终目的很简单:帮你把写好的代码(比如 .c 文件),自动编译成能运行的程序(比如 mytest)。 看下面两张图就懂了: 第一张图是你的工作目录,里面有 makefile 文件和代码文件(比如 main.c); 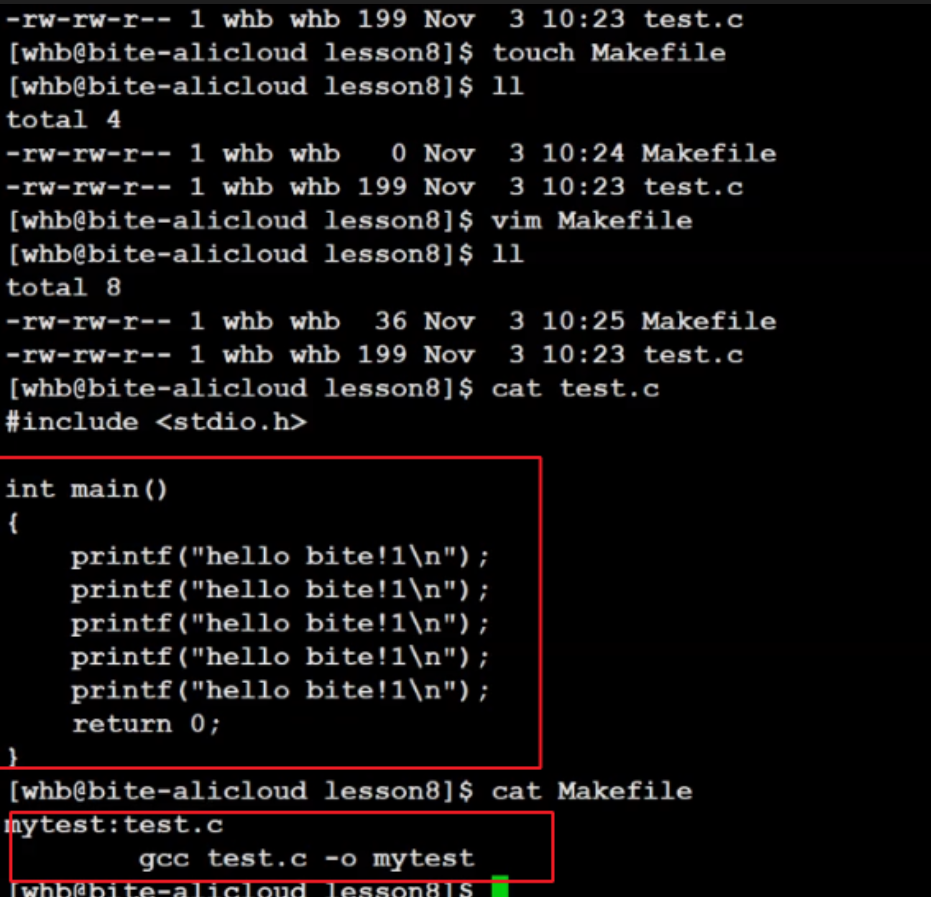 第二张图是执行
第二张图是执行 make 命令后,“工人”按照 makefile 的指挥,生成了可执行文件 mytest;  ## 二、快速上手:Makefile 的核心逻辑 Makefile 之所以好用,全靠“依赖关系”和“依赖方法”这俩东西,说白了就是: - 依赖关系:要做一个“目标”(比如
## 二、快速上手:Makefile 的核心逻辑 Makefile 之所以好用,全靠“依赖关系”和“依赖方法”这俩东西,说白了就是: - 依赖关系:要做一个“目标”(比如 mytest),得有哪些“原材料”(比如 main.o); - 依赖方法:用什么命令把“原材料”做成“目标”(比如 gcc main.o -o mytest)。 看这张图,里面把逻辑写得很清楚:  - 目标
- 目标 mytest 依赖 main.o; - 要做 mytest,就执行 gcc main.o -o mytest; - 而 main.o 又依赖 main.c,要做 main.o 就执行 gcc -c main.c。 执行 make 命令后,它会按这个逻辑一步步走,最后生成 mytest,就像下面这张图的效果:  ## 三、核心思想:不做无用功 Make 的精髓就一个:只编译“改了的文件”。 比如你改了
## 三、核心思想:不做无用功 Make 的精髓就一个:只编译“改了的文件”。 比如你改了 main.c,Make 会对比 main.c 和 main.o 的“修改时间”(后面会讲),发现 main.c 更新,就重新编译 main.o;如果没改,就跳过这一步,直接用之前的 main.o 生成 mytest——省时间,效率高。 ## 四、Makefile 具体语法:这些细节要记住 ### 1. 清除编译垃圾:clean 目标 编译后会生成 .o 文件(中间文件)和可执行文件,想一键删除这些“垃圾”,就加个 clean 目标,写法看下面的图:  -
- rm -rf *.o mytest:就是删除所有 .o 文件和 mytest; - 用的时候输命令:make clean。 ### 2. Make 的“默认行为” Make 会从上到下扫描 Makefile,默认只生成第一个目标(比如前面的 mytest)。 如果想生成其他目标(比如 clean),就用 make 目标名(比如 make clean)。 ### 3. 伪目标:.PHONY 是干啥的? 先想个问题:如果你的目录里不小心有个叫 clean 的文件,再执行 make clean,Make 会觉得“clean 文件已经存在,不用再执行了”——这就错了! 这时候就要用 伪目标:用 .PHONY 修饰的目标,不管有没有同名文件,都会执行对应的命令(忽略时间对比)。 写法看下面的图,给 clean 加个 .PHONY: clean 就行:  #### 为什么需要伪目标?本质是“时间对比” Make 判断要不要重新编译,靠的是“文件修改时间”(Modify 时间): - 如果“原材料”(比如
#### 为什么需要伪目标?本质是“时间对比” Make 判断要不要重新编译,靠的是“文件修改时间”(Modify 时间): - 如果“原材料”(比如 main.c)的 Modify 时间,比“目标”(比如 main.o)新,就重新编译; - 如果“目标”时间更新,就跳过。 下面这张图能看到时间对比的逻辑:  #### 补充:文件的三组时间 Linux 里文件有三个关键时间,Make 主要看前两个: - Modify:文件内容修改的时间(最关键,改代码会变); - Access:文件被访问的时间(比如打开看一眼),但因为历史设计,不是实时更新; - (还有个 Change 是文件属性修改时间,比如改文件名,Make 用得少) 看这张图,能直观看到这些时间:
#### 补充:文件的三组时间 Linux 里文件有三个关键时间,Make 主要看前两个: - Modify:文件内容修改的时间(最关键,改代码会变); - Access:文件被访问的时间(比如打开看一眼),但因为历史设计,不是实时更新; - (还有个 Change 是文件属性修改时间,比如改文件名,Make 用得少) 看这张图,能直观看到这些时间: 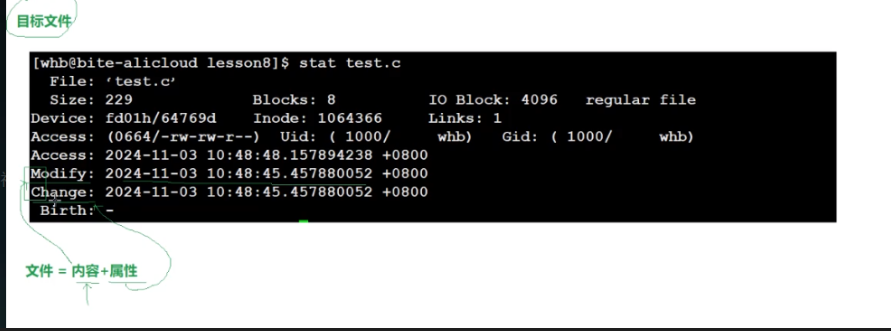 ### 4. 注释:# 后面的内容是“备注” Makefile 里用
### 4. 注释:# 后面的内容是“备注” Makefile 里用 # 写注释,# 后面的内容不会被执行,只是给人看的,比如下面这张图: 
# 这是注释,不会执行 这句话就是备注,告诉别人这行代码是干嘛的。 ### 5. 