MyBatis四大组件详解

前言
上次我们在说mybatis 的 plugin 功能的时候,提到了其可作用于myBatis 的四大组件,也放了一个基础的模型图,但是对于这四大组件更具体的功能和原理:却没有进一步说明,今天就来完成这项工作
先来看一张图mybatis的类引用图,然后我们再详细解释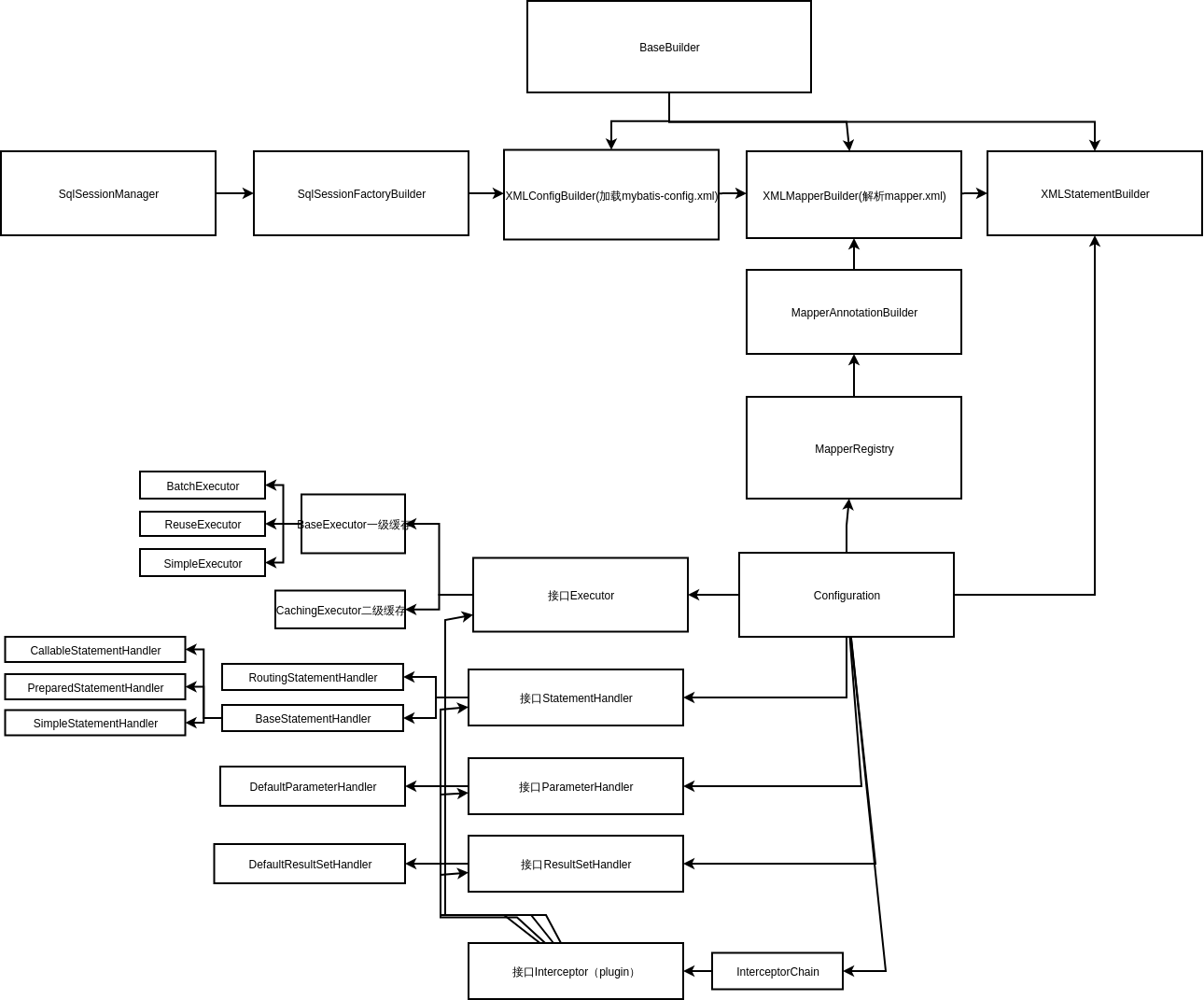
我们现浏览下Executor 接口都提供了什么方法:
public interface Executor {
ResultHandler NO_RESULT_HANDLER = null;
int update(MappedStatement ms, Object parameter) throws SQLException;
<E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler,
CacheKey cacheKey, BoundSql boundSql) throws SQLException;
<E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler)
throws SQLException;
<E> Cursor<E> queryCursor(MappedStatement ms, Object parameter, RowBounds rowBounds) throws SQLException;
List<BatchResult> flushStatements() throws SQLException;
void commit(boolean required) throws SQLException;
void rollback(boolean required) throws SQLException;
CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql);
boolean isCached(MappedStatement ms, CacheKey key);
void clearLocalCache();
void deferLoad(MappedStatement ms, MetaObject resultObject, String property, CacheKey key, Class<?> targetType);
Transaction getTransaction();
void close(boolean forceRollback);
boolean isClosed();
void setExecutorWrapper(Executor executor);
}
我们知道,执行器是直接存在会话中的,在整个调用链路中还是比较偏上层的,可以看到其主要的功能就是三点:
- 数据的查改
- 事务的提交与回滚
- 还有mybatis本身缓存的处理
我们把该接口的几个默认实现都列出来,慢慢来介绍。
