flair适配昇腾开源验证任务心得

【摘要】 Flair 是一个开源的自然语言处理(NLP)框架,旨在为研究人员提供用于各种文本分析任务的灵活高效的工具集。Flair 的框架构建在 PyTorch 上,支持多种 NLP 常见应用场景,例如命名实体识别(NER)、情感分析、词性标记(PoS)、语义消歧和分类。
一、背景介绍
Flair 是一个开源的自然语言处理(NLP)框架,旨在为研究人员提供用于各种文本分析任务的灵活高效的工具集。Flair 的框架构建在 PyTorch 上,支持多种 NLP 常见应用场景,例如命名实体识别(NER)、情感分析、词性标记(PoS)、语义消歧和分类。本文将介绍在华为的Ascend NPU上配置 Flair 项目的过程中遇到的问题和解决方案,以及心得总结。
二、资源清单
Kunpeng CPU:
|
产品名称 |
CPU架构 |
实例类型 |
公共镜像 |
镜像版本 |
|
弹性云服务器 |
鲲鹏计算 |
鲲鹏通用计算增强型kc1.large.4 |
Huawei Cloud EulerOS |
Huawei Cloud EulerOS 2.0 64bit for kAi2p with HDK 23.0.1 and CANN 7.0.0.1 RC |
Ascend NPU:
|
产品名称 |
芯片类型 |
CANN版本 |
驱动版本 |
操作系统 |
|
堡垒机 |
昇腾910B3 |
CANN 7.0.1.5 |
23.0.6 |
Huawei Cloud EulerOS 2.0 |
三、遇到的问题和解决方案
具体步骤详见:https://blog.csdn.net/qq_54958500/article/details/142937355?spm=1001.2014.3001.5502
验证DEMO地址:https://gitcode.com/can_glan/opensource-demo-flair-241108/overview
1.环境搭建
问题1:依赖安装错误
- 描述:直接安装依赖时出现错误,提示 :AttributeError: 'LSTM' object has no attribute '_flat_weights'。
- 解决方案:修改 requirements.txt 文件中的 PyTorch 版本,将 torch>=1.5.0,!=1.8 改为 torch==1.11.0,然后重新安装依赖。
问题2:预训练模型下载失败
- 描述:直接运行示例代码时找不到预训练模型,提示 ValueError: Could not find any model with name 'ner'。
- 解决方案:手动下载预训练模型到本地文件夹 models,并修改代码中的模型加载路径。
问题3:Hugging Face 模型下载受限
- 描述:由于 Hugging Face 不支持国内访问,无法直接下载预训练模型。
- 解决方案:设置环境变量 HF_ENDPOINT 指向 Hugging Face 的国内镜像地址 https://hf-mirror.com,然后使用 huggingface-cli 下载模型。
2.使用昇腾 NPU
问题1:安装 NPU 版本的 PyTorch
- 描述:需要安装适用于 NPU 的 PyTorch 版本。
- 解决方案:下载并安装torch_npu :
wget https://gitee.com/ascend/pytorch/releases/download/v6.0.rc2.1-pytorch1.11.0/torch_npu-1.11.0.post15-cp39-cp39-linux_aarch64.whl pip install torch_npu-1.11.0.post15-cp39-cp39-linux_aarch64.whl
问题2:验证 NPU 环境
- 描述:需要验证 NPU 环境是否正常。
- 解决方案:编写测试脚本 test_npu.py 检查 NPU 是否可用:
import torch import torch_npu if torch.npu.is_available(): print("NPU is available.") device = torch.device('npu') tensor = torch.tensor([1.0, 2.0, 3.0], device=device) print(tensor) else: print("NPU is not available.")
