搭建Skywalking分布式链路追踪与监控,并接入Java项目的教程

一、简介
Skywalking是一个国产的开源框架,2015年有吴晟个人开源,2017年加入Apache孵化器,国人开源的产品,主要开发人员来自于华为,2019年4月17日Apache董事会批准SkyWalking成为顶级项目,支持Java、.Net、NodeJs等探针,数据存储支持Mysql、Elasticsearch等,跟Pinpoint一样采用字节码注入的方式实现代码的无侵入,探针采集数据粒度粗,但性能表现优秀,且对云原生支持,目前增长势头强劲,社区活跃。
Skywalking是分布式系统的应用程序性能监视工具,专为微服务,云原生架构和基于容器(Docker,K8S,Mesos)架构而设计,它是一款优秀的APM(Application Performance Management)工具,包括了分布式追踪,性能指标分析和服务依赖分析等。

二、搭建教程
这边先采用windows的方式,在本地搭建。
1、官网下载包
官网地址:https://skywalking.apache.org/

主要有两种:一种是只支持Elasticsearch数据存储的,另一种支持多种数据存储的(如 H2、MySQL、TiDB、InfluxDB、ElasticSearch)。
我选用的是:v8.7.0 for H2/MySQL/TiDB/InfluxDB/ElasticSearch 7
2、压缩包解压
3、修改数据存储方式
配置文件位置在config/application.yml,如下图所示。
默认是H2,重启会丢失。我们可以根据需要,修改数据存储方式,大家熟悉MySQL多也可以用它,当然最为推荐的还是ElasticSearch,时序数据库性能要高很多。
storage:
selector: ${SW_STORAGE:h2}
elasticsearch:
nameSpace: ${SW_NAMESPACE:""}
clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:localhost:9200}
protocol: ${SW_STORAGE_ES_HTTP_PROTOCOL:"http"}
connectTimeout: ${SW_STORAGE_ES_CONNECT_TIMEOUT:500}
socketTimeout: ${SW_STORAGE_ES_SOCKET_TIMEOUT:30000}
user: ${SW_ES_USER:""}
password: ${SW_ES_PASSWORD:""}
trustStorePath: ${SW_STORAGE_ES_SSL_JKS_PATH:""}
trustStorePass: ${SW_STORAGE_ES_SSL_JKS_PASS:""}
secretsManagementFile: ${SW_ES_SECRETS_MANAGEMENT_FILE:""} # Secrets management file in the properties format includes the username, password, which are managed by 3rd party tool.
dayStep: ${SW_STORAGE_DAY_STEP:1} # Represent the number of days in the one minute/hour/day index.
indexShardsNumber: ${SW_STORAGE_ES_INDEX_SHARDS_NUMBER:1} # Shard number of new indexes
indexReplicasNumber: ${SW_STORAGE_ES_INDEX_REPLICAS_NUMBER:1} # Replicas number of new indexes
# Super data set has been defined in the codes, such as trace segments.The following 3 config would be improve es performance when storage super size data in es.
superDatasetDayStep: ${SW_SUPERDATASET_STORAGE_DAY_STEP:-1} # Represent the number of days in the super size dataset record index, the default value is the same as dayStep when the value is less than 0
superDatasetIndexShardsFactor: ${SW_STORAGE_ES_SUPER_DATASET_INDEX_SHARDS_FACTOR:5} # This factor provides more shards for the super data set, shards number = indexShardsNumber * superDatasetIndexShardsFactor. Also, this factor effects Zipkin and Jaeger traces.
superDatasetIndexReplicasNumber: ${SW_STORAGE_ES_SUPER_DATASET_INDEX_REPLICAS_NUMBER:0} # Represent the replicas number in the super size dataset record index, the default value is 0.
indexTemplateOrder: ${SW_STORAGE_ES_INDEX_TEMPLATE_ORDER:0} # the order of index template
bulkActions: ${SW_STORAGE_ES_BULK_ACTIONS:5000} # Execute the async bulk record data every ${SW_STORAGE_ES_BULK_ACTIONS} requests
# flush the bulk every 10 seconds whatever the number of requests
# INT(flushInterval * 2/3) would be used for index refresh period.
flushInterval: ${SW_STORAGE_ES_FLUSH_INTERVAL:15}
concurrentRequests: ${SW_STORAGE_ES_CONCURRENT_REQUESTS:2} # the number of concurrent requests
resultWindowMaxSize: ${SW_STORAGE_ES_QUERY_MAX_WINDOW_SIZE:10000}
metadataQueryMaxSize: ${SW_STORAGE_ES_QUERY_MAX_SIZE:5000}
segmentQueryMaxSize: ${SW_STORAGE_ES_QUERY_SEGMENT_SIZE:200}
profileTaskQueryMaxSize: ${SW_STORAGE_ES_QUERY_PROFILE_TASK_SIZE:200}
oapAnalyzer: ${SW_STORAGE_ES_OAP_ANALYZER:"{\"analyzer\":{\"oap_analyzer\":{\"type\":\"stop\"}}}"} # the oap analyzer.