- CachingExecutor: 独树一帜,它本身并不具备其他执行器的功能,不能直接进行sql操作,也无没获取连接,自然也无法执行事务提交或回滚,它只是个缓存容器(二级缓存),所以每一次使用CachingExecutor时,其内必须含一个其他执行器,sql和事务的操作,其实都由该其他执行器负责。
- BaseExecutor: 一个抽象类,执行器的基本实现。该类主要完成了一些事务管理和一级缓存准备的工作,而查询和更新的核心逻辑则是空方法,所以不直接使用,一般使用的都是其三个子类,其子类将重写核心方法。
- SimpleExecutor:Mybatis默认的执行器,它对每个SQL语句都创建一个Statement对象,执行完毕后立即关闭。SimpleExecutor适用于执行一些短期查询、插入、更新或删除等SQL操作,但频繁的创建和关闭Statement对象会导致较差的性能。
- ReuseExecutor:重用已经创建的Statement对象,将相同sql的多次查询或更新操作放到同一个Statement中执行,提高了性能。
- BatchExecutor:用于批量执行SQL语句,它将多个SQL语句放到同一个Statement中执行,从而减少了与数据库的通信次数
我们以一个查询语句来看看执行器到底在干什么
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
// 获取总配置
Configuration configuration = ms.getConfiguration();
// 创建个 StatementHandler ,注意此处可应用自定义plugin来修改默认Handler的逻辑
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 使用 StatementHandler 生成Statement ,该对象是sql语句的封装,将交由jdbc来执行
// 注意,默认的几种 handler 创建Statement 的逻辑都是一样的
stmt = prepareStatement(handler, ms.getStatementLog());
// 使用 某种handler 来执行sql,不同handler 稍有不同
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
可以看出,Executor执行器的核心功能,就是新建出一个statementHandler , 然后利用该handler创建一个statement 的实例。最后调用该实例的对应方法完成sql的执行。其基础和默认实现类是SimpleExecutor,另两种执行器则是该基础执行器在特殊场景下的优化版本。
而CachingExecutor则只专注二级缓存,没有上述核心功能,所以无法单独出现,其必定引用着一个“正常”的执行器,以便二级缓存没结果时,能正常查询数据库。
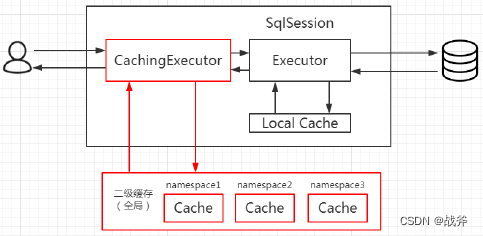
上面,我们讲执行器的时候,已经提到了 StatementHandler,现在则详细讲讲,在讲之前,还是得介绍下什么是Statement?
