经典/最新计算机视觉论文及代码推荐

今日推荐几篇最新/经典计算机视觉方向的论文,涉及诸多方面,都是CVPR2022录用的文章,具体内容详见论文原文和代码链接。
Mobile-Former来了!微软提出:MobileNet+Transformer轻量化并行网络

- 论文题目:Mobile-Former: Bridging MobileNet and Transformer
- 论文链接:https://arxiv.org/pdf/2108.05895.pdf
- 代码链接:https://github.com/BR-IDL/PaddleViT
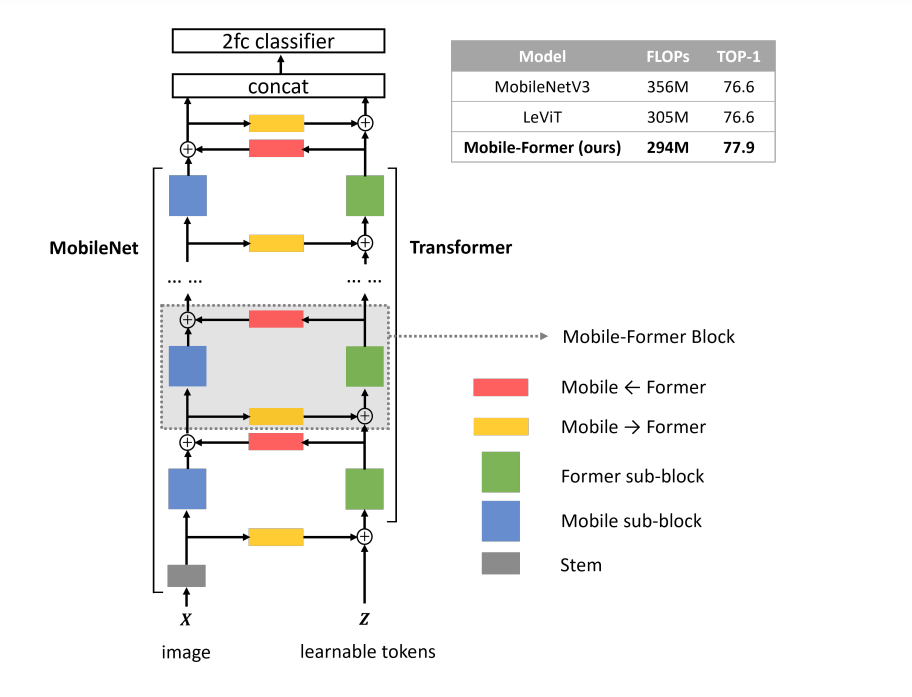
在本文中,作者将设计范式从串联向并联转变,提出了一种新的MobileNet和Transformer并行化,并在两者之间建立双向桥接(见图)。将其命名为Mobile-Former,其中Mobile指MobileNet, Former指transformer。Mobile以图像为输入堆叠mobile block(或inverted bottleneck)。它利用高效的depthwise和pointwise卷积来提取像素级的局部特征。前者以一些可学习的token作为输入,叠加multi-head attention和前馈网络(FFN)。这些token用于对图像的全局特征进行编码。
Mobile-Former是MobileNet和Transformer的并行设计,中间有一个双向桥接。这种结构利用了MobileNet在局部处理和Transformer在全局交互方面的优势。并且该桥接可以实现局部和全局特征的双向融合。与最近在视觉Transformer上的工作不同,Mobile-Former中的Transformer包含非常少的随机初始化的token(例如少于6个token),从而导致计算成本低。Mobile-Former结构如下图所示:
Meta-Former/PoolFormer
-
论文题目:MetaFormer Is Actually What You Need for Vision
-
论文链接:https://arxiv.org/abs/2111.11418
-
代码链接:https://github.com/sail-sg/poolformer
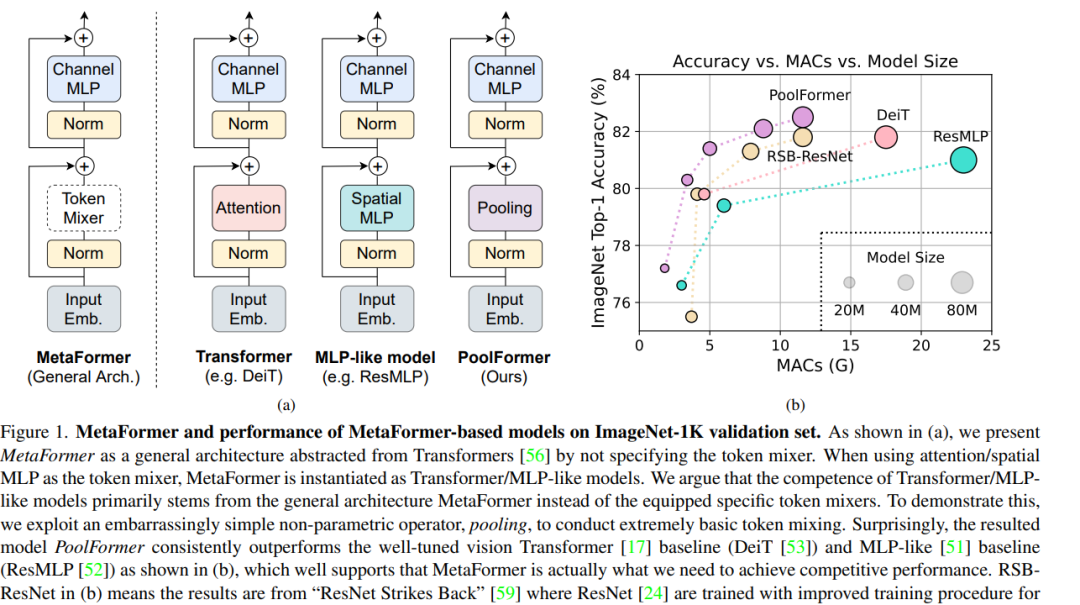
Transformer已经证明在计算机视觉任务中有非常大的潜力,一种普遍的看法是基于attention的token mixer模块使transformer具有竞争力。但是将attention用spatial MLP替代后,模型仍然具有非常好的效果。那么是不是transformer的结构而不是attention使其有效呢?作者使用池化层代替transformer中的attention,构建了PoolFormer模型,取得了非常好的效果,ImageNet-1k准确率达到82.1%。证明了Transformer结构的有效性,而非attention。主要结构如下图所示:
多尺度 Attention
-
论文题目:Shunted Self-Attention via Multi-Scale Token Aggregation
-
论文链接:https://arxiv.org/abs/2111.15193
-
代码链接:https://github.com/OliverRensu/Shunted-Transformer