oapLogAnalyzer: ${SW_STORAGE_ES_OAP_LOG_ANALYZER:"{\"analyzer\":{\"oap_log_analyzer\":{\"type\":\"standard\"}}}"} # the oap log analyzer. It could be customized by the ES analyzer configuration to support more language log formats, such as Chinese log, Japanese log and etc.
advanced: ${SW_STORAGE_ES_ADVANCED:""}
elasticsearch7:
nameSpace: ${SW_NAMESPACE:""}
clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:localhost:9200}
protocol: ${SW_STORAGE_ES_HTTP_PROTOCOL:"http"}
connectTimeout: ${SW_STORAGE_ES_CONNECT_TIMEOUT:500}
socketTimeout: ${SW_STORAGE_ES_SOCKET_TIMEOUT:30000}
trustStorePath: ${SW_STORAGE_ES_SSL_JKS_PATH:""}
trustStorePass: ${SW_STORAGE_ES_SSL_JKS_PASS:""}
dayStep: ${SW_STORAGE_DAY_STEP:1} # Represent the number of days in the one minute/hour/day index.
indexShardsNumber: ${SW_STORAGE_ES_INDEX_SHARDS_NUMBER:1} # Shard number of new indexes
indexReplicasNumber: ${SW_STORAGE_ES_INDEX_REPLICAS_NUMBER:1} # Replicas number of new indexes
# Super data set has been defined in the codes, such as trace segments.The following 3 config would be improve es performance when storage super size data in es.
superDatasetDayStep: ${SW_SUPERDATASET_STORAGE_DAY_STEP:-1} # Represent the number of days in the super size dataset record index, the default value is the same as dayStep when the value is less than 0
superDatasetIndexShardsFactor: ${SW_STORAGE_ES_SUPER_DATASET_INDEX_SHARDS_FACTOR:5} # This factor provides more shards for the super data set, shards number = indexShardsNumber * superDatasetIndexShardsFactor. Also, this factor effects Zipkin and Jaeger traces.
superDatasetIndexReplicasNumber: ${SW_STORAGE_ES_SUPER_DATASET_INDEX_REPLICAS_NUMBER:0} # Represent the replicas number in the super size dataset record index, the default value is 0.
indexTemplateOrder: ${SW_STORAGE_ES_INDEX_TEMPLATE_ORDER:0} # the order of index template
user: ${SW_ES_USER:""}
password: ${SW_ES_PASSWORD:""}
secretsManagementFile: ${SW_ES_SECRETS_MANAGEMENT_FILE:""} # Secrets management file in the properties format includes the username, password, which are managed by 3rd party tool.
bulkActions: ${SW_STORAGE_ES_BULK_ACTIONS:5000} # Execute the async bulk record data every ${SW_STORAGE_ES_BULK_ACTIONS} requests
# flush the bulk every 10 seconds whatever the number of requests
# INT(flushInterval * 2/3) would be used for index refresh period.
flushInterval: ${SW_STORAGE_ES_FLUSH_INTERVAL:15}
concurrentRequests: ${SW_STORAGE_ES_CONCURRENT_REQUESTS:2} # the number of concurrent requests
resultWindowMaxSize: ${SW_STORAGE_ES_QUERY_MAX_WINDOW_SIZE:10000}
metadataQueryMaxSize: ${SW_STORAGE_ES_QUERY_MAX_SIZE:5000}
segmentQueryMaxSize: ${SW_STORAGE_ES_QUERY_SEGMENT_SIZE:200}
profileTaskQueryMaxSize: ${SW_STORAGE_ES_QUERY_PROFILE_TASK_SIZE:200}
oapAnalyzer: ${SW_STORAGE_ES_OAP_ANALYZER:"{\"analyzer\":{\"oap_analyzer\":{\"type\":\"stop\"}}}"} # the oap analyzer.
oapLogAnalyzer: ${SW_STORAGE_ES_OAP_LOG_ANALYZER:"{\"analyzer\":{\"oap_log_analyzer\":{\"type\":\"standard\"}}}"} # the oap log analyzer. It could be customized by the ES analyzer configuration to support more language log formats, such as Chinese log, Japanese log and etc.
