2025-10-13:找到最常见的回答。用go语言,给你一个二维字符串数组 responses,数组中第 i 个子数组表示第 i

【摘要】 2025-10-13:找到最常见的回答。用go语言,给你一个二维字符串数组 responses,数组中第 i 个子数组表示第 i 天记录到的若干回答。先把每一天内部的重复回答去掉(同一天内相同答复只计为一次),然后在所有天数中统计每个答案被计入的总次数。返回出现次数最多的答案;如果有多个并列,选择字典序最小的那个。1 <= responses.length <= 1000。1 <= resp...
2025-10-13:找到最常见的回答。用go语言,给你一个二维字符串数组 responses,数组中第 i 个子数组表示第 i 天记录到的若干回答。
先把每一天内部的重复回答去掉(同一天内相同答复只计为一次),然后在所有天数中统计每个答案被计入的总次数。
返回出现次数最多的答案;如果有多个并列,选择字典序最小的那个。
1 <= responses.length <= 1000。
1 <= responses[i].length <= 1000。
1 <= responses[i][j].length <= 10。
responses[i][j] 仅由小写英文字母组成。
输入: responses = [[“good”,“ok”,“good”,“ok”],[“ok”,“bad”,“good”,“ok”,“ok”],[“good”],[“bad”]]。
输出: “good”。
解释:
每个列表去重后,得到 responses = [[“good”, “ok”], [“ok”, “bad”, “good”], [“good”], [“bad”]]。
“good” 出现了 3 次,“ok” 出现了 2 次,“bad” 也出现了 2 次。
返回 “good”,因为它出现的频率最高。
题目来自力扣3527。
根据你的代码和题目描述,整个过程可以分为以下几个步骤:
处理过程描述
-
初始化阶段:
- 创建三个关键变量:
maxCnt:记录当前遇到的最大出现次数,初始为0cnt:哈希表,记录每个答案在所有天数中的累计出现次数vis:哈希表,用于标记当前天内已经处理过的答案,避免同一天内重复计数
- 创建三个关键变量:
-
遍历每一天的回答数据:
- 外层循环遍历
