一文掌握Windows平台GPU深度学习开发环境部署

这是机器未来的第2篇文章,由机器未来原创
写在前面:
- 博客简介:专注AIoT领域,追逐未来时代的脉搏,记录路途中的技术成长!
- 专栏简介:记录博主从0到1掌握物体检测工作流的过程,具备自定义物体检测器的能力
- 面向人群:具备深度学习理论基础的学生或初级开发者
- 专栏计划:接下来会逐步发布跨入人工智能的系列博文,敬请期待
- Python零基础快速入门系列
- 快速入门Python数据科学系列
- 人工智能开发环境搭建系列
- 机器学习系列
- 物体检测快速入门系列
- 自动驾驶物体检测系列
- …
@[toc]
1. 概述
windows GPU深度学习开发环境的安装包含显卡驱动、cuda、cuDNN深度学习加速包、anaconda、tensorflow的安装以及安装源的配置,理解了本文,还可以安装pytorch等其他开发框架。

2. GPU工具链安装
2.1 GPU工具链的组成
Nvidia显卡、显卡驱动、cuda工具套件、cuDNN工具包四部分构成。
目前支持深度学习的显卡基本上就是N卡,不论是硬件性能,还是最新的论文支持基本上都是N卡,所以不用在这里纠结了,采购时一定要上N卡。
-
什么是cuda
CUDA(ComputeUnified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。注意:cuda的支持依赖显卡驱动的版本。 -
什么是cuDNN
NVIDIA cuDNN是用于深度神经网络的GPU加速库。它强调性能、易用性和低内存开销。NVIDIA cuDNN可以集成到更高级别的机器学习框架中,如谷歌的Tensorflow、加州大学伯克利分校的流行caffe软件。简单的插入式设计可以让开发人员专注于设计和实现神经网络模型,而不是简单调整性能,同时还可以在GPU上实现高性能现代并行计算。 -
CUDA与CUDNN的关系
CUDA看作是一个并行计算架构平台,cuDNN是基于CUDA的深度学习GPU加速库,有了它才能在GPU上完成深度学习的计算。想要在CUDA上运行深度神经网络,就要安装cuDNN,这样才能使GPU进行深度神经网络的工作,工作速度相较CPU快很多。
2.2 安装nvidia显卡驱动
下载地址:https://www.nvidia.com/download/index.aspx?lang=en-us
 根据提供的下载链接选择电脑对应的最新显卡驱动安装即可,这里需要记录一下显卡驱动的版本,安装cuda要用,我这台老电脑显卡驱动的文件名为425.31-notebook-win10-64bit-international-whql.exe,版本是425.31。
根据提供的下载链接选择电脑对应的最新显卡驱动安装即可,这里需要记录一下显卡驱动的版本,安装cuda要用,我这台老电脑显卡驱动的文件名为425.31-notebook-win10-64bit-international-whql.exe,版本是425.31。
2.3 安装cuda-通用并行计算架构平台
-
查询显卡可支持的cuda版本
- 显卡驱动cuda版本对照表