问题3:Flair 框架适配 NPU
- 描述:直接将模型和句子.to("npu") 会导致错误。
- 解决方案:
- 修改代码,设置 flair.device 为 NPU:
import torch import flair if torch.npu.is_available(): print("NPU is available.") flair.device = torch.device('npu') else: print("NPU is not available.") flair.device = torch.device('cpu') - 如果运行时出现新的报错,设置环境变量 ASCEND_LAUNCH_BLOCKING=1:
export ASCEND_LAUNCH_BLOCKING=1 - 如果仍然报错,可能是缺少某些依赖,安装缺失的依赖:
pip install decorator
- 修改代码,设置 flair.device 为 NPU:
问题4:NPU运行优化
- 问题:模型较大,加载和推理速度较慢。
- 解决方案:
-
-
根据错误日志中的警告信息,启用 expandable_segments 功能采用一种更灵活的内存分配方式,允许在运行时动态地扩展内存段。
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True -
转换模型文件。
- 尝试将 .pt 文件转换为 .onnx 文件以优化 NPU 上的运行。
- 新建 export_onnx.py 文件进行 .pt 文件到 .onnx 文件的转换。
- 由于 .onnx 文件不包含运行时配置参数和字典信息,这些信息是模型运行和推理时必需的,因此需要提前准备一个文件用于保存原有模型的字典信息。
- 重写类代码。
- 新建 ner_model_npu.py 文件,在原有 SequenceTagger 基础上新建加载 .onnx 模型文件的类。
- 新建 verify_onnx.py 文件,对转换后的模型文件进行对比验证。
- 运行 run_ner_npu.py 文件,可以看到相比之前加载和推理用时都有所缩短。
-
四、验证结果
- DEMO内容:加载预训练模型,输入一句话,通过模型提取出其中的实体,通过gradio构建一个简单的Web应用界面展示效果。
Kunpeng CPU:

前端链接:http://113.44.138.39:7860/
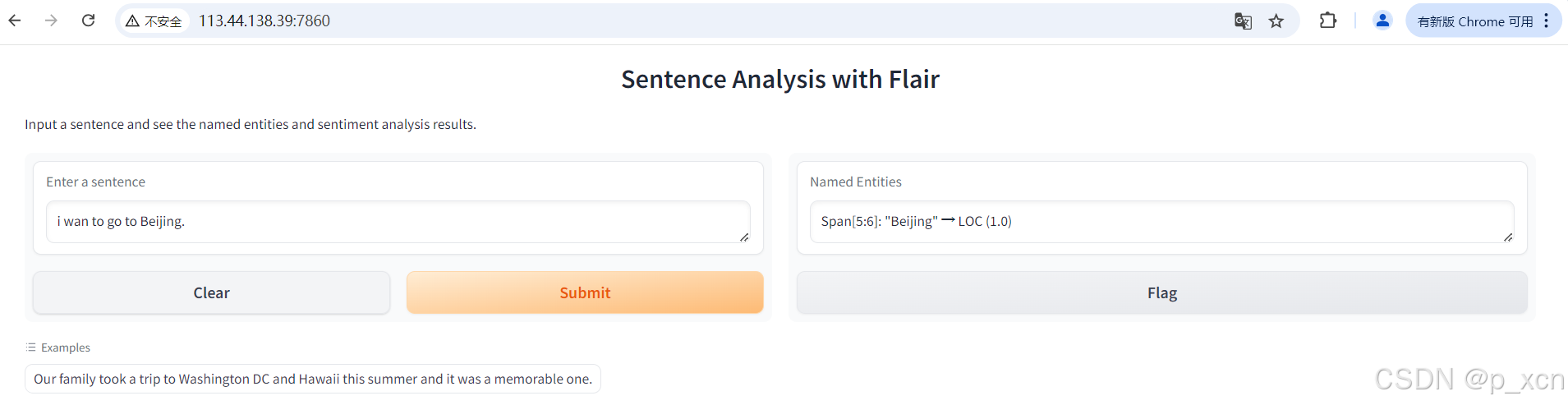
Ascend NPU:
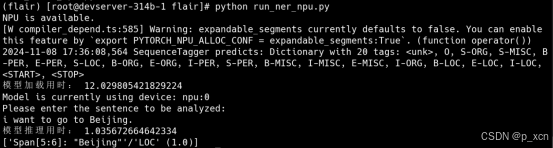
五、心得体会
- 环境配置的重要性:在适配开源项目到特定硬件和操作系统时,环境配置是关键。每个步骤都需要仔细检查和验证,确保所有依赖项正确安装和配置。
- 手动下载预训练模型:由于网络限制,有时需要手动下载预训练模型并修改加载路径。这虽然增加了工作量,但可以有效避免网络问题导致的失败。
- 使用国内镜像:对于无法直接访问的资源,使用国内镜像是一个有效的解决方案。这不仅可以加快下载速度,还能避免因网络问题导致的失败。
- NPU 适配的挑战:昇腾 NPU 的适配需要特别注意 PyTorch 版本和依赖项的兼容性。使用对应版本的Ascend torch_npu,通过修改源码和设置环境变量,可以解决大部分适配问题。
- 详细文档和社区支持:在适配过程中,详细阅读官方文档和社区讨论是非常有帮助的。有些问题已经有现成的解决方案,自己没办法解决的积极联系开发者或官方人员。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)