Statement 是Java JDBC API中定义的一个接口,位于java.sql 包下,是一种执行静态SQL语句的对象,可以用于执行SQL语句的查询、更新、插入和删除等操作。我们可以看其上的官方注释:
The object used for executing a static SQL statement and returning the results it produces.
By default, only one ResultSet object per Statement object can be open at the same time. Therefore, if the reading of one ResultSet object is interleaved with the reading of another, each must have been generated by different Statement objects. All execution methods in the Statement interface implicitly close a current ResultSet object of the statement if an open one exists.
用于执行静态SQL语句并返回其生成的结果的对象。
默认情况下,每个Statement对象只能同时打开一个ResultSet对象。因此,如果一个ResultSet对象的读取与另一个ResultSet对象的读取交错进行,则每个ResultSet对象必须由不同的Statement对象生成。如果存在打开的语句的ResultSet对象,则Statement接口中的所有执行方法都隐式关闭该语句的当前ResultSet对象。
换句话说,该对象就是 jdbc 的核心, 负责在已经建立数据库连接的基础上,向数据库发送要执行的SQL语句。
StatementHandler 是 mybatis 内的一个接口,从名字看,它主要是围绕statement进行管理和操作的,照例,我们先看看它定义的所有方法
public interface StatementHandler {
Statement prepare(Connection connection, Integer transactionTimeout)
throws SQLException;
void parameterize(Statement statement)
throws SQLException;
void batch(Statement statement)
throws SQLException;
int update(Statement statement)
throws SQLException;
<E> List<E> query(Statement statement, ResultHandler resultHandler)
throws SQLException;
<E> Cursor<E> queryCursor(Statement statement)
throws SQLException;
BoundSql getBoundSql();
ParameterHandler getParameterHandler();
}
从这些方法来看,StatementHandler 的主要功能应该包括
- 创建statement,并为其绑定参数
- 通过statement,对数据库执行sql,并对结果集进行映射
既然是接口,我们先看看mybatis 为其提供了几种实现类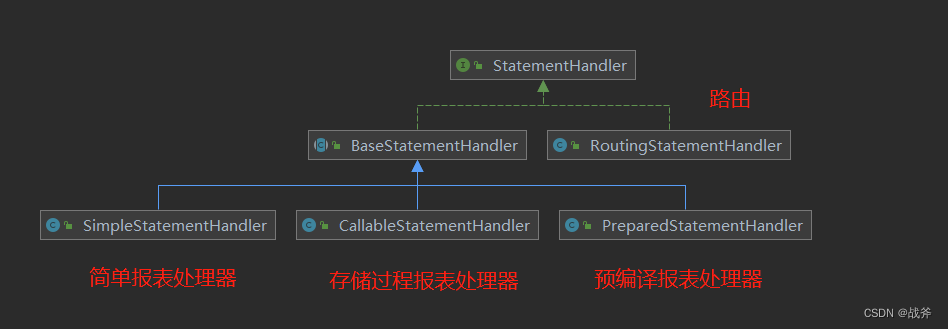
可以看到,其几乎好执行器接口的结构相同,下面,我们来说说这些实现类的区别
- RoutingStatementHandler: 路由,不带有任何实际逻辑,但是会根据报表statemnet的类型创建一个实现类,然后作为真实的报表处理器。
- BaseStatementHandler: 一个抽象类,报表处理器的基本实现。该类存储着一些变量,如参数处理器和结果处理器。且实现了创建报表的方法,但不含sql执行的具体操作。
- PreparedStatementHandler:用于执行预编译的SQL语句,并支持参数绑定和批量操作。
- CallableStatementHandler:用于执行存储过程和函数等数据库特殊语法,支持输入、输出和输入输出参数的绑定。
