开源数据计算引擎,实现媲美ElasticSearch的高性能并发查询

高并发帐户查询的应用场景有很多,例如:手机银行查流水、电商系统查购物订单、手游帐户查充值记录等等。这些场景一般会涉及众多帐户,数据总量非常大,需要外存。每个帐户的数据量通常不大(几条到几千条),而且就是简单查询,几乎没有什么运算。不过,众多的帐户自然也会有大量、高频率的查询,并发访问量会很大,要达到秒级甚至更高的响应速度也是一个不小的挑战。
在SQL数据库或数据仓库中,用索引查找单个帐户数据的速度很快,几乎感觉不到耗时,但并发很多时就会有明显延迟了。这是因为,基于无序集合理解的关系数据库不能保证数据在存储时的次序,也就无法保证同一帐户数据在物理上连续存放,查找一个帐户数据时,可能要到硬盘的很多位置读取才能全部取出。而硬盘有最小读取单位,在读取不连续数据时,会取出很多无关内容,查询就会变慢。虽然每个帐户数据量很少,单个帐户查询的时候只是慢一点,但是高并发访问的每个查询都慢一点,总体性能就会很差了。

因为关系数据库的表现不如人意,所以搜索引擎Elastic Search经常会被用来应对这种场景,即把数据导出到ES里,利用搜索技术实现高性能并发查询。使用ES后,通常确实可以达到期望的性能要求,但遗憾的是ES对JOIN支持非常差,如果查询过程中还涉及关联计算,就会造成巨大的麻烦。比如帐户交易明细表,要和用户表、商品表、网点表等等关联,使用ES时通常只能将这些数据全都整合到交易表中形成大宽表。准备这个大宽表的过程费时费力,还会丧失很多灵活性;而且ES的数据导入非常慢,会进一步加剧这个问题。使用大宽表后无法在关联数据发生变动时简单追加写入,只能重新准备新的宽表再重新导入,耗时很长,这期间只能暂停查询服务。用ES解决高并发帐户查询只能说是一个权宜之计。
其实这个问题也不是很难,解决的关键在于要把数据按照帐户排序,保证同一帐户的数据在物理上是连续存储的。这样,查询时从硬盘上读出的数据块几乎都是目标值,性能就会得到大幅提升。只是,关系数据库不保证数据存储的物理次序,就难以应用这个方法。
开源数据计算引擎 S P L 支持有序存储,可以保证数据按照帐户物理有序存放。高并发查找时,S P L 的索引可以迅速、精确定位到指定帐号的外存存储位置;有序存储技术则保证同一帐号的数据在物理上连续存储在一片区域中,不需要跳动读取。两者配合,可以让高并发帐户查询达到极致性能。
另外,高并发场景要选择行式存储,而不是很多数据仓库鼓吹的列存方案。这是因为,行存时一条记录的各个字段数据在物理上是连续存放的,才能保证同一帐户的所有数据存在一处。而列存时,则是各列数据连续存放,一个帐户的字段分散在不同的列中,还是会造成硬盘读取不连续数据的情况。特别是有并发任务时,列存造成的硬盘不连续访问程度要比行存严重的多。
实际上,行存更适合查找,列存则更适合遍历。S P L 两者都支持,程序员可以根据计算的需要来自由选择。有些数据仓库做成了透明机制,不允许用户自由选择行存和列存,就很难达到最佳效果了。
S P L 有序行存加索引的代码也很简单,比如,从数据库导出数据,生成有序行存的帐户交易表和索引的代码大致是这样:
| A |
B |
|
| 1 |
|
|
| 2 |
|
|
| 3 |
|
|
A1连数据库准备取数。A2创建交易明细表,@r代表行存。B2向明细表追加数据,A3给明细表创建索引。
然后,就可以使用生成的明细表和索引进行高速查询::
| A |
|
| … |
|
| 4 |
|
| 5 |
|
A4加载明细表的索引,A5利用有序行存表和索引完成查询。
在此基础上,S P L实现JOIN运算也很轻松,多外键关联、多层关联都很容易做到。比如,查询交易明细表时,要关联网点表store,在查询结果中要包含网点名称。代码是下面这样:
| A |
|
| … |
|
| 4 |
|
| 5 |
|
| 6 |
|
| 7 |
|
| 8 |
|
A6、A7、A8加载网点表,完成内存关联,生成查询结果(包含网点名称)。
由于每个帐户的数据量都不大,所以A7和A8是内存计算,几乎不占用什么时间。
S P L 还支持新增数据的快速追加,详情请参考SQL 提速:高并发帐户查询。
经过实际测试,在总数据量2亿条,500用户并发查询的场景中,S P L 有序行存索引的查询性能可以超过ES。测试结果如下:
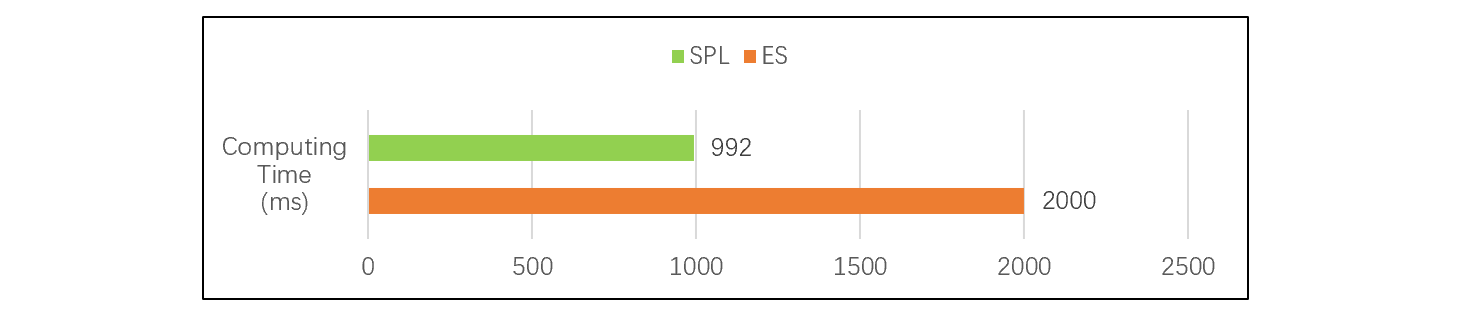
可以看到,S P L 性能与ES相当甚至稍快。而 S P L 对JOIN的支持要好得多,也不存在加载复杂的问题,相比之下,比ES更适合高并发帐户查询场景。
还要注意的是,高并发帐户查询属于查找计算,但有时候系统还要兼顾遍历计算的性能,比如说2月份的帐户交易数据,要按产品分组统计交易总金额、总笔数等。S P L 提供了带值索引机制,可以同时支持高性能遍历和查找计算。有兴趣的读者可以参考SQL 提速:高并发帐户查询。
源码地址
文章来源: csp1999.blog.csdn.net,作者:兴趣使然的草帽路飞,版权归原作者所有,如需转载,请联系作者。
原文链接:csp1999.blog.csdn.net/article/details/125847894

- 点赞
- 收藏
- 关注作者
评论(0)