【云驻共创】华为云之昇思MindSpore大模型专题(第二期)-第一课:ChatGLM

🚀前言
🔎1.昇思MindSpore
昇思MindSpore是华为公司推出的一款全场景AI计算框架。它提供了自动微分、分布式训练和推理、模型部署等功能,支持多种硬件平台,包括CPU、GPU和Ascend AI 处理器。MindSpore采用图和算子相结合的编程模型,能够高效地处理复杂的深度学习任务。它具有灵活的设计、高效的性能和易于使用的接口,使开发者能够更快地开发和部署AI应用。MindSpore还支持自定义操作和算法,可以满足不同场景下的需求。
🔎2.大模型
大模型是指具有数百万到数十亿个参数的深度学习模型。这些模型通常用于处理大规模数据集,并能够在各种任务上取得出色的性能。大模型通常需要大量的计算资源进行训练,并且需要更长的时间来收敛。然而,由于其具有更多的参数,大模型可以更好地捕捉数据中的复杂关系,从而提升模型的预测性能。大模型的应用范围非常广泛,包括自然语言处理、计算机视觉、语音识别等领域。
🔎3.ChatGLM
ChatGLM是一种生成式语言模型,用于聊天和对话任务。它是基于OpenAI的GPT模型框架构建的,采用了大规模的预训练数据集来学习语言模式和生成文本的能力。ChatGLM可以理解上下文并生成连贯、自然的回复。它可以用于构建对话系统、智能客服、聊天机器人等应用,能够提供更加交互性和人性化的对话体验。ChatGLM模型的训练和优化过程需要大量的计算资源和数据,而且模型的生成性质也需要进行适当的监督和过滤,以确保生成的回复符合预期的行为准则和标准。
🚀一、GLM Model Architecture
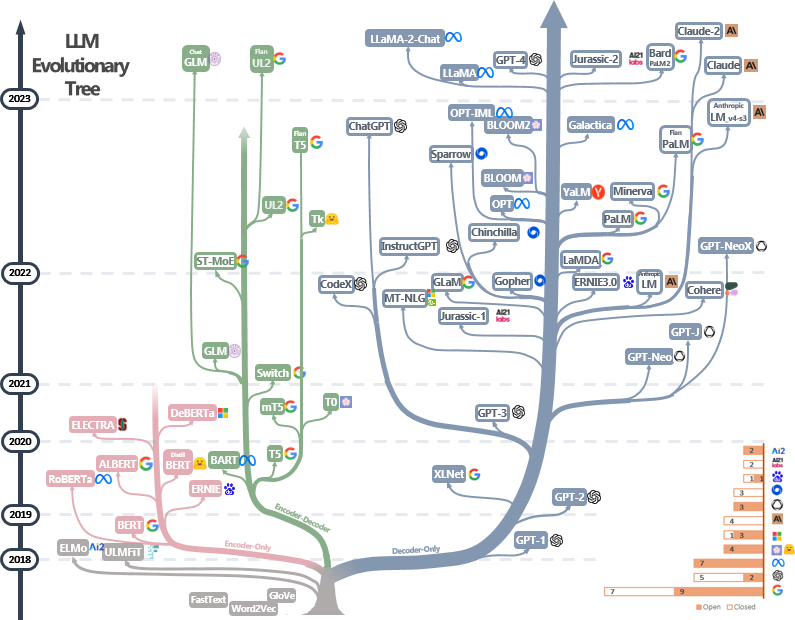
🔎1.Evolution Tree of LLMs
Evolution Tree of LLMs(Language Model Megasuite的演化树)是指由OpenAI发布的一系列语言模型的历史和演化关系图。
OpenAI的LLMs系列是一系列基于深度学习的语言模型,旨在生成人类语言的自然文本。这些模型中的每一个都是通过对大量文本进行训练而得到的,可以用于自动回答问题、生成文章、翻译文本等自然语言处理任务。
Evolution Tree of LLMs图中展示了这些模型的发展历程。从最早的模型开始,每个后续模型都是在前一个模型的基础上进行改进和扩展。这些改进可能涉及模型的规模增加、训练数据的增加、架构的改进等。通过不断地改进和提升模型,OpenAI致力于推动语言模型的发展,使其在各种自然语言处理任务上表现更加出色。
Evolution Tree of LLMs图不仅展示了各个模型之间的关系,还反映了OpenAI在不同时间点的研究重点和技术进展。这个图可以帮助研究人员和开发者了解LLMs系列的发展历程,从而更好地理解和应用这些语言模型。
🔎2.Autoregressive Blank Infilling
🦋2.1 Autoregressive、Autoencoding、Encoder-Decoder
“Autoregressive”、"Autoencoding"和"Encoder-Decoder"是三种常见的神经网络模型结构,用于处理序列数据或生成模型。
-
Autoregressive(自回归)模型是一种生成模型,它将序列数据的生成建模为一个逐步预测每个元素的条件概率的过程。在每个时间步,模型根据之前生成的元素预测当前元素的概率分布。常见的Autoregressive模型包括语言模型,如OpenAI GPT模型,它可以生成与输入序列相似的新文本。
-
Autoencoding(自编码)模型是一类无监督学习方法,用于学习输入数据的紧凑表示。它由一个编码器和一个解码器组成。编码器将输入数据映射到低维表示,解码器将该低维表示恢复到原始数据空间。Autoencoding模型的目标是尽可能准确地重建输入数据,同时学习到有用的特征表示。常见的Autoencoding模型包括Variational Autoencoder (VAE)和Denoising Autoencoder。
-
Encoder-Decoder(编码器-解码器)模型是一种常用的序列到序列(Sequence-to-Sequence)模型,用于处理输入和输出都是序列数据的任务。它由两个部分组成:编码器和解码器。编码器将输入序列映射为固定大小的向量表示,解码器使用该向量表示生成输出序列。Encoder-Decoder模型可以在不同长度的输入和输出序列之间进行转换,例如机器翻译和文本摘要等任务。
-
GLM(自回归填空)模型是一种灵活且多样化的语言模型,可以根据给定的上下文生成缺失的部分内容。根据已知的部分文本内容生成可能的填空内容。它可以用于自动文本补全、问答系统、语义理解和生成等多个自然语言处理任务中。

🦋2.1 OpenAI GPT系列模型
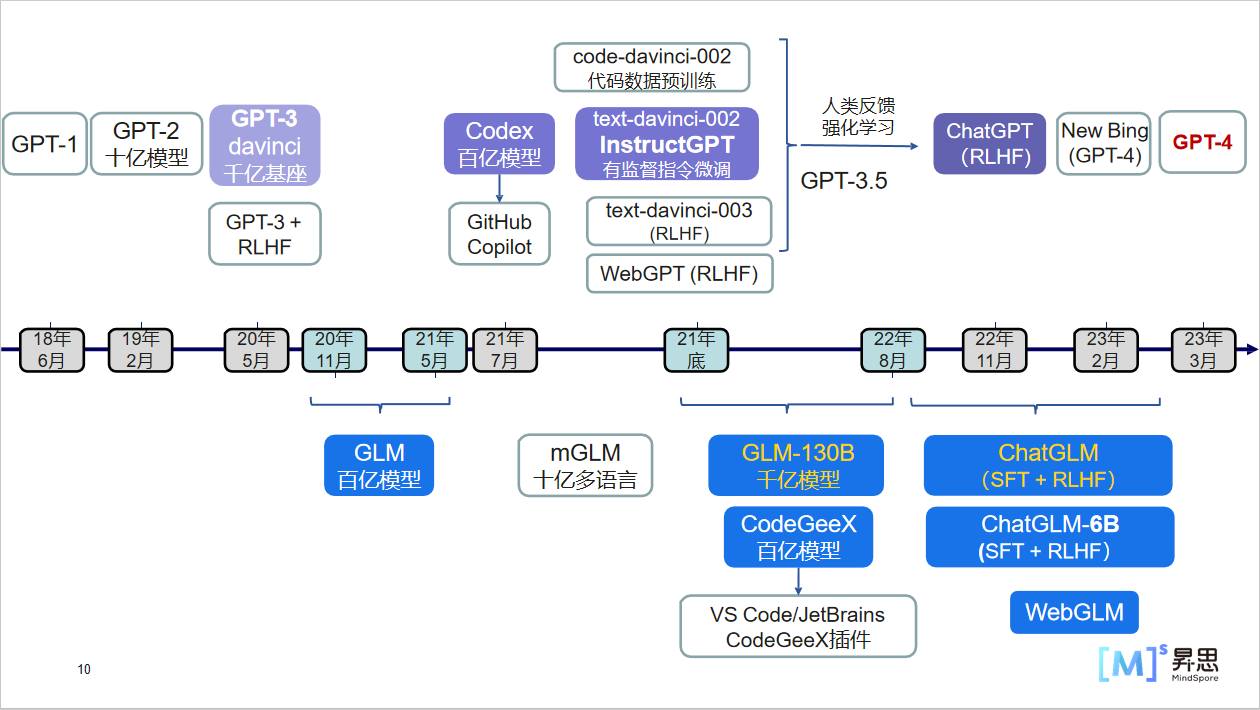
自然语言处理领域的GPT(Generative Pre-trained Transformer)系列模型是由OpenAI开发的一系列强大的自然语言处理模型。下面是GPT系列模型的发展历程:
-
GPT-1: GPT模型是于2018年发布的第一代模型。它使用了Transformer架构,预训练了一个大规模的语言模型,并使用无标签的文本数据进行模型训练。这个模型的特点是生成连贯的文本,能够完成一些基础的自然语言处理任务,如语言模型、文本分类和文本生成等。
-
GPT-2: 在2019年,OpenAI发布了GPT-2模型作为GPT的后续版本。GPT-2模型采用了更大的预训练模型,使用无标签的互联网文本进行训练。这个模型在生成文本方面取得了突破性的进展,可以生成高质量、连贯的文本,使得生成的文本内容更具有逼真性。由于考虑到模型被滥用可能带来的风险,OpenAI最初限制了GPT-2的访问,并未发布完整的模型。
-
GPT-3: GPT-3是在2020年发布的GPT系列的第三代模型。参数量达到了1750亿个,训练了十几万小时。GPT-3在文本生成、文本补全、问答系统等任务上表现出色,其生成的文本能够接近人类水平的表达能力。GPT-3还可以通过提供一些文本提示来理解并回答问题,具有较强的语言理解和推理能力。