- SimpleStatementHandler:用于执行简单的SQL语句,不支持参数绑定和批量操作
毫无疑问,在实际应用中,我们的sql大多是带参数的,即含有#{},所以一般会被路由创建个PreparedStatementHandler,而静态sql 和只是用 ${} 的sql 则使用的是 SimpleStatementHandler
我们通过PreparedStatementHandler 里的查询方法来看其功能
@Override
public void parameterize(Statement statement) throws SQLException {
// 把参数装填进报表
parameterHandler.setParameters((PreparedStatement) statement);
}
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
// 将报表类型向上转型为 PreparedStatement
PreparedStatement ps = (PreparedStatement) statement;
// 报表执行sql
ps.execute();
// 使用结果处理器,处理返回值
return resultSetHandler.handleResultSets(ps);
}
可以看出,StatementHandler 的功能还是直接操作statement,并围绕sql的准备,执行,返回值处理三个点来运行的,
ParameterHandler 接口相对比较简单,只有两个方法
public interface ParameterHandler {
Object getParameterObject();
void setParameters(PreparedStatement ps) throws SQLException;
}
所以看得出来,ParameterHandler 其实就是两个功能,一个是提供入参对象,另一个就是把入参给sql注入进去
ParameterHandler 接口只有一个默认实现类 DefaultParameterHandler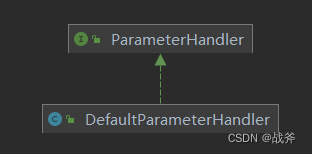
我们来看一下,要构建个参数处理器需要些什么内容,来看一下该类的构造方法:
public DefaultParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql) {
// 由 MyBatis解析xml得出的某个方法对应的sql的信息,包含sql语句 ,参数和结果集的映射
this.mappedStatement = mappedStatement;
// MyBatis总配置对象,包含mybatis的所有设置信息
this.configuration = mappedStatement.getConfiguration();
// 类型处理器注册表, 类型处理器是用来处理Java对象和字段类型之间映射,负责将Java类型和JDBC类型相互转换
this.typeHandlerRegistry = mappedStatement.getConfiguration().getTypeHandlerRegistry();
// 方法的入参拼出的对象,实际内部为HashMap
this.parameterObject = parameterObject;
// 完整的 sql语句,但参数部分尚未装填,由 ? 代替
this.boundSql = boundSql;
}
再来看下这所谓的处理器到底是怎么把入参设置进sql内的呢?我们来看看其核心方法 setParameters ,该方法作用是为预处理语句设置参数
@Override
public void setParameters(PreparedStatement ps) {
ErrorContext.instance().activity("setting parameters").object(mappedStatement.getParameterMap().getId());
// 从boundSql中获取参数映射列表,即方法入参对象 和 sql 中预留的参数位置的映射信息
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if (parameterMappings != null) {