- https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html

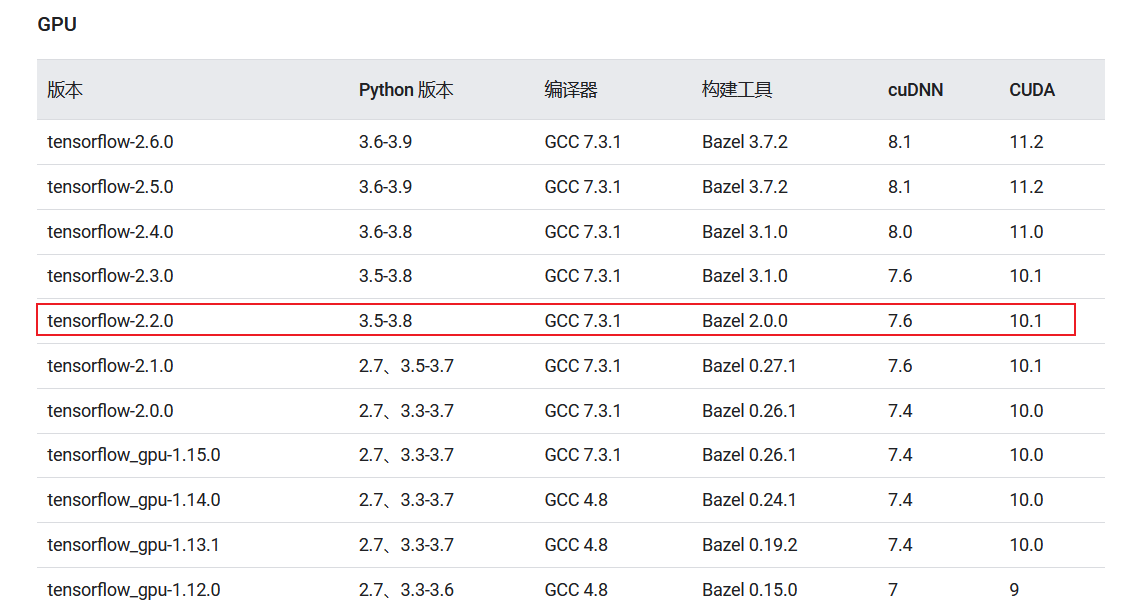
根据上一个步骤下载的显卡驱动的版本,选择可支持的最新cuda toolkit版本,从上图中可以看到支持425.31驱动版本的cuda toolkit版本是CUDA 10.1 (10.1.105 general release, and updates) ,因此选择下载cuda10.1的版本。
- https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
- 显卡驱动cuda版本对照表
-
安装cuda
- cuda下载地址:
- 下载最新版本的cuda10.1
- 选择配置
- 下载完成后,文件名为cuda_10.1.243_426.00_win10.exe,双击一直下一步安装即可, 默认安装路径为C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1。

2.4 安装cuDNN-深度学习GPU加速库
-
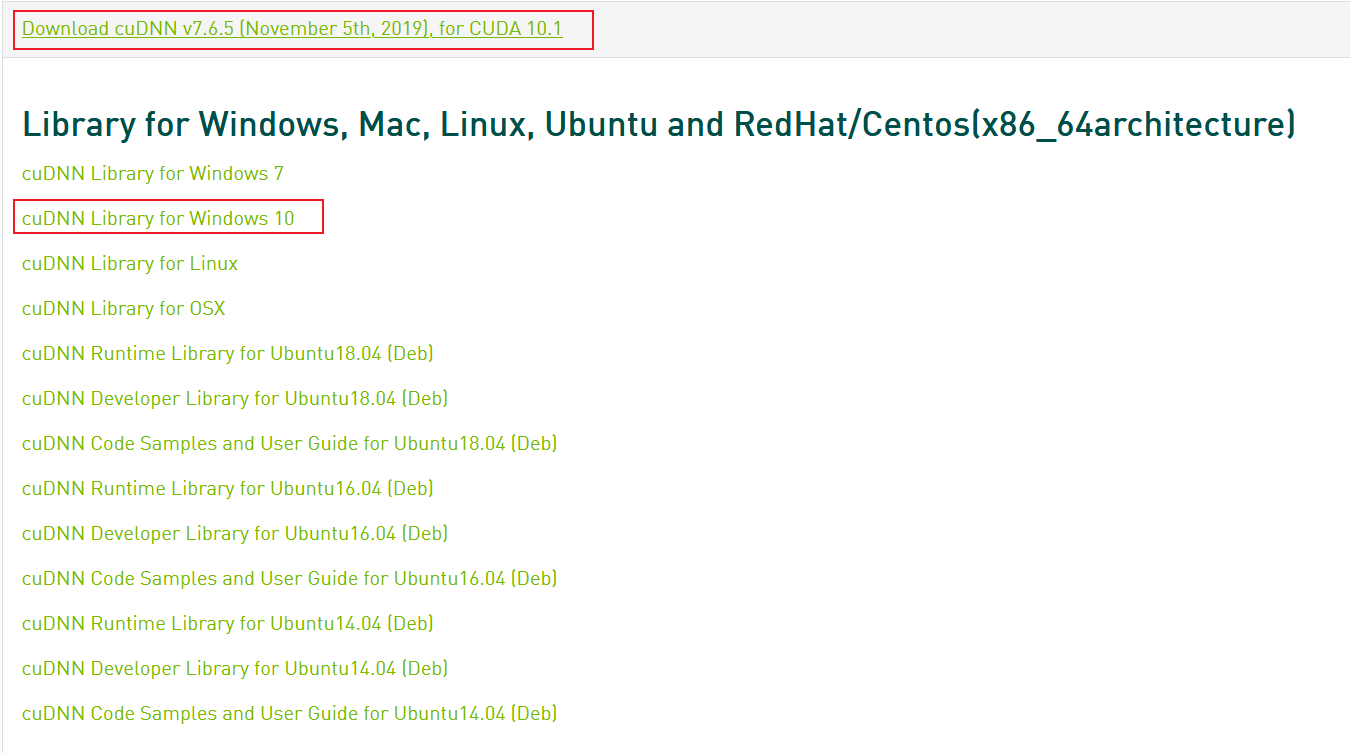
cuDNN下载地址(需要注册)
-
cuDNN版本的选择
以tensorflow常见cuda和cuDNN搭配为主。
下载的cuda版本为10.1版本,从列表中查找支持cuda10.1的最新的cuDNN版本是cuDNN7.6.5,下载后的cuDNN文件为cudnn-10.1-windows10-x64-v7.6.5.32.zip -
安装cuDNN
- 将下载的cudnn-10.1-windows10-x64-v7.6.5.32.zip解压,然后将解压后cuda文件夹下的文件或文件夹,完全拷贝到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1目录下即可。
- 将下载的cudnn-10.1-windows10-x64-v7.6.5.32.zip解压,然后将解压后cuda文件夹下的文件或文件夹,完全拷贝到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1目录下即可。

2.5 测试GPU环境
- 命令提示行输入
nvidia-smi查询GPU使用情况和更改GPU状态的功能
PS C:\Users\zhoushimin> nvidia-smi
Mon Apr 04 22:00:37 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 426.00 Driver Version: 426.00 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GT 650M WDDM | 00000000:01:00.0 N/A | N/A |
| N/A 36C P0 N/A / N/A | 40MiB / 2048MiB | N/A Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 Not Supported |