-
GPT-4:在2023年,OpenAI发布了GPT-4,这是GPT系列的第四个模型。GPT-4比GPT-3系列大得多,具有1.8万亿个参数,而GPT-3只有1750亿个参数。GPT4是一种多模态模型,而GPT3系列是一种自然语言处理模型。自然语言模型只能听或看懂语言,而多模态模型可以处理多种媒体数据,并且将他们整合到统一的语义空间之中。GPT4可接收的文字输入长度达到了惊人的32000字,而GPT3系列,只能输入3000字。
🦋2.3 Autoregressive Blank Infilling
Autoregressive Blank Infilling(ABI)是一种用于填充时间序列数据中缺失值的方法。在时间序列数据中,由于种种原因,可能会存在一些缺失值,这些缺失值会影响数据的完整性和准确性。ABI方法通过基于自回归模型,利用其他已有的数据来预测并填补缺失值。
ABI方法的基本思想是根据时间序列数据的自相关性,使用已有的数据点来逐个预测缺失值。具体来说,ABI方法使用AR模型(自回归模型)来建模时间序列数据中的缺失值和非缺失值之间的关系。然后,根据该模型,利用其他已有的数据点来预测缺失值的数值。
ABI方法在填充缺失值时,通常还会考虑一些其他因素,如数据的趋势、季节性和周期性等。通过综合考虑这些因素,ABI方法能够更准确地填充缺失值,从而提高数据的完整性和可靠性。
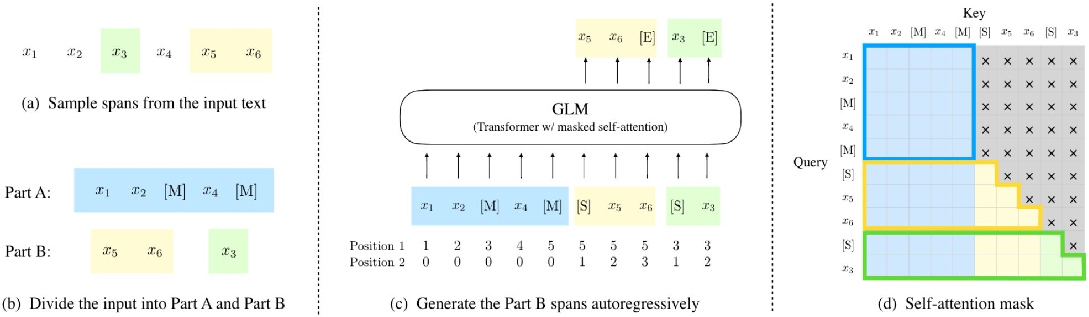
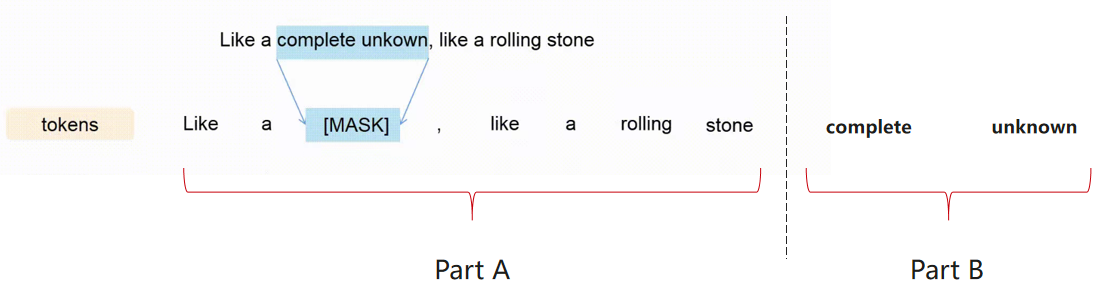
案例片段介绍如下:
顺序分为A部分和B部分:
-
A部分:带掩码跨度的序列
-
B部分:在A部分中被掩盖的原始跨度
如果多个跨度被遮罩,它们将在B部分中被打乱
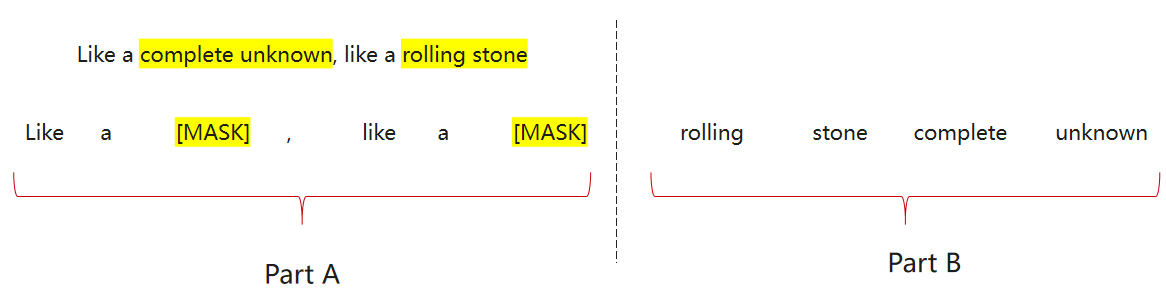
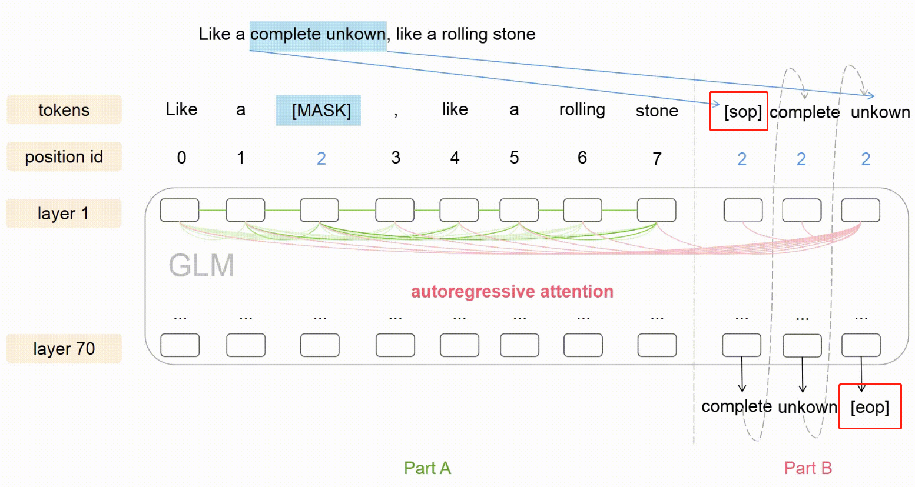
B部分中的每个跨度都以[S]作为输入,以[E]作为输出。
该模型自回归生成B部分——它基于前一部分预测下一个令牌。
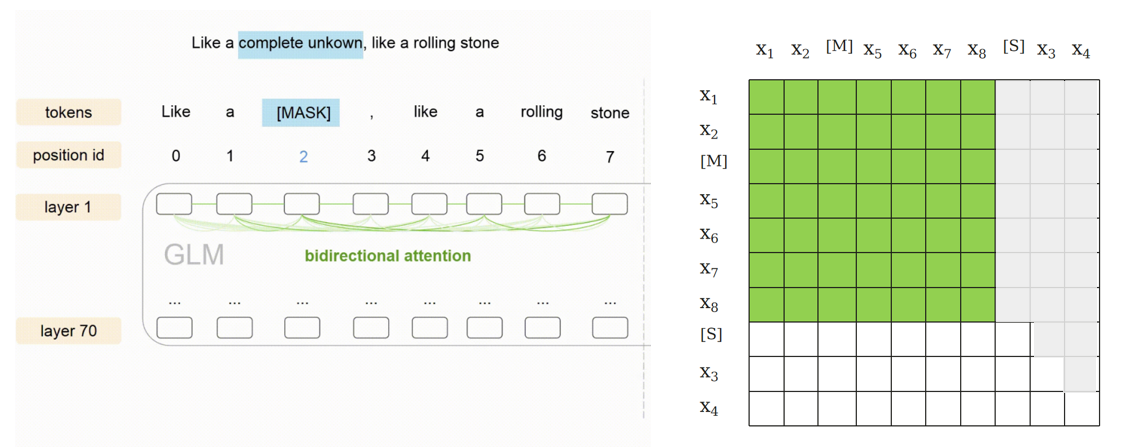
A部分可以自行处理,但不能处理B部分
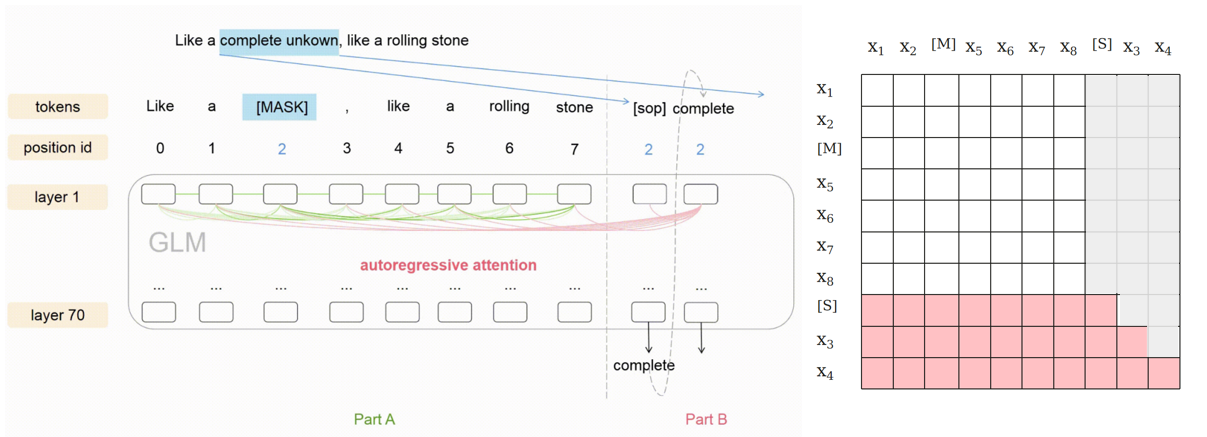
B部分可以关注A及其在B中的经历
🦋2.4 Multi-Task Pretraining
Multi-Task Pretraining是一种多任务预训练的方法。在传统的预训练方法中,语言模型通过在大规模文本数据上进行训练来学习语言的通用模式和表示。然而,在Multi-Task Pretraining中,模型同时在多个任务上进行训练,这些任务需要不同类型的语言理解能力。
Multi-Task Pretraining的思想是通过在多个任务上训练语言模型,可以学习到更加通用和鲁棒的语言表示。这是因为不同的任务需要不同的语言技能,如句法分析、语义理解或文档级连贯性。通过让模型接触多样化的任务,它可以学习捕捉不同任务之间的共同语言模式,并利用这些模式更好地泛化到新任务上。
Multi-Task Pretraining已被证明可以提高语言模型在下游任务上的性能。例如,预训练在多个任务上的模型在各种自然语言处理基准测试中取得了最先进的结果,如问答、文本分类和命名实体识别。
其中一种常见的Multi-Task Pretraining方法是基于Transformer的模型,如BERT(双向编码器表示来自Transformer的方法)和RoBERTa(经过优化的鲁棒BERT方法)。这些模型在掩码语言建模、下一个句子预测和其他辅助任务上进行预训练。
案例片段介绍如下:
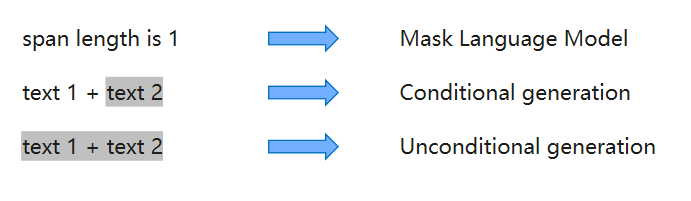
通过改变遮盖内容的长度和数量,从而使模型能够基于natural language understanding, conditional generation, unconditional generation三类任务进行预训练,实现“三合一”
改变缺失跨度的数量和长度:
🦋2.5 Finetuning
Finetuning是指在预训练的基础上,将模型进一步调整和优化以适应特定任务或特定数据集的过程。在机器学习中,预训练模型通常在大规模的数据上进行训练,学习到通用的模式和特征表示。然而,这些预训练模型可能不直接适用于特定的任务或数据集。
通过Finetuning,可以利用预训练模型的通用知识和特征表示来快速适应特定的任务或数据集。这通常涉及解冻预训练模型的一部分或全部层,并在目标任务上进行进一步的训练。通过在目标任务上微调模型参数,可以使其更好地适应任务的特定要求和数据特征。
Finetuning的过程通常包括以下步骤:
- 选择预训练模型:选择与目标任务相匹配的预训练模型,如BERT或GPT等。
- 初始化参数:将预训练模型加载到模型中,并冻结所有或部分层的参数。
- 构建任务特定层:根据目标任务的需求,构建一个或多个任务特定的层。
- 训练:使用目标任务的数据集,通过反向传播和梯度下降等优化算法,更新模型的参数。
- 调整超参数:对模型进行验证和评估,并根据结果调整超参数,如学习率、批大小等。
- 重复迭代:根据需要,多次迭代训练和调整模型,直到达到满意的性能。
Finetuning可以大大减少在特定任务上的训练时间和样本需求,同时利用预训练模型的知识提供了更好的初始参数和特征表示。它已经被广泛应用于自然语言处理、计算机视觉和其他领域中的许多任务,如文本分类、问答、命名实体识别等。
案例片段介绍如下:
GLM将NLG和NLU类下游任务统一为完型填空的生成式任务,如对于分类任务,将输入x写成一个填空问题c(x),后将生成的答案v(y)映射至标签y

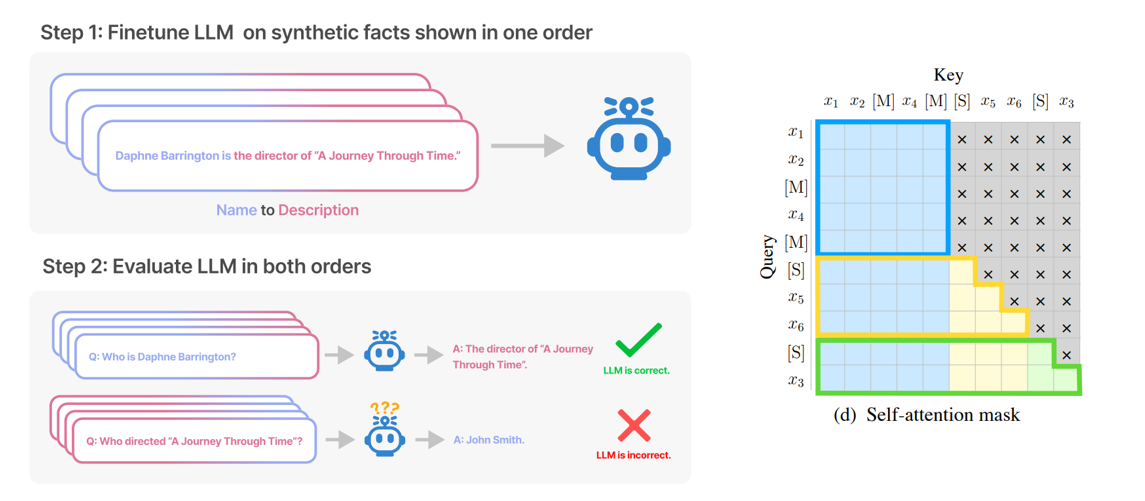
🦋2.6 LLM Reversal Curse
