【小白学习keras教程】十、三种Model Selection方法:k-fold cross-validation,GridS

【摘要】 @Author:RunsenModel Selection是划分训练集和测试集的手段,下面总结了三种Model Selection方法。k-fold cross-validation using scikit-learn wrappergrid search using scikit-learn wrapperrandom search using scikit-learn wrapper ...
@Author:Runsen
Model Selection是划分训练集和测试集的手段,下面总结了三种Model Selection方法。
- k-fold cross-validation using
scikit-learn wrapper - grid search using
scikit-learn wrapper - random search using
scikit-learn wrapper
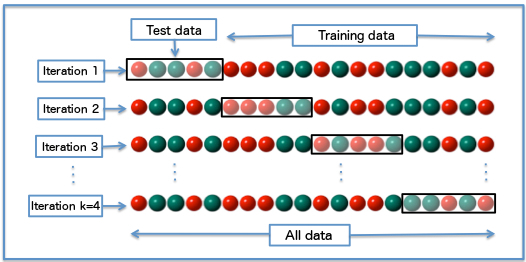
k-fold cross-validation
- 模型验证和选择最常用的方法之一
- 将训练数据集划分为
k子集,并选择其中一个子集作为验证集,其他子集作为训练集 - 然后,使用训练集训练模型,并使用验证集进行验证
- “k”轮分区和培训/验证的平均验证结果
- 比较结果
网格搜索和随机搜索
- 网格搜索和随机搜索是超参数调整的两种方法
- 网格搜索尝试指定的超参数值的所有可能组合
- 随机搜索实现参数随机搜索,其中每个试验都是来自可能的超参数分布的样本
Load dataset
imdbdataset
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing import sequence
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words = 5000)
# printing out maximum & minimun length of sentences
print(len(max(X_train)))
print(len(max(X_test)))
print(len(min(X_train)))
print(len(min(X_test)))
2494
2315
11
7
X_train = sequence.pad_sequences(X_train, maxlen = 500)
X_test = sequence.pad_sequences(X_test, maxlen = 500)
当使用顺序模型API时,可以使用scikit学习包装器
定义函数来创建模型,并传递给KerasClassifier
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import *
from tensorflow.keras import optimizers
from tensorflow.keras.wrappers.scikit_learn import KerasClassifier
from sklearn.model_selection import KFold, cross_val_score
def imdb_model(embed_dim = 100, lstm = True, lr = 0.01):
model = Sequential()
model.add(Embedding(5000, embed_dim))
if lstm:
model.add(LSTM(15))
else:
model.add(GRU(15))
model.add(Dense(50))
model.add(Activation('relu'))
model.add(Dropout(0.3))
model.add(Dense(1))
model.add(Activation('sigmoid'))
adam = optimizers.Adam(lr = lr)
model.compile(loss = 'binary_crossentropy', optimizer = adam, metrics = ['accuracy'])
return model
model = KerasClassifier(build_fn = imdb_model, epochs = 3, batch_size = 128, verbose = 1)
k-fold cross-validation using scikit-learn wrapper
# set k = 3
results = cross_val_score(model, X_train, y_train, cv = 3)

# 平均准确度和标准差
print('Cross validation Results: ')
for i in range(len(results)):
print('{}th round accuracy: {}'.format(i+1, results[i]))
print('Average accuracy: ', results.mean())
print('Standard deviation: ', results.std())
Cross validation Results:
1th round accuracy: 0.8707703351974487
2th round accuracy: 0.8862354755401611
3th round accuracy: 0.8576743006706238
Average accuracy: 0.8715600371360779
Standard deviation: 0.011673414220526314
GridSearchCV
from sklearn.model_selection import GridSearchCV
# first define hyperparameter grid
embed_dim = [100, 300]
lstm = [True, False]
lr = [0.001, 0.01]
batch_size = [64, 128, 256]
hyperparam_grid = {'embed_dim': embed_dim, 'lstm': lstm, 'lr': lr, 'batch_size': batch_size}
model = KerasClassifier(build_fn = imdb_model, epochs = 5, verbose = 1)
clf = GridSearchCV(estimator = model, param_grid = hyperparam_grid)
grid_result = clf.fit(X_train, y_train)
means = clf.cv_results_['mean_test_score']
stds = clf.cv_results_['std_test_score']
params = clf.cv_results_['params']
# displaying best results & parameter settings
max_idx = np.argmax(means)
print('Best test accuracy: ', means[max_idx])
print('Standard Deviation of Accuracies: ', stds[max_idx])
print('Parameter Setting: ', params[max_idx])
RandomizedSearchCV
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint, uniform
import numpy as np
embed_dim = randint(100, 300)
lstm = [True, False]
lr = uniform(0.001, 0.1)
batch_size = randint(64, 256)
hyperparam_dist = {'embed_dim': embed_dim, 'lstm': lstm, 'lr': lr, 'batch_size': batch_size}
model = KerasClassifier(build_fn = imdb_model, epochs = 5, verbose = 1)
clf = RandomizedSearchCV(estimator = model, param_distributions = hyperparam_dist, n_iter = 20)
random_result = clf.fit(X_train, y_train)
means = clf.cv_results_['mean_test_score']
stds = clf.cv_results_['std_test_score']
params = clf.cv_results_['params']
# displaying best results & parameter settings
max_idx = np.argmax(means)
print('Best test accuracy: ', means[max_idx])
print('Standard Deviation of Accuracies: ', stds[max_idx])
print('Parameter Setting: ', params[max_idx])
【版权声明】本文为华为云社区用户原创内容,转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息, 否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)