+-----------------------------------------------------------------------------+
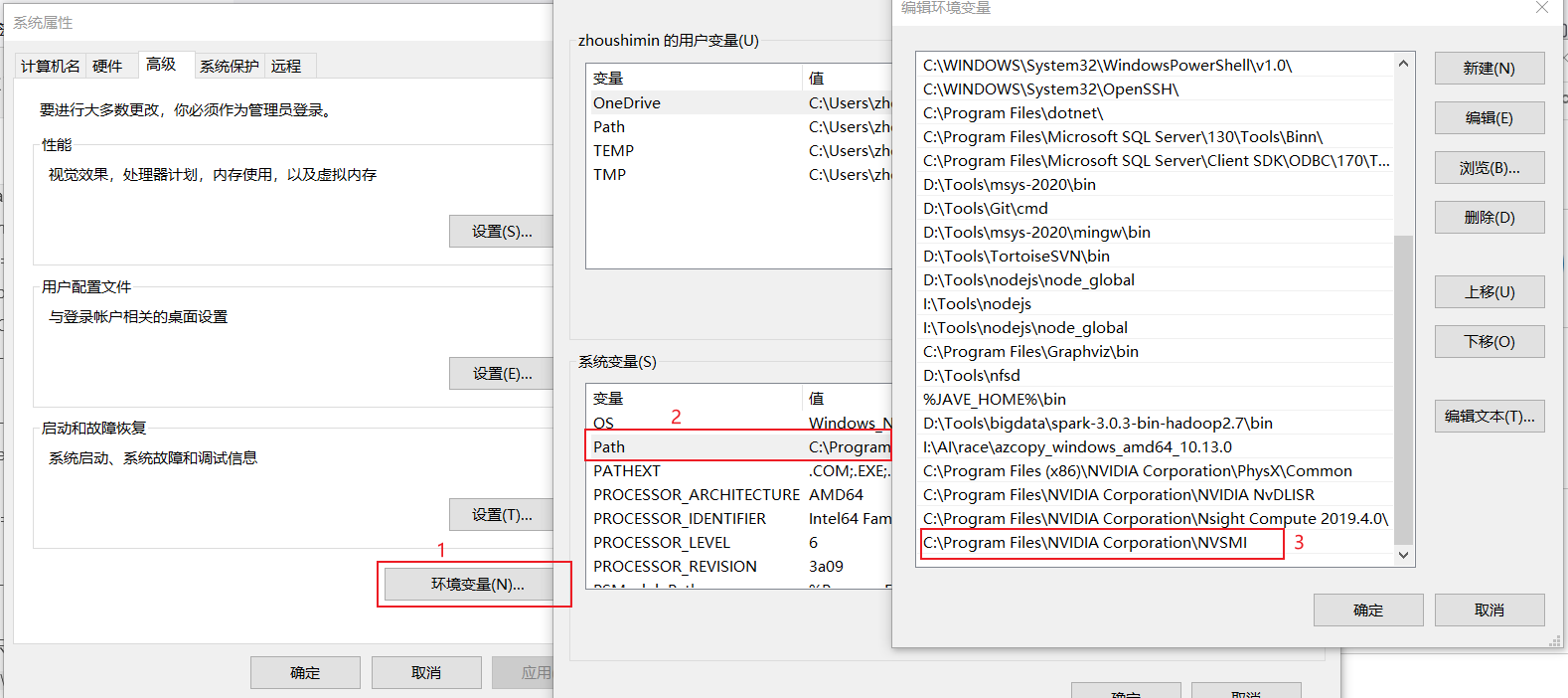
如果提示’nvidia-smi’ 不是内部或外部命令,也不是可运行的程序,则可能环境变量没有配置好,需要将 C:\Program Files\NVIDIA Corporation\NVSMI 目录添加到系统环境变量中关闭命令提示符,重新打开输入 nvidia-smi 就可以看到上面的输出结果了。
- 查看cuda版本
输入nvcc -V查看cuda版本
PS C:\Users\zhoushimin> nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2019 NVIDIA Corporation
Built on Sun_Jul_28_19:12:52_Pacific_Daylight_Time_2019
Cuda compilation tools, release 10.1, V10.1.243
可以看到cuda版本为10.1
- 查看cuDNN版本
输入如下命令查看
type "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\include\cudnn.h" | less
按回车键,直到输出结果如下:
#ifndef CUDNN_VERSION_H_
#define CUDNN_VERSION_H_
#define CUDNN_MAJOR 7
#define CUDNN_MINOR 6
#define CUDNN_PATCHLEVEL 5
#define CUDNN_VERSION (CUDNN_MAJOR * 1000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL)
#endif /* CUDNN_VERSION_H */
可知cuDNN的版本为7.6.5
如果找不到相关信息,可以使用如下命令测试
type "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\include\cudnn_version.h" | less
3. 安装Anaconda
3.1 概述
Anaconda,中文大蟒蛇,是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。其简化了python软件包的安装,并且自动关联依赖,自动下载依赖的软件包,避免不必要的冲突,另外,anaconda最重要的功能就是创建虚拟环境,实现各种项目开发框架及版本的隔离。
3.2 下载anaconda
Anaconda的官方下载速度较慢,推荐使用清华大学的源下载,尽量选择日期较新的版本,根据操作系统版本选择对应的版本。
- 官方下载地址:https://www.anaconda.com/
- 国内下载地址:
3.3 安装Anaconda
注意事项:不要有中文路径,安装过程无脑下一步即可。