advanced: ${SW_STORAGE_ES_ADVANCED:""}
h2:
driver: ${SW_STORAGE_H2_DRIVER:org.h2.jdbcx.JdbcDataSource}
url: ${SW_STORAGE_H2_URL:jdbc:h2:mem:skywalking-oap-db;DB_CLOSE_DELAY=-1}
user: ${SW_STORAGE_H2_USER:sa}
metadataQueryMaxSize: ${SW_STORAGE_H2_QUERY_MAX_SIZE:5000}
maxSizeOfArrayColumn: ${SW_STORAGE_MAX_SIZE_OF_ARRAY_COLUMN:20}
numOfSearchableValuesPerTag: ${SW_STORAGE_NUM_OF_SEARCHABLE_VALUES_PER_TAG:2}
mysql:
properties:
jdbcUrl: ${SW_JDBC_URL:"jdbc:mysql://localhost:3306/swtest"}
dataSource.user: ${SW_DATA_SOURCE_USER:root}
dataSource.password: ${SW_DATA_SOURCE_PASSWORD:root}
dataSource.cachePrepStmts: ${SW_DATA_SOURCE_CACHE_PREP_STMTS:true}
dataSource.prepStmtCacheSize: ${SW_DATA_SOURCE_PREP_STMT_CACHE_SQL_SIZE:250}
dataSource.prepStmtCacheSqlLimit: ${SW_DATA_SOURCE_PREP_STMT_CACHE_SQL_LIMIT:2048}
dataSource.useServerPrepStmts: ${SW_DATA_SOURCE_USE_SERVER_PREP_STMTS:true}
metadataQueryMaxSize: ${SW_STORAGE_MYSQL_QUERY_MAX_SIZE:5000}
maxSizeOfArrayColumn: ${SW_STORAGE_MAX_SIZE_OF_ARRAY_COLUMN:20}
numOfSearchableValuesPerTag: ${SW_STORAGE_NUM_OF_SEARCHABLE_VALUES_PER_TAG:2}
tidb:
properties:
jdbcUrl: ${SW_JDBC_URL:"jdbc:mysql://localhost:4000/tidbswtest"}
dataSource.user: ${SW_DATA_SOURCE_USER:root}
dataSource.password: ${SW_DATA_SOURCE_PASSWORD:""}
dataSource.cachePrepStmts: ${SW_DATA_SOURCE_CACHE_PREP_STMTS:true}
dataSource.prepStmtCacheSize: ${SW_DATA_SOURCE_PREP_STMT_CACHE_SQL_SIZE:250}
dataSource.prepStmtCacheSqlLimit: ${SW_DATA_SOURCE_PREP_STMT_CACHE_SQL_LIMIT:2048}
dataSource.useServerPrepStmts: ${SW_DATA_SOURCE_USE_SERVER_PREP_STMTS:true}
dataSource.useAffectedRows: ${SW_DATA_SOURCE_USE_AFFECTED_ROWS:true}
metadataQueryMaxSize: ${SW_STORAGE_MYSQL_QUERY_MAX_SIZE:5000}
maxSizeOfArrayColumn: ${SW_STORAGE_MAX_SIZE_OF_ARRAY_COLUMN:20}
numOfSearchableValuesPerTag: ${SW_STORAGE_NUM_OF_SEARCHABLE_VALUES_PER_TAG:2}
influxdb:
# InfluxDB configuration
url: ${SW_STORAGE_INFLUXDB_URL:http://localhost:8086}
user: ${SW_STORAGE_INFLUXDB_USER:root}
password: ${SW_STORAGE_INFLUXDB_PASSWORD:}
database: ${SW_STORAGE_INFLUXDB_DATABASE:skywalking}
actions: ${SW_STORAGE_INFLUXDB_ACTIONS:1000} # the number of actions to collect
duration: ${SW_STORAGE_INFLUXDB_DURATION:1000} # the time to wait at most (milliseconds)
batchEnabled: ${SW_STORAGE_INFLUXDB_BATCH_ENABLED:true}
fetchTaskLogMaxSize: ${SW_STORAGE_INFLUXDB_FETCH_TASK_LOG_MAX_SIZE:5000} # the max number of fetch task log in a request
connectionResponseFormat: ${SW_STORAGE_INFLUXDB_CONNECTION_RESPONSE_FORMAT:MSGPACK} # the response format of connection to influxDB, cannot be anything but MSGPACK or JSON.