responses数组中的每一天(每个子数组) - 对于每一天开始处理前,清空
vis哈希表,确保新的一天重新开始记录
- 外层循环遍历
-
处理单日内的回答去重:
- 内层循环遍历当前天内的所有回答
- 对于每个回答,先检查
vis哈希表:- 如果该回答已经在当天出现过,跳过不处理(实现同一天去重)
- 如果该回答是当天第一次出现,将其加入
vis哈希表标记为已访问
-
统计跨天出现次数:
- 对于当天首次出现的回答,在全局计数器
cnt中将其出现次数加1 - 同时获取该回答更新后的总出现次数
c
- 对于当天首次出现的回答,在全局计数器
-
实时更新最优答案:
- 在每次更新计数器后,立即检查当前回答是否应该成为新的最优答案:
- 如果当前回答的出现次数
c大于历史最大次数maxCnt,更新maxCnt和答案ans - 如果出现次数相等但字典序更小,也更新答案
ans
- 如果当前回答的出现次数
- 这种实时更新避免了后续需要再次遍历所有答案来寻找最优解
- 在每次更新计数器后,立即检查当前回答是否应该成为新的最优答案:
-
返回结果:
- 处理完所有天的所有回答后,直接返回最终确定的
ans
- 处理完所有天的所有回答后,直接返回最终确定的
复杂度分析
总的时间复杂度:O(N × M)
- 其中N是总天数(
responses.length) - M是平均每天的回答数量
- 每个回答只被处理一次,哈希表的操作都是O(1)时间复杂度
总的额外空间复杂度:O(K + D)
cnt哈希表:存储所有不同回答的出现次数,空间O(K),K是不同回答的总数vis哈希表:存储单天内出现的不同回答,空间O(D),D是单天内最多不同回答数- 由于每天处理完后
vis被清空复用,所以峰值空间是O(K + max(D))
在极端情况下,如果所有回答都不同,K可能达到N × M,但根据题目约束(回答长度≤10,总数据量有限),实际空间使用是可接受的。
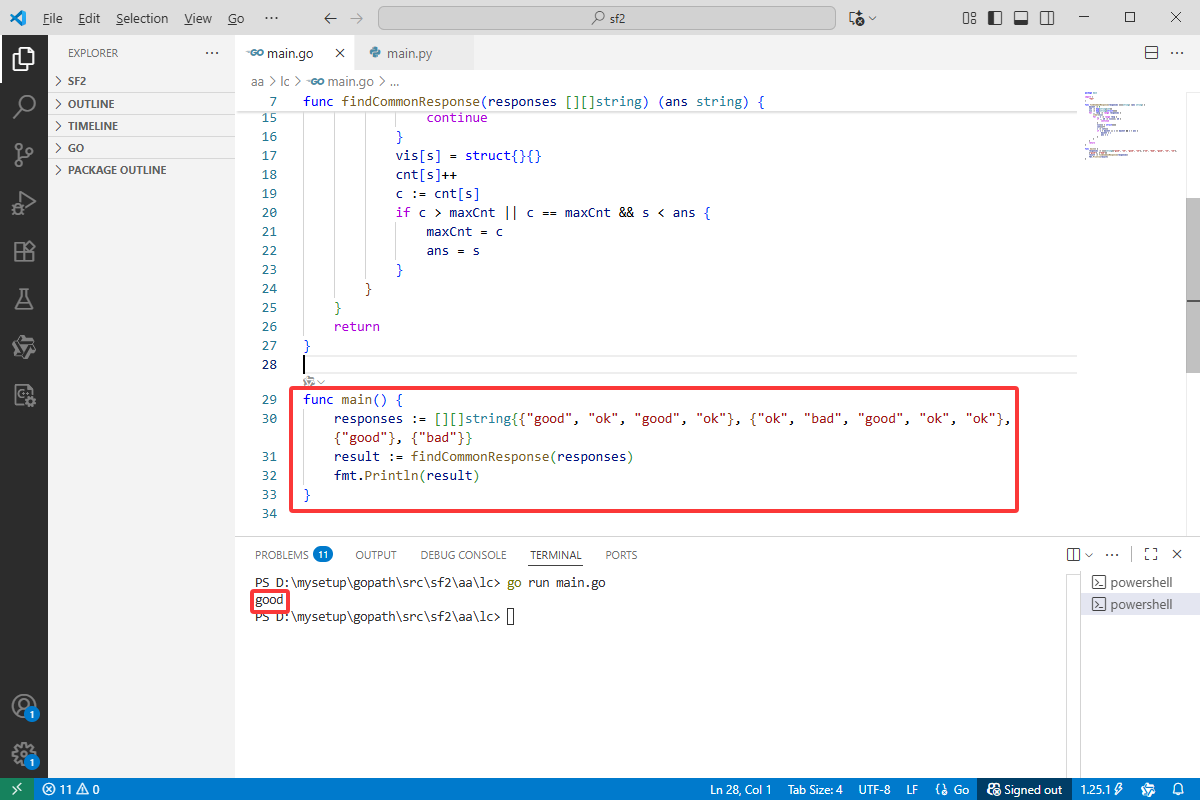
Go完整代码如下:
package main
import (
"fmt"
)
func findCommonResponse(responses [][]string) (ans string) {
maxCnt := 0
cnt := map[string]int{}
vis := map[string]struct{}{}