安装完毕之后,python、pip等软件均已安装完毕。
3.4 测试Anaconda
在命令提示符输入conda -V查看conda版本,以确认conda环境是否生效。
PS C:\Users\zhoushimin> conda -V
conda 4.10.3
3.5 配置Anaconda
由于Anaconda官方服务器在国外,安装python软件包时下载速度巨慢,因此需要配置国内安装源,在这里使用清华大学的第三方源。
-
首先找到配置文件【.condarc】,其在C盘用户目录下,如图:
如果不存在,则直接创建即可。 -
打开文件后,将以下内容拷贝到文件中
 如果不存在,则直接创建即可。
如果不存在,则直接创建即可。channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch-lts: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
- 清除索引缓存
在命令行执行命令
conda clean -i
- 建立虚拟环境测试下载速度
conda create -n myenv numpy
测试时会发现下载包的速度杠杠的,测试完毕后,删除myenv虚拟环境
conda remove -n myenv --all
- 恢复官方安装源
如果使用第三方源出现问题,可以恢复官方安装源重试,恢复指令如下:
conda config --remove-key channels
4. 配置pip国内安装源
使用pip安装软件包时,有些安装包下载速度特别慢,可以选择国内的安装源。
4.1 安装源列表
以下安装源可以选择:
# 清华大学
https://pypi.tuna.tsinghua.edu.cn/simple/
# 阿里云
http://mirrors.aliyun.com/pypi/simple/
# 中国科技大学
https://pypi.mirrors.ustc.edu.cn/simple
4.2 安装源的使用方式
4.2.1 临时使用
以安装tensorflow使用阿里云安装源为例,在-i后面指定安装源即可
pip install tensorflow_gpu==2.3 -i http://mirrors.aliyun.com/pypi/simple/
4.2.2 永久使用
做如下配置后,无需再使用-i选项
pip install pip -U #升级 pip 到最新的版本后进行配置:
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
4.2.3 恢复官方安装源
如果安装源出现异常,恢复官方安装源的方式如下:
pip config unset global.index-url`
5. 安装tensorflow
5.1 创建tensorflow虚拟环境
为了隔离不同项目可能对应的不同tensorflow版本或pytorch或python版本,强烈建议使用conda创建不同的虚拟环境以实现各种不同的开发环境的隔离。
我们需要根据开发框架、cuda版本等信息综合选择合适的开发环境,强烈不建议自行搭建开发环境适配开源框架,你会怀疑人生,时间周期可能是星期级别!