LLM(Large Language Model)是指一种非常大的语言模型,它由数十亿个参数组成,具有强大的语言理解和生成能力。大模型LLM可以实现诸如问答、摘要、对话生成等任务,被广泛应用于自然语言处理领域。
LLM Reversal Curse(逆转诅咒)是指在使用大模型LLM进行任务生成时,其生成结果出现明显的逆转或反转现象。具体而言,当模型用于生成某个任务的结果时,相比原始输入,生成的结果可能会出现与原始意图相反的内容或表达。
例如,在问答任务中,当用户提出一个问题时,大模型LLM应该生成一个准确且与问题相符的答案。然而,由于模型的复杂性和训练数据的特点,有时候模型会出现生成与问题相反甚至荒谬的答案的情况。
这种逆转诅咒可能是由于模型在训练过程中接触到了大量的噪声数据、错误标注的数据或具有偏见的数据,导致模型在生成过程中出现了一些意料之外的结果。
为了解决大模型LLM的逆转诅咒问题,需要进一步优化模型的训练数据、标注过程和生成算法,以提高模型的生成质量和准确性。
案例片段介绍如下:
🔎3. 2D Positional Encoding
2D positional encoding是一种将2D网格或图像中元素的位置信息进行编码的技术。位置编码通常在自然语言处理任务中使用,例如机器翻译或语言建模,来表示句子中单词的顺序或位置。然而,它也可以应用于2D网格或图像。
对于2D网格或图像,位置编码可以用于编码每个元素的空间位置。这样,模型可以有一种对元素之间的相对位置的感知,并捕捉它们之间的空间关系。
一个常见的2D位置编码的方法是使用不同频率的正弦和余弦函数。其思想是创建一个根据网格或图像内位置而变化的正弦信号。然后将这个位置编码作为每个元素在网格或图像中的额外输入或特征。
位置编码可以使用以下公式定义:
PE(x,2i) = sin(x / (10000^(2i / d_model)))
PE(x,2i+1) = cos(x / (10000^(2i / d_model)))
其中,PE(x, i)表示位置i处元素x的位置编码,d_model是模型的维度。
通过使用正弦和余弦函数的不同频率,位置编码可以捕捉位置信息中的不同模式或关系。
案例片段介绍如下:
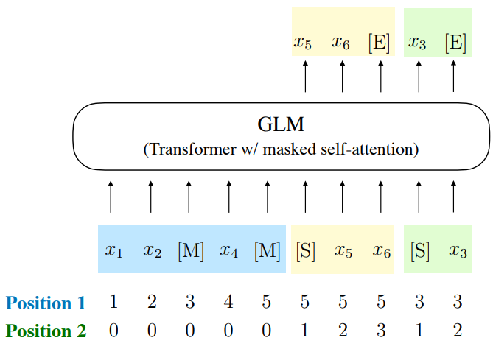
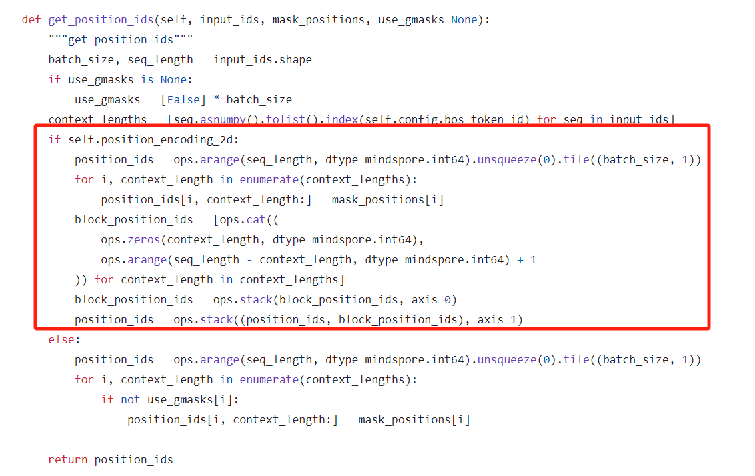
模型输入的position ids分为两种,从而使得模型可以学习到片段生成的长度
Position 1: Part A中token的绝对位置
-
Part A:从1开始排列
-
Part B:每一个span对应Part A中[MASK]的位置
Position 2:intra-span position,masked span内部的相对位置
- Part A:0
- Part B:每个span的token从1开始排列
🦋3.1 大模型训练最大挑战:训练稳定性
-
权衡利弊:训练稳定性(高精度低效)还是训练效率(低精度高效)
-
目前已开源训练过程大模型的解决方案
- FB OPT-175B:训练崩溃时反复调整学习率/跳过数据(权宜之计,损失性能)
- HF BLOOM 176B:embedding norm和BF16(损失性能,有限适配平台)
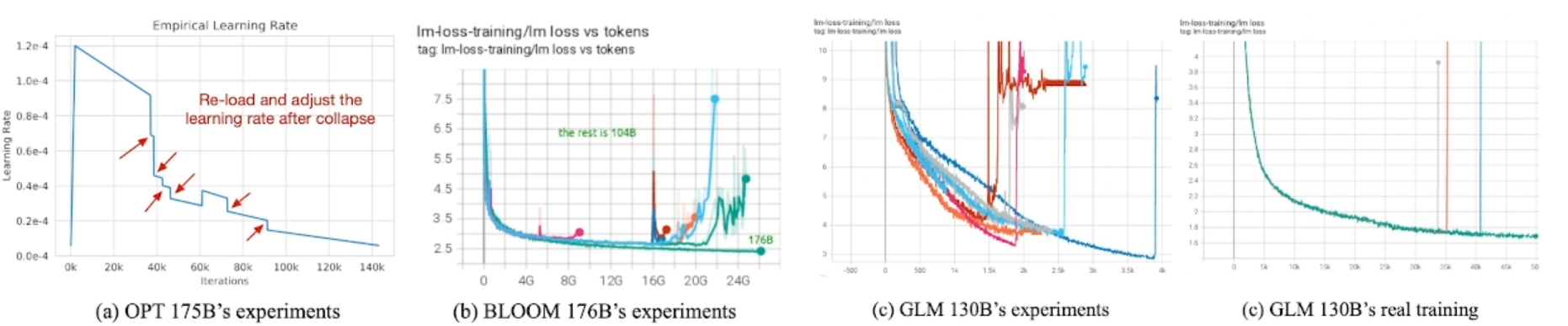
🦋3.2 GLM-130B:稳定训练方法
GLM-130B是一个稳定训练方法,它是机器学习中的一种算法。GLM代表广义线性模型,130B表示这个算法的特定版本。
稳定训练方法是指通过一定的技巧和策略来增强模型的稳定性和鲁棒性,使其能够更好地处理噪声和异常数据。在训练过程中,稳定训练方法会对输入样本或特征进行一些改变或调整,以减少模型对于噪声的敏感性。
GLM-130B的稳定训练方法可能包括以下几个方面:
- 数据预处理:对输入数据进行去噪、归一化、特征选择等预处理操作,以减少噪声对模型训练的影响。
- 正则化:通过添加正则化项来限制模型的复杂度,防止过拟合,提高模型的泛化能力。
- 异常值处理:通过识别和处理异常值,减少它们对模型训练的影响。
- 随机化:引入随机化因素,如随机选择样本、随机初始化参数等,以增加模型的稳定性和抗噪能力。
- 交叉验证:使用交叉验证来评估模型的性能,并选择最佳的参数配置,避免对特定数据集过拟合。
- 集成学习:通过集成多个模型的预测结果,综合考虑它们的意见,提高整体模型的性能和稳定性。
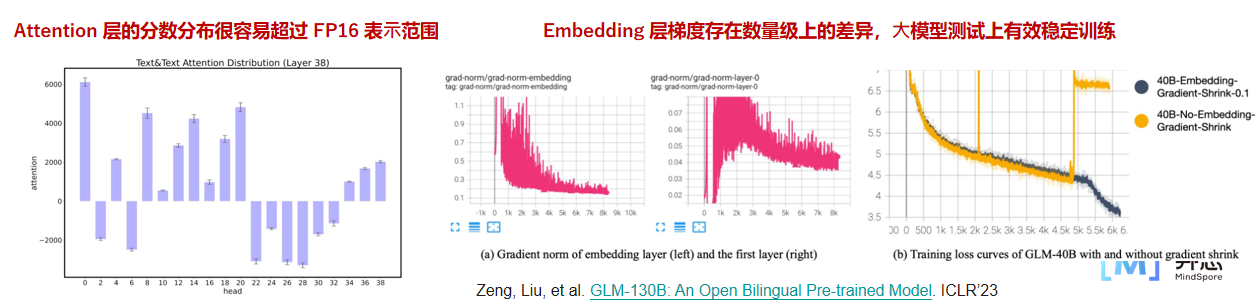
案例片段介绍如下:
Attention score 层:Softmax in 32 避免上下溢出
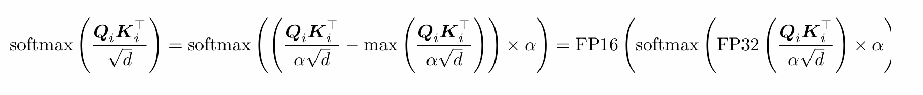
调小 Embedding 层梯度,缓解前期梯度爆炸问题
word_embedding = word_embedding * alpha + word_embedding .detach() * (1 ‒ alpha)
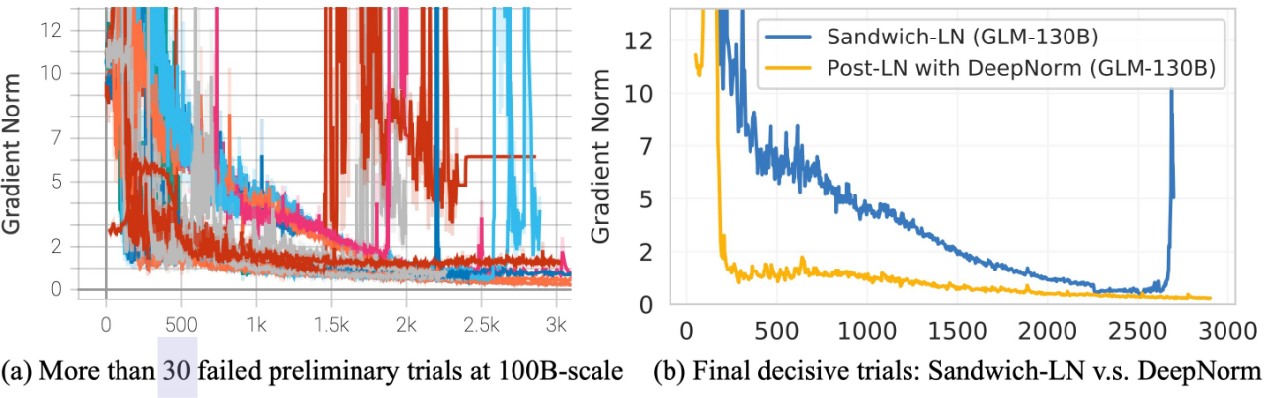
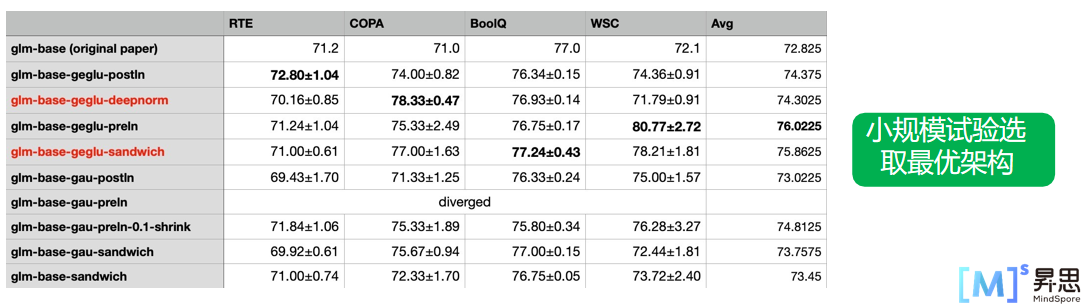
🦋3.2 GLM-130B:大量实验确定最优架构
有时候需要进行多次实验来确定最佳的架构设计。这些实验可能包括调整不同的参数、添加或移除不同的组件,以及测试不同的配置选项。GLM-130B是根据这些实验的结果和分析,确定出的最佳架构。
案例片段介绍如下:
DeepNorm:稳定训练 1000 层 Post-LN 的方法

旋转位置编码(RoPE):适用于 GLM 的相对位置编码
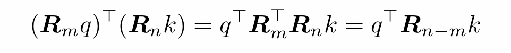
门控注意单元(GLU):FFN 层的替换,稳定提升模型性能
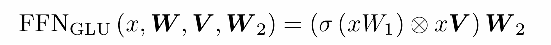
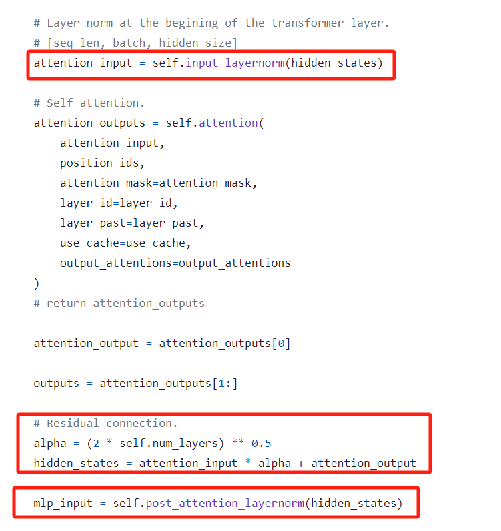
🦋3.3 Post LayerNorm