for _, resp := range responses {
clear(vis)
for _, s := range resp {
if _, ok := vis[s]; ok {
continue
}
vis[s] = struct{}{}
cnt[s]++
c := cnt[s]
if c > maxCnt || c == maxCnt && s < ans {
maxCnt = c
ans = s
}
}
}
return
}
func main() {
responses := [][]string{{"good", "ok", "good", "ok"}, {"ok", "bad", "good", "ok", "ok"}, {"good"}, {"bad"}}
result := findCommonResponse(responses)
fmt.Println(result)
}
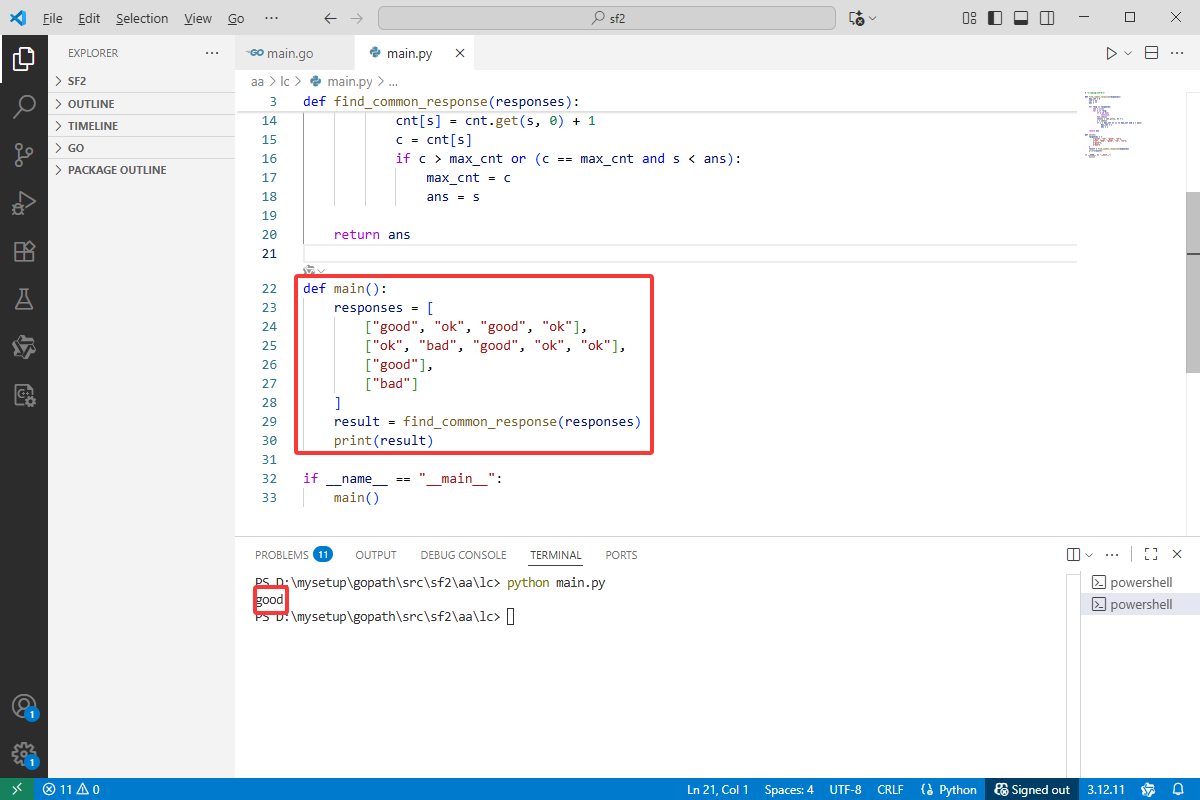
Python完整代码如下:
# -*-coding:utf-8-*-
def find_common_response(responses):
max_cnt = 0
cnt = {}
ans = ""
for resp in responses:
vis = set()
for s in resp:
if s in vis:
continue
vis.add(s)
cnt[s] = cnt.get(s, 0) + 1
c = cnt[s]
if c > max_cnt or (c == max_cnt and s < ans):
max_cnt = c
ans = s
return ans
def main():
responses = [
["good", "ok", "good", "ok"],
["ok", "bad", "good", "ok", "ok"],
["good"],
["bad"]
]
result = find_common_response(responses)
print(result)
if __name__ == "__main__":
main()

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)