在Jetson AGX Orin上体验Nemo镜像

【摘要】 在Jetson AGX Orin上体验Nemo镜像
这是张小白省吃俭用买的Jetson AGX Orin的软件配置:
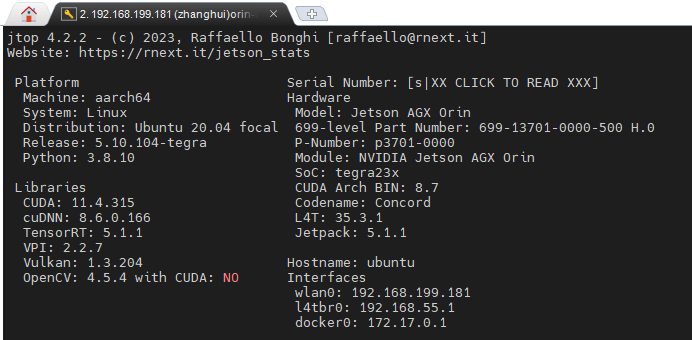
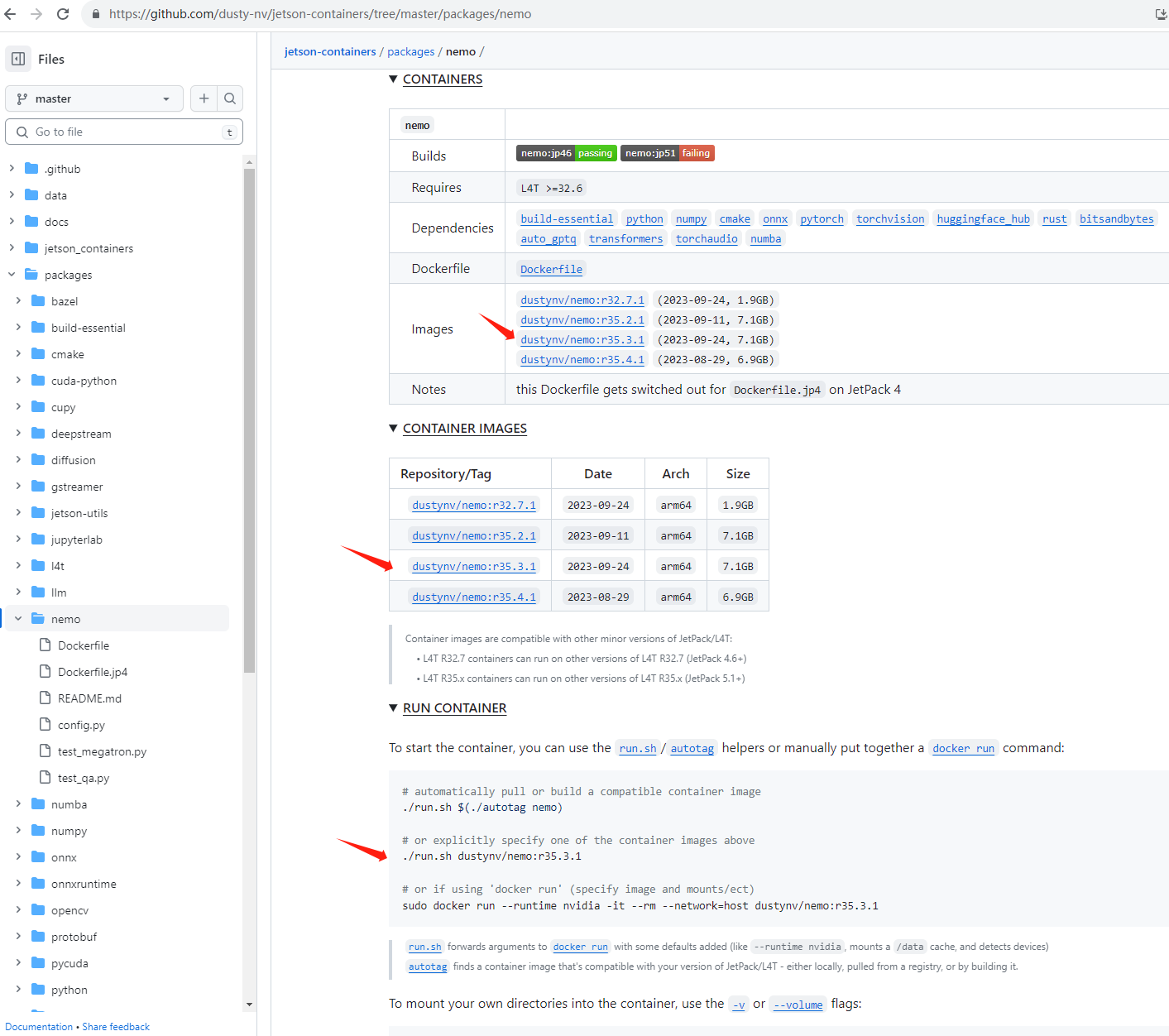
由于Orin的L4T版本为35.3.1,所以按照README.md,应该使用r35.3.1的镜像。
张小白记得上次已经将镜像目录迁移到了 /home1的大硬盘目录下了。
下载代码仓:
cd /home1/zhanghui
git clone https://github.com/dusty-nv/jetson-containers.git

cd jetson-containers

./run.sh dustynv/nemo:r35.3.1
所以现在可以放心的下载镜像:
sudo docker run --runtime nvidia -it --rm --network=host dustynv/nemo:r35.3.1
这里应该不仅下载了镜像,而且启动了镜像进入了容器里面,我们看看:
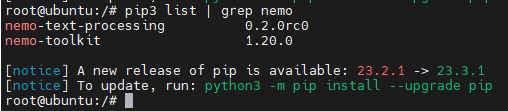
查看nemo-toolkit信息:
pip3 show nemo_toolkit

pip3 list| grep nemo
查看pytorch的版本:
pip3 list | grep torch
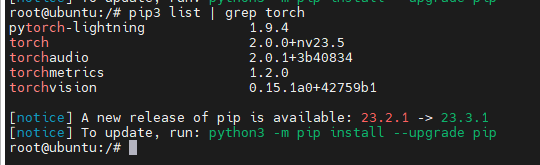
可以看到这里用的是torch 2.0.1 jetson专用版(nv23.5)。
查看容器内cuda和cuDNN的版本:
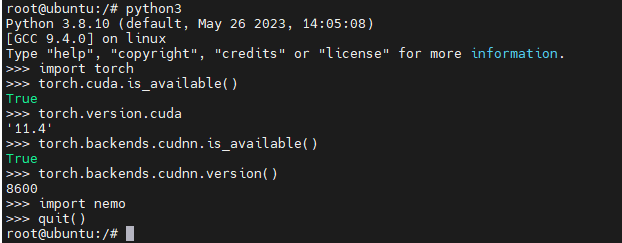
分别是11.4和8.6.
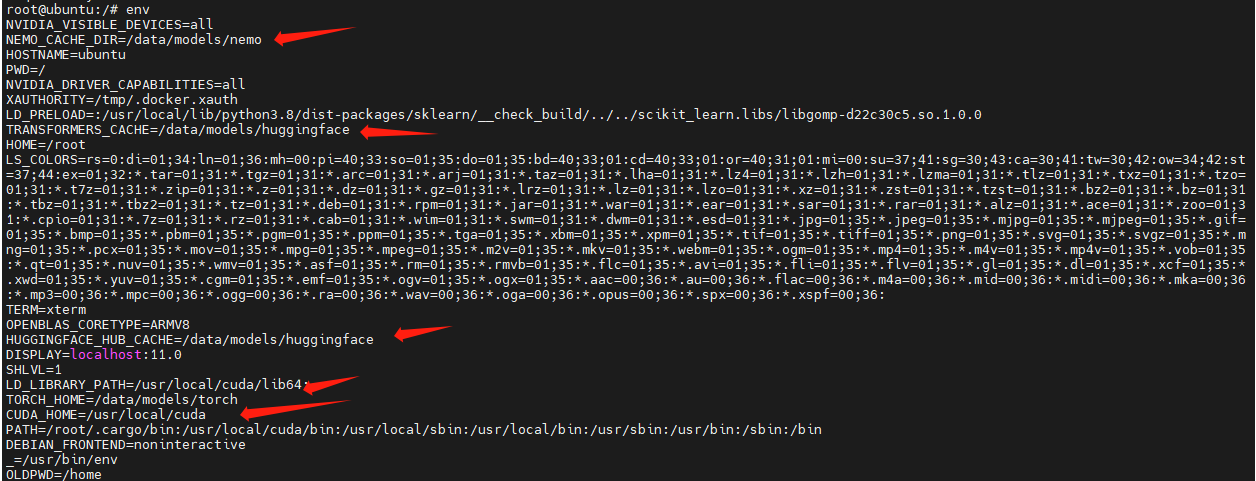
查看容器内的环境变量:
env
另外打开一个终端查看下镜像的情况:
sudo docker images
sudo docker ps

(base) zhanghui@ubuntu:~$ sudo docker ps
[sudo] password for zhanghui:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ef497ac9a264 dustynv/nemo:r35.3.1 "/bin/bash" 4 hours ago Up 4 hours priceless_mahavira
(base) zhanghui@ubuntu:~$
容器ID是 ef497ac9a264,备用。
sudo docker info
回到容器里面,装个jupyterlab:
pip3 install jupyter -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install jupyterlab -i https://pypi.tuna.tsinghua.edu.cn/simple
jupyter-lab --generate-config

编辑文件:
nano /root/.jupyter/jupyter_lab_config.py
c.ServerApp.allow_origin ='*'
c.ServerApp.ip ='192.168.199.181'

使用Ctrl-X->Y->回车保存文件并退出:

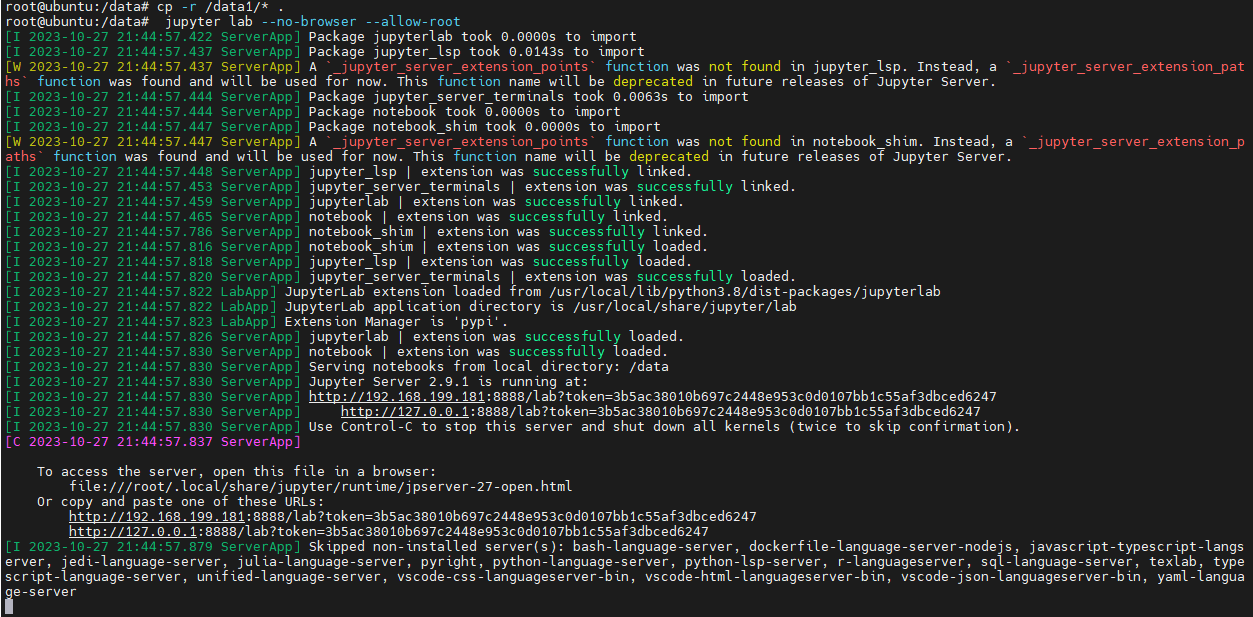
jupyter lab --no-browser --allow-root
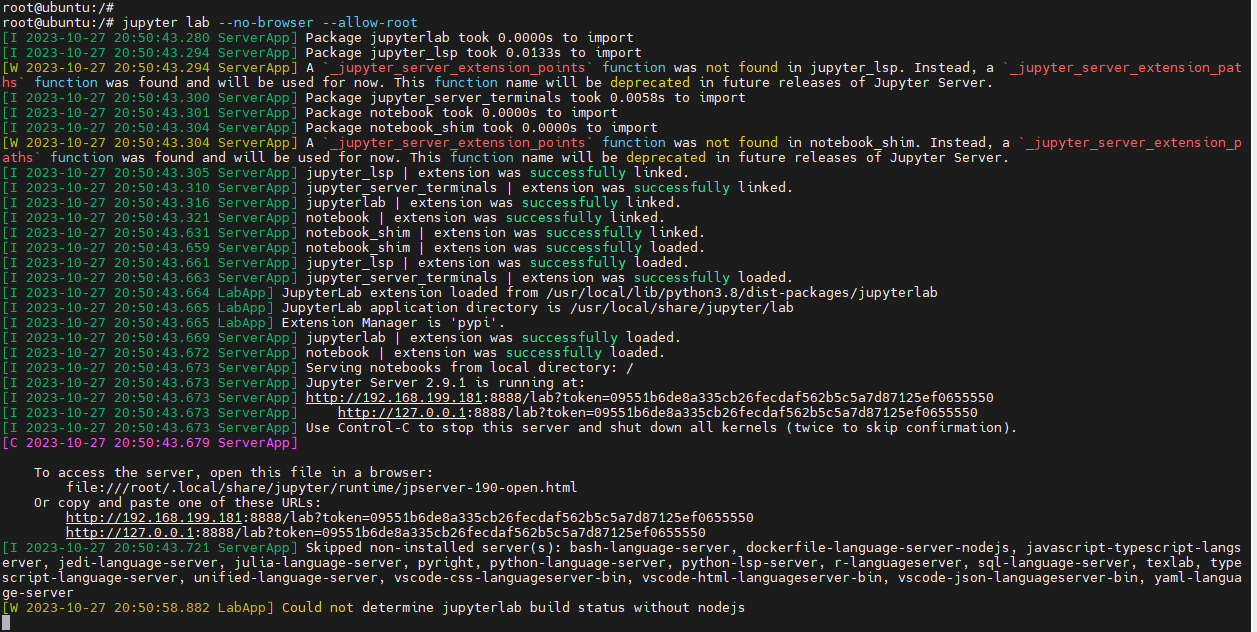
在windows浏览器打开这个链接:
http://192.168.199.181:8888/lab?token=09551b6de8a335cb26fecdaf562b5c5a7d87125ef0655550
打开notebook
!python3 -V
可以到nemo的github去下载范例:https://github.com/NVIDIA/NeMo/tree/stable/tutorials
使用博客提供的示例代码:
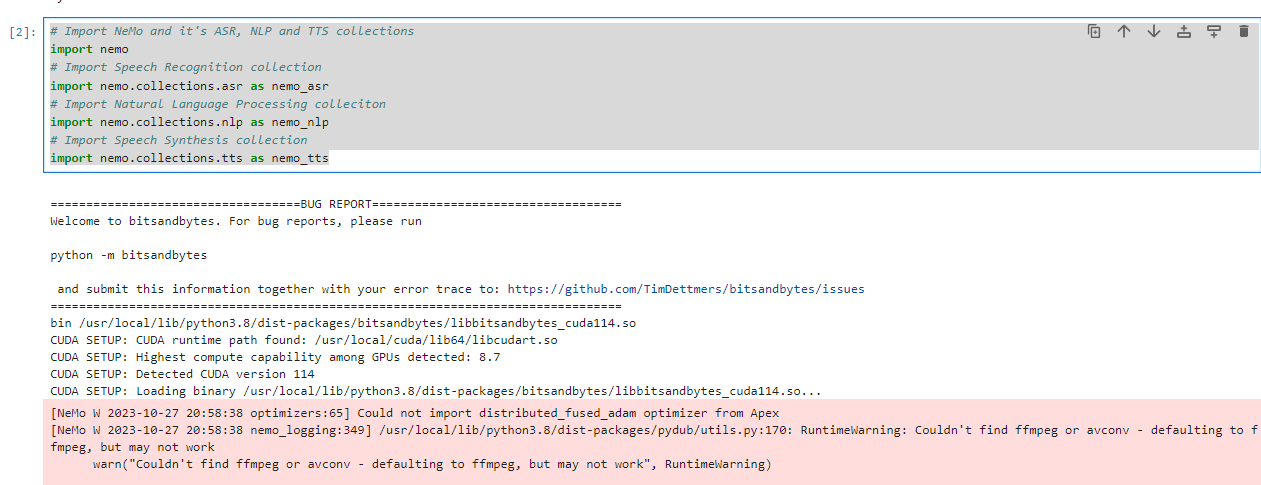
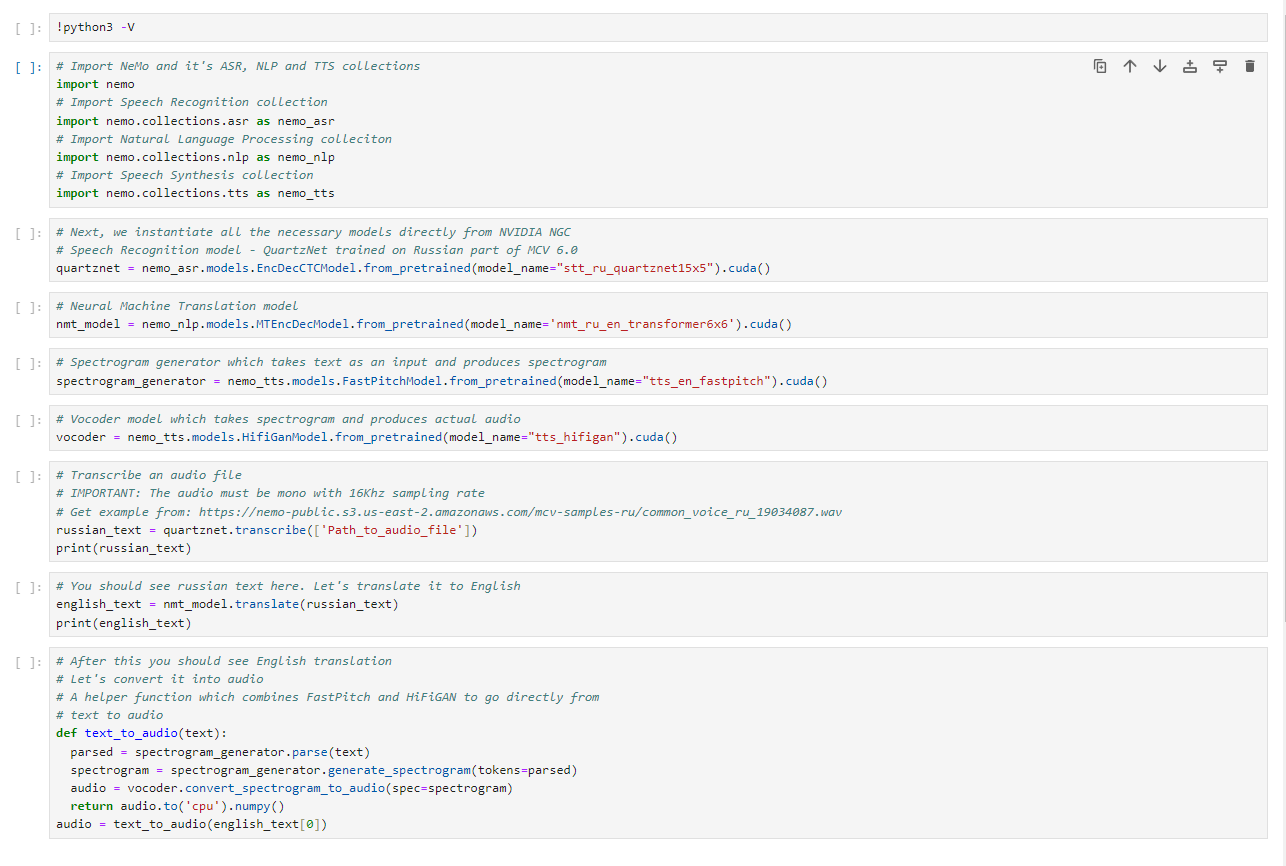
# Import NeMo and it's ASR, NLP and TTS collections
import nemo
# Import Speech Recognition collection
import nemo.collections.asr as nemo_asr
# Import Natural Language Processing colleciton
import nemo.collections.nlp as nemo_nlp
# Import Speech Synthesis collection
import nemo.collections.tts as nemo_tts
执行结果:
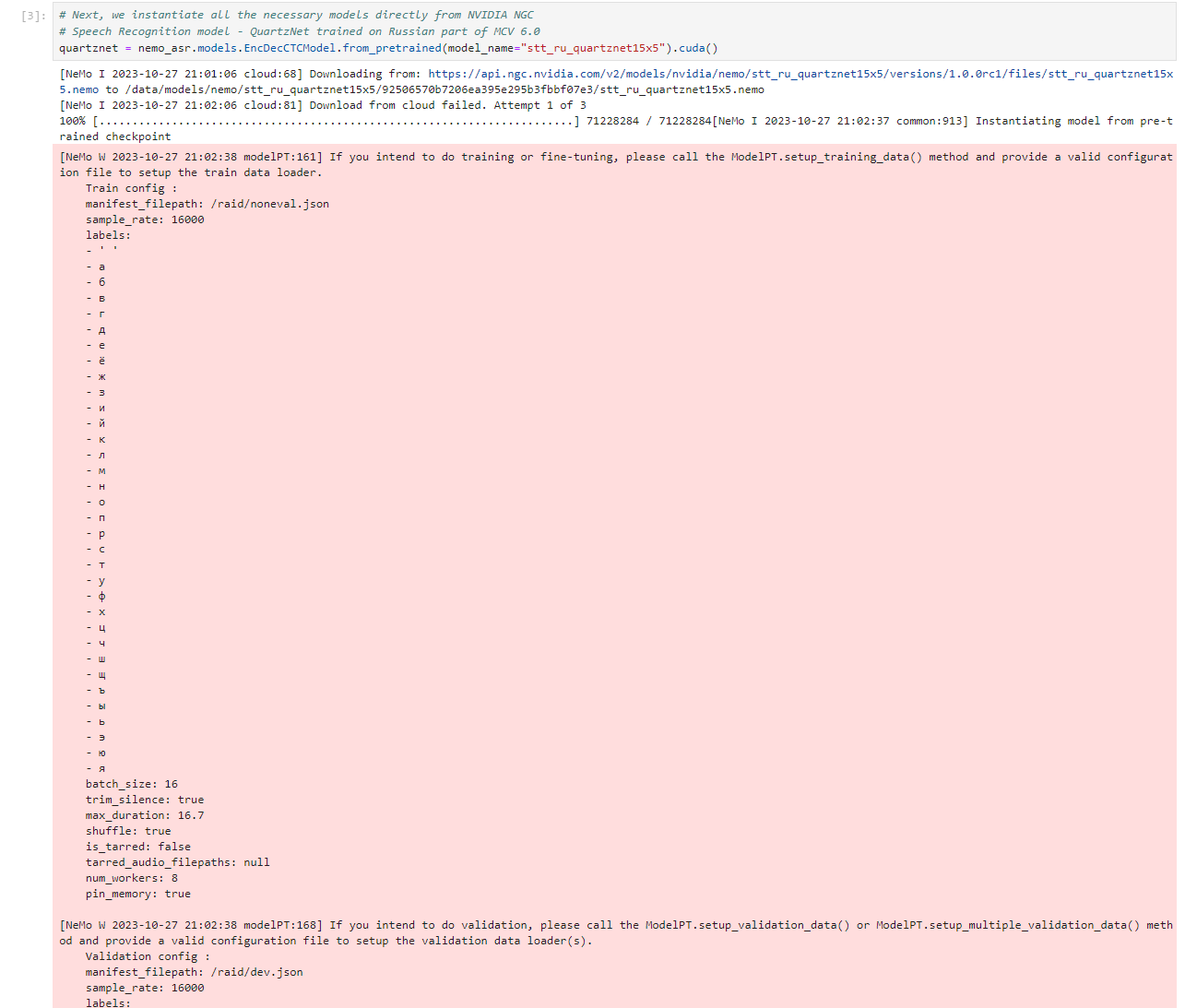
# Next, we instantiate all the necessary models directly from NVIDIA NGC
# Speech Recognition model - QuartzNet trained on Russian part of MCV 6.0
quartznet = nemo_asr.models.EncDecCTCModel.from_pretrained(model_name="stt_ru_quartznet15x5").cuda()
执行结果:
# Neural Machine Translation model
nmt_model = nemo_nlp.models.MTEncDecModel.from_pretrained(model_name='nmt_ru_en_transformer6x6').cuda()
执行结果:
# Spectrogram generator which takes text as an input and produces spectrogram
spectrogram_generator = nemo_tts.models.FastPitchModel.from_pretrained(model_name="tts_en_fastpitch").cuda()
执行结果:
# Vocoder model which takes spectrogram and produces actual audio
vocoder = nemo_tts.models.HifiGanModel.from_pretrained(model_name="tts_hifigan").cuda()
执行结果:
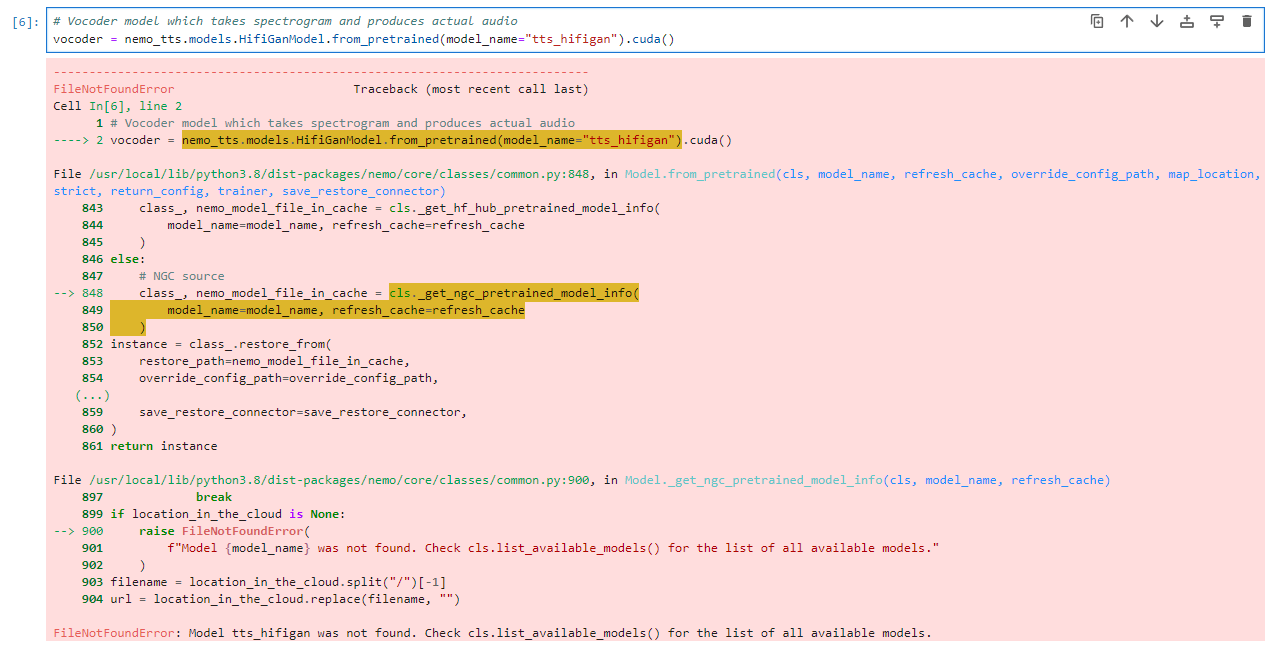
这个模型好像名字不对。
先保存这个notebook,并下载到本地,备用:
我们修改一下,在容器启动后,挂载到orin的目录:
ctrl-c 停止jupyterlab运行:
浏览器也关了。
将容器内的 /data目录 复制到 /data1目录下:
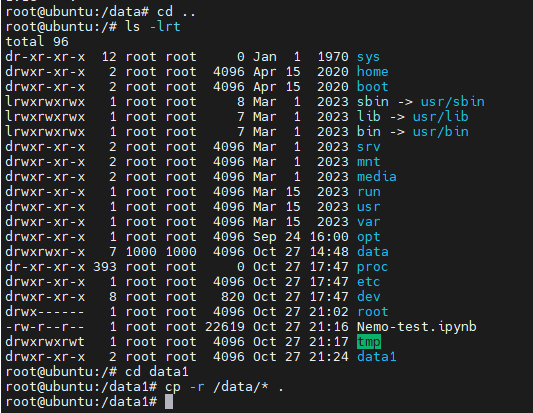
切换到orin终端:
把容器commit做成镜像
前面查到的容器id ef497ac9a264
sudo docker commit ef497ac9a264 zhanghui-nemo:v0.1
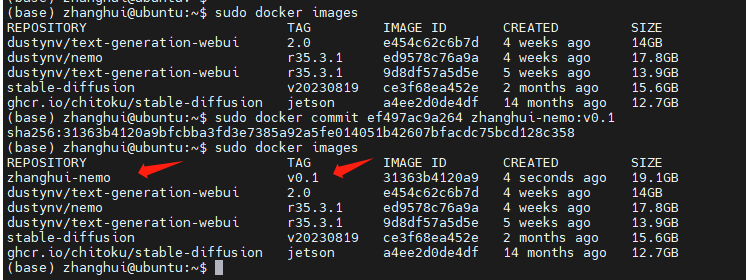
退出容器,停止容器运行:
exit