postgresql:
properties:
jdbcUrl: ${SW_JDBC_URL:"jdbc:postgresql://localhost:5432/skywalking"}
dataSource.user: ${SW_DATA_SOURCE_USER:postgres}
dataSource.password: ${SW_DATA_SOURCE_PASSWORD:123456}
dataSource.cachePrepStmts: ${SW_DATA_SOURCE_CACHE_PREP_STMTS:true}
dataSource.prepStmtCacheSize: ${SW_DATA_SOURCE_PREP_STMT_CACHE_SQL_SIZE:250}
dataSource.prepStmtCacheSqlLimit: ${SW_DATA_SOURCE_PREP_STMT_CACHE_SQL_LIMIT:2048}
dataSource.useServerPrepStmts: ${SW_DATA_SOURCE_USE_SERVER_PREP_STMTS:true}
metadataQueryMaxSize: ${SW_STORAGE_MYSQL_QUERY_MAX_SIZE:5000}
maxSizeOfArrayColumn: ${SW_STORAGE_MAX_SIZE_OF_ARRAY_COLUMN:20}
numOfSearchableValuesPerTag: ${SW_STORAGE_NUM_OF_SEARCHABLE_VALUES_PER_TAG:2}
zipkin-elasticsearch7:
nameSpace: ${SW_NAMESPACE:""}
clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:localhost:9200}
protocol: ${SW_STORAGE_ES_HTTP_PROTOCOL:"http"}
trustStorePath: ${SW_STORAGE_ES_SSL_JKS_PATH:""}
trustStorePass: ${SW_STORAGE_ES_SSL_JKS_PASS:""}
dayStep: ${SW_STORAGE_DAY_STEP:1} # Represent the number of days in the one minute/hour/day index.
indexShardsNumber: ${SW_STORAGE_ES_INDEX_SHARDS_NUMBER:1} # Shard number of new indexes
indexReplicasNumber: ${SW_STORAGE_ES_INDEX_REPLICAS_NUMBER:1} # Replicas number of new indexes
# Super data set has been defined in the codes, such as trace segments.The following 3 config would be improve es performance when storage super size data in es.
superDatasetDayStep: ${SW_SUPERDATASET_STORAGE_DAY_STEP:-1} # Represent the number of days in the super size dataset record index, the default value is the same as dayStep when the value is less than 0
superDatasetIndexShardsFactor: ${SW_STORAGE_ES_SUPER_DATASET_INDEX_SHARDS_FACTOR:5} # This factor provides more shards for the super data set, shards number = indexShardsNumber * superDatasetIndexShardsFactor. Also, this factor effects Zipkin and Jaeger traces.
superDatasetIndexReplicasNumber: ${SW_STORAGE_ES_SUPER_DATASET_INDEX_REPLICAS_NUMBER:0} # Represent the replicas number in the super size dataset record index, the default value is 0.
user: ${SW_ES_USER:""}
password: ${SW_ES_PASSWORD:""}
secretsManagementFile: ${SW_ES_SECRETS_MANAGEMENT_FILE:""} # Secrets management file in the properties format includes the username, password, which are managed by 3rd party tool.
bulkActions: ${SW_STORAGE_ES_BULK_ACTIONS:5000} # Execute the async bulk record data every ${SW_STORAGE_ES_BULK_ACTIONS} requests
# flush the bulk every 10 seconds whatever the number of requests
# INT(flushInterval * 2/3) would be used for index refresh period.
flushInterval: ${SW_STORAGE_ES_FLUSH_INTERVAL:15}
concurrentRequests: ${SW_STORAGE_ES_CONCURRENT_REQUESTS:2} # the number of concurrent requests
resultWindowMaxSize: ${SW_STORAGE_ES_QUERY_MAX_WINDOW_SIZE:10000}
metadataQueryMaxSize: ${SW_STORAGE_ES_QUERY_MAX_SIZE:5000}
segmentQueryMaxSize: ${SW_STORAGE_ES_QUERY_SEGMENT_SIZE:200}
profileTaskQueryMaxSize: ${SW_STORAGE_ES_QUERY_PROFILE_TASK_SIZE:200}
oapAnalyzer: ${SW_STORAGE_ES_OAP_ANALYZER:"{\"analyzer\":{\"oap_analyzer\":{\"type\":\"stop\"}}}"} # the oap analyzer.
oapLogAnalyzer: ${SW_STORAGE_ES_OAP_LOG_ANALYZER:"{\"analyzer\":{\"oap_log_analyzer\":{\"type\":\"standard\"}}}"} # the oap log analyzer. It could be customized by the ES analyzer configuration to support more language log formats, such as Chinese log, Japanese log and etc.