编译文件:从 .c 到 .o 再到可执行文件 前面其实提过编译步骤,这里看具体代码: 第一张图是“把 .c 编译成 .o”(gcc -c 是生成中间文件): 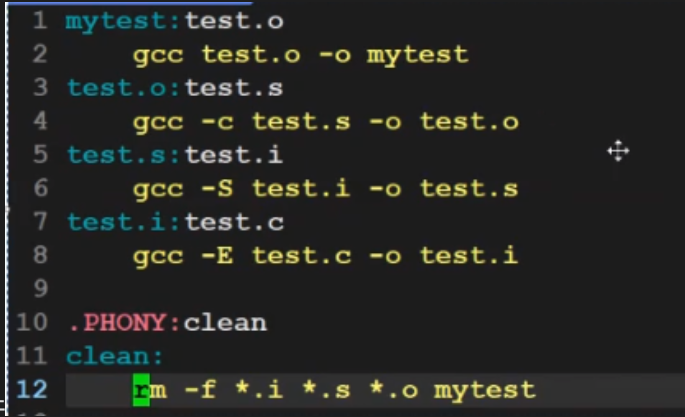 第二张图是“把
第二张图是“把 .o 编译成可执行文件 mytest”:  ### 6. 推导原则:像“堆积木”一样处理依赖 Make 处理依赖时,会像“入栈出栈”一样,先处理最底层的依赖,再往上走。 比如要生成
### 6. 推导原则:像“堆积木”一样处理依赖 Make 处理依赖时,会像“入栈出栈”一样,先处理最底层的依赖,再往上走。 比如要生成 mytest,得先有 main.o;要生成 main.o,得先有 main.c——Make 会先找 main.c 编译成 main.o(入栈处理依赖),再用 main.o 生成 mytest(出栈处理目标)。 看这张图,能理解这个“层层推导”的过程:  ## 五、通用 Makefile:一次写好,多次复用 如果代码文件多了(比如有
## 五、通用 Makefile:一次写好,多次复用 如果代码文件多了(比如有 main.c、add.c、sub.c),一个个写依赖太麻烦,这时候就需要“通用 Makefile”——自动找源文件、自动生成中间文件,不用手动改。 ### 1. 基础通用版 先看下面这张基础通用 Makefile 的图:  里面用了变量(比如
里面用了变量(比如 CC=gcc 表示编译器,TARGET=mytest 表示目标程序),但还不够灵活,比如源文件多了要手动加。 ### 2. 优化通用版:自动找文件、自动替换 下面这张是优化后的版本,解决了“手动加文件”的问题: 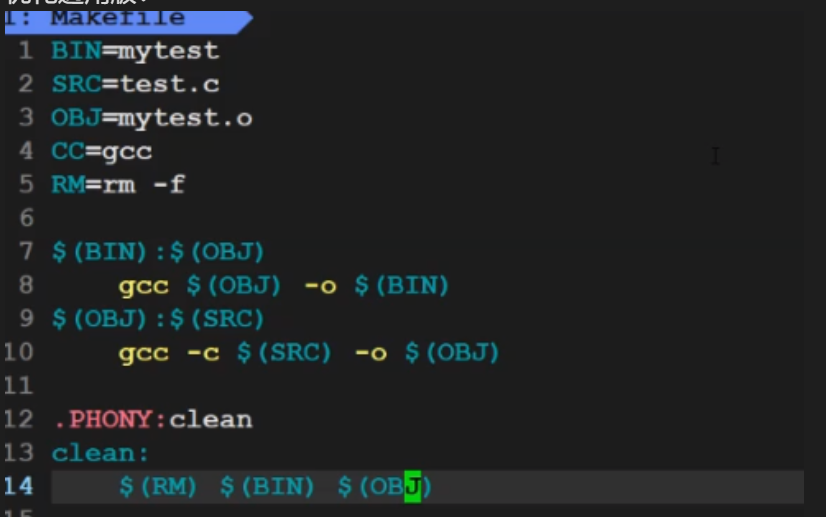 这里有几个关键技巧,咱们一个个说: #### 技巧1:动态获取所有 .c 文件(SRC 变量) 用
这里有几个关键技巧,咱们一个个说: #### 技巧1:动态获取所有 .c 文件(SRC 变量) 用 SRC=$(wildcard *.c),wildcard 是 Makefile 的“通配符函数”,意思是“找当前目录下所有 .c 文件”,不用手动写 main.c add.c 了,看这张图:  #### 技巧2:@ 号:隐藏命令本身,只显示结果 如果写
