【论文导读】 - A Comprehensive Survey on Trustworthy Graph Neural Netw

@[TOC]
论文信息
A Comprehensive Survey on Trustworthy Graph Neural Networks: Privacy, Robustness, Fairness, and Explainability
关于可信图神经网络的全面综述:隐私性、健壮性、公平性和可解释性

摘要
Graph Neural Networks (GNNs) have made rapid developments in the recent years. Due to their great ability in modeling graph-structured data, GNNs are vastly used in various applications, including high-stakes scenarios such as financial analysis, traffic predictions, and drug discovery. Despite their great potential in benefiting humans in the real world, recent study shows that GNNs can leak private information, are vulnerable to adversarial attacks, can inherit and magnify societal bias from training data and lack interpretability, which have risk of causing unintentional harm to the users and society. For example, existing works demonstrate that attackers can fool the GNNs to give the outcome they desire with unnoticeable perturbation on training graph. GNNs trained on social networks may embed the discrimination in their decision process, strengthening the undesirable societal bias. Consequently, trustworthy GNNs in various aspects are emerging to prevent the harm from GNN models and increase the users’ trust in GNNs. In this paper, we give a comprehensive survey of GNNs in the computational aspects of privacy, robustness, fairness, and explainability. For each aspect, we give the taxonomy of the related methods and formulate the general frameworks for the multiple categories of trustworthy GNNs. We also discuss the future research directions of each aspect and connections between these aspects to help achieve trustworthiness.