advanced: ${SW_STORAGE_ES_ADVANCED:""}
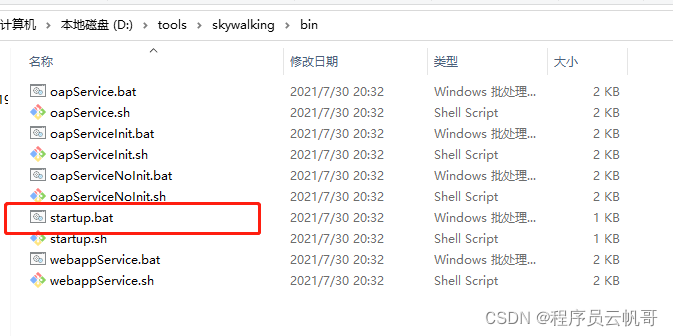
3、启动服务
启动位置在 bin/startup.bat。
查看Skywalking界面
http://localhost:8080/

三、Java项目接入Skywalking
1、启动参数配置
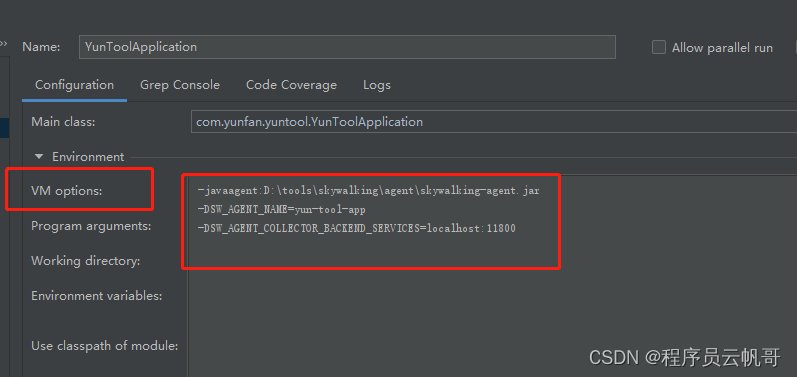
-javaagent:D:\tools\skywalking-8.7.0\agent\skywalking-agent.jar
-DSW_AGENT_NAME=yun-tool-app
-DSW_AGENT_COLLECTOR_BACKEND_SERVICES=localhost:11800