for (int i = 0; i < parameterMappings.size(); i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
// 检查参数模式是否不是OUT , OUT模式一般用在存储过程,拿参数去接返回值
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) { // issue #448 ask first for additional params
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
// 获取类型处理器,主要是根据方法入参类型确定的
TypeHandler typeHandler = parameterMapping.getTypeHandler();
// 获取jdbc类型,由用户在xml中预留参数时指定,如 #{orderdesc , JDBCTYPE = VARCHAR}
JdbcType jdbcType = parameterMapping.getJdbcType();
if (value == null && jdbcType == null) {
// 如果值为null且JDBC类型也为null,则将JDBC类型设置为null值的默认JDBC类型,
// ORACLE 出现此情况可能或报错: Error setting null for parameter #XXX with JdbcType OTHER
jdbcType = configuration.getJdbcTypeForNull();
}
try {
// 使用类型处理程序为预处理语句设置参数值
typeHandler.setParameter(ps, i + 1, value, jdbcType);
} catch (TypeException | SQLException e) {
throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e);
}
}
}
}
}
通过对该方法的分析,其实不难看出来,就是把对方法的入参拆成基础的数据类型,然后替换掉sql里的对应的 " ?" 部分。但是具体是怎么做的呢。我们还得看其调用的一个关键类 TypeHandler 以及这里的 typeHandler.setParameter 方法。
TypeHandler 是 MyBatis 框架的一部分,它是一个接口,用于将 Java 类型和数据库类型之间进行转换。在 MyBatis 中,通过 TypeHandler 将 Java 对象转换为 JDBC 可以处理的数据类型,同时也将查询结果从数据库中的数据类型转换为 Java 类型。
public interface TypeHandler<T> {
void setParameter(PreparedStatement ps, int i, T parameter, JdbcType jdbcType) throws SQLException;
T getResult(ResultSet rs, String columnName) throws SQLException;
T getResult(ResultSet rs, int columnIndex) throws SQLException;
T getResult(CallableStatement cs, int columnIndex) throws SQLException;
}
可以看出,它不仅有设置参数的能力,而且还能返回结果,即把sql的返回结果,使用对应的java类型展示出来。而且我们先来看一看它的基类 BaseTypeHandler 及核心方法 setParameter
@Override
// 将 Java 对象转换为 JDBC 可以处理的数据类型,并设置到 PreparedStatement 对象中
// 把sql里第i个问号注入参数parameter,且要将parameter对象转换为指定的Jdbc类型
public void setParameter(PreparedStatement ps, int i, T parameter, JdbcType jdbcType) throws SQLException {
if (parameter == null) {
if (jdbcType == null) {