由于GNN在建模图结构数据方面的强大能力,GNN被广泛用于各种应用,包括高风险场景,如财务分析、流量预测和药物发现。尽管在现实世界中,GNN在造福人类方面具有巨大潜力,但最近的研究表明,GNN可以泄露私人信息,容易受到敌对攻击,可以从训练数据中继承和放大社会偏见,并且缺乏可解释性,这有可能对用户和社会造成意外伤害。例如,现有的工作表明,攻击者可以欺骗GNNs以在训练图上进行不明显的扰动来给出他们想要的结果。在社交网络上接受培训的GNN可能会在他们的决策过程中嵌入歧视,从而加强了令人不快的社会偏见。因此,在各个方面值得信赖的GNNs不断涌现,以防止GNN模型的危害和增长。在本文中,我们对GNNs在隐私性、鲁棒性、公平性和可解释性的计算方面进行了全面的综述。对于每个方面,我们给出相关方法的分类法,并为多个类别的可信GNN制定通用框架。我们还讨论了每个方面的未来研究方向以及这些方面之间的联系,以帮助实现可信性。
主要内容
该文是一篇关于图神经网络在隐私性、鲁棒性、公平性和可解释性的计算等方面的综述文章。主要的contributions如下:
- 首先介绍了图神经网络相关的预备知识(如果对GNN不太清楚的可以看看我的这篇博客:【图神经网络】 - GNN的几个模型及论文解析(NN4G、GAT、GCN):https://blog.csdn.net/weixin_43598687/article/details/126946131)
- 对GNNs的隐私攻击和防御方面的现有工作进行了全面的综述,并给出了未来的发展方向。还列出了隐私域中的图形数据集。
- 讨论了GNN模型上的各种对抗攻击和防御方法。进一步介绍了GNN鲁棒性的一些最新进展,如可伸缩攻击、图后门攻击和自监督学习防御方法。
- 讨论了可信GNN的公平性,其中包括图结构数据的偏差和公平性定义、各种公平GNN模型以及它们所应用的数据集。
- 介绍了GNN可解释性的全面调查,介绍现有工作所采用的动机、挑战和实验设置。
下面,我们就一起来看看文章中隐私保护这一章节的内容。
图神经网络的隐私保护
1. 隐私攻击的分类
1.1 GNN的隐私攻击类型。
对GNN进行隐私攻击的目的是提取不打算共享的信息。目标信息可以是关于训练图的,例如成员资格、节点的敏感属性和节点的连接。此外,一些攻击者旨在提取GNN的模型参数。基于目标知识,GNN上不同类型的隐私攻击方法可以分为如下几类:
- Membership inference
- Property Inference
- Reconstruction attack
- Model extraction
Membership inference
在成员关系推断 攻击中,攻击者试图确定目标样本是否为训练集的一部分。例如,假设研究人员在COVID - 19患者的社交网络上训练一个GNN模型来分析病毒的传播。成员关系推断攻击可以识别目标主体是否在训练患者网络,导致该主体的信息泄露。
Property Inference
与属性重构攻击不同,属性推断攻击旨在推断未编码为特征的数据集属性。例如,人们可能想推断社会网络中女性和男性的比例,而这些信息并不包含在节点属性中。攻击者还可能对与结构相关的属性感兴趣,例如节点的度,即社交网络中目标用户的朋友数。
Reconstruction attack