配置完,启动Java项目。
2、查看仪表盘
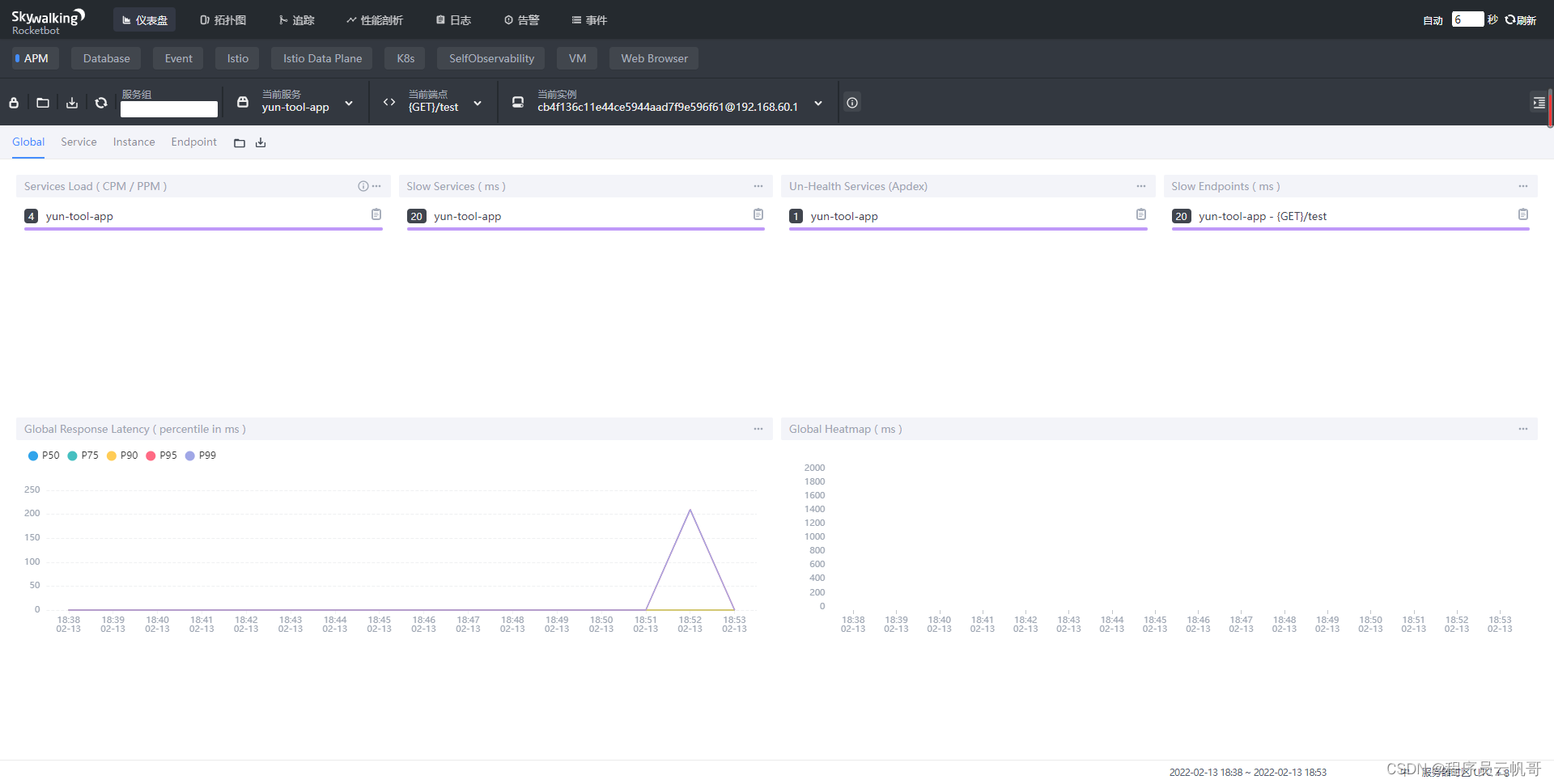
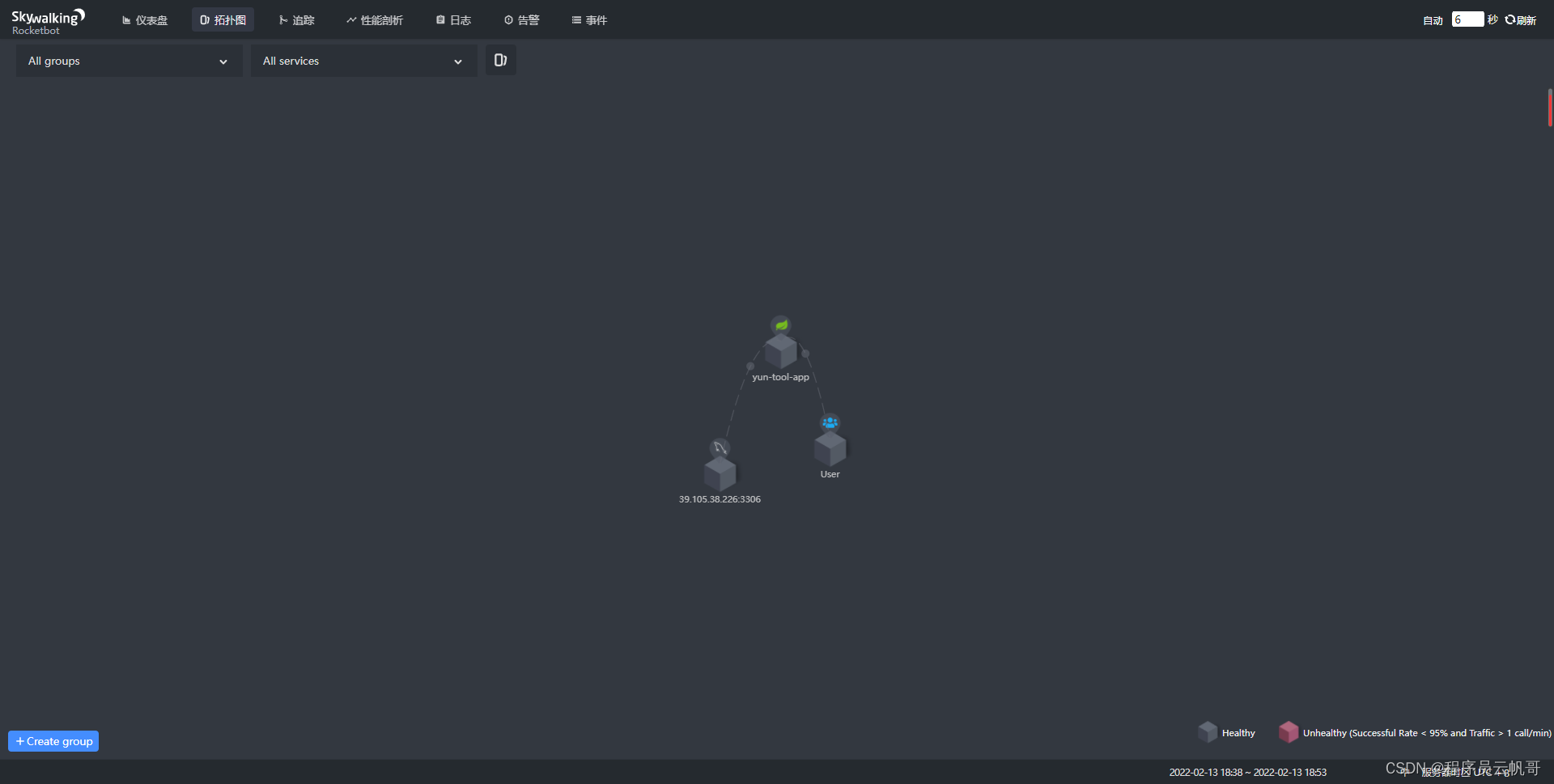
3、查看拓扑图
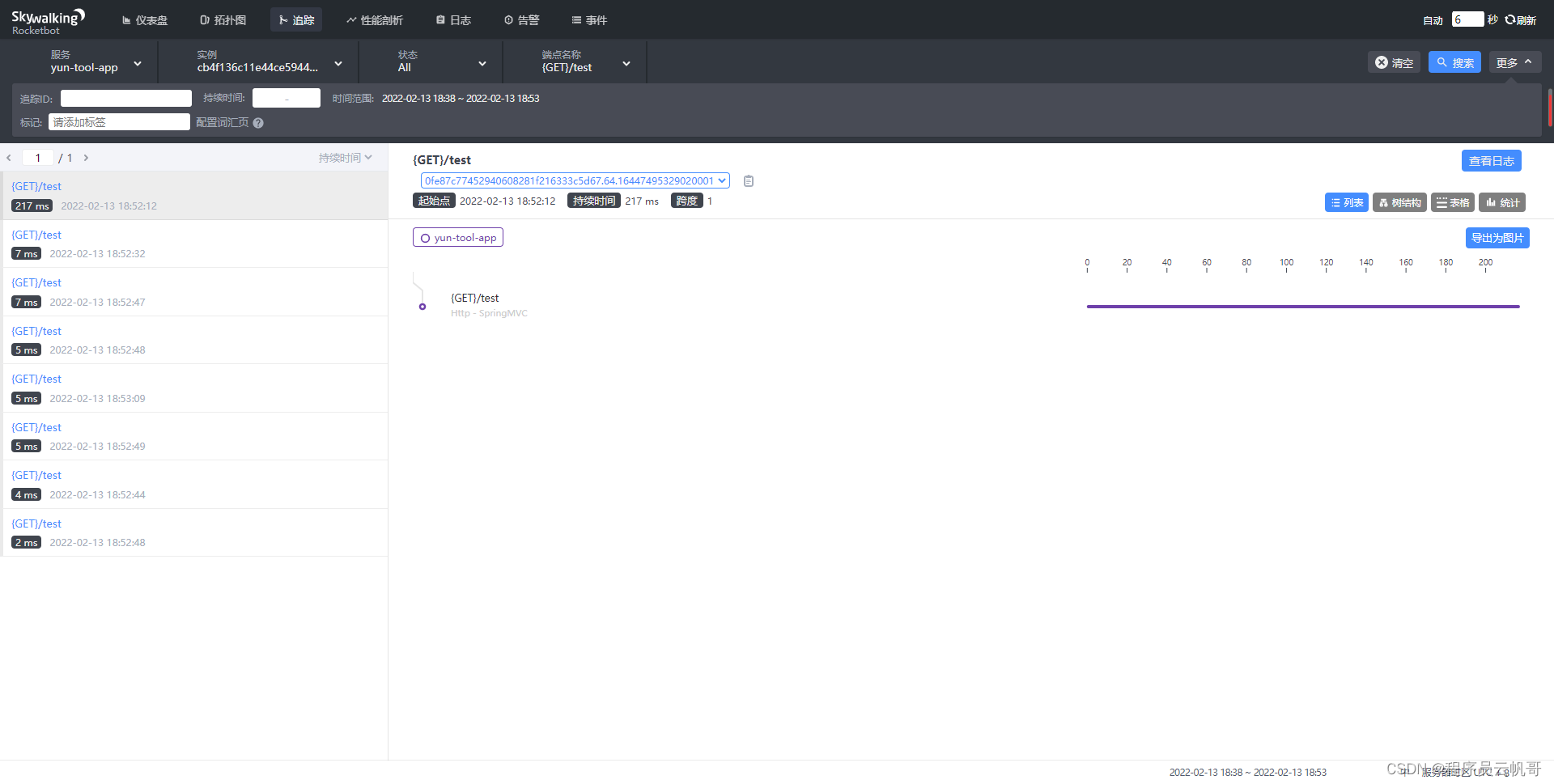
4、查看追踪面板
5、分布式日志管理
引入依赖
<dependency>
<groupId>org.apache.skywalking</groupId>
<artifactId>apm-toolkit-logback-1.x</artifactId>
<version>8.7.0</version>
</dependency>