5.1.1 查看开源框架支持的python和tensorflow版本
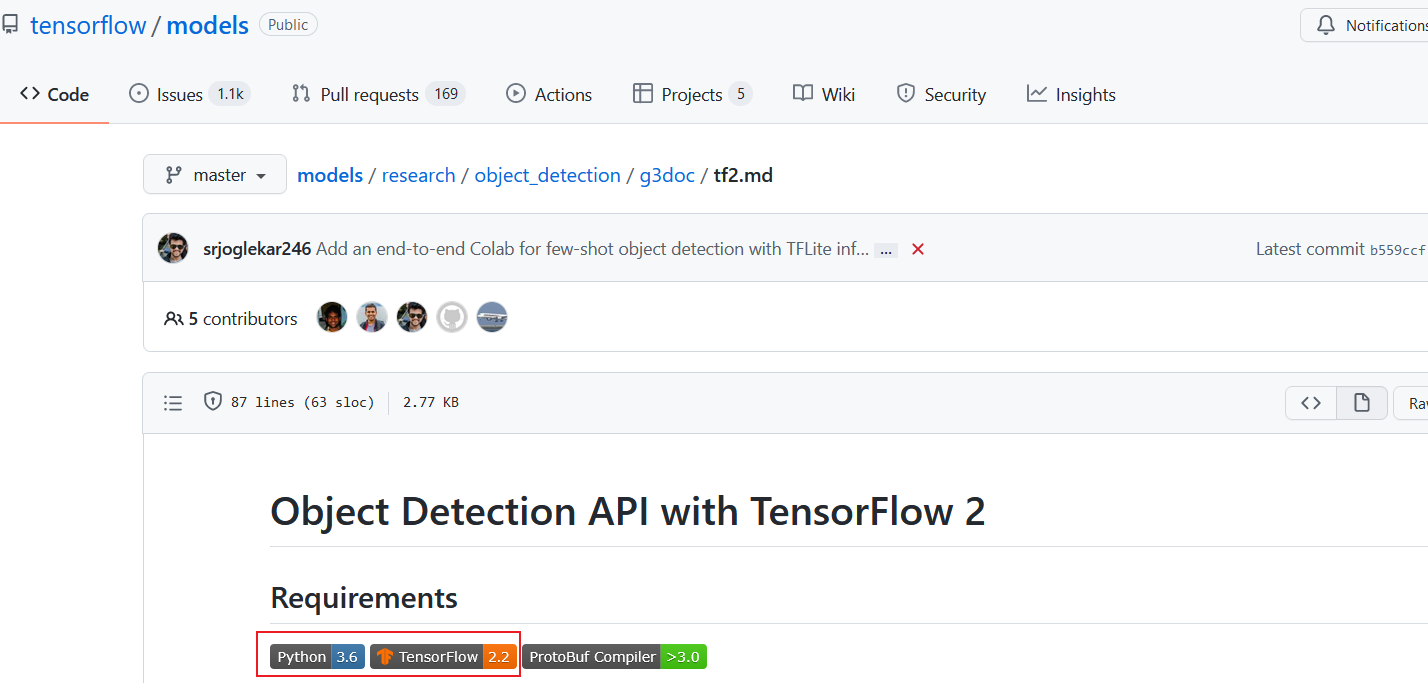
博主的需求是安装物体检测API[OBJECT DETECTION API],根据项目的最低配置可以了解到支持的是tensorflow-2.2 python3.6
5.1.2 查看cuda可支持的tensorflow版本
- 查看cuda、tensorflow对照关系表
- [经过测试的构建配置](https://tensorflow.google.cn/install/source?hl=zh-cn#gpu)

5.1.3 根据开源框架支持的tensorflow版本、cuda版本,选择tensorflow-2.2,python-3.6,根据这些信息创建虚拟环境
conda create -n [env_name] python=[python version]
详细命令如下:
conda create -n tensorflow-2.2-py36 python=3.6
输出如下:
PS C:\Users\zhoushimin> conda create -n tensorflow-2.2-py36 python=3.6
Collecting package metadata (repodata.json): done
Solving environment: done
==> WARNING: A newer version of conda exists. <==
current version: 4.10.3
latest version: 4.12.0
Please update conda by running
$ conda update -n base -c defaults conda
## Package Plan ##
environment location: D:\Tools\Anaconda3\envs\tensorflow-2.2-py36
added / updated specs:
- python=3.6
The following packages will be downloaded:
package | build
---------------------------|-----------------
certifi-2021.5.30 | py36haa95532_0 142 KB defaults
pip-21.2.2 | py36haa95532_0 2.1 MB defaults
python-3.6.13 | h3758d61_0 17.7 MB defaults
setuptools-58.0.4 | py36haa95532_0 976 KB defaults
wincertstore-0.2 | py36h7fe50ca_0 13 KB defaults
------------------------------------------------------------
Total: 20.9 MB
The following NEW packages will be INSTALLED:
certifi anaconda/pkgs/main/win-64::certifi-2021.5.30-py36haa95532_0
pip anaconda/pkgs/main/win-64::pip-21.2.2-py36haa95532_0
python anaconda/pkgs/main/win-64::python-3.6.13-h3758d61_0
setuptools anaconda/pkgs/main/win-64::setuptools-58.0.4-py36haa95532_0
sqlite anaconda/pkgs/main/win-64::sqlite-3.38.2-h2bbff1b_0
vc anaconda/pkgs/main/win-64::vc-14.2-h21ff451_1
vs2015_runtime anaconda/pkgs/main/win-64::vs2015_runtime-14.27.29016-h5e58377_2
wheel anaconda/pkgs/main/noarch::wheel-0.37.1-pyhd3eb1b0_0
wincertstore anaconda/pkgs/main/win-64::wincertstore-0.2-py36h7fe50ca_0
Proceed ([y]/n)? y
等待执行完毕。
5.2 切换至虚拟环境,安装tensorflow
- 切换至虚拟环境
conda activate tensorflow-2.2-py36
- 安装tensorflow
pip install tensorflow==2.2.0
- 安装完毕后的输出如下
Successfully built termcolor
Installing collected packages: urllib3, pyasn1, idna, charset-normalizer, zipp, typing-extensions, six, rsa, requests, pyasn1-modules, oauthlib, cachetools, requests-oauthlib, importlib-metadata, google-auth, dataclasses, werkzeug, tensorboard-plugin-wit, protobuf, numpy, markdown, grpcio, google-auth-oauthlib, absl-py, wrapt, termcolor, tensorflow-estimator, tensorboard, scipy, opt-einsum, keras-preprocessing, h5py, google-pasta, gast, astunparse, tensorflow
Successfully installed absl-py-1.0.0 astunparse-1.6.3 cachetools-4.2.4 charset-normalizer-2.0.12 dataclasses-0.8 gast-0.3.3 google-auth-1.35.0 google-auth-oauthlib-0.4.6 google-pasta-0.2.0 grpcio-1.44.0 h5py-2.10.0 idna-3.3 importlib-metadata-4.8.3 keras-preprocessing-1.1.2 markdown-3.3.6 numpy-1.19.5 oauthlib-3.2.0 opt-einsum-3.3.0 protobuf-3.19.4 pyasn1-0.4.8 pyasn1-modules-0.2.8 requests-2.27.1 requests-oauthlib-1.3.1 rsa-4.8 scipy-1.4.1 six-1.16.0 tensorboard-2.2.2 tensorboard-plugin-wit-1.8.1 tensorflow-2.2.0 tensorflow-estimator-2.2.0 termcolor-1.1.0 typing-extensions-4.1.1 urllib3-1.26.9 werkzeug-2.0.3 wrapt-1.14.0 zipp-3.6.0
