Pandas时间处理

【摘要】 DataFrame时间处理示例数据 将字符串列转化成时间序列有时从 csv 或 xlsx 文件中读取的时间,是字符串(Object)类型,这时就需要将其转化成 datetime 类型,方便后续对时间的处理。pd.to_datetime(df['datetime']) 将时间列作为索引对于大部分时间序列数据,我们都可以将该列作为索引,来最大的利用时间。这里 drop=False 选择不删除 ...
DataFrame时间处理
示例数据
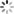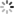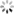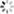
将字符串列转化成时间序列
有时从 csv 或 xlsx 文件中读取的时间,是字符串(Object)类型,这时就需要将其转化成 datetime 类型,方便后续对时间的处理。
pd.to_datetime(df['datetime'])
将时间列作为索引
对于大部分时间序列数据,我们都可以将该列作为索引,来最大的利用时间。这里 drop=False 选择不删除 datetime 列。
df.set_index('datetime', drop=False)
通过索引获取 1月 的数据,这里显示前五行。
df.loc['2021-1'].head()
通过索引获取 1~3月 的数据。
df.loc['2021-1':'2021-3'].info()
获取时间的各个属性
这里给出一般需求中可能会用到的属性,同时给出各个方法的实例。
| 常见属性 | 描述 |
|---|---|
date |
获取日期 |
time |
获取时间 |
year |
获取年份 |
month |
获取月份 |
day |
获取天 |
hour |
获取小时 |
minute |
获取分钟 |
second |
获取秒 |
dayofyear |
数据处于一年中的第几天 |
weekofyear |
数据处于一年中的第几周(新版使用 isocalendar().week) |
weekday |
数据处于一周中的第几天(数字 周一为0) |
day_name() |
数据处于一周中的第几天(英文 Monday) |
quarter |
数据处于一年中的第几季度 |
is_leap_year |
是否为闰年 |
这里随便选第 100 行的日期做示例,各个属性的结果均以注释的形式展示。
df['datetime'].dt.date[100]
# datetime.date(2021, 4, 11)
df['datetime'].dt.time[100]
# datetime.time(11, 50, 58, 995000)
df['datetime'].dt.year[100]
# 2021
df['datetime'].dt.month[100]
# 4
df['datetime'].dt.day[100]
# 11
df['datetime'].dt.hour[100]
# 11
df['datetime'].dt.minute[100]
# 50
df['datetime'].dt.second[100]
# 58
df['datetime'].dt.dayofyear[100]
# 101
df['datetime'].dt.isocalendar().week[100]
# 14
df['datetime'].dt.weekday[100]
# 6
df['datetime'].dt.day_name()[100]
# 'Sunday'
df['datetime'].dt.quarter[100]
# 2
df['datetime'].dt.is_leap_year[100]
# False
重采样 resample()
重采样分为 降采样 和 升采样 两种。
降采样指的是采样的时间频率低于原时间序列的时间频率,同时来讲就是一个聚合操作。看示例,下面获取各季度的 count 列平均值。Q 代表 quarter 表示按季度采样。
df.resample('Q',on='datetime')["count"].mean()
注意:此时的输出的最大时间为06-30, 并不是实际数据中的 05-31。 但是并不影响计算。
升采样与降采样相反,指的是采样的时间频率高于原时间序列的时间频率,相当于获取更细纬度的时间数据,但这样往往会造成数据中存在大量空值,实际用的不多,这里就不展开讲解了。
【版权声明】本文为华为云社区用户原创内容,未经允许不得转载,如需转载请自行联系原作者进行授权。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)