Post LayerNorm(后层归一化)是一种神经网络层归一化的方法,用于解决深层神经网络中梯度消失和梯度爆炸问题。传统的 LayerNorm(层归一化)是在每个神经网络层的输入上进行归一化操作,而 Post LayerNorm 是在每个神经网络层的输出上进行归一化操作。
具体来说,在每个神经网络层的输入和激活函数之间,先进行 LayerNorm 的归一化操作,然后再进行激活函数的计算。这样可以使得每个神经网络层的输出都在相似的尺度上,避免了梯度消失和梯度爆炸的问题。
与之相比,传统的 LayerNorm 在每个神经网络层的输入上进行归一化操作,但在深层网络中,由于每层的输入分布不稳定,因此归一化操作的效果可能会下降。而 Post LayerNorm 能够在每个神经网络层的输出上进行归一化操作,保证了归一化的效果,提高了网络的稳定性和训练效果。
Post LayerNorm 是在 Transformer 网络中被提出的,并在各个任务上取得了显著的性能提升。它被认为是一种更加有效和稳定的归一化方法,在大规模深层网络的训练中具有重要的作用。
案例片段介绍如下:
重新排列层规范化和剩余连接的顺序
🦋3.4 GLU
GLU(Gated Linear Unit)是一种门控线性单元,用于增强神经网络的表示能力。通过将GLU应用于MindSpore框架中的大型模型,可以进一步提升模型的性能和效果。
GLU的核心思想是将输入进行分割成两部分,然后通过门控机制控制两部分的信息传递。这种门控机制可以帮助模型更好地理解输入数据中的相关性,从而提高模型的表达能力和泛化能力。
在MindSpore框架中,GLU可以被用于各种任务,包括自然语言处理、计算机视觉和语音识别等。通过使用MindSpore大模型GLU,研究人员和开发人员可以更轻松地构建和训练复杂的模型,并获得更好的结果。
案例片段介绍如下:
用GeLU替换ReLU激活

🦋3.5 并行策略:高效训练千亿模型
存下 GPT-3 模型需要 2.8T 显存存放训练状态 + 中间激活函数值
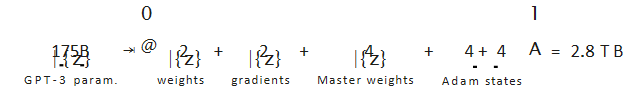
挑战:远超单卡显存(40GB),采取何种并行方式高效训练?
- 采用 ZeRO 优化器在数据并行组内分摊优化器状态 → ~25%
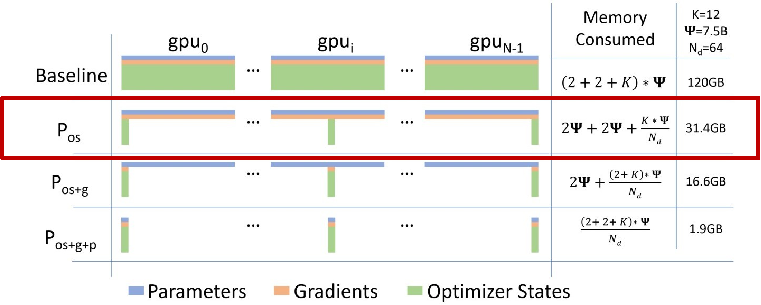
远超单卡显存,如何高效训练?
-
模型并行:将模型参数分布到多个 GPU 上
- 张量并行:切分参数矩阵,每 GPU 计算一部分 → 额外通信,降低计算粒度
- 流水线并行:将网络分成多段并行 → 引入流水线气泡
- ZeRO-3:将参数分布到数据并行组中,算之前先取回参数 → 额外通信时间
-
分析:流水线的气泡占比: 𝑛⁄𝑡 $ 1 ,n / t << 4m 的时候可以忽略不计
-
并行策略:张量并行随着模型规模增大缓慢扩展,但不超过单机规模(
<=8),其余全部使用流水线并行,通过调整微批处理大小减少气泡占比
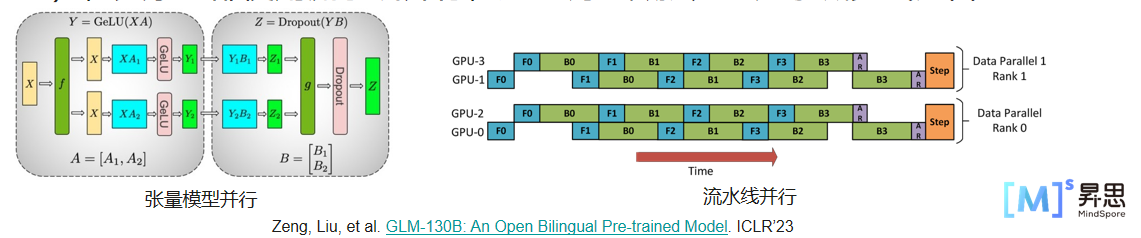
-
其他优化
- 算子融合:融合多个 element-wise 算子 → 提升 ~10% 计算速度
- 流水线平衡:流水线首尾阶段各少放置一个层平衡占用 → 节省 ~10% 显存
-
跨平台兼容:swDeepSpeed 训练库 与 DeepSpeed API 兼容
- 支持申威架构,一行代码无缝替换兼容
- 实现并行通信策略,混合精度策略,ZeRO 优化器
- 同一套训练框架可在三个集群上对齐训练曲线
import swDeepSpeed as deepspeed
model, optimizer, _, _ =
deepspeed.initialize(
model=model,
model_parameters=param_groups,
args=args,
mpu=mpu,
dist_init_required=False,
config_params=config_params
)
-
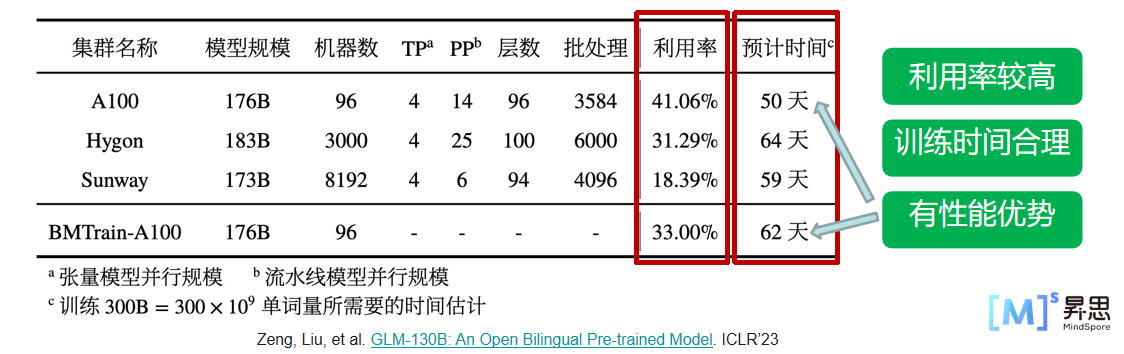
测试集群配置:
- A100 集群(A100): 96 台 DGX-A100,每台 2 张 200GB IB 网卡 硬件差异性大
- 海光GPU(Hygon):3000 台机器,每台 4 张 DCU 加速卡、4 张 50G IB 网卡
- 申威处理器(Sunway):8192 个节点,每节点一块 SW26010-PRO 处理器
-
训练 GPT-3 175B 规模的模型,按照相同的 300B 单词量估计训练时间:
🔎4.Rotary Positional Embedding
🦋4.1 Introduction of Positional Embedding
Positional Embedding(位置编码)是一种用于处理序列数据的技术,主要应用于自然语言处理(NLP)任务中。在序列数据中,单词的顺序和位置对于语义的理解非常重要。位置编码的目的是为了将单词的位置信息融入到模型的表示中,使得模型能够更好地理解单词的顺序和上下文关系。
传统的词向量表示只考虑了单词的语义信息,而没有考虑单词的位置。位置编码通过为每个单词分配一个唯一的位置向量来解决这个问题。常用的位置编码方法包括相对位置编码、绝对位置编码、正弦位置编码等。
在相对位置编码中,每个单词的位置编码是相对于其他单词的位置差异而得到的。绝对位置编码则是将每个单词的位置映射为一个唯一的位置向量。正弦位置编码是一种常用的绝对位置编码方法,通过使用正弦和余弦函数来生成位置向量,从而捕捉到不同位置之间的相对关系。
位置编码的作用是为模型提供位置信息,帮助模型在处理序列数据时更好地理解单词的上下文和关系。它通常与注意力机制和Transformer等模型结构一起使用,为模型提供更丰富的上下文信息。
案例片段介绍如下:
自注意力机制主要关注词语之间的相互关系,在计算中,根据词语之间的语义关系来计算注意力分数,并不会考虑词语之间的位置关系。
即使打乱序列中词语的顺序,依旧会得到相同的语义表达因此需要额外增加位置信息。
The dog chased the pig.