5.3 测试tensorflow gpu环境
创建gpu_tf_test.py,拷贝如下代码:
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD
import time
# config = tf.ConfigProto()
# config.gpu_options.allow_growth = True
# session = tf.Session(config=config)
# 启用GPU
from tensorflow.compat.v1 import ConfigProto# tf 2.x的写法
config =ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction=0.9
tf.compat.v1.Session(config=config)
# 构建数据集
X_data = np.linspace(-1,1,1000)[:, np.newaxis]
noise = np.random.normal(0,0.05,X_data.shape)
y_data = np.square(X_data) + noise + 0.5
print("shape")
print(X_data.shape)
# 构建神经网络
model = Sequential()
model.add(Dense(10, input_shape=(1,), kernel_initializer='normal', activation='relu'))
#model.add(Dense(5, activation='relu'))
# vs 分类为softmax激活
model.add(Dense(10000, kernel_initializer='normal'))
model.add(Dense(10000, kernel_initializer='normal'))
model.add(Dense(100, kernel_initializer='normal'))
model.add(Dense(1, kernel_initializer='normal'))
#sgd = SGD(lr=0.001)
model.compile(loss='mean_squared_error', optimizer="sgd") #adam
# 训练 epoch = 10, 30, 50, view the results
start = time.time()
model.fit(X_data, y_data, epochs=50, batch_size=16, verbose=1)
end = time.time()
# 在原数据上预测
y_predict=model.predict(X_data)
#print(y_predict)
model.summary()
print("training time {}".format(end - start))
执行测试
# 切换至虚拟环境
conda activate tensorflow-2.2-py36
# 执行测试
python gpu_tf_test.py
输出如下:
(tensorflow-2.2-py36) C:\Users\zhoushimin\Desktop>python gpu_test.py
2022-04-05 00:24:35.790114: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
2022-04-05 00:24:39.180693: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x211ab3407a0 initialized for platform Host (this does not guarantee
that XLA will be used). Devices:
2022-04-05 00:24:39.181152: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version
2022-04-05 00:24:39.185023: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library nvcuda.dll
2022-04-05 00:24:39.957288: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1561] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: GeForce GT 650M computeCapability: 3.0
coreClock: 0.835GHz coreCount: 2 deviceMemorySize: 2.00GiB deviceMemoryBandwidth: 59.60GiB/s
2022-04-05 00:24:39.958038: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
2022-04-05 00:24:39.965471: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cublas64_10.dll
2022-04-05 00:24:39.972214: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cufft64_10.dll
2022-04-05 00:24:39.975560: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library curand64_10.dll
2022-04-05 00:24:39.985029: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cusolver64_10.dll
2022-04-05 00:24:39.989813: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cusparse64_10.dll
2022-04-05 00:24:40.014427: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudnn64_7.dll
2022-04-05 00:24:40.016214: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1657] Ignoring visible gpu device (device: 0, name: GeForce GT 650M, pci bus id: 0000:01:00.0, compute capability: 3.0) with Cuda compute capability 3.0. The minimum required Cuda capability is 3.5.