重构攻击,也称为模型反转攻击,旨在推断输入图的私有信息。由于图结构数据由图的拓扑结构和节点属性组成,对GNNs的重构攻击可以拆分为结构重构,即推断目标样本的结构和属性重构(也称为属性推断攻击),即推断目标样本的属性。通常,目标样本的嵌入是进行重构攻击所必需的。
Model extraction
模型提取攻击旨在通过学习与目标模型行为相似的模型来提取目标模型信息。它可能关注模型信息的不同方面,这导致了模型提取中的两个目标
(1)攻击者旨在获得与目标模型的准确性相匹配的模型;
(2)攻击者试图复制目标模型的决策边界。模型提取攻击可以威胁API服务模型的安全,并且可以成为各种隐私攻击和对抗攻击的垫脚石。
1.2 隐私攻击的威胁模型。
根据目标GNN的模型参数是否可用,攻击者关于威胁模型的知识可以拆分为两种类型:白盒攻击 和 黑盒攻击。
- 白盒攻击
在白盒攻击中,攻击者可以访问训练过程中的模型参数或梯度。除了关于训练好的GNN的知识外,攻击可能还需要一些其他知识,如推断攻击中需要攻击的节点/图以及一个阴影数据集,即与目标GNN的训练数据集服从相同分布的数据集。白盒攻击可用于攻击模型已公开发布的预训练GNN。在联邦学习的训练过程中,中间计算也是实用的。 - 黑盒攻击
与白盒攻击不同,黑盒攻击中目标GNN的参数是未知的;而目标GNN的体系结构和训练过程中的超参数可能是已知的。在这种设置下,攻击者一般被允许查询目标GNN模型以得到查询样本的预测向量或嵌入。与白盒攻击类似,阴影数据集和目标节点/图形也需要进行黑盒攻击。黑盒隐私攻击的一个实际例子是在收到用户的查询时,攻击发送GNN模型输出的API服务。
2. 对GNN进行隐私攻击的方法
2.1 有监督隐私攻击框架
有监督隐私攻击方法的核心思想是利用阴影数据集和目标模型的输出,得到用于训练隐私攻击方式的监督,如下图所示:
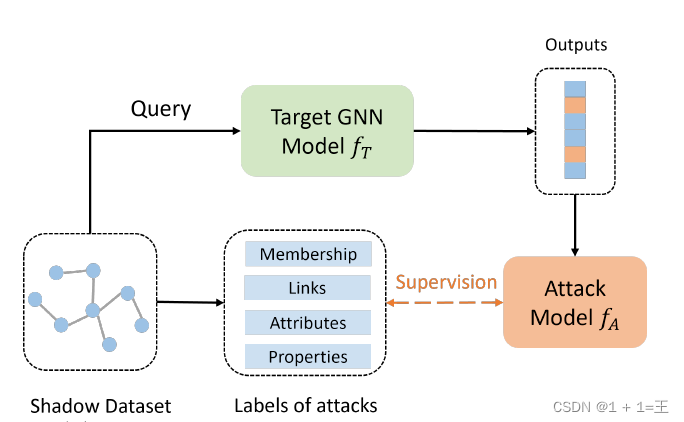
攻击者使用阴影数据集D~𝑆~作为目标模型𝑓~𝑇~的输入来获得预测或嵌入。然后,可以获得阴影数据集上各种类型隐私攻击的基本事实。利用来自阴影数据集的攻击标签,攻击者可以训练一个攻击模型,该模型根据目标模型的输出执行推理:
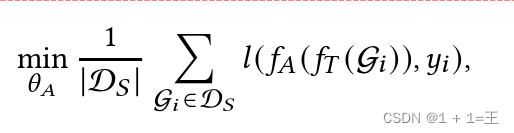
其中:
- G~i~ 表示来自阴影数据集的样本,这些样本可以是节点𝑣~𝑖~ 的用于节点分类的局部图的子图,也可以是用于图分类的样本图。
- 𝑦~i~ 表示样本G~i~ 提取的攻击标签。
- 𝑙 ( · )表示损失函数,例如交叉熵损失来训练攻击模型𝑓~𝐴~。
- 𝜃~𝐴~ 表示攻击模型𝑓~𝐴~ 的参数。攻击模型训练完成后,可以通过𝑓~𝐴~ ( 𝑓~T~ ( G~t~ )) )对目标示例G~𝑡~进行隐私攻击。
2.2 成员关系推断攻击
成员推断攻击旨在识别目标样本是否用于训练目标模型𝑓~T~。成员身份的隐私泄露是由于模型在训练数据集上的过拟合造成的,导致训练和测试数据集的预测向量(预测标签分布)服从不同的分布。因此,攻击者可以利用预测向量来判断数据实例是否在~T~的训练集中。
其最常见的方法是应用阴影训练来获得成员推断的监督,并训练一个攻击模型。
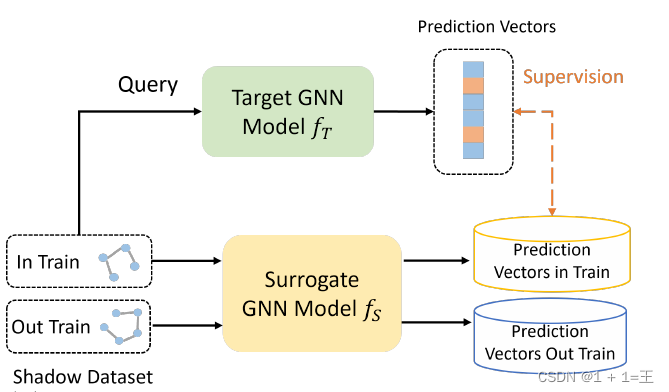
在阴影训练中,阴影数据集D 𝑡 𝑟 𝑎 𝑖 𝑛 𝑆的一部分用于训练代理模型𝑓~𝑆~以模拟目标模型的行为:
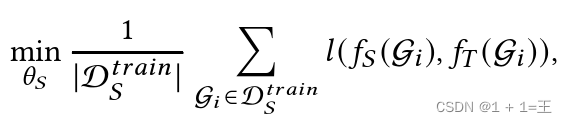
其中:
- G~𝑖~ 是用于图分类的图,或者以节点𝑣~𝑖~ 为中心的用于节点分类的𝑘 - hop子图。
- 𝑓~T~ ( G~i~ )表示G~i~ 的预测标签分布。
- 𝑙 ( · )为交叉熵损失等损失函数。
2.3 重建攻击