sudo docker ps

启动镜像的时候挂载目录:
cd /home1/zhanghui/jetson-containers
./run.sh -v /home1/zhanghui/jetson-containers/data:/data zhanghui-nemo:v0.1
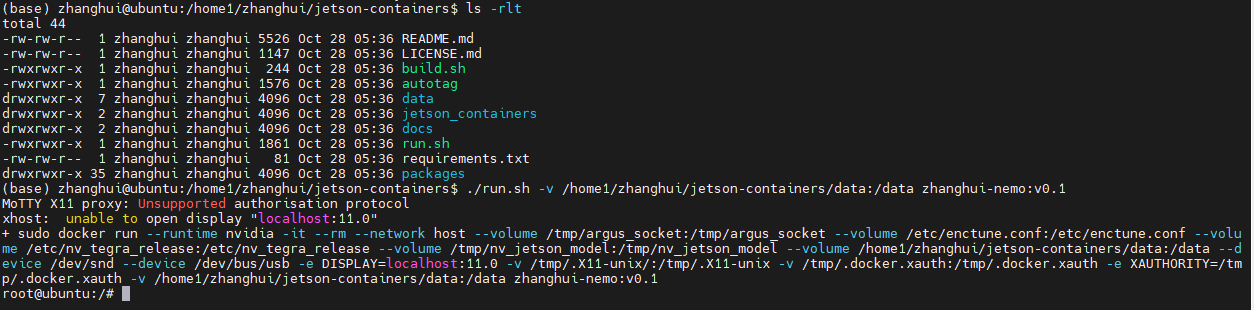
将前面备份的/data1目录下的东西复制过来:
cd /data
cp -r /data1/* .
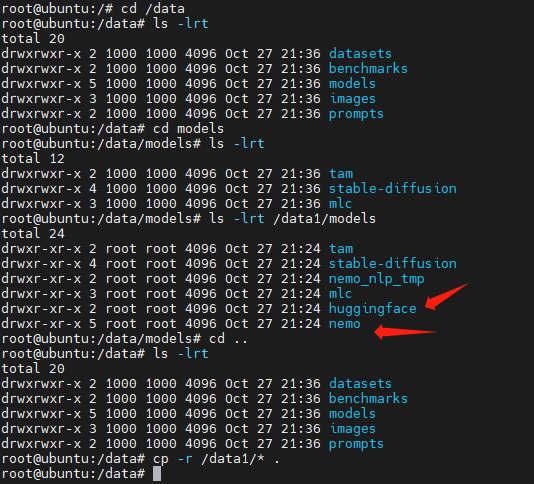
启动jupyterlab:
jupyter lab --no-browser --allow-root
浏览器打开:
http://192.168.199.181:8888/lab?token=3b5ac38010b697c2448e953c0d0107bb1c55af3dbced6247
上传刚才下载的notebook:
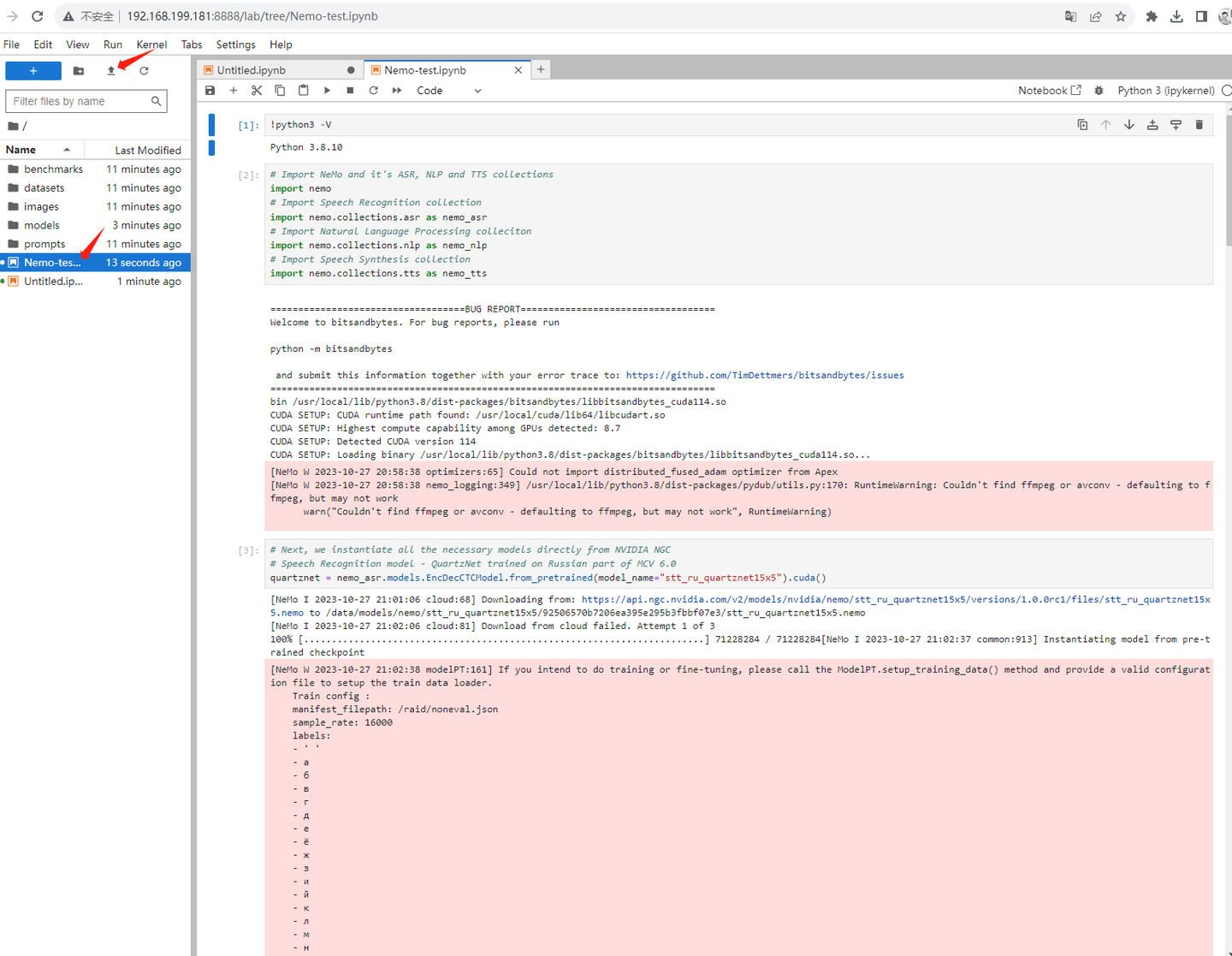
清空output重新开始执行前面的cell
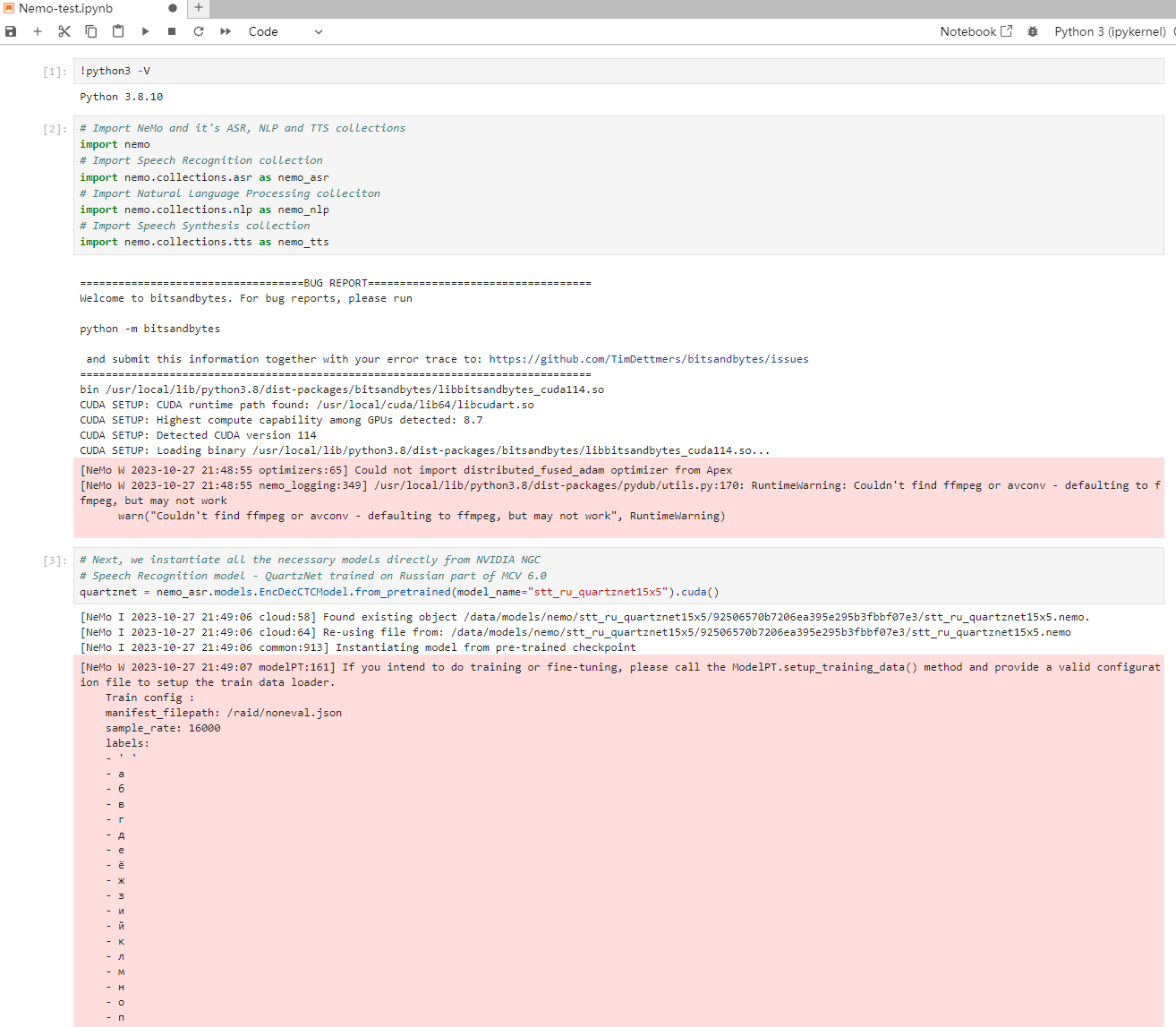
请注意此时模型加载都没有下载过程,而是使用了本地的nemo文件。除了下面这个:
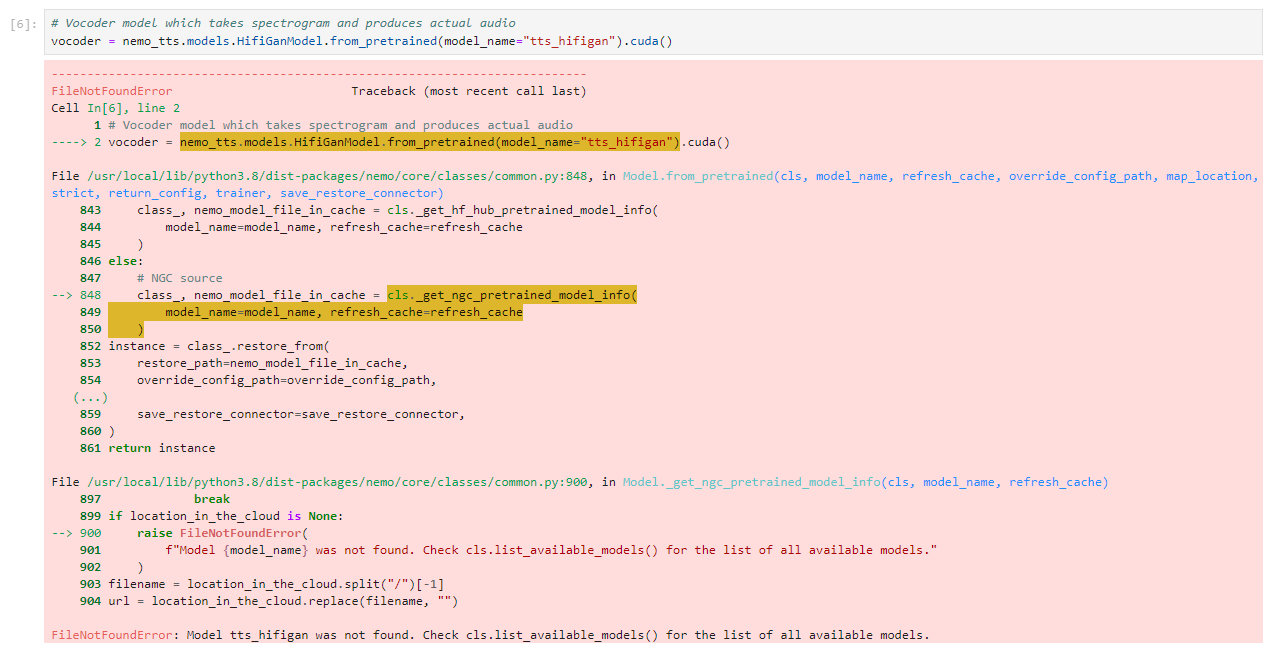
应该是模型的名称不对。
将其改为:
vocoder = nemo_tts.models.HifiGanModel.from_pretrained(model_name="tts_en_hifigan").cuda()
重新执行:
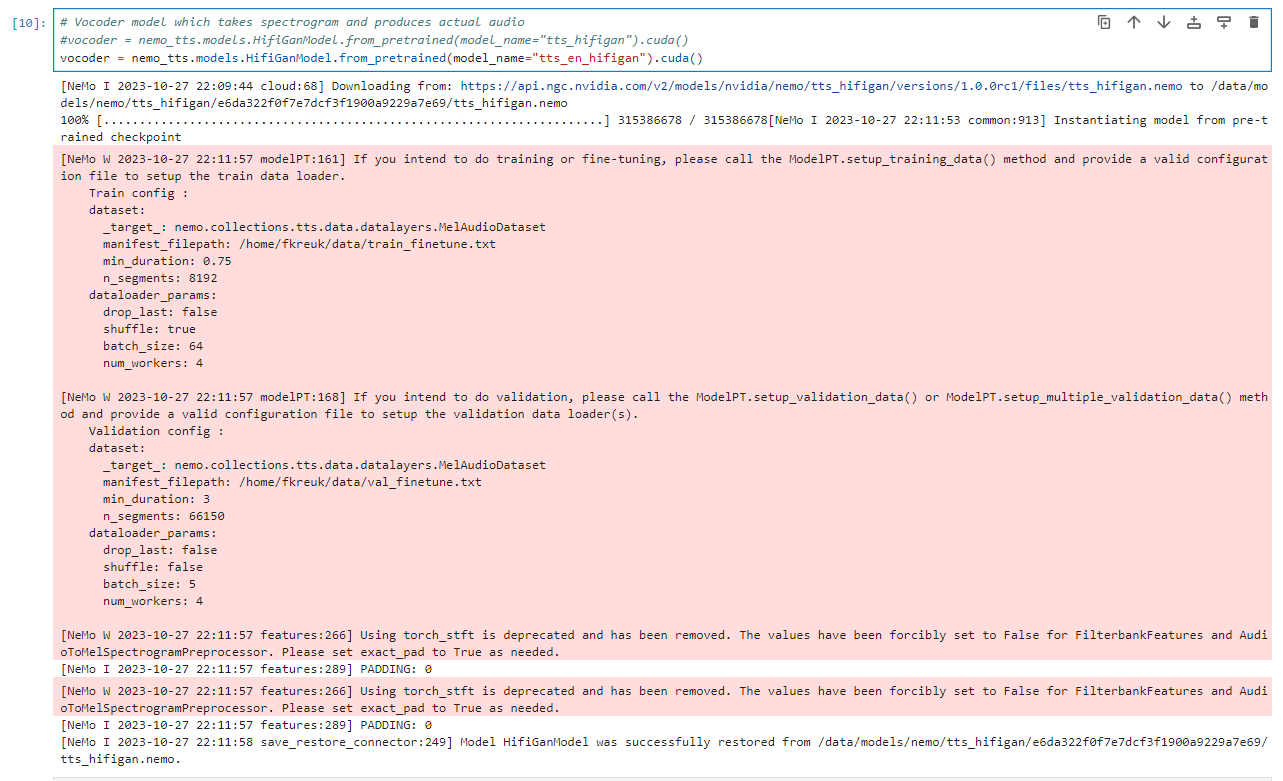
下载 https://nemo-public.s3.us-east-2.amazonaws.com/mcv-samples-ru/common_voice_ru_19034087.wav 这个俄罗斯语言的wav文件。
上传到notebook
# Transcribe an audio file
# IMPORTANT: The audio must be mono with 16Khz sampling rate
# Get example from: https://nemo-public.s3.us-east-2.amazonaws.com/mcv-samples-ru/common_voice_ru_19034087.wav
russian_text = quartznet.transcribe(['common_voice_ru_19034087.wav'])
print(russian_text)
执行结果:
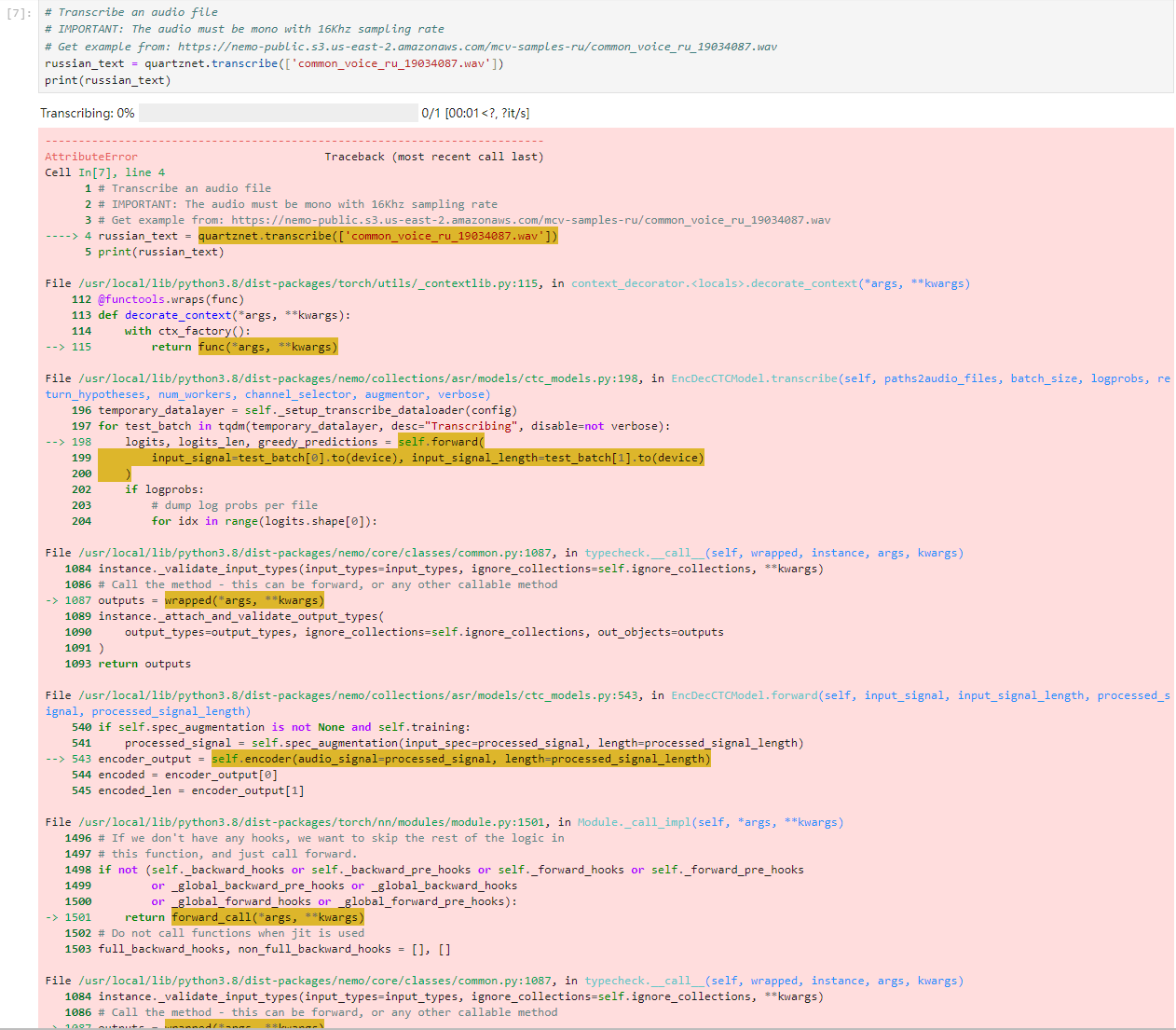
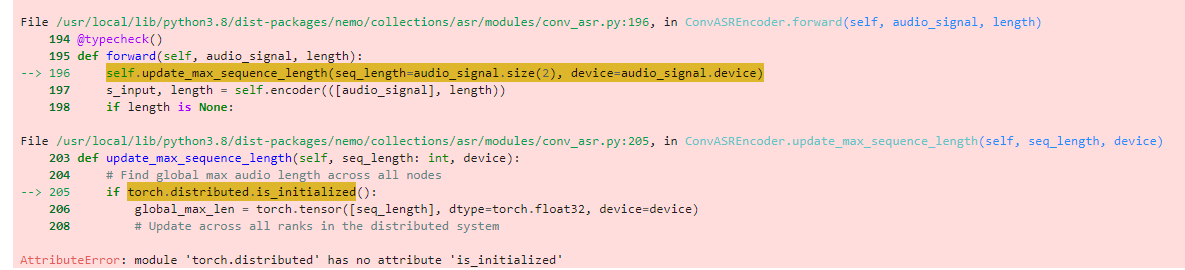
AttributeError: module 'torch.distributed' has no attribute 'is_initialized'
张小白感觉有点不妙,好像torch的版本有问题。
但是,,,这个是镜像提供的torch啊。。。
怎么办?
只好再忽略这个步骤,强行找一段俄语:
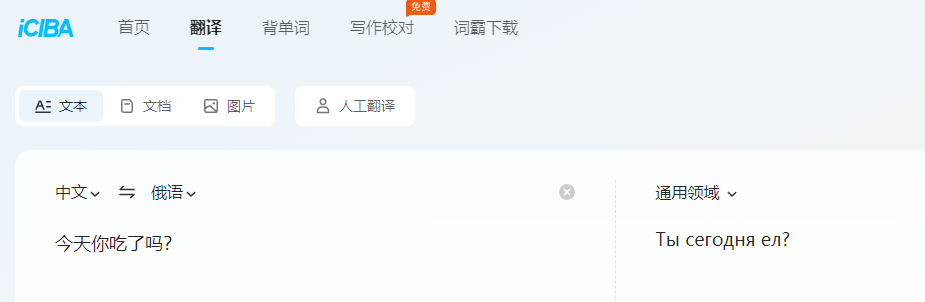
试试文字翻译:俄文-》英文
# You should see russian text here. Let's translate it to English
russian_text = 'Ты сегодня ел?'
english_text = nmt_model.translate(russian_text)
print(english_text)
执行结果:

好像也不对。
# After this you should see English translation
# Let's convert it into audio
# A helper function which combines FastPitch and HiFiGAN to go directly from
# text to audio
def text_to_audio(text):
parsed = spectrogram_generator.parse(text)
spectrogram = spectrogram_generator.generate_spectrogram(tokens=parsed)
audio = vocoder.convert_spectrogram_to_audio(spec=spectrogram)
return audio.to('cpu').numpy()
audio = text_to_audio(english_text[0])
执行结果:
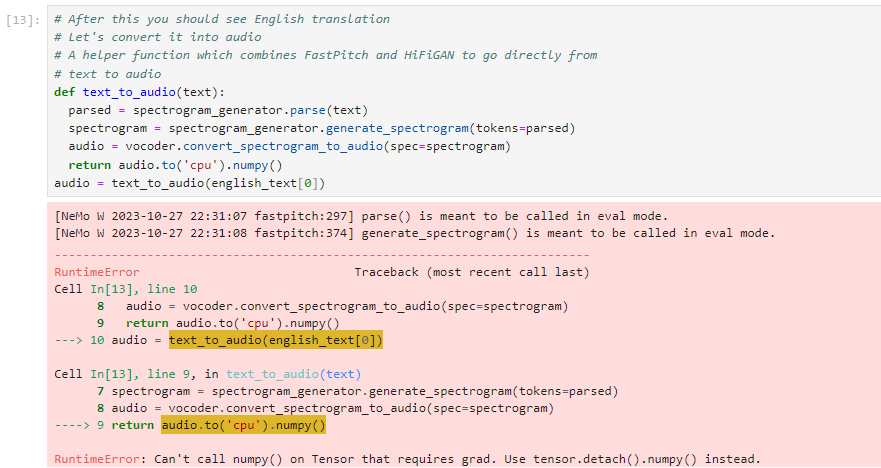
这个。。。
试试在Nemo语音机器人里面的几个cell吧!
先试下这篇里面的文字转语音吧!
from nemo.collections.tts.models import FastPitchModel
from matplotlib.pyplot import imshow
from matplotlib import pyplot as plt
执行结果:

spec_generator = FastPitchModel.from_pretrained(model_name="tts_zh_fastpitch_sfspeech")
执行结果:

这段加载有点久,需要耐心等待一下。
from nemo.collections.tts.models import HifiGanModel
#model = HifiGanModel.from_pretrained("tts_hifigan")
#model.save_to(f'tts_hifigan.nemo')
Hifigan = HifiGanModel.restore_from("tts_hifigan.nemo")
执行结果:
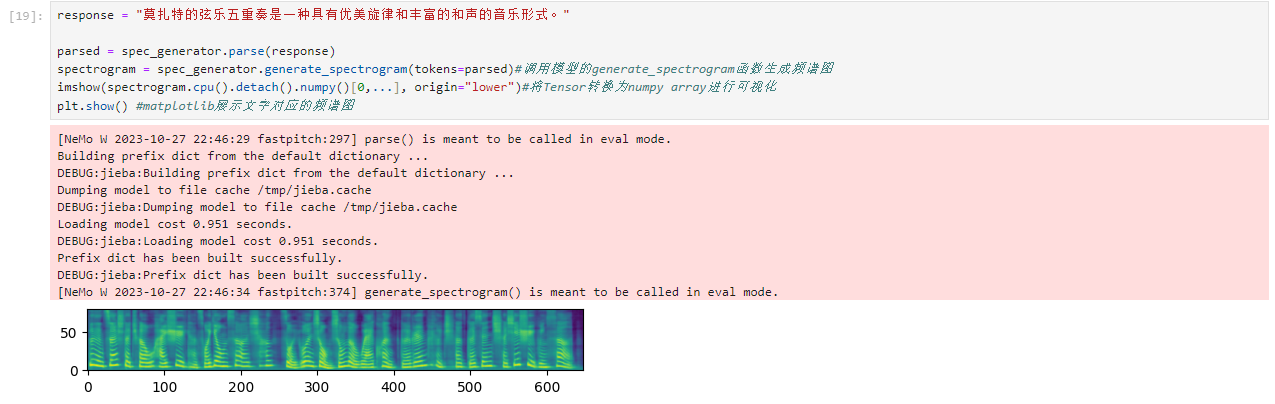
response = "莫扎特的弦乐五重奏是一种具有优美旋律和丰富的和声的音乐形式。"
parsed = spec_generator.parse(response)
spectrogram = spec_generator.generate_spectrogram(tokens=parsed)#调用模型的generate_spectrogram函数生成频谱图
imshow(spectrogram.cpu().detach().numpy()[0,...], origin="lower")#将Tensor转换为numpy array进行可视化
plt.show() #matplotlib展示文字对应的频谱图
执行结果:
import IPython
audio = Hifigan.convert_spectrogram_to_audio(spec=spectrogram) #调用模型convert_spectrogram_to_audio()函数进行频谱到音频文件的转换
IPython.display.Audio(audio.to('cpu').detach().numpy(), rate=22050)
执行结果:

再试试语音识别部分:
!pip install chinese2digits -i https://pypi.tuna.tsinghua.edu.cn/simple
执行结果:
import nemo
import nemo.collections.asr as nemo_asr
import nemo.collections.tts as nemo_tts
import chinese2digits as c2d #pip install chinese2digits安装中文与数字转换工具库
执行结果:

#citrinet = nemo_asr.models.EncDecCTCModel.from_pretrained(model_name="stt_zh_citrinet_512")# 加载ASR语音识别预训练模型
citrinet = nemo_asr.models.EncDecCTCModel.restore_from("stt_zh_citrinet_512.nemo")# 加载ASR语音识别预训练模型
将 "C:\Users\xishu\.cache\torch\NeMo\NeMo_1.20.0\stt_zh_citrinet_512\cfe4cc823730475d065cd2ce4a3a9758\stt_zh_citrinet_512.nemo" 上传到Notebook
执行结果:
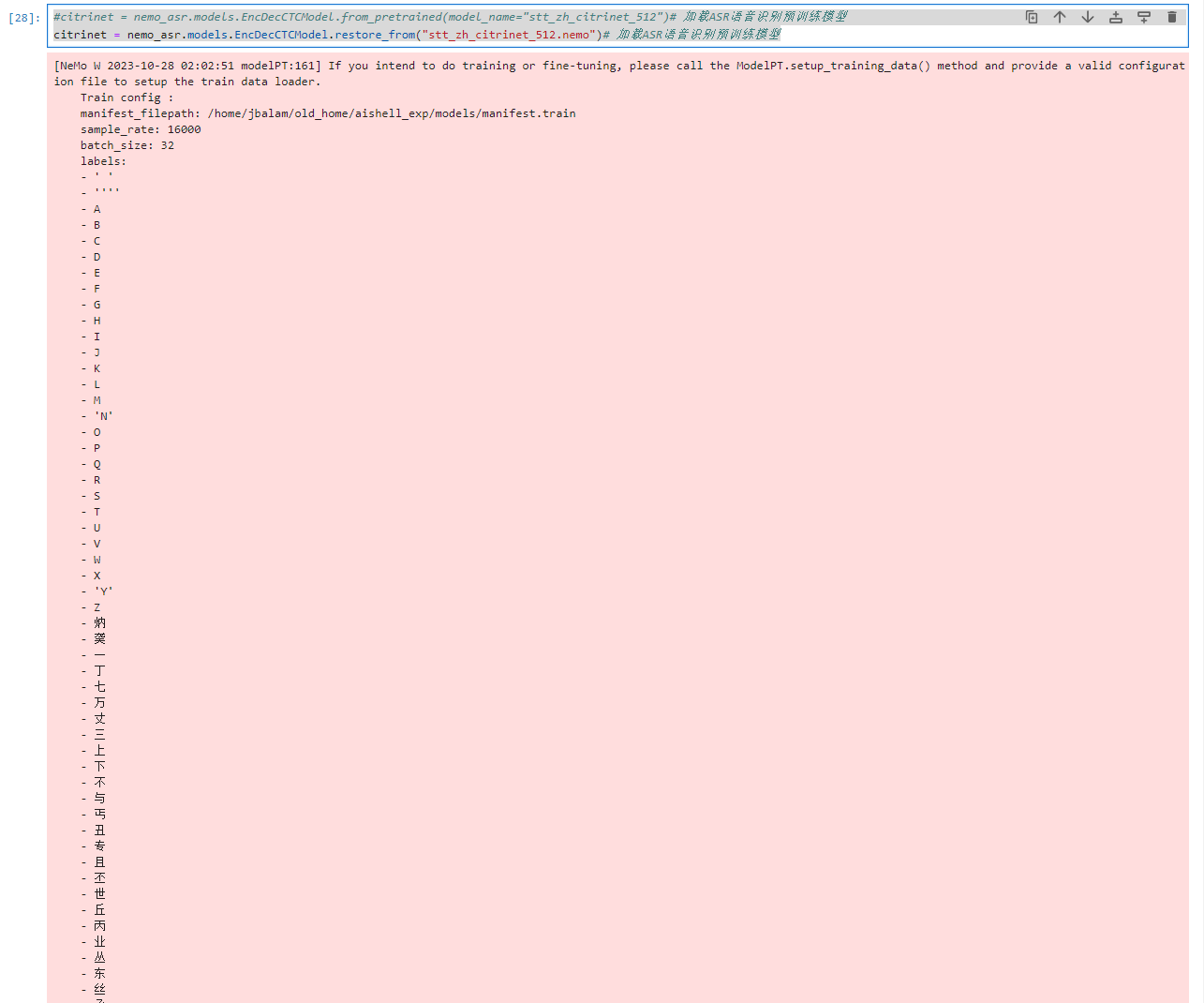