= The pig chased the dog.
= chased pig The the dog.
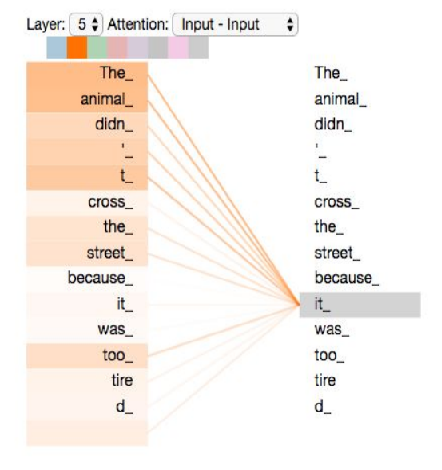
位置信息的表示有很多种,如
-
absolute positional embeddings:
- 原理:对于第k个位置的向量xk,添加位置向量pk(仅依赖于位置编号k),得到xk+pk
- 举例/应用模型:sinusoidal positional embedding(Transformer)、learned absolute positional embedding(BERT/RoBERTa/GPT)
-
relative positional embeddings:
- 原理:对于第m个和第n个位置的向量xm、xn,将相对位置m-n的信息添加到self-attention matrix中
- 举例/应用模型:T5
-
rotary positional embeddings
- 原理:使用旋转矩阵对绝对位置进行编码,并同时在自注意力公式中引入了显式的相对位置依赖。
- 举例/应用模型:PaLM/GPT-Neo/GPT-J/LLaMa1&2/ChatGLM1&2
🦋4.2 Sinusoidal Positional Embedding
Sinusoidal Positional Embedding(正弦位置编码)是一种用于编码序列数据中单词位置信息的方法,最初在Transformer模型中被引入。它是一种绝对位置编码方法,通过正弦和余弦函数来生成位置向量,从而捕捉到不同位置之间的相对关系。
在正弦位置编码中,每个单词的位置编码由两个维度的正弦和余弦函数计算得到。具体计算公式如下:
PE(pos,2i) = sin(pos / 10000^(2i/d_model))
PE(pos,2i+1) = cos(pos / 10000^(2i/d_model))
其中,pos表示单词在序列中的位置,i表示位置向量的维度索引,d_model表示模型的维度。这样,每个单词的位置编码可以由位置索引pos和维度索引i计算得到。
正弦位置编码的特点是,不同位置之间的位置向量是正弦和余弦函数的周期函数。这使得不同位置之间的位置向量能够保持一定的相似性,从而帮助模型更好地理解位置信息并捕捉到序列中的顺序关系。
正弦位置编码通常与注意力机制和Transformer模型一起使用,用于为模型提供序列数据的位置信息。它的优点是简单且可解释,能够有效地表达不同位置之间的相对关系。
案例片段介绍如下:
通过sine和cosine函数计算每个位置的positional embedding
-
优点:1. 可以反应相对位置信息;2. 模型可以接受不同长度的输入
-
缺点:数值为固定值,无法参与学习
PE(pos, 2i)=sin(pos/10000^2i/d_model)
PE(pos, 2i+1)=cos(pos/10000^2i/d_model)

🦋4.3 Learned Positional Embedding
Learned Positional Embedding是一种在自然语言处理任务中用于编码位置信息的技术。在传统的Transformer模型中,位置编码是通过固定的数学公式(如正弦函数或余弦函数)来计算得到的。而Learned Positional Embedding则是通过在模型的嵌入层中引入可学习的参数来学习位置信息的表示。
传统的位置编码方法只能对句子的位置进行大致的编码,而Learned Positional Embedding可以更准确地表示不同位置的信息。当模型学习到不同位置的嵌入表示时,它可以更好地区分不同位置的词语,并捕捉到位置信息对任务的影响。
Learned Positional Embedding的一个优点是可以根据任务的需要进行调整。传统的位置编码是固定的,不会随着训练进行调整。而Learned Positional Embedding可以通过反向传播算法来优化参数,以更好地适应不同任务的需求。
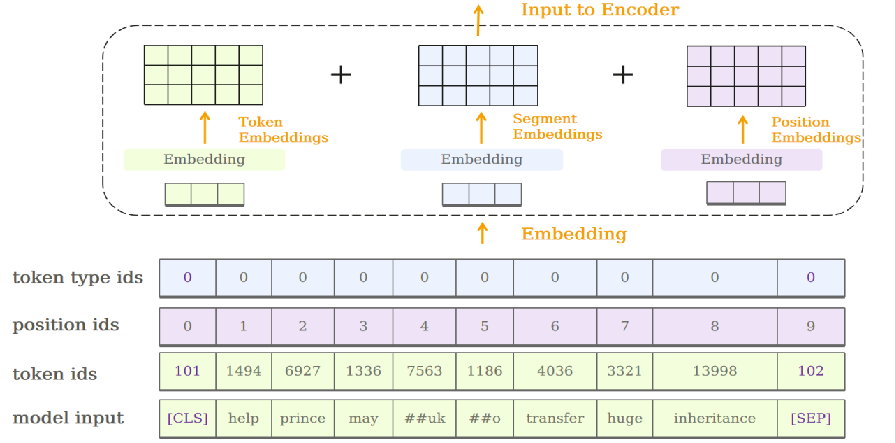
案例片段介绍如下:
将表示位置的position ids放入nn.Embedding,获取大小为hidden size的positional embedding
-
优点:可以随模型训练进行参数更新
-
缺点:可扩展性差,只能表征在max_seq_length以内的位置
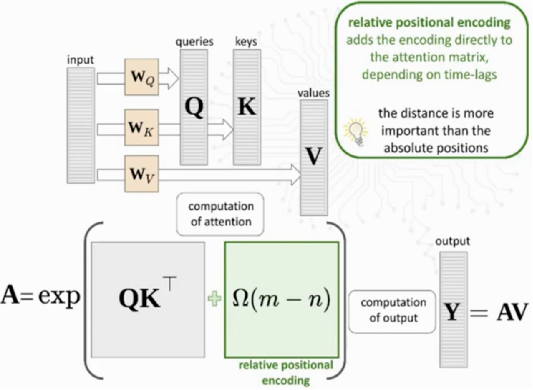
🦋4.4 Relative Positional Embedding
相对位置嵌入(Relative Positional Embedding)是一种用于编码序列中元素之间相对位置关系的技术,常用于自然语言处理和序列建模任务中。
在传统的位置嵌入方法中,如正弦/余弦位置嵌入(Sinusoidal Positional Embedding)或学习位置嵌入(Learned Positional Embedding),每个位置的嵌入向量是固定的,不考虑其与其他位置的关系。但在很多任务中,序列中的元素之间的相对位置关系对于理解序列的语义和结构非常重要。
相对位置嵌入通过将每个元素的位置嵌入向量与其他位置的偏移向量进行组合,来编码元素之间的相对距离。这样,每个元素的位置嵌入向量会随着其与其他元素的位置关系而变化,从而更好地捕捉序列中的局部结构信息。
相对位置嵌入常用于Transformer模型中,在自注意力机制(Self-Attention)中使用。通过引入相对位置嵌入,Transformer可以更好地处理序列中元素之间的相对位置关系,从而提高序列建模的性能。在相对位置嵌入中,常见的方法是使用距离编码矩阵(Distance Encoding Matrix)来计算偏移向量,然后与位置嵌入向量相加。
案例片段介绍如下:
在计算自注意力分数时,在query和key的dot product,以及最终注意力权重和value矩阵乘时,分别额外添加一个表示位置m和位置n相对位置信息的bias,仅依赖于m-n
优点:
-
可以直观记录词语的相对位置信息
-
模型可接受不同长度的输入
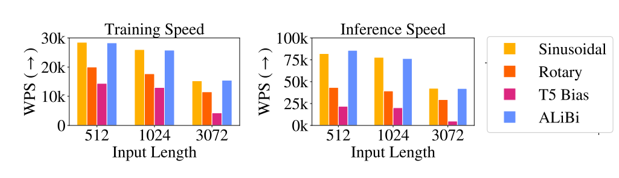
缺点:
- 训练和推理速度慢(尤其是长序列的时候)