重构攻击方法将目标GNN学习到的节点嵌入信息H = [ h1 , … , h 𝑁]进行重构。对于属性重构,𝑓 𝐴可以简单地作为一个多层感知器( MLP )并将属性重构为( X = 𝑀 𝐿 𝑃 ( H ) )。对于链接推断,𝑓 𝐴通常根据𝑤 ( 𝑖、𝑗) = 𝑀 𝐿 𝑃 ( h 𝑖 , h 𝑗)节点𝑣 𝑖和𝑣 𝑗的嵌入预测链接。遵循统一框架,使用阴影图G 𝑆提供邻接矩阵A 𝑆和敏感属性X 𝑆作为监督。假设阴影图的节点嵌入H 𝑆是可用的。
然后,攻击模型可以采用有监督的方式进行训练。对于属性重构攻击,给定训练损失为
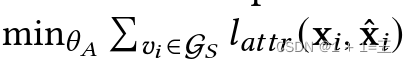
,其中𝑙 𝑎 𝑡 𝑡 𝑟可以是连续属性的MSE损失,也可以是分类属性的交叉熵损失。
对于链接推断,目标函数为:
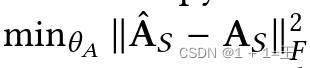
,其中A 𝑆是由𝑓 𝐴重构的邻接矩阵。攻击者模型通过图嵌入直接推断邻接矩阵( A = 𝑀 𝐿 𝑃 ( h 𝐺 ),其中h 𝐺表示图嵌入。
2.4 属性推断攻击
属性推断攻击仍处于早期阶段。最初的工作是通过嵌入来推断目标图的属性。所提出的方法也遵循统一的框架。令𝑝 𝑖表示阴影数据集D 𝑆中图G 𝑖的属性,攻击模型由
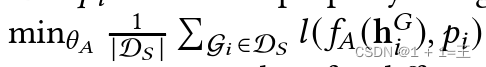
训练,其中h 𝐺 𝑖 = 𝑓 𝑇 ( G 𝑖 )为G 𝑖的嵌入。对于不同类型的属性,𝑙 ( · )可以是MSE损失或者交叉熵损失。
2.5 模型提取攻击
模型提取攻击旨在学习一个与目标模型行为相似的代理模型。训练代理模型的过程也包含在成员推断攻击中,一般情况下,攻击者会首先查询目标模型以获得阴影数据集上的预测。然后,它利用阴影数据集和相应的预测来训练模型提取攻击的代理模型。
3. 图神经网络的隐私保护
目前的GNN隐私保护一般分为三类:差分隐私保护、联邦学习和对抗隐私保护。
3.1 基于差分隐私的GNN隐私保护
差分隐私一种能够提供训练数据隐私保护的流行方法。差分隐私的核心思想是,如果两个数据集仅相差一条记录,并且被同一个算法使用,那么算法在两个数据集上的输出应该是相似的。通过差分隐私,单个样本的影响被严格控制。因此,成员推理攻击可以由DP防御,并有理论保证。形式上,差分隐私的定义如下:
给定𝜖 > 0和𝛿>=0,一个随机的机理M满足( 𝜖 , 𝛿)差分隐私,如果对任意相邻的数据集𝐷和𝐷′以及对任意的输出子集S,满足下面的方程:
其中,𝜖是权衡效用和隐私的隐私预算。更大的𝜖将导致更强的隐私保证,但效用较弱。当𝛿 = 0时,它相当于𝜖 -差分隐私。( 𝜖 , 𝛿) - DP允许普通𝜖 - DP以小概率𝛿被破坏的可能性。
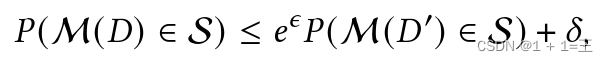 其中,𝜖是权衡效用和隐私的隐私预算。更大的𝜖将导致更强的隐私保证,但效用较弱。当𝛿 = 0时,它相当于𝜖 -差分隐私。( 𝜖 , 𝛿) - DP允许普通𝜖 - DP以小概率𝛿被破坏的可能性。
其中,𝜖是权衡效用和隐私的隐私预算。更大的𝜖将导致更强的隐私保证,但效用较弱。当𝛿 = 0时,它相当于𝜖 -差分隐私。( 𝜖 , 𝛿) - DP允许普通𝜖 - DP以小概率𝛿被破坏的可能性。为了实现( 𝜖 , 𝛿) -差分隐私,一些加性噪声机制如高斯机制和拉普拉斯机制被广泛采用。基于隐私预算和需要保护的机制,一定水平的高斯噪声或拉普拉斯噪声将被注入以实现差分隐私机制。
3.2 基于联邦学习的GNN隐私保护
目前,大多数深度学习方法都需要集中存储用户数据进行训练。然而,由于隐私问题,这可能是不现实的。例如,当几家公司或医院希望将它们的数据结合起来训练GNN模型时,它们的用户的数据不允许根据隐私条款共享。此外,用户可能由于担心信息泄露而不愿意将数据上传到平台服务器。对于这种情况,数据将保留在用户或数据持有者组织的本地设备中。