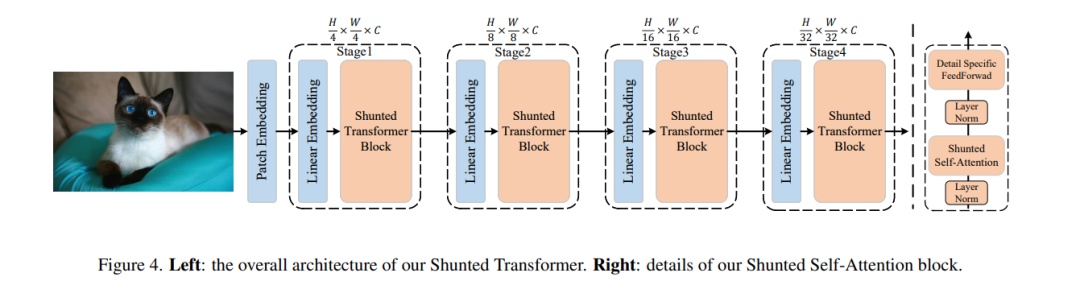
这篇文章思路是一种金字塔多尺度的 Attention,动机可以看下面的图:

红色圈为 Attention 针对的地方,蓝色圈大小为感受野,数量为计算成本。作者想说在传统 ViT 中,由于感受野都很小,虽然能充分考虑到全图各种细节,但所需的计算成本很大。而在 PVT 结构中,因为 K / V 得到了适当的尺寸缩减,因此感受野很大,虽然削减了计算成本,但无法考虑小物体细节。
本文提供了另一种思路,类似金字塔型多尺度attention,具体详见原文和代码连接。下图是Shunted self-attention block结构图。
后续
下一期最新/经典视觉cvpr顶会论文敬请期待!
文章来源: blog.csdn.net,作者:小小谢先生,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/xiewenrui1996/article/details/126634535

- 点赞
- 收藏
- 关注作者
评论(0)