修改logback配置文件
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.TraceIdPatternLogbackLayout">
<Pattern>${CONSOLE_LOG_PATTERN}</Pattern>
</layout>
</encoder>
</appender>
<appender name="grpc-log" class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.log.GRPCLogClientAppender">
<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.mdc.TraceIdMDCPatternLogbackLayout">
<Pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%X{tid}] [%thread] %-5level %logger{36} -%msg%n</Pattern>
</layout>
</encoder>
</appender>
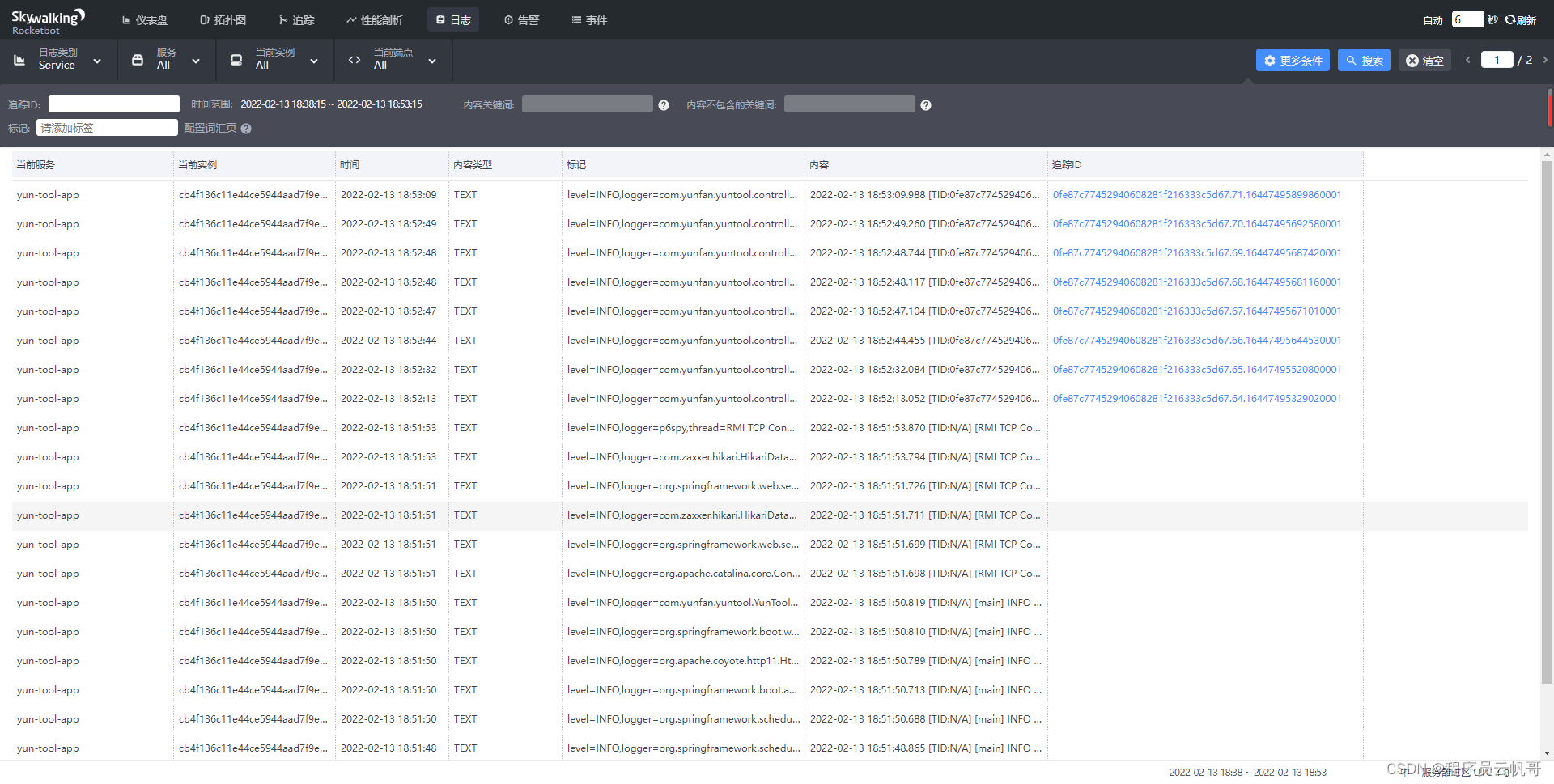
6、查看日志面板
调用接口时,控制台输出看到分布式链路id了

查看日志面板
点击日志中的分布式链路id,可以看到:

后续还将使用Skywalking的性能剖析功能和告警功能。

- 点赞
- 收藏
- 关注作者
评论(0)