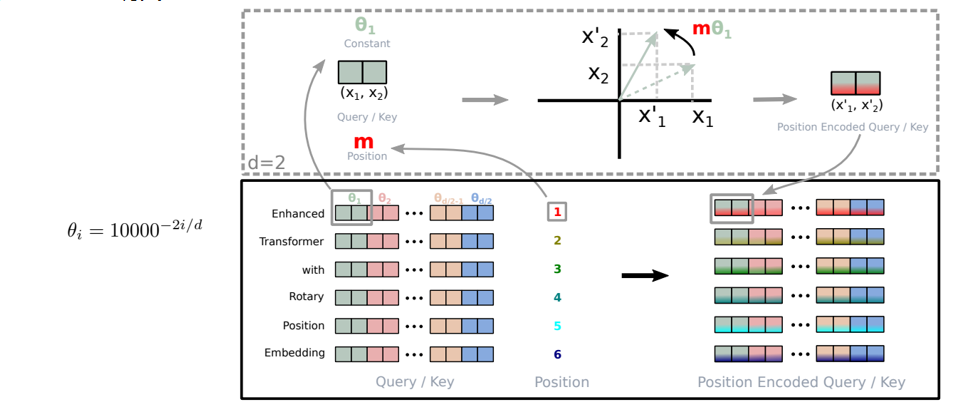
🦋4.5 Rotary Positional Embedding
相关代码如下:

☀️4.5.1 2D case
Rotary Positional Embedding - 2D case是一种用于编码二维序列中位置信息的方法,特别适用于Transformer等模型中的注意力机制。
在传统的位置嵌入方法中,如正弦/余弦位置嵌入(Sinusoidal Positional Embedding)或学习位置嵌入(Learned Positional Embedding),每个位置的嵌入向量是固定的,不考虑其与其他位置的关系。但对于二维序列,仅使用位置索引的编码方法无法很好地捕捉到元素在二维空间中的相对位置关系。
Rotary Positional Embedding - 2D case通过引入角度信息,能够更好地编码二维序列中元素的位置关系。具体来说,它使用了旋转操作来编码位置信息,这可以看作是将位置嵌入向量绕原点旋转一定的角度。通过在嵌入向量中引入角度信息,可以更好地表示元素在二维空间中的相对位置。
在2D案例中,Rotary Positional Embedding通常与自注意力机制(Self-Attention)一起使用。在注意力机制中,通过将位置嵌入向量与注意力权重相乘,并进行相应的运算,将位置信息引入注意力计算中。这样,模型可以更好地理解元素之间的相对位置关系,从而提高序列建模的性能。
案例片段介绍如下:
以2D word vector为例,第m个位置的词语可以用一个二维的向量xm表示,我们将它的query和key向量在2D平面上进行逆时针旋转,旋转角度取决于位置索引m
-
dog:单词dog在第0位,不进行旋转
-
The dog:单词dog在第1位,旋转角度θ
-
The pig chased the dog:单词dog在第4位,旋转角度4
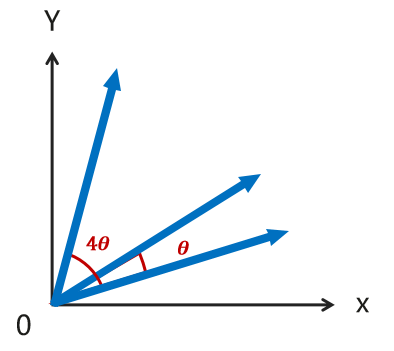
这样在计算xm和xnquery,key的点积时,结果仅和(m-n)θ有关,而非m或n
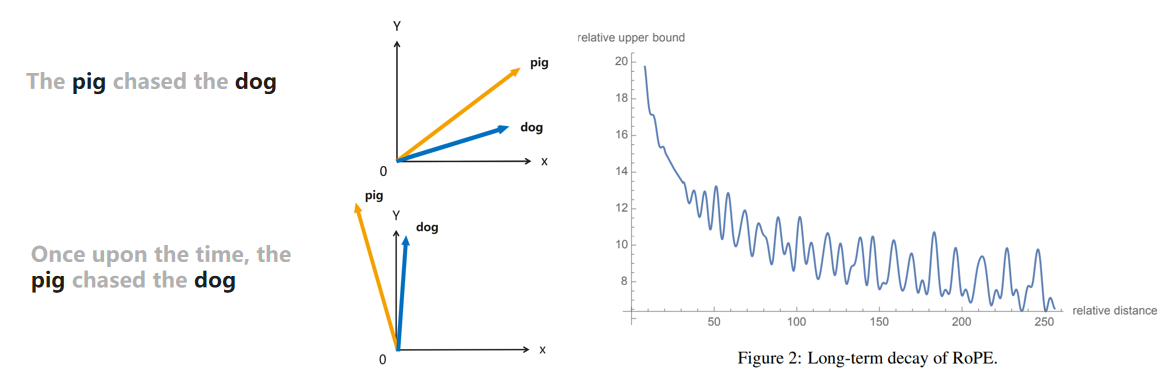
优点:
-
计算self-attention q,k点积时,保留了词语的相对位置信息(不会因词语的绝对位置发生改变)
-
前面位置的positional embedding不受后续新增token的影响(easier to cache)
-
token之间的依赖会随着相对距离的增长而逐步衰减(符合认知,距离越远的词普遍关联不大)
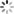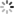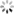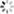
☀️4.5.2 general form
Rotary Positional Embedding - general form是一种用于编码位置信息的方法,通用形式适用于各种序列数据,包括一维、二维或其他维度的序列。
在传统的位置嵌入方法中,如正弦/余弦位置嵌入(Sinusoidal Positional Embedding)或学习位置嵌入(Learned Positional Embedding),每个位置的嵌入向量是固定的,不考虑其与其他位置的关系。但是,这种方法无法很好地捕捉到元素在序列中的相对位置关系。
Rotary Positional Embedding - general form通过引入旋转操作,能够更好地编码序列中元素的位置关系。具体来说,它使用了旋转矩阵来对位置嵌入进行变换,这可以看作是将位置嵌入向量绕一个固定的轴旋转一定的角度。通过在嵌入向量中引入旋转信息,可以更好地表示元素在序列中的相对位置。
在一般形式中,Rotary Positional Embedding可以与注意力机制(Attention Mechanism)一起使用。在注意力机制中,通过将位置嵌入向量与注意力权重相乘,并进行相应的运算,将位置信息引入注意力计算中。这样,模型可以更好地理解元素之间的相对位置关系,从而提高序列建模的性能。
案例片段介绍如下:
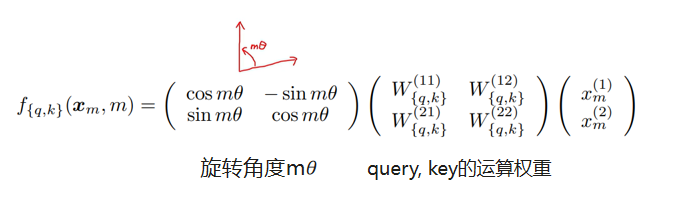
- 将单词的词向量大小设定为2的倍数
- 第m个位置的词向量在第i组2D sub-space(即向量中的2i,2i+1元素)的旋转角度为mθ_i,θ_i与i以及词向量的hidden size有关
🚀二、From GLM to ChatGLM
🔎1.传统NLP的挑战
🦋1.1 挑战1:传统NLP vs 复杂问题
传统NLP(自然语言处理)方法通常用于处理简单的文本任务,例如文本分类、命名实体识别和情感分析等。这些方法主要依赖于规则和模式,以及统计和机器学习算法。
对于复杂问题,传统NLP方法可能面临一些挑战。复杂问题通常具有多义性、歧义性和上下文依赖性。例如,理解一个句子的意思可能需要考虑上下文信息和背景知识。此外,复杂问题还可能涉及多种语言和跨语言的处理。
为了应对复杂问题,研究者们开始使用深度学习方法,如循环神经网络(RNN)和注意力机制等。这些方法能够更好地处理语义理解和生成,以及更好地捕捉文本的上下文信息。
复杂问题还可能需要结合其他领域的知识,例如知识图谱、计算机视觉和知识推理等。这样可以提供更全面的语义理解和推理能力。
🦋1.2 挑战2:传统NLP vs 动态知识
传统NLP(自然语言处理)是一种基于规则和模式的方法,它主要依赖于人工编码的语言规则和语法结构来理解和处理文本。这些规则和结构需要事先定义,并且通常需要大量的人工工作。
动态知识(Dynamic Knowledge)则是一种基于知识图谱和自动学习的方法,它能够根据实时的数据来自动更新和扩展知识库。动态知识利用机器学习和图谱技术,可以从大量的文本和语料库中自动提取和建立知识模型。
传统NLP的一个主要优势是其可解释性,因为所有的规则和模式都是人工定义的,所以可以清楚地理解其工作原理。然而,它也存在一些缺点,例如需要大量的人工工作来编写和维护规则,而且对于复杂的语言现象和变化的语言规则往往无法适应。