throw new TypeException("JDBC requires that the JdbcType must be specified for all nullable parameters.");
}
try {
// 为第i个问号注入null,第二个参数则为jdbc类型的唯一代码,比如FLOAT = 6,DATE = 91等
ps.setNull(i, jdbcType.TYPE_CODE);
} catch (SQLException e) {
throw new TypeException("Error setting null for parameter #" + i + " with JdbcType " + jdbcType + " . "
+ "Try setting a different JdbcType for this parameter or a different jdbcTypeForNull configuration property. "
+ "Cause: " + e, e);
}
} else {
try {
// 如果参数不为空,则需要真正塞值进去,此方法抽象类里没有实现,交由各子类实现
setNonNullParameter(ps, i, parameter, jdbcType);
} catch (Exception e) {
throw new TypeException("Error setting non null for parameter #" + i + " with JdbcType " + jdbcType + " . "
+ "Try setting a different JdbcType for this parameter or a different configuration property. "
+ "Cause: " + e, e);
}
}
}
而 BaseTypeHandler 在mybatis3.5.6 内置了四十三种子类,即有四十三种类型处理器,基本覆盖了当前数据库的各大字段类型,当然同时也支持用户自定义 TypeHandler。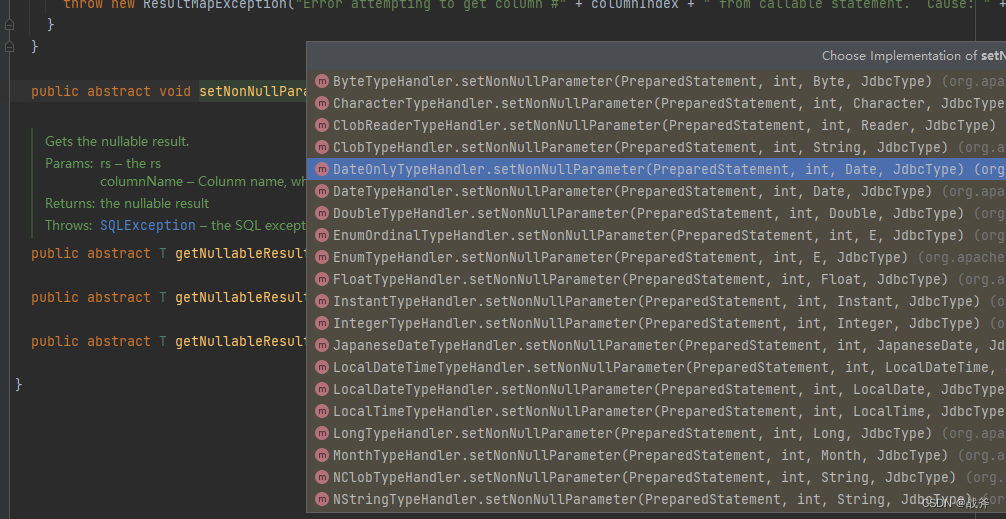
我们选择最典型的几种
- Double
public void setNonNullParameter(PreparedStatement ps, int i, Double parameter, JdbcType jdbcType)
throws SQLException {
ps.setDouble(i, parameter);
}
- Date
public void setNonNullParameter(PreparedStatement ps, int i, Date parameter, JdbcType jdbcType)
throws SQLException {
ps.setTimestamp(i, new Timestamp(parameter.getTime()));
}
- String
public void setNonNullParameter(PreparedStatement ps, int i, String parameter, JdbcType jdbcType)
throws SQLException {
ps.setString(i, parameter);
}
需要注意的是,上面的ps, 已经是来自各数据库的驱动的实现类了,因此可以根据数据库对该字段不同的命名,自行来处理。
我们写下这样的代码,Dao层以及SQL文件
// 实体类,构造方法
public User(int id, String username, String password) {
this.id = id;
this.username = username;
this.password = password;
}
public boolean addUser(User user) {
User user1 = new User(1 ,"zhangsan","123456");
User user2 = new User(2 ,"lisi","123456");
User user3 = new User(3 ,"wangwu","123456");
List<User> list = new ArrayList<>();
