【Node.JS】buffer类缓冲区

【摘要】 【Node.JS】buffer类缓冲区
简介
node.js的开发语言就是js,
javascript语言自身只有字符串数据类型,没有二进制数据类型。
node.js有时会操作一些文件,或是tcp流之类的东西。
那么就必须要操作二进制数据,
因此,在node.js中,有一个buffer类,
他用来创建一个专门存放二进制数据的缓存区。
buffer类是随node.js安装的,直接引入就可以使用。
这些原始数据是存储在buffer类的实例中,一个buffer类就相当于是一个整数数组,他相当于是划出了一块自己的内存空间。
buffer类的实例,用于表示编码字符的序列,支持utf-8,ascii等
创建Buffer类
Buffer.alloc,返回一个指定大小的Buffer实例,如果没有设置 fill,则默认填满 0。
const buf1 = Buffer.alloc(100);
//指定大小使用Buffer类
buf.write(string[, offset[, length]][, encoding])string - 写入缓冲区的字符串。
offset - 缓冲区开始写入的索引值,默认为 0 。
length - 写入的字节数,默认为 buffer.length
encoding - 使用的编码。默认为 'utf8' 。
const buf1 = Buffer.alloc(100);
var xx = buf1.write('坚毅的小解同志'); //返回的是字节数
console.log(buf1); //显示二进制字节占用情况
console.log('字节数' + xx);
console.log(buf1.toString());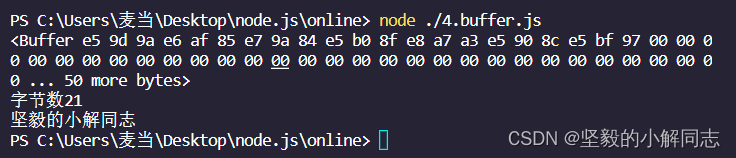
![]()
七个汉字,一共占有了21个字节,一个汉字占三个自己,在unicode编码格式中一个汉字占两个字节,在默认的utf-8中一个汉字占三个字节。我们可以通过toString这个方法来将二进制转化为字符串。
buffer类在实际应用中不多,当所修改的内容较为庞大的时候,我们可以采取这种二进制数组来修改内容,不会像replace产生新的数组。
例
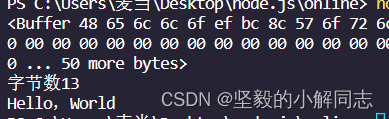
const buf1 = Buffer.alloc(100);
var xx = buf1.write('aello,World'); //返回的是字节数
buf1[0] = 72;
console.log(buf1); //显示二进制字节占用情况
console.log('字节数' + xx);通过二进制ASCII码来替换首字母。
![]()
中间的逗号是中文的逗号 所以一共13个字节。
直接使用buffer类
var xx = Buffer.from('aellow,World');
xx[0] = 72;
console.log(xx); //显示二进制字节占用情况
console.log(xx.toString());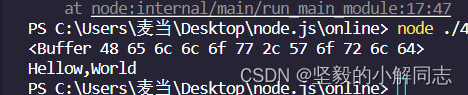
![]()

![]()

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)