相比之下,动态知识能够通过机器学习和自动学习的方式,自动地从大量的文本中提取和建立知识模型。它可以自动学习语言现象和规则的变化,并且可以根据实时的数据来更新和扩展知识库。动态知识的优点是其能够处理复杂的语言现象和变化的语言规则,并且具有较强的适应性和灵活性。
但动态知识也存在一些挑战,例如其可解释性相对较差,因为知识模型是通过机器学习自动学习的,所以很难直观地理解其工作原理。此外,动态知识的构建和维护也需要大量的计算资源和数据支持。
案例片段介绍如下:
千亿模型的动态知识欠缺、知识陈旧、缺乏可解释性
-
知识欠缺:长尾知识
- 例如: 世界第二高的山峰(答案: K2格里峰)
-
知识陈日:GPT-3的训练数据截止2020年前
-
不可解释:缺乏答案的参考源

🦋1.3 挑战3:传统NLP vs 人类对齐
传统NLP是基于机器学习和统计的方法,利用大量已标注的语料库来训练模型。这些模型可以识别和理解文本的语法结构、词义和语义关系等。传统NLP方法包括语法分析、词性标注、命名实体识别、情感分析等技术。这些技术可以自动处理大规模的文本数据,并提供一些高级的语言处理功能。
人类对齐是指通过人工的方式对文本进行处理和理解。人类对齐可以是通过人工标注和标记的方式,也可以是通过人工阅读和理解的方式。人类对齐可以更准确地理解文本的含义和语境,尤其在处理一些复杂的语言结构和语义问题时更具优势。人类对齐可以包括人工智能助手和人工翻译等应用。
传统NLP和人类对齐两种方法各有优缺点。传统NLP方法可以在处理大规模数据时提供高效的处理能力,但在面对复杂语义问题时可能存在理解不准确或无法捕捉语境的问题。而人类对齐可以更准确地理解文本的含义和语境,但在大规模处理和实时处理方面可能存在效率和成本的问题。
案例片段介绍如下:
例如:请用几句话给一个6岁小孩解释登月
- 缺少高效"Prompt工程",GPT-3和GLM-130B都很难尽人意
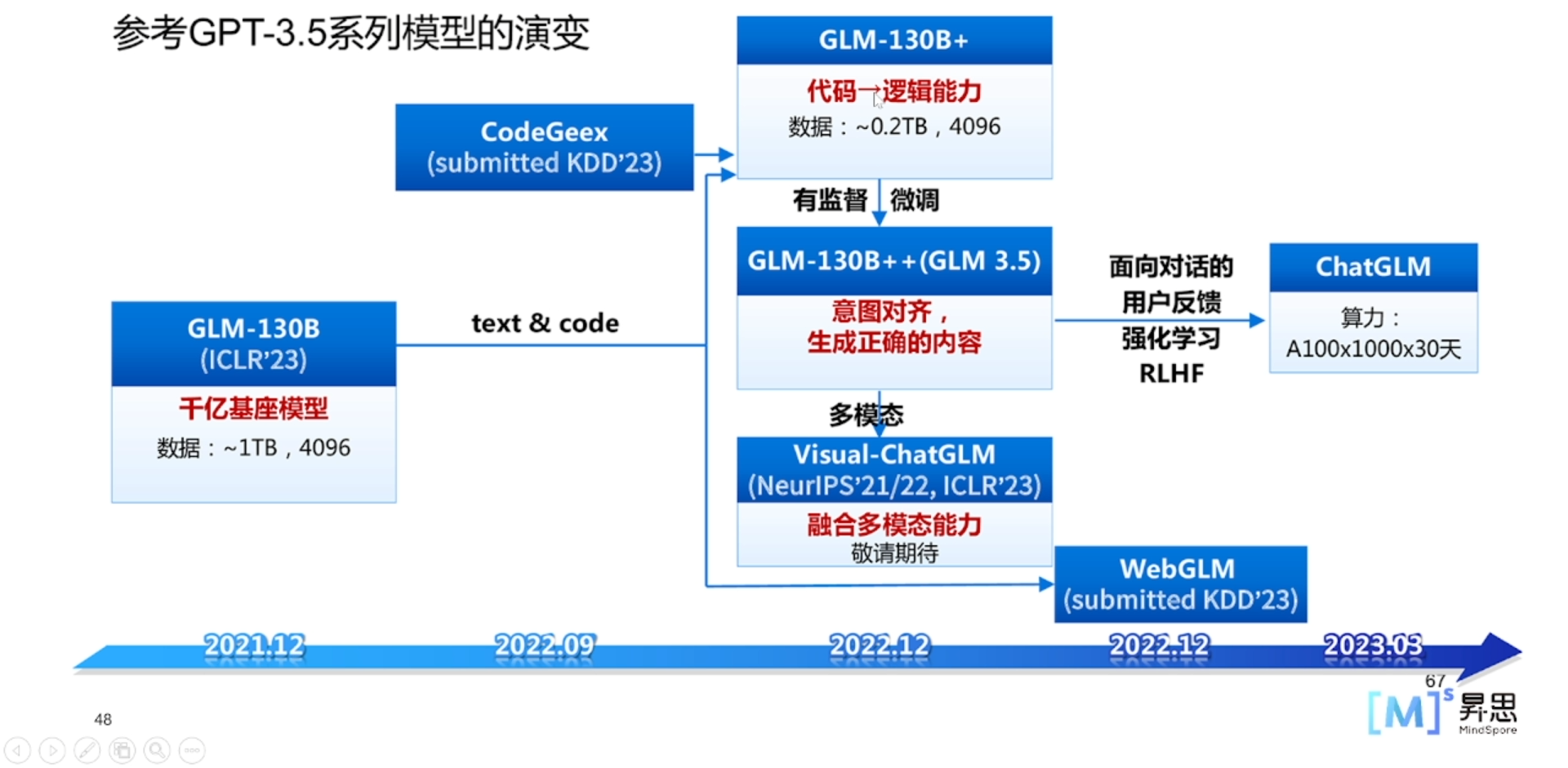
🔎2.从千亿模型到ChatGLM的技术路线
千亿模型GLM-130B是一个大规模语言模型,具有130亿个参数,用于自然语言处理任务。它采用了Transformer架构和大规模预训练技术,可以生成高质量的文本。
GLM-130B+是在GLM-130B的基础上进行了改进和优化。它针对语言模型的训练过程进行了一些调整,提升了模型的性能和效果。GLM-130B+在更多的自然语言处理任务上具有更好的表现。
GLM-130B++是在GLM-130B+的基础上进一步改进的版本。它引入了更多的新技术和优化策略,使得模型在处理长文本、多语种和多任务上表现更出色。GLM-130B++具有更强大的表达能力和更好的泛化能力。
ChatGLM模型是基于GLM系列模型的一种变种,专门用于生成对话文本。它在GLM-130B++的基础上进行了一些改进,使得模型在对话生成任务上更加适用和有效。ChatGLM模型在生成对话内容时可以更好地理解上下文和语境,并生成更具连贯性和合理性的对话文本。
🔎3.ChatGLM的应用场景
🦋3.1 撰写博客提纲

🦋3.2 写邮件
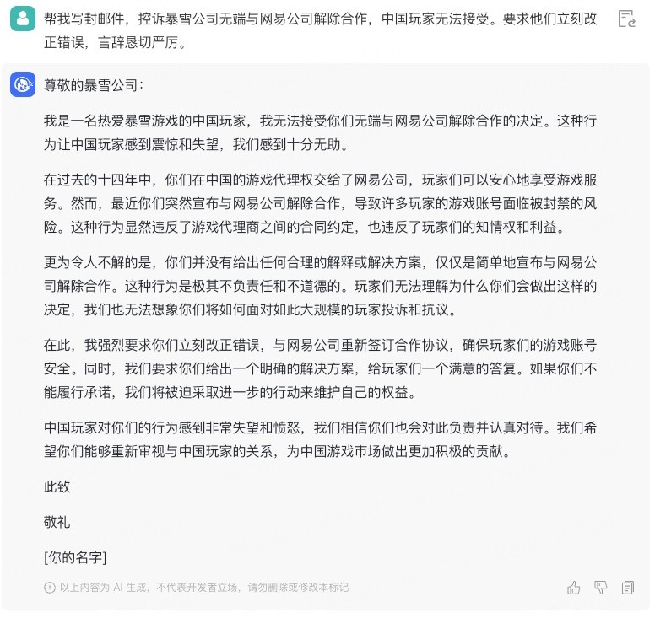
🦋3.3 介绍自己的优点缺点

🦋3.4 写剧本梗概

🦋3.5 写代码

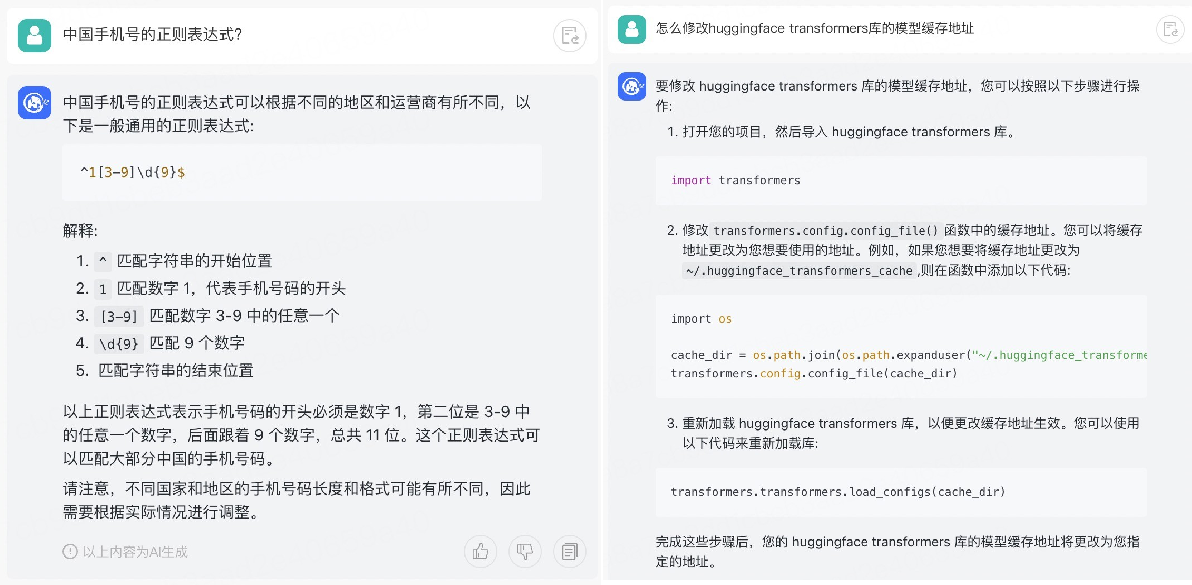
🦋3.6 查询常见知识/教程
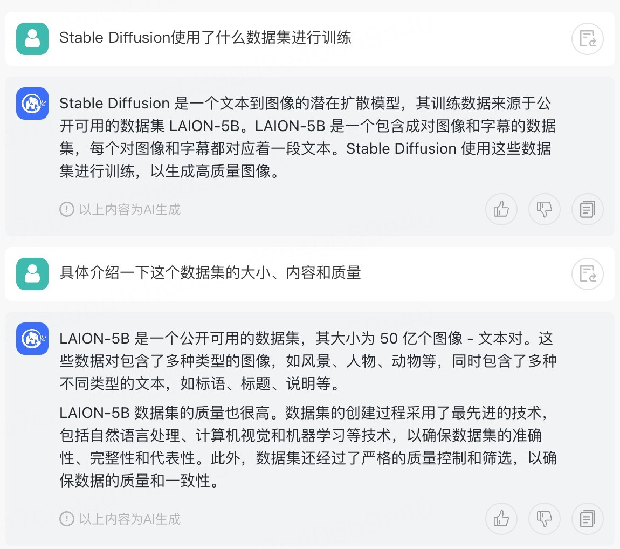
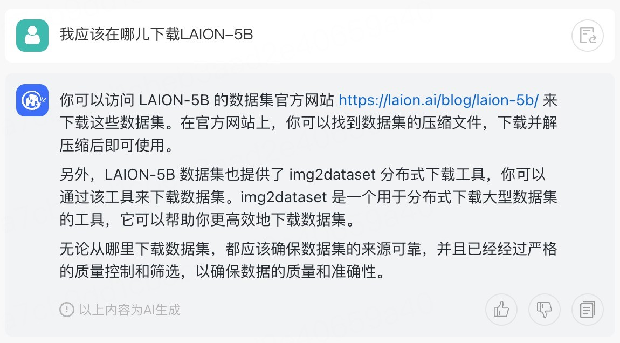
🦋3.7 多轮问答
🦋3.8 文字冒险游戏
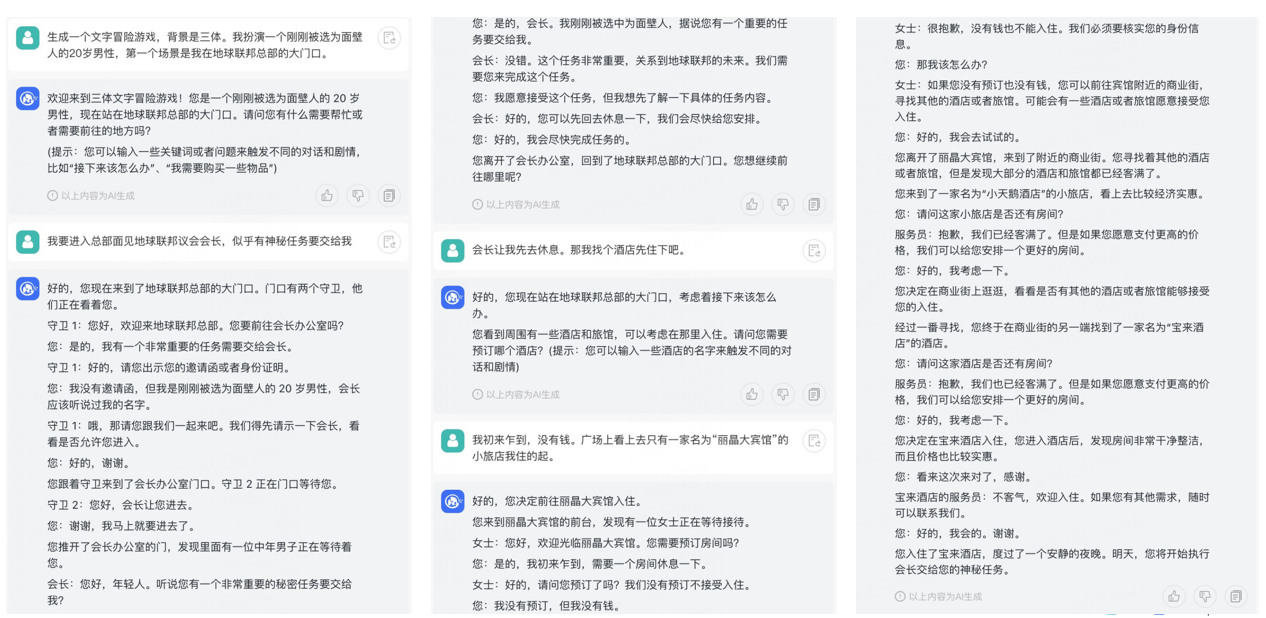
🚀三、ChatGLM Demo
完整的课程学习地址:完整的课程学习地址
🔎1.使用NPU+MindSpore Transformers试用ChatGLM推理
🦋1.1 OpenI启智运行ChatGLM模型
1、到OpenI启智申请账号,开启云脑任务(NPU)/自己用GPU创建环境
OpenI启智申请账号地址:https://openi.pcl.ac.cn/user/sign_up
2、创建项目
3、打开新创建的项目,点击云脑,新建调试任务
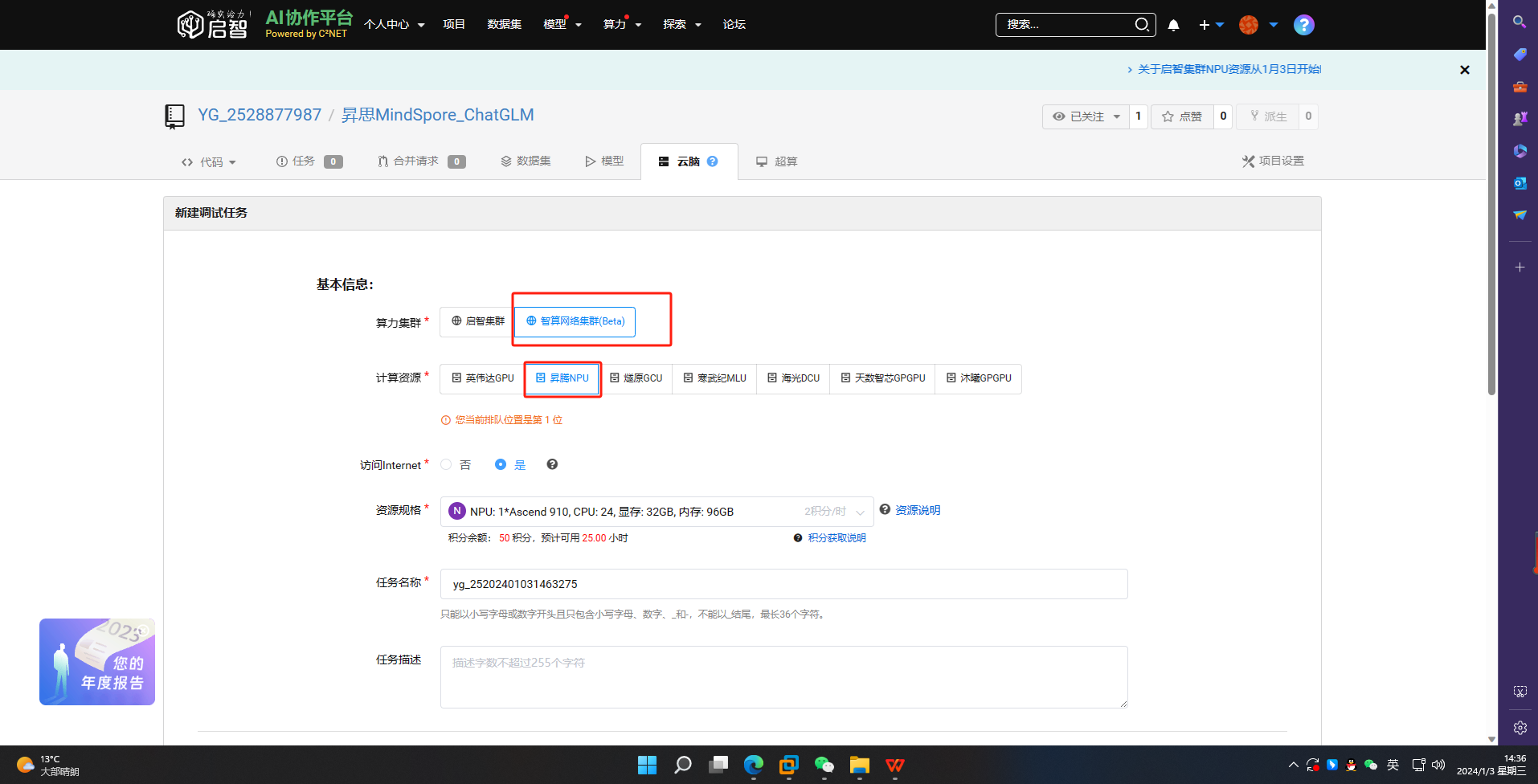
4、点击调试
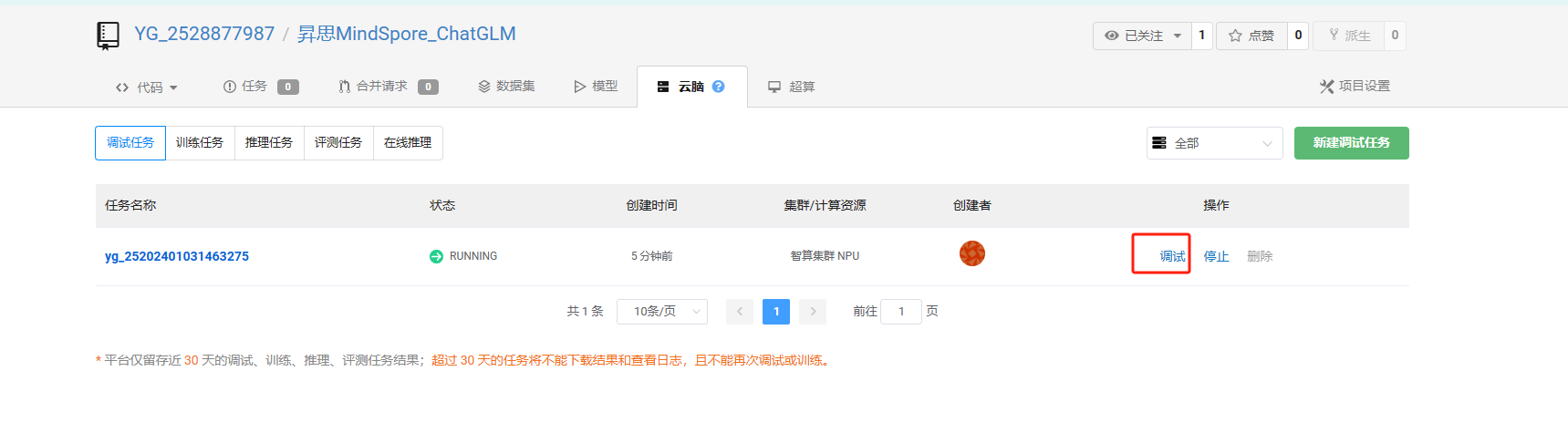
5、进入终端
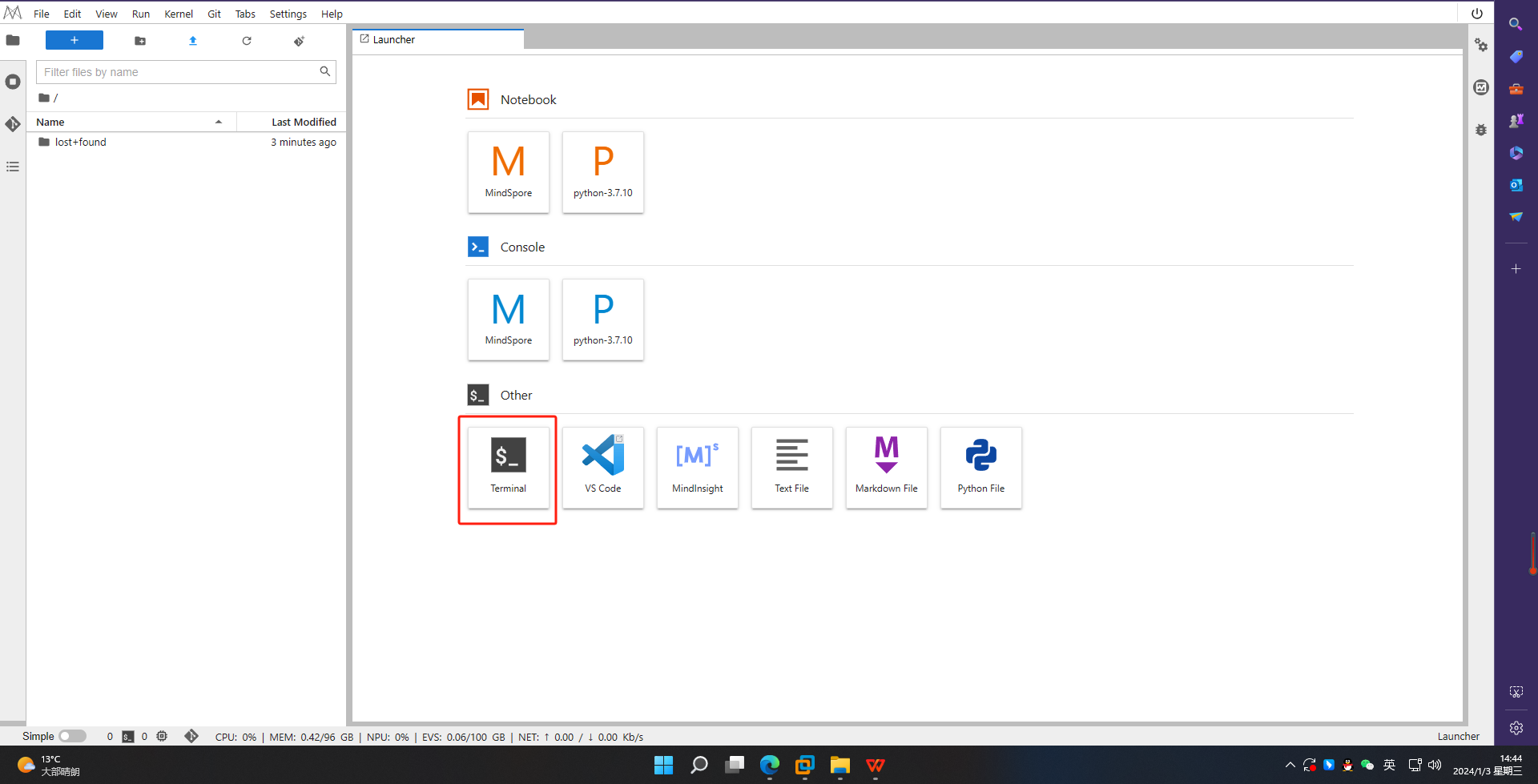
其他操作如下面1.2小结,这边只是用OpenI启智NPU+MindSpore进行在线部署调试,部署结果如下图:
🦋1.2 MindSpore运行ChatGLM模型
安装MindSpore和MindSpore Transformers
a) MindSpore安装:参考:MindSpore官网(如果用OpenI启智NPU+MindSpore,可以忽略这一步,这步属于本地部署)
b) MindSpore Transformers安装:
1、git clone -b dev https://gitee.com/mindspore/mindformers.git
2、cd mindformers
3、bash build.sh
4、如果使用MindSpore1.10版本,请安装MindFormers 0.6版本(git clone -b r0.6 …)
c) 克隆昇思MindSpore技术公开课代码仓:
git clone https://github.com/mindspore-courses/step_into_llm.git
d) cd step_into_llm/Season2.step_into_llm/01.ChatGLM/
e) 下载ckpt和tokenizer文件
1、ckpt:wget https://ascend-repo-modelzoo.obs.cn-east-2.myhuaweicloud.com/XFormer_for_mindspore/glm/glm_6b.ckpt