list.add(user1);
list.add(user2);
list.add(user3);
return userMapper.addUser(list);
}
boolean addUser(@Param("list") List<User> users);
<insert id="addUser" parameterType="com.zhanfu.springboot.demo.entity.User" >
insert into user (id,username,password) values
<foreach collection="list" item="item">
(#{item.id}, #{item.username}, #{item.password})
</foreach>
</insert>
需要注意的是,因为我们的示例中,含有foreach标签,所以是一段动态sql。而动态sql的逻辑和样式,是在有入参之后才能确定的,所以动态sql解析映射关系是在dao方法真正被调用的时候才开始。而静态sql,会在程序运行时,就构造出ParameterMappings,并存储在StaticSqlSource对象内
像上面这样的Dao方法和Sql,当我们执行Dao方法时,会先把动态条件进行判断好,比如此处列表有三条数据,意味着foreach 就会重复三次,最后解析出来的原生sql 就是
insert into user(id,username,password) values
(#{__frch_item_0.id}, #{__frch_item_0.username},#{__frch_item_0.password})
(#{__frch_item_1.id}, #{__frch_item_1.username},#{__frch_item_1.password})
(#{__frch_item_2.id}, #{__frch_item_2.username},#{__frch_item_2.password})
在通过对这段sql 的 #{} 里面的内容如"__frch_item_0.id",进行分析,结合入参的同名字段的适配,最终会生成一个长度为 9 的映射关系列表,如下图: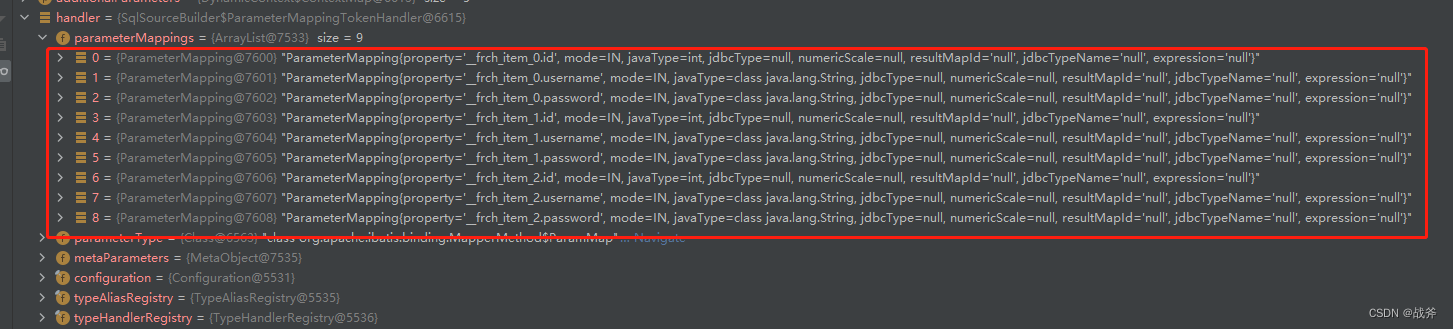
这样我们就得到了一个ParameterMappings,注意,这里只是映射关系,就是明确了有9个java对象,对应Sql的九个位置,而真正的参数填充还没开始
现在,我们聚焦到DefaultParameterHandler.setParameter() 方法,关注mybatis是怎么填充参数的。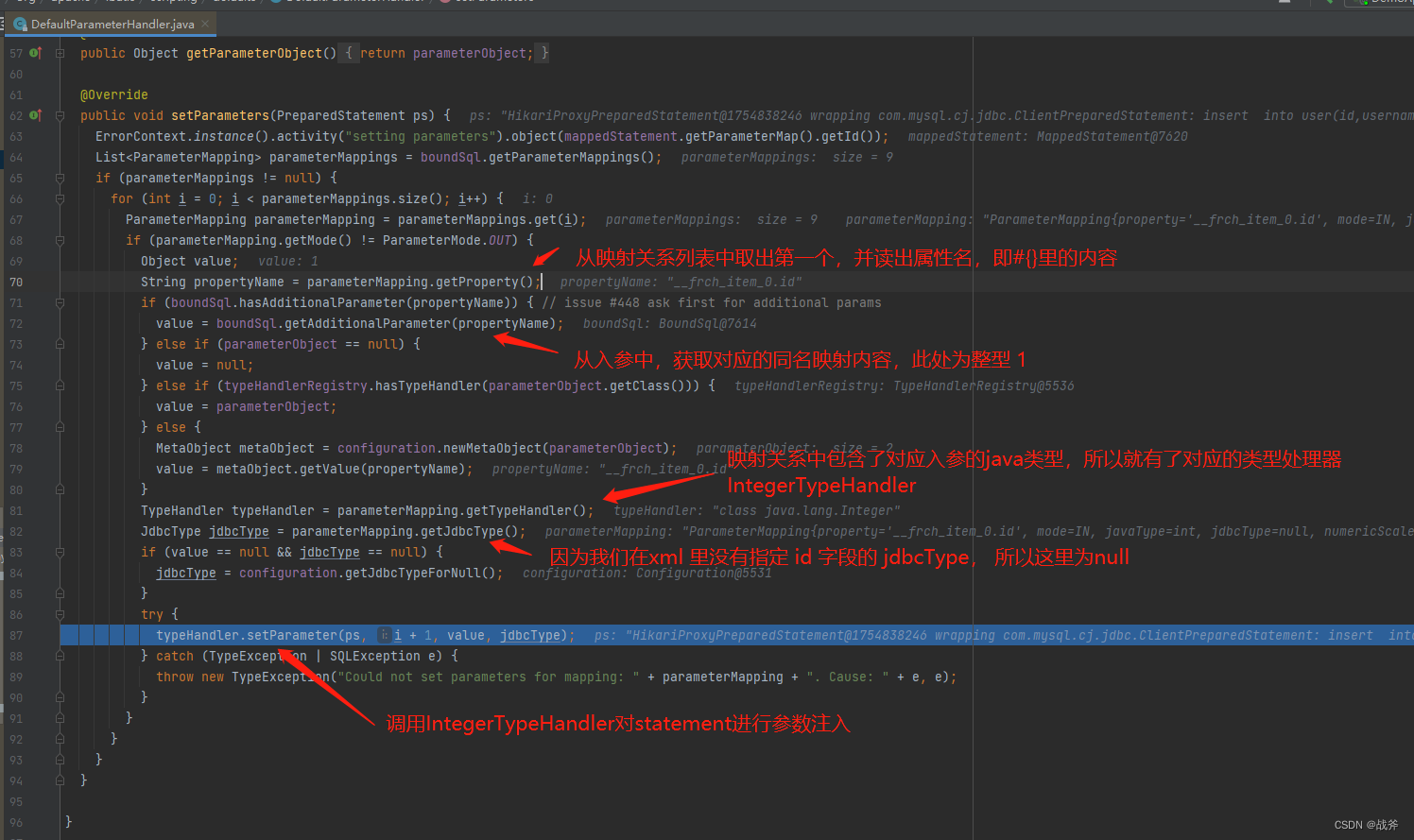

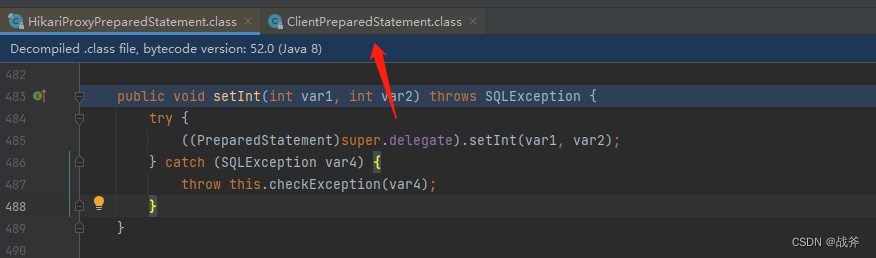
最终参数的设置,会交由 ClientPreparedStatement 完成,而 ClientPreparedStatement 则是mysql的驱动层了。
ResultHandler 的接口就是用来处理结果集的,根绝不同的sql分类有三种方法,第一种是最常用的
public interface ResultSetHandler {
// 处理 ResultSet 的结果,将其转换成一个 List<java对象> 并返回 ———— 最常用
<E> List<E> handleResultSets(Statement stmt) throws SQLException;
// 处理Cursor游标的的结果
<E> Cursor<E> handleCursorResultSets(Statement stmt) throws SQLException;
// 处理存储过程等带回调参数的情况
void handleOutputParameters(CallableStatement cs) throws SQLException;
}
MyBatis中提供了一个默认的ResultSetHandler实现
这个类比较大,我们直接看其核心方法,正是将结果集一行行遍历,然后针对指定的出参java类型,使用构造函数构造完后,往里面填入映射的值。
// public class DefaultResultSetHandler implements ResultSetHandler
private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping)