为了解决这个问题,联邦学习被提出来以隐私保护的方式对具有分散用户数据的模型进行集体学习。特别地,它旨在优化以下目标函数:
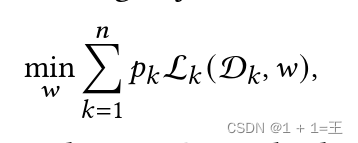
其中:
- 𝑛为设备/客户端总数;
- D𝑘为存储在𝑘客户端的本地数据集;
- L𝑘为𝑘设备的本地目标函数。
- 每个设备的冲击力由𝑝~𝑘~控制,𝑝~𝑘~≥0且∑~𝑘~𝑝~𝑘~ = 1。𝑝~𝑘~通常设置为1/n或| D~𝑘~ | / | D |,其中| D | = ∑~k~| D 𝑘 |是样本的总大小。
联邦学习求解方程的一般框架如下图所示,其中用户数据和本地模型在联邦学习中的客户机中维护。
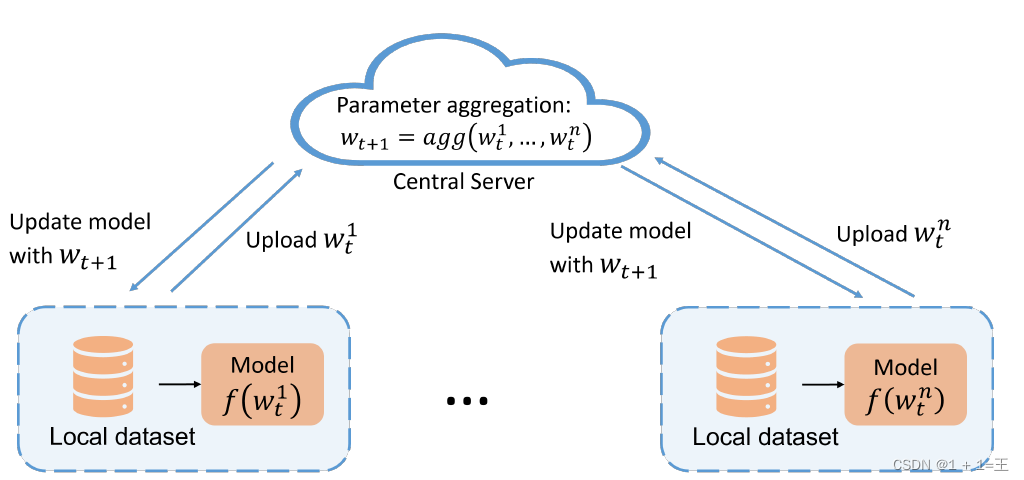
在训练步骤𝑡中,每个客户机将根据自己的数据计算本地模型更新。然后,中心服务器将聚合来自客户端的模型更新,并将全局模型参数更新为𝑤~t~ + 1。更新后的全局模型将分发给客户端,供以后的迭代使用。
特别地,FedAvg模型参数通过将来自客户端的更新模型参数平均为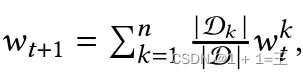 ,其中𝑤𝑘~𝑡~表示客户端在步骤𝑡中的更新参数。
,其中𝑤𝑘~𝑡~表示客户端在步骤𝑡中的更新参数。
3.1 基于对抗隐私的GNN隐私保护
为了防御敏感属性/链接泄露攻击,采用对抗学习对GNNs进行隐私保护。设H为编码器, GNN学习到的节点表示H = 𝑓~𝐸~ ( G ; 𝜃)。对抗隐私保护的核心思想是采用对抗𝑓~𝐴~从节点表示中推断敏感属性,而编码器𝑓~𝐸~旨在学习能够欺骗𝑓~𝐴~的表示,即使𝑓~𝐴~无法推断敏感属性。理论上表明,通过这种minmax博弈,可以最小化学习到的表示与敏感属性𝑀𝐼 ( H , 𝑠)之间的互信息,从而保护敏感信息不被泄露。该过程可以形式化地写为:
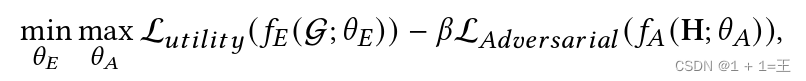
其中:
- 𝜃~E~和𝜃~A~分别是编码器𝑓~E~和对抗𝑓~A~的参数;
- L~𝑢𝑡𝑖𝑙𝑖𝑡𝑦~ 是一个损失函数,用于确保学习到的表示如分类损失和重构损失的效用;
- L~𝐴𝑑𝑣𝑒𝑟𝑠𝑎𝑟𝑖𝑎𝑙~为对抗损失,一般为基于节点表示H的对手敏感属性预测的交叉熵损失。
4. 用于隐私保护的GNNs的数据集
5. GNNs隐私保护的应用
- 预训练和模型共享。
- 分布式学习
- 保健方面
- 推荐系统
6. GNNs隐私保护的未来研究方向
-
防御各种隐私攻击
尽管已经提出了许多保护隐私的GNN,但它们主要侧重于防御成员推断攻击和属性重构攻击。针对结构攻击、属性推断攻击和模型提取攻击的隐私保护GNN研究较少。因此,开发保护隐私的GNN来抵御各种隐私攻击是有希望的。 -
GNN预训练中的隐私攻击和保护
模型预训练一直是一个常见的方案,以使缺乏标签的下游任务受益。预训练的GNN的参数将针对下游任务发布,这可能会导致私有信息泄漏。然而,现有的隐私攻击大多集中在黑盒设置上,并没有考察模型发布导致的信息泄露。因此,需要研究针对预训练GNN模型的隐私攻击和相应的防御方法。 -
隐私和效用之间的权衡
尽管应用差分隐私、联合学习或对抗学习的方法已被提出来保护训练数据的隐私,但很少讨论隐私保护性能与预测精度之间的关系。例如,在差分隐私GNNs中,一般不评估抵御各种隐私攻击的实际性能。而在对抗隐私保护的中,如何控制预测性能和隐私保护之间的平衡仍然没有得到很好的讨论。

- 点赞
- 收藏
- 关注作者
评论(0)