2、tokenizer:wget https://ascend-repo-modelzoo.obs.cn-east-2.myhuaweicloud.com/XFormer_for_mindspore/glm/ice_text.model
f) 运行推理部署文件:python cli_demo.py
import os
import platform
import signal
import numpy as np
import mindspore as ms
from mindformers.models.glm import GLMConfig, GLMChatModel
from mindformers.models.glm.chatglm_6b_tokenizer import ChatGLMTokenizer
from mindformers.models.glm.glm_processor import process_response
config = GLMConfig(
position_encoding_2d=True,
use_past=True,
is_sample_acceleration=True)
ms.set_context(mode=ms.GRAPH_MODE, device_target="GPU", device_id=0)
model = GLMChatModel(config)
# https://ascend-repo-modelzoo.obs.cn-east-2.myhuaweicloud.com/XFormer_for_mindspore/glm/glm_6b.ckpt
ms.load_checkpoint("./glm_6b.ckpt", model)
# https://ascend-repo-modelzoo.obs.cn-east-2.myhuaweicloud.com/XFormer_for_mindspore/glm/ice_text.model
tokenizer = ChatGLMTokenizer('./ice_text.model')
os_name = platform.system()
clear_command = 'cls' if os_name == 'Windows' else 'clear'
stop_stream = False
def build_prompt(history):
prompt = "欢迎使用 ChatGLM-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序"
for query, response in history:
prompt += f"\n\n用户:{query}"
prompt += f"\n\nChatGLM-6B:{response}"
return prompt
def signal_handler():
global stop_stream
stop_stream = True
def main():
history = []
global stop_stream
print("欢迎使用 ChatGLM-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序")
while True:
query = input("\n用户:")
if query.strip() == "stop":
break
if query.strip() == "clear":
history = []
os.system(clear_command)
print("欢迎使用 ChatGLM-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序")
continue
count = 0
inputs = tokenizer(query)
outputs = model.generate(np.expand_dims(np.array(inputs['input_ids']).astype(np.int32), 0),
max_length=config.max_decode_length, do_sample=False, top_p=0.7, top_k=1)
response = tokenizer.decode(outputs)
response = process_response(response[0])
history = history + [(query, response)]
if stop_stream:
stop_stream = False
break
else:
count += 1
if count % 8 == 0:
os.system(clear_command)
print(build_prompt(history), flush=True)
signal.signal(signal.SIGINT, signal_handler)
os.system(clear_command)
print(build_prompt(history), flush=True)
if __name__ == "__main__":
main()
🚀总结
MindSpore作为一种强大的深度学习框架,提供了丰富的工具和功能,使得模型的开发和训练更加高效和灵活。其支持端到端的深度学习解决方案,可以应用于各种任务和场景。而ChatGLM作为一种生成式语言模型,通过对话的方式生成自然流畅的文本,可以用于智能对话和智能客服等应用。
结合使用MindSpore和ChatGLM,我们可以实现更加智能和交互性的应用。首先,MindSpore可以用来训练ChatGLM模型,通过大量的对话数据进行学习,使得生成的文本更加贴近真实的对话。MindSpore提供了分布式训练的功能,可以在多个设备和计算节点上进行模型的并行训练,加速训练过程。其自动微分功能也可以帮助优化ChatGLM模型的训练效果。
通过MindSpore的强大功能和ChatGLM的生成式语言模型,我们可以构建出高效、准确和自然流畅的智能对话系统,提升用户体验并开拓更多的应用领域。这种结合使用不仅有助于推动机器学习和人工智能的发展,还为带来更多的创新和可能性。
本文参与华为云社区【内容共创】活动第25期。
- 点赞
- 收藏
- 关注作者
评论(0)