throws SQLException {
DefaultResultContext<Object> resultContext = new DefaultResultContext<>();
ResultSet resultSet = rsw.getResultSet();
skipRows(resultSet, rowBounds);
while (shouldProcessMoreRows(resultContext, rowBounds) && !resultSet.isClosed() && resultSet.next()) {
ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(resultSet, resultMap, null);
// 循环从结果集中获取数据,注意此时的 rowValue 已经是业务对象了
Object rowValue = getRowValue(rsw, discriminatedResultMap, null);
// 储存该业务对象
storeObject(resultHandler, resultContext, rowValue, parentMapping, resultSet);
}
}
private void storeObject(ResultHandler<?> resultHandler, DefaultResultContext<Object> resultContext, Object rowValue, ResultMapping parentMapping, ResultSet rs) throws SQLException {
if (parentMapping != null) {
linkToParents(rs, parentMapping, rowValue);
} else {
// 调用 resultHandler 存储本行结果
callResultHandler(resultHandler, resultContext, rowValue);
}
}
ResultHandler 其实是一个储存用的接口,它有两个实现类
public interface ResultHandler<T> {
void handleResult(ResultContext<? extends T> resultContext);
}
- DefaultResultHandler:默认的ResultHandler实现类。它将查询结果存储在一个List中
- MapResultHandler:将查询结果转换为Map类型的ResultHandler实现类。它将每条记录转换为一个Map,其中Map的key是列名,value是列的值
这两个类的逻辑非常简单,两个类分别维护了一个List 和 Map,将入参的resultContext内的值解析,存入各自的集合里即可。
需要注意的是,ResultHandler 的入参resultContext仅代表一行数据,真正的返回值可能是多行的,所以 ResultHandler 其实是在for循环中,一行行解析和转换的,而负责处理多行的结果处理器是ResultSetHandler,ResultSet在数据量较大时,会占用较大的内存,而ResultHandler可以将查询结果逐条处理,避免了占用大量内存的问题
所以,ResultSetHandler主要用于将查询结果转换成Java对象;而ResultHandler主要用于对查询结果以某种形式展现。它们的使用场景是不同的
ParameterHandler 负责翻译,把java对象的值,翻译进sql的指定位置;ResultSetHandler 则是一个讲解员,把SQL的结果集按框架搭建出来,再汇报给上级;StatementHandler则是一个部门经理,它不仅管理着前两者,还能创建statement(即存储着sql的对象),并指挥翻译把入参翻译进statement,然后调用驱动执行statement,最后的结果指挥讲解员把结果以特定格式展示出来;Executor则是个公司老板,位置更高,不再执行那些基础的工作,而是负责招聘部门经理(创建StatementHandler),并一键通知经理做事,而他自己的主要职责则是与其他公司搞关系(获取数据库连接、事务的提交回滚),调度仓储(缓存)

- 点赞
- 收藏
- 关注作者
评论(0)