#### 技巧2:@ 号:隐藏命令本身,只显示结果 如果写 echo "编译中...",执行 make 时会先打印命令 echo "编译中...",再打印 编译中...(两份内容); 加个 @ 变成 @echo "编译中...",就只显示 编译中...,干净多了,看这张图:  这是 Makefile 自己的语法,和 Shell 里的“隐藏命令输出”逻辑类似,看这张图的对比:
这是 Makefile 自己的语法,和 Shell 里的“隐藏命令输出”逻辑类似,看这张图的对比:  #### 技巧3:自动把 .c 换成 .o(OBJ 变量) 用
#### 技巧3:自动把 .c 换成 .o(OBJ 变量) 用 OBJ=$(patsubst %.c,%.o,$(SRC)),patsubst 是“替换函数”,意思是“把 SRC 里所有 .c 后缀,换成 .o 后缀”。 比如 SRC 是 main.c add.c,OBJ 就自动变成 main.o add.o,不用手动写了,看这张图:  #### 技巧4:$@ 和 @
#### 技巧4:$@ 和 @:代表“当前目标”(比如下面图里的 ^:代表“当前目标的所有依赖”(比如下面图里的 (CC) $^ -o $@,看这张图:  #### 技巧5:% 和 $<:批量处理 .o 依赖 用 %.o: %.c写“模式规则”,意思是“所有.o文件,都依赖对应的.c文件”(比如main.o依赖main.c,add.o依赖add.c)。 再用 $<代表“当前依赖的第一个文件”(这里就是对应的.c文件),所以gcc -c $< -o $@就等于“把当前.c编译成对应的.o”,批量处理所有文件,看这张图: 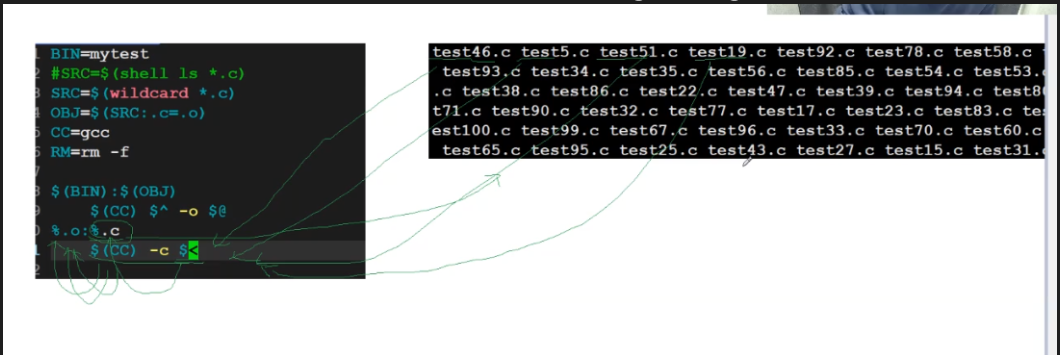 ### 3. 通用 Makefile 效果 最后看这两张图,左边是执行 make自动编译,右边是执行make clean` 自动清除垃圾,全程不用手动改命令: 
 ## 最后总结 Make/Makefile 本质是“自动化构建工具”——它帮你省去重复输编译命令的麻烦,还能智能判断哪些文件需要重新编译,提高效率。 刚开始可能觉得语法有点绕,但记住“依赖关系+变量简化”这两个核心,再结合上面的通用模板,很快就能上手啦!
## 最后总结 Make/Makefile 本质是“自动化构建工具”——它帮你省去重复输编译命令的麻烦,还能智能判断哪些文件需要重新编译,提高效率。 刚开始可能觉得语法有点绕,但记住“依赖关系+变量简化”这两个核心,再结合上面的通用模板,很快就能上手啦!

- 点赞
- 收藏
- 关注作者
评论(0)