2022-04-05 00:24:40.063972: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1102] Device interconnect StreamExecutor with strength 1 edge matrix:
2022-04-05 00:24:40.064381: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1108] 0
2022-04-05 00:24:40.064707: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1121] 0: N
2022-04-05 00:24:40.068691: I tensorflow/compiler/xla/service/platform_util.cc:139] StreamExecutor cuda device (0) is of insufficient compute capability: 3.5 required, device is 3.0
2022-04-05 00:24:40.069704: I tensorflow/compiler/jit/xla_gpu_device.cc:161] Ignoring visible XLA_GPU_JIT device. Device number is 0, reason: Internal: no supported devices found for platform CUDA
shape
(1000, 1)
2022-04-05 00:24:40.099506: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1561] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: GeForce GT 650M computeCapability: 3.0
coreClock: 0.835GHz coreCount: 2 deviceMemorySize: 2.00GiB deviceMemoryBandwidth: 59.60GiB/s
2022-04-05 00:24:40.100197: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
2022-04-05 00:24:40.100541: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cublas64_10.dll
2022-04-05 00:24:40.100821: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cufft64_10.dll
2022-04-05 00:24:40.101140: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library curand64_10.dll
2022-04-05 00:24:40.101432: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cusolver64_10.dll
2022-04-05 00:24:40.101674: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cusparse64_10.dll
2022-04-05 00:24:40.101915: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudnn64_7.dll
2022-04-05 00:24:40.103257: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1657] Ignoring visible gpu device (device: 0, name: GeForce GT 650M, pci bus id: 0000:01:00.0, compute capability: 3.0) with Cuda compute capability 3.0. The minimum required Cuda capability is 3.5.
2022-04-05 00:24:40.104045: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1102] Device interconnect StreamExecutor with strength 1 edge matrix:
2022-04-05 00:24:40.104239: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1108]
2022-04-05 00:24:40.139180: W tensorflow/core/framework/cpu_allocator_impl.cc:81] Allocation of 400000000 exceeds 10% of free system memory.
2022-04-05 00:24:41.717374: W tensorflow/core/framework/cpu_allocator_impl.cc:81] Allocation of 400000000 exceeds 10% of free system memory.
2022-04-05 00:24:41.799759: W tensorflow/core/framework/cpu_allocator_impl.cc:81] Allocation of 400000000 exceeds 10% of free system memory.
Epoch 1/50
2022-04-05 00:24:42.666531: W tensorflow/core/framework/cpu_allocator_impl.cc:81] Allocation of 400000000 exceeds 10% of free system memory.
2022-04-05 00:24:42.841301: W tensorflow/core/framework/cpu_allocator_impl.cc:81] Allocation of 400000000 exceeds 10% of free system memory.