上传语音文件test.wav到Notebook
asr_result = citrinet.transcribe(paths2audio_files=["test.wav"])
asr_result = " ".join(asr_result)
asr_result = c2d.takeChineseNumberFromString(asr_result)['replacedText']
print(asr_result)
执行结果:
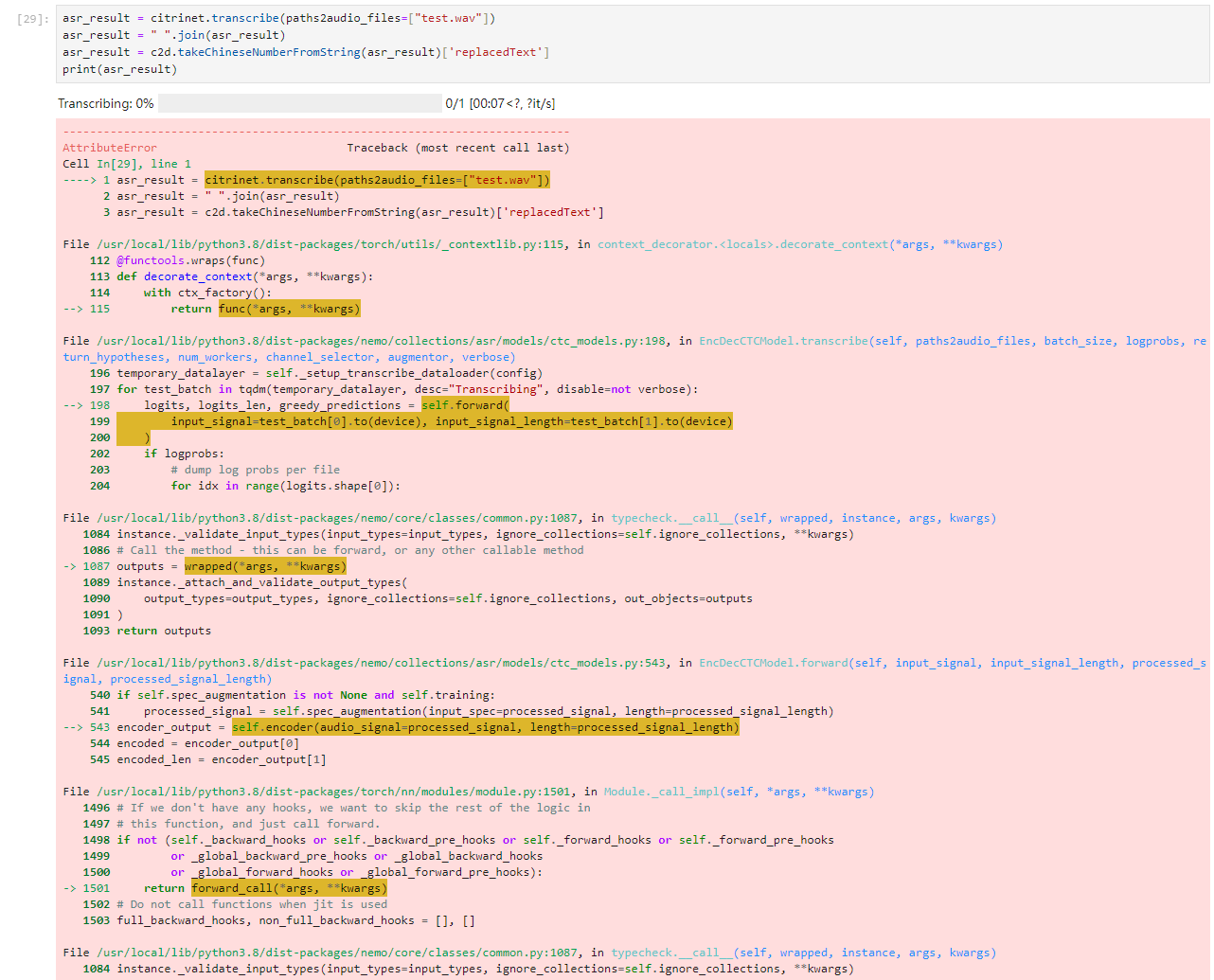
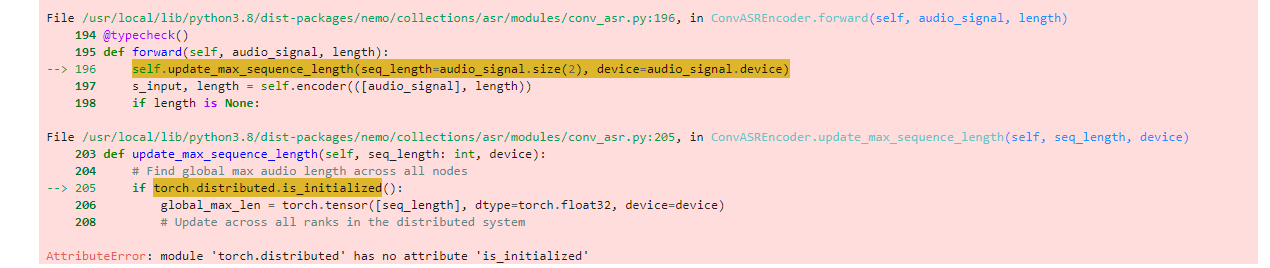
这个错误跟参考范例写的脚本执行的错误是一样的:
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[29], line 1
----> 1 asr_result = citrinet.transcribe(paths2audio_files=["test.wav"])
2 asr_result = " ".join(asr_result)
3 asr_result = c2d.takeChineseNumberFromString(asr_result)['replacedText']
File /usr/local/lib/python3.8/dist-packages/torch/utils/_contextlib.py:115, in context_decorator.<locals>.decorate_context(*args, **kwargs)
112 @functools.wraps(func)
113 def decorate_context(*args, **kwargs):
114 with ctx_factory():
--> 115 return func(*args, **kwargs)
File /usr/local/lib/python3.8/dist-packages/nemo/collections/asr/models/ctc_models.py:198, in EncDecCTCModel.transcribe(self, paths2audio_files, batch_size, logprobs, return_hypotheses, num_workers, channel_selector, augmentor, verbose)
196 temporary_datalayer = self._setup_transcribe_dataloader(config)
197 for test_batch in tqdm(temporary_datalayer, desc="Transcribing", disable=not verbose):
--> 198 logits, logits_len, greedy_predictions = self.forward(
199 input_signal=test_batch[0].to(device), input_signal_length=test_batch[1].to(device)
200 )
202 if logprobs:
203 # dump log probs per file
204 for idx in range(logits.shape[0]):
File /usr/local/lib/python3.8/dist-packages/nemo/core/classes/common.py:1087, in typecheck.__call__(self, wrapped, instance, args, kwargs)
1084 instance._validate_input_types(input_types=input_types, ignore_collections=self.ignore_collections, **kwargs)
1086 # Call the method - this can be forward, or any other callable method
-> 1087 outputs = wrapped(*args, **kwargs)
1089 instance._attach_and_validate_output_types(
1090 output_types=output_types, ignore_collections=self.ignore_collections, out_objects=outputs
1091 )
1093 return outputs
File /usr/local/lib/python3.8/dist-packages/nemo/collections/asr/models/ctc_models.py:543, in EncDecCTCModel.forward(self, input_signal, input_signal_length, processed_signal, processed_signal_length)
540 if self.spec_augmentation is not None and self.training:
541 processed_signal = self.spec_augmentation(input_spec=processed_signal, length=processed_signal_length)
--> 543 encoder_output = self.encoder(audio_signal=processed_signal, length=processed_signal_length)
544 encoded = encoder_output[0]
545 encoded_len = encoder_output[1]
File /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py:1501, in Module._call_impl(self, *args, **kwargs)
1496 # If we don't have any hooks, we want to skip the rest of the logic in
1497 # this function, and just call forward.
1498 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1499 or _global_backward_pre_hooks or _global_backward_hooks
1500 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1501 return forward_call(*args, **kwargs)
1502 # Do not call functions when jit is used
1503 full_backward_hooks, non_full_backward_hooks = [], []
File /usr/local/lib/python3.8/dist-packages/nemo/core/classes/common.py:1087, in typecheck.__call__(self, wrapped, instance, args, kwargs)
1084 instance._validate_input_types(input_types=input_types, ignore_collections=self.ignore_collections, **kwargs)
1086 # Call the method - this can be forward, or any other callable method
-> 1087 outputs = wrapped(*args, **kwargs)
1089 instance._attach_and_validate_output_types(
1090 output_types=output_types, ignore_collections=self.ignore_collections, out_objects=outputs
1091 )
1093 return outputs
File /usr/local/lib/python3.8/dist-packages/nemo/collections/asr/modules/conv_asr.py:196, in ConvASREncoder.forward(self, audio_signal, length)
194 @typecheck()
195 def forward(self, audio_signal, length):
--> 196 self.update_max_sequence_length(seq_length=audio_signal.size(2), device=audio_signal.device)
197 s_input, length = self.encoder(([audio_signal], length))
198 if length is None:
File /usr/local/lib/python3.8/dist-packages/nemo/collections/asr/modules/conv_asr.py:205, in ConvASREncoder.update_max_sequence_length(self, seq_length, device)
203 def update_max_sequence_length(self, seq_length: int, device):
204 # Find global max audio length across all nodes
--> 205 if torch.distributed.is_initialized():
206 global_max_len = torch.tensor([seq_length], dtype=torch.float32, device=device)
208 # Update across all ranks in the distributed system
AttributeError: module 'torch.distributed' has no attribute 'is_initialized'
查看pytorch是否支持distributed
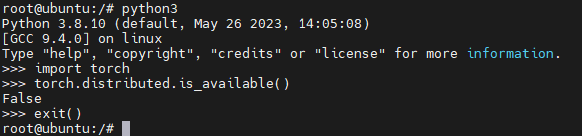
难道要重新编译pytorch的源码才行吗?
张小白曾经重新编译了pytorch的代码:
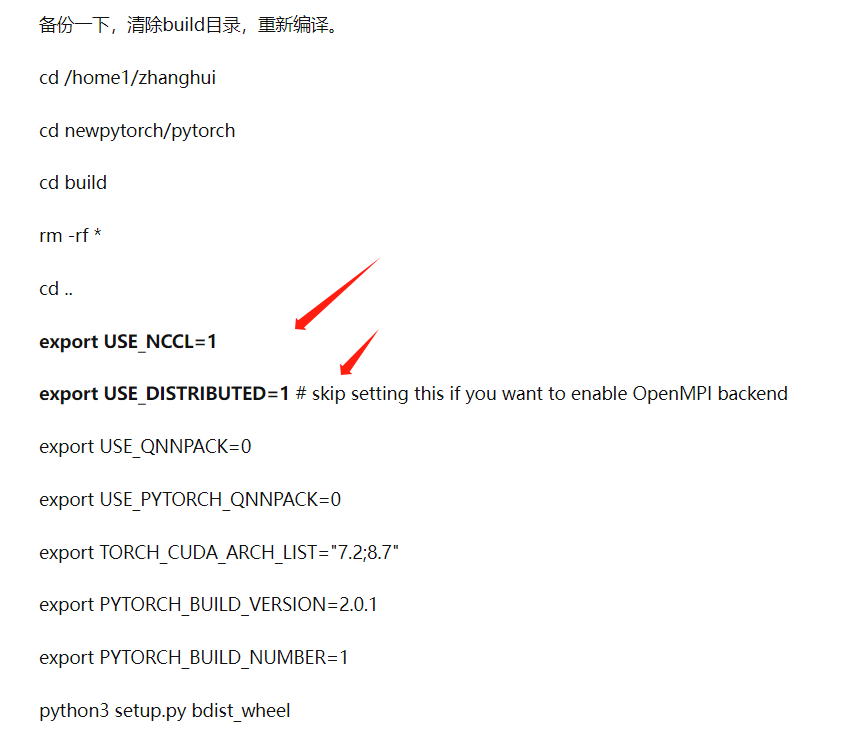
当时改了上面两个参数。
当时编译好的whl包是:torch-2.0.1-cp38-cp38-linux_aarch64.whl
不妨拿这个包试一下。
先将这个包拷贝到 data目录下:
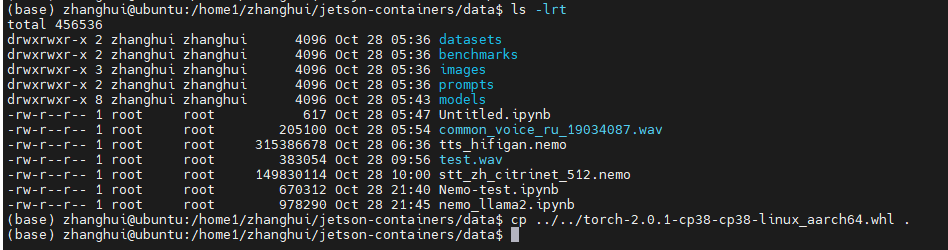
再回到容器里面,cd /data
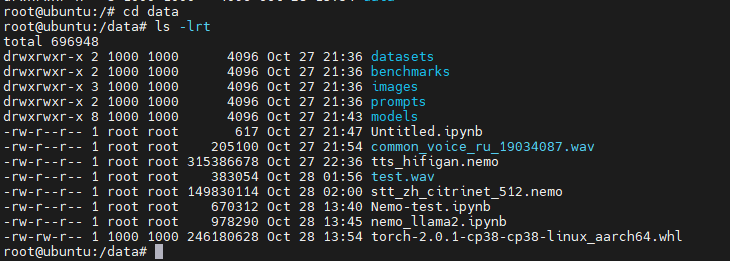
安装:
pip install ./torch-2.0.1-cp38-cp38-linux_aarch64.whl --force-reinstall
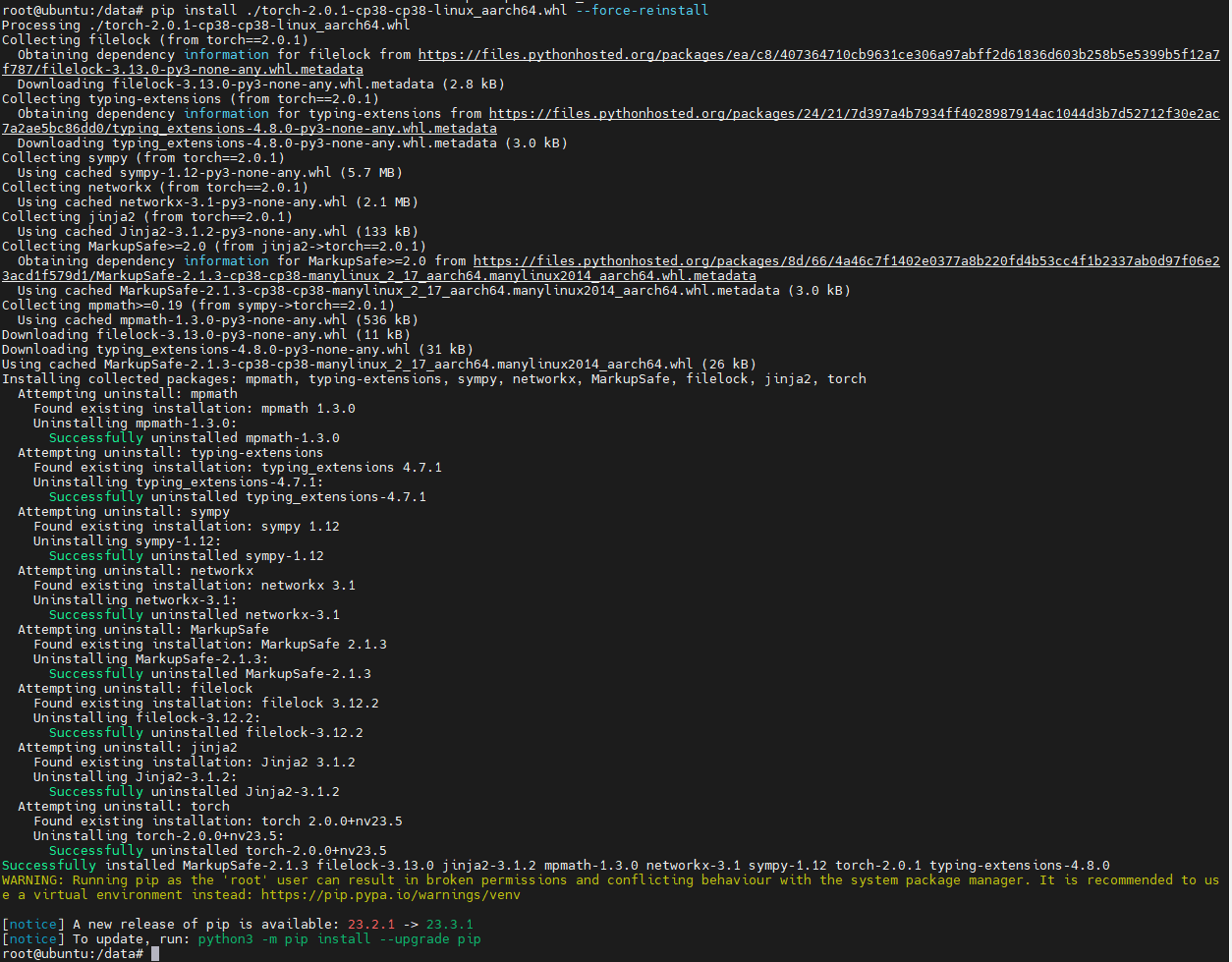
重新打开notebook:
jupyter lab --no-browser --allow-root
重新执行:

看来有希望。
我们重试下。
先试验语音转文字:
import nemo
import nemo.collections.asr as nemo_asr
import nemo.collections.tts as nemo_tts
import chinese2digits as c2d #pip install chinese2digits安装中文与数字转换工具库
citrinet = nemo_asr.models.EncDecCTCModel.from_pretrained(model_name="stt_zh_citrinet_512")# 加载ASR语音识别预训练模型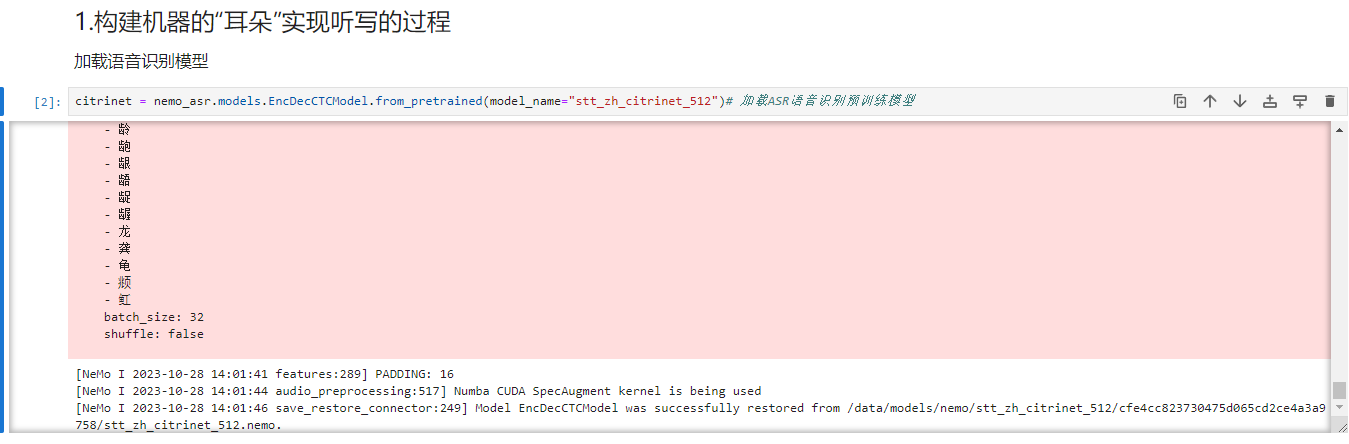
asr_result = citrinet.transcribe(paths2audio_files=["test.wav"])
asr_result = " ".join(asr_result)
asr_result = c2d.takeChineseNumberFromString(asr_result)['replacedText']
print(asr_result)
跳过大模型的部分,继续尝试 文字转语音:
from nemo.collections.tts.models import FastPitchModel
from matplotlib.pyplot import imshow
from matplotlib import pyplot as plt
spec_generator = FastPitchModel.from_pretrained(model_name="tts_zh_fastpitch_sfspeech")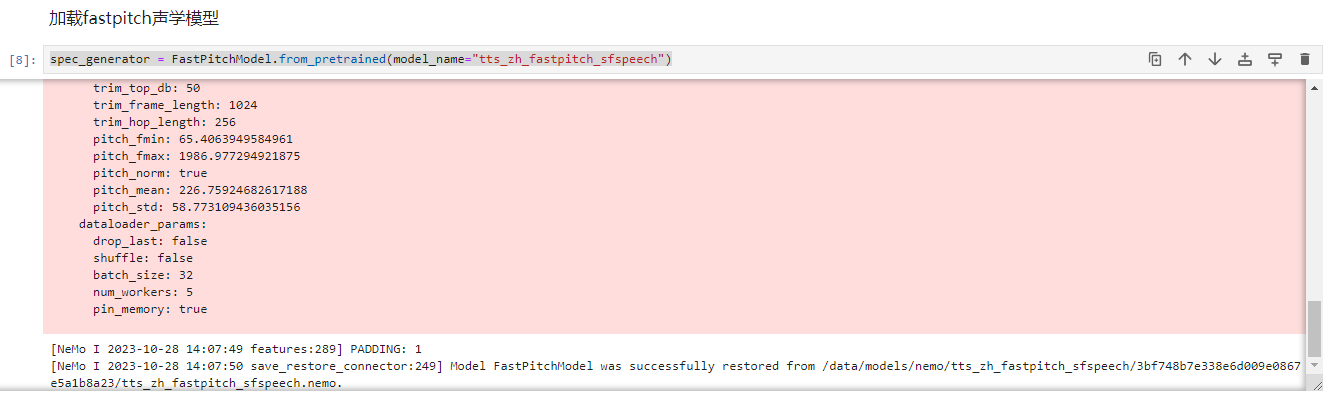
response = "Hi, I am Zhanghui. Welcome to AI World"
#response = "您好,我是张辉,有什么可以帮助您?"
parsed = spec_generator.parse(response)
spectrogram = spec_generator.generate_spectrogram(tokens=parsed)#调用模型的generate_spectrogram函数生成频谱图
imshow(spectrogram.cpu().detach().numpy()[0,...], origin="lower")#将Tensor转换为numpy array进行可视化
plt.show() #matplotlib展示文字对应的频谱图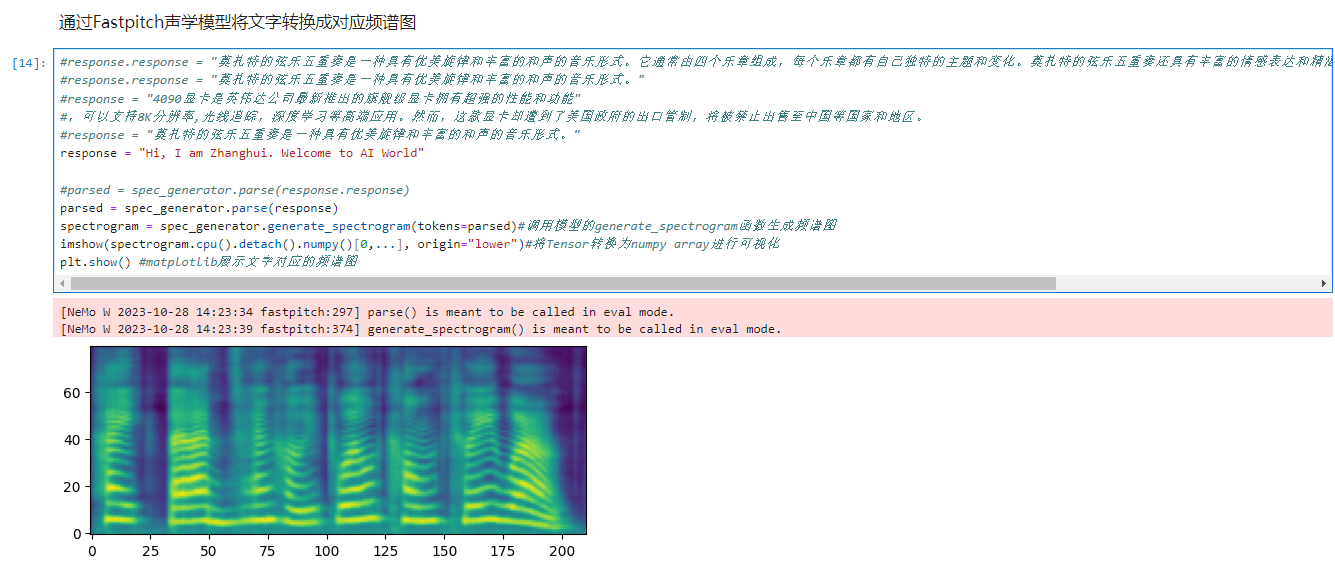
from nemo.collections.tts.models import HifiGanModel
#model = HifiGanModel.from_pretrained("tts_hifigan")
#model.save_to(f'tts_hifigan.nemo')
Hifigan = HifiGanModel.restore_from("tts_hifigan.nemo")
import IPython
audio = Hifigan.convert_spectrogram_to_audio(spec=spectrogram) #调用模型convert_spectrogram_to_audio()函数进行频谱到音频文件的转换
IPython.display.Audio(audio.to('cpu').detach().numpy(), rate=22050)
好像都是可以的(至少英文转语音是可以的)
倒回来试一下 俄语语音-》俄语文字-》英语文字
# Import NeMo and it's ASR, NLP and TTS collections
import nemo
# Import Speech Recognition collection
import nemo.collections.asr as nemo_asr
# Import Natural Language Processing colleciton
import nemo.collections.nlp as nemo_nlp
# Import Speech Synthesis collection
import nemo.collections.tts as nemo_tts
# Next, we instantiate all the necessary models directly from NVIDIA NGC
# Speech Recognition model - QuartzNet trained on Russian part of MCV 6.0
quartznet = nemo_asr.models.EncDecCTCModel.from_pretrained(model_name="stt_ru_quartznet15x5").cuda()

#加载俄文翻译英文模型
# Neural Machine Translation model
nmt_model = nemo_nlp.models.MTEncDecModel.from_pretrained(model_name='nmt_ru_en_transformer6x6').cuda()
# Spectrogram generator which takes text as an input and produces spectrogram
spectrogram_generator = nemo_tts.models.FastPitchModel.from_pretrained(model_name="tts_en_fastpitch").cuda()
# Vocoder model which takes spectrogram and produces actual audio
#vocoder = nemo_tts.models.HifiGanModel.from_pretrained(model_name="tts_hifigan").cuda()
#vocoder = nemo_tts.models.HifiGanModel.from_pretrained(model_name="tts_en_hifigan").cuda()
vocoder = nemo_tts.models.HifiGanModel.restore_from("tts_hifigan.nemo").cuda()
# Transcribe an audio file
# IMPORTANT: The audio must be mono with 16Khz sampling rate
# Get example from: https://nemo-public.s3.us-east-2.amazonaws.com/mcv-samples-ru/common_voice_ru_19034087.wav
russian_text = quartznet.transcribe(['common_voice_ru_19034087.wav'])
print(russian_text)
# You should see russian text here. Let's translate it to English
english_text = nmt_model.translate(russian_text)
print(english_text)
这里好像有点不对头。不是俄文转英文吗?
# After this you should see English translation
# Let's convert it into audio
# A helper function which combines FastPitch and HiFiGAN to go directly from
# text to audio
def text_to_audio(text):
parsed = spectrogram_generator.parse(text)
spectrogram = spectrogram_generator.generate_spectrogram(tokens=parsed)
audio = vocoder.convert_spectrogram_to_audio(spec=spectrogram)
return audio.to('cpu').numpy()
audio = text_to_audio(english_text[0])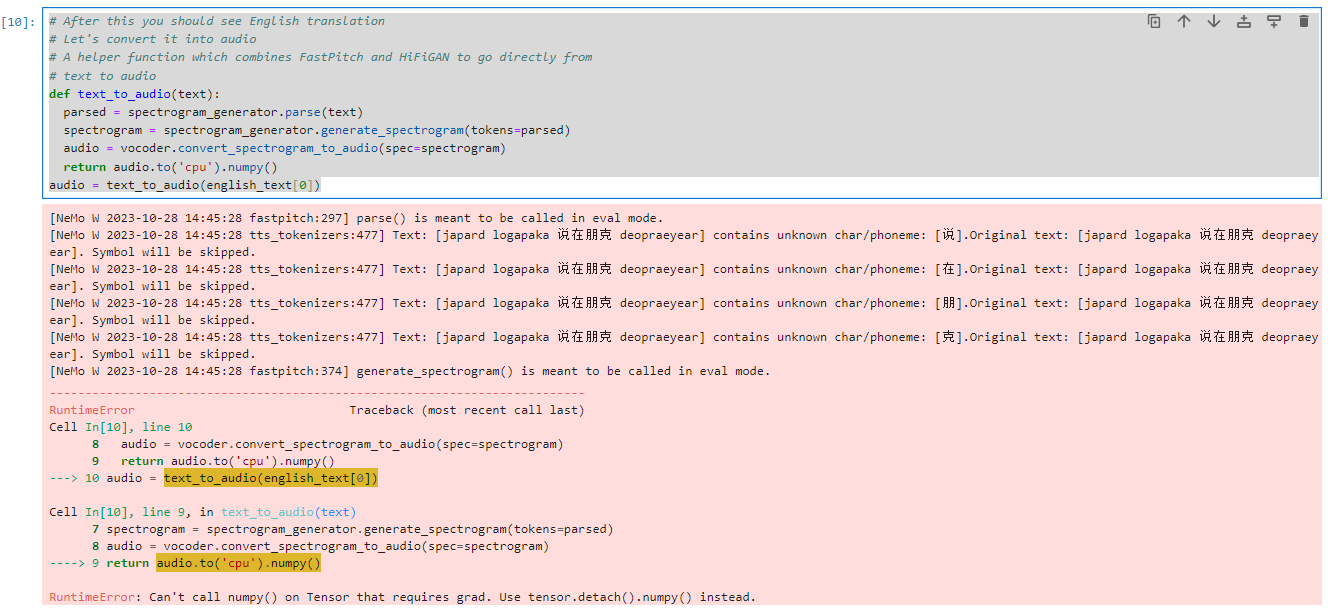
好像这个cell跟原来一样,也无法正常运行。
至此,我们使用官方的容器,换了张小白编译好的pytorch包。基本上算是完成了语音识别和文字转语音。还有些小BUG待日后再解吧。
最后将容器commit成镜像:
sudo docker ps
sudo docker commit de6066a9ebdc zhanghui-nemo:v0.2
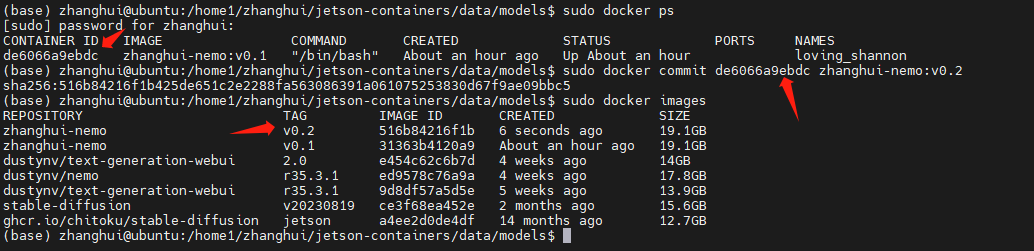
记得下次启动容器的方法是:
cd /home1/zhanghui/jetson-containers
./run.sh -v /home1/zhanghui/jetson-containers/data:/data zhanghui-nemo:v0.2
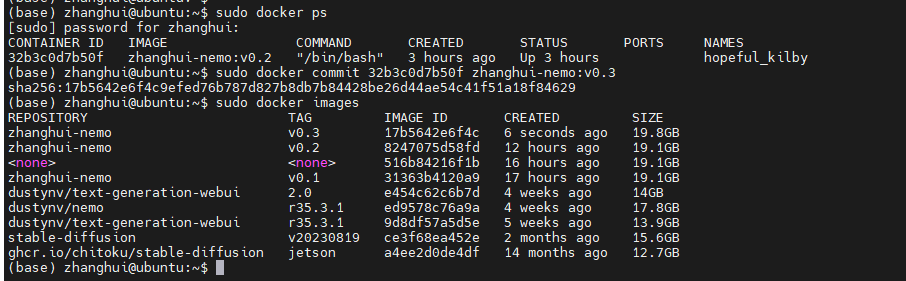
以前尝试更新1:
咨询了一下专家,说装一下nemo 1.8.1试试。
登录进入容器:

pip install nemo_toolkit[all]==1.8.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
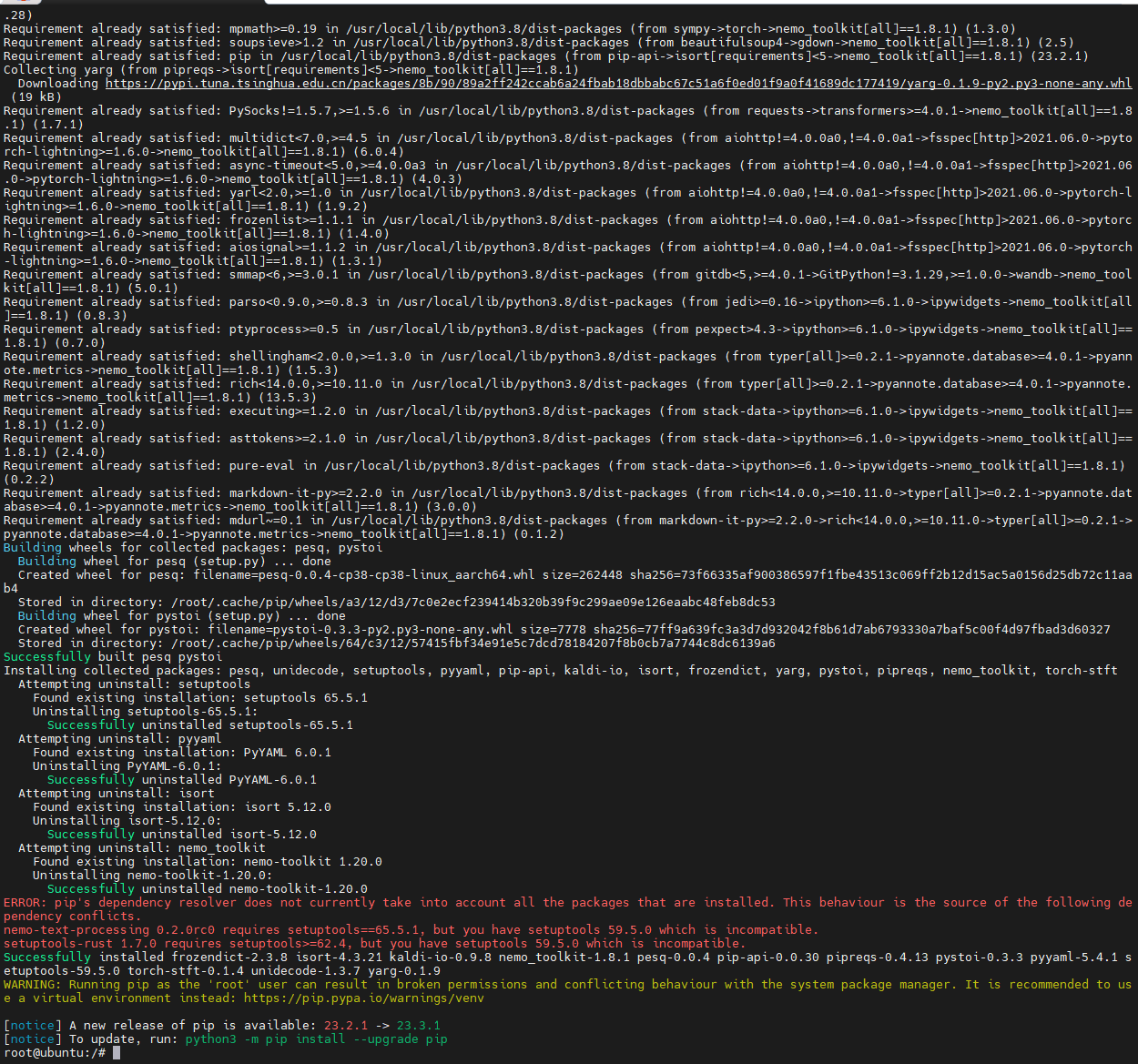
重新打开jupyterlab
jupyter lab --no-browser --allow-root
执行import就报错了!
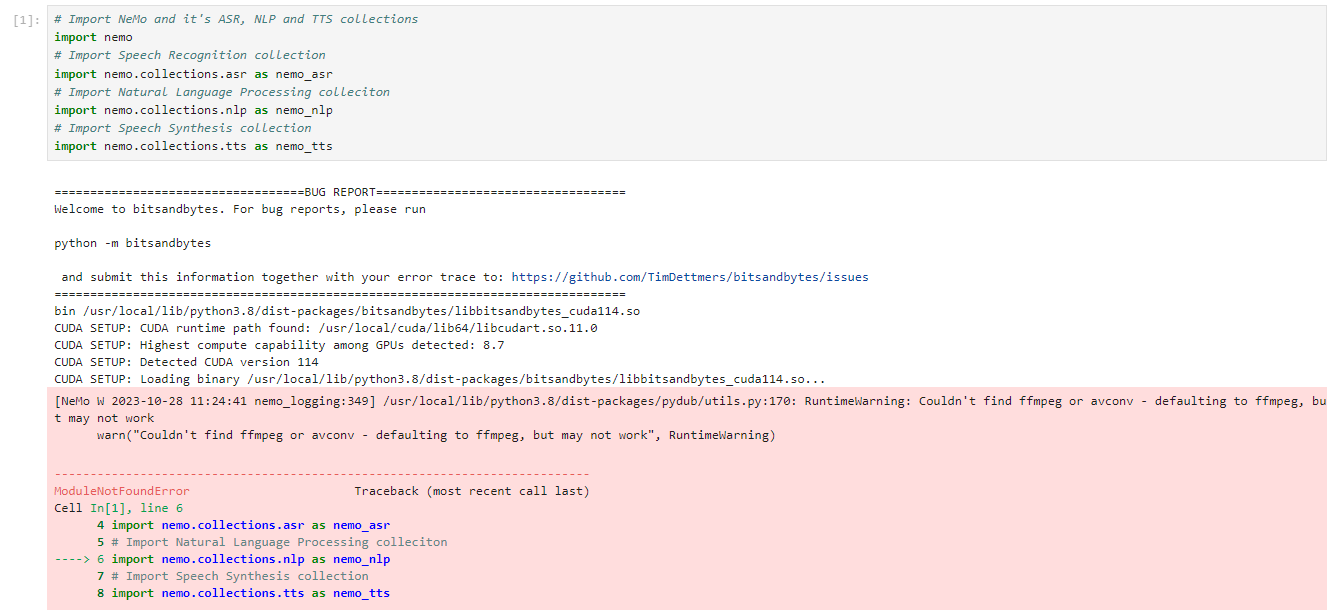
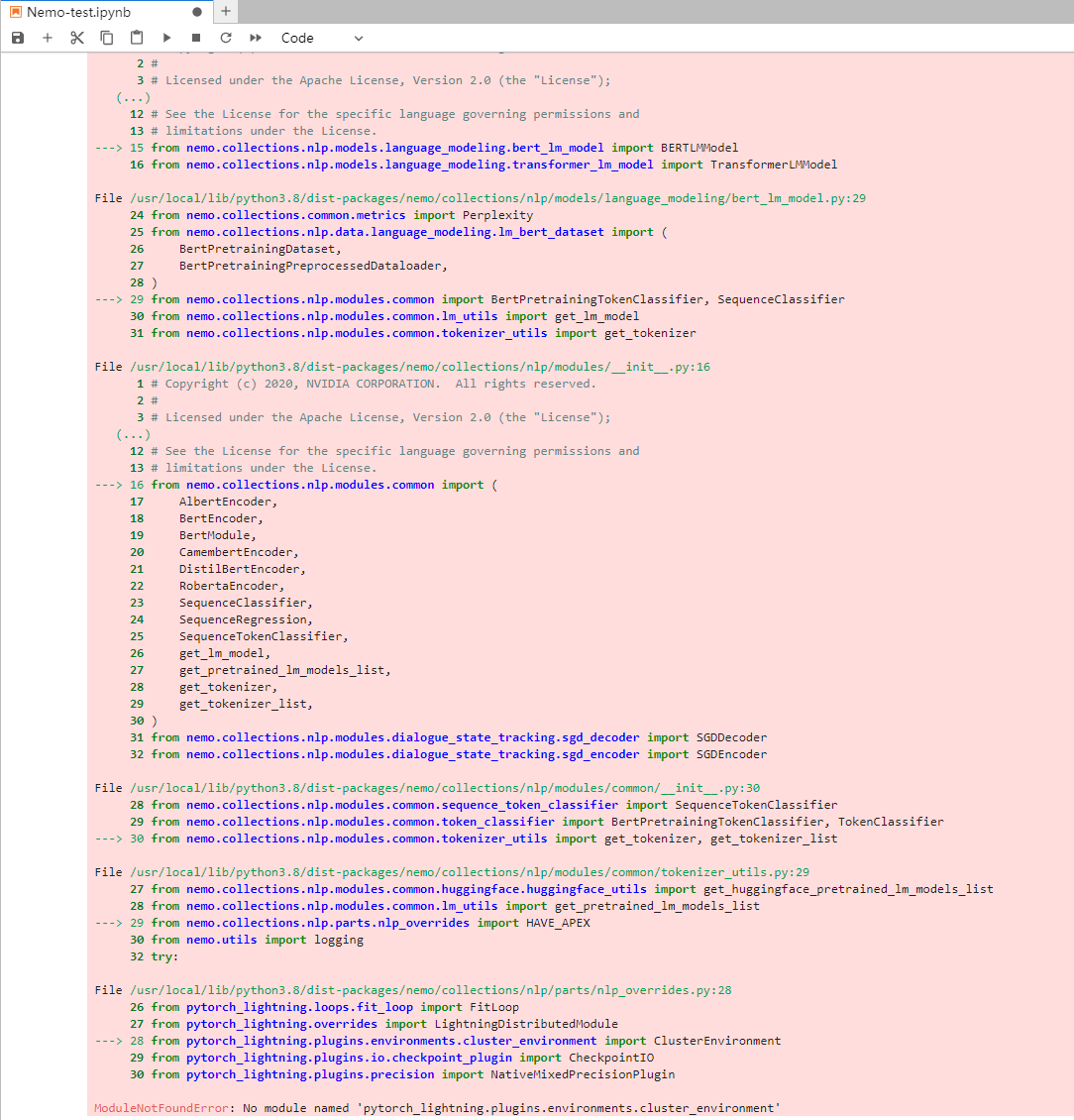
只好退出容器后重新进入。
前面的样例是 俄语语音识别成俄语文字,然后翻译成英文。俄语张小白也不大懂,大概只知道乌拉、赫拉笑之类的。
不如试一下 英语语音识别成英语文字,然后翻译成中文。
具体过程如下:
1.加载包
# Import NeMo and it's ASR, NLP and TTS collections
import nemo
# Import Speech Recognition collection
import nemo.collections.asr as nemo_asr
# Import Natural Language Processing colleciton
import nemo.collections.nlp as nemo_nlp
# Import Speech Synthesis collection
import nemo.collections.tts as nemo_tts
2.加载英文语音识别模型:
# Next, we instantiate all the necessary models directly from NVIDIA NGC
# Speech Recognition model - QuartzNet trained on Russian part of MCV 6.0
#quartznet = nemo_asr.models.EncDecCTCModel.from_pretrained(model_name="stt_ru_quartznet15x5").cuda()
quartznet = nemo_asr.models.EncDecCTCModel.from_pretrained(model_name="stt_en_quartznet15x5").cuda()

3.加载英文翻译中文模型:
# Neural Machine Translation model
#nmt_model = nemo_nlp.models.MTEncDecModel.from_pretrained(model_name='nmt_ru_en_transformer6x6').cuda()
nmt_model = nemo_nlp.models.MTEncDecModel.from_pretrained(model_name='nmt_en_zh_transformer6x6').cuda()
# Spectrogram generator which takes text as an input and produces spectrogram
spectrogram_generator = nemo_tts.models.FastPitchModel.from_pretrained(model_name="tts_en_fastpitch").cuda()
#spectrogram_generator = nemo_tts.models.FastPitchModel.from_pretrained(model_name="tts_en_fastpitch").cuda()
这个好像没有中文的包。
# Vocoder model which takes spectrogram and produces actual audio
#vocoder = nemo_tts.models.HifiGanModel.from_pretrained(model_name="tts_hifigan").cuda()
vocoder = nemo_tts.models.HifiGanModel.restore_from("tts_hifigan.nemo").cuda()
#vocoder = nemo_tts.models.HifiGanModel.from_pretrained(model_name="tts_en_hifigan").cuda()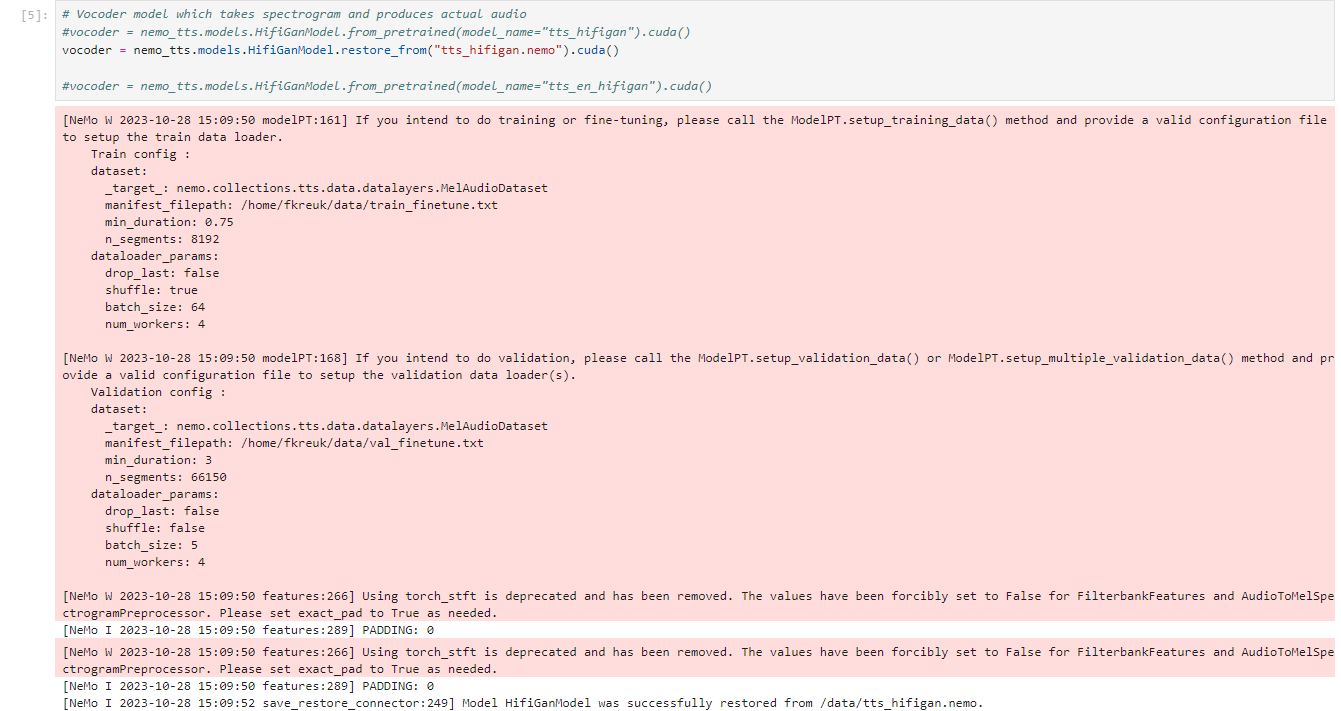
录一段英文,保存成wav格式(单声道)

上传到/data
开始识别:
# Transcribe an audio file
# IMPORTANT: The audio must be mono with 16Khz sampling rate
# Get example from: https://nemo-public.s3.us-east-2.amazonaws.com/mcv-samples-ru/common_voice_ru_19034087.wav
english_text = quartznet.transcribe(['EnglishVoice.wav'])
print(english_text)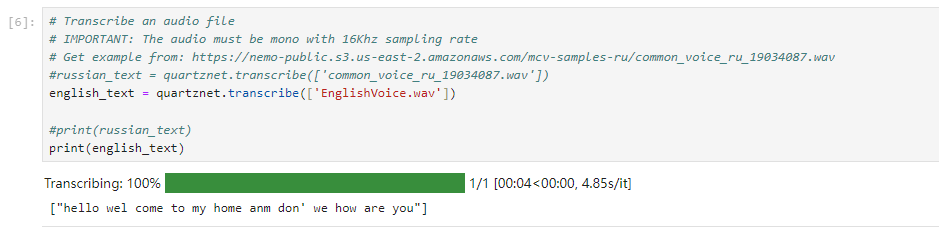
其实英文识别得不错。我的原话是:
Hello, Welcome to my home, How are you?
# You should see russian text here. Let's translate it to English
english_text = "Hello, Welcome to my home, I am Zhang Hui"
chinese_text = nmt_model.translate(english_text)
print(chinese_text)
这一段的翻译就不敢恭维了。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)