63/63 [==============================] - 36s 567ms/step - loss: 0.2708
Epoch 2/50
63/63 [==============================] - 35s 559ms/step - loss: 0.0703
Epoch 3/50
63/63 [==============================] - 39s 614ms/step - loss: 0.0350
Epoch 4/50
63/63 [==============================] - 41s 643ms/step - loss: 0.0140
Epoch 5/50
63/63 [==============================] - 41s 650ms/step - loss: 0.0144
Epoch 6/50
30/63 [=============>................] - ETA: 21s - loss: 0.0091
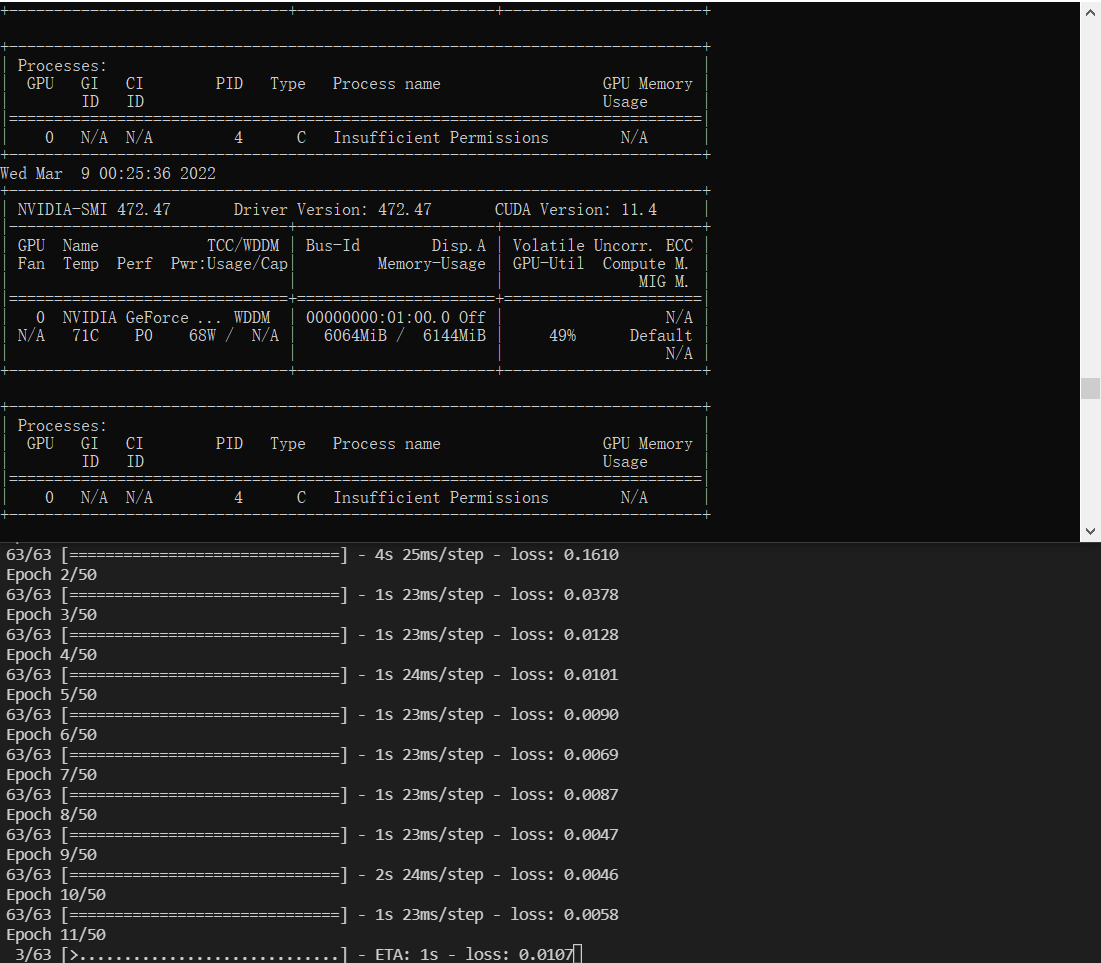
从日志中可以看到显卡GeForce GT 650M已经加载成功了,cuda也加载成功了,因为GPU性能较弱,仅3.0,不满足最小要求3.5,直接使用的cpu在运行。
6. 总结
总体来说,深度学习安装环境的安装还是比较麻烦的,涉及到
- 显卡支持的cuda版本确定
- 依赖新卡驱动版本号
- cuDNN版本的确认
- 依赖cuda版本和开发框架匹配的cuDNN版本
- python版本的确认等
- 依赖开源项目支持的版本
一般来说,一个项目一个环境,避免环境冲突。一个项目一个环境可以通过anaconda来实现,也可以使用docker来实现隔离。有一些框架在windows平台支持不好,例如目标检测框架MMDetection,尽可能还是使用linux环境来做开发。
以上是我的学习总结,有问题欢迎交流。
参考链接:
推荐阅读:
- 物体检测快速入门系列(1)-Windows部署GPU深度学习开发环境
- 物体检测快速入门系列(2)-Windows部署Docker GPU深度学习开发环境
- 物体检测快速入门系列(3)-TensorFlow 2.x Object Detection API快速安装手册
- 物体检测快速入门系列(4)-基于Tensorflow2.x Object Detection API构建自定义物体检测器


- 点赞
- 收藏
- 关注作者
评论(0)