[Python自动化]selenium之网络课程自动化学习

这一专栏,将以目的为导向,以简化或自动化完成工作任务为目标,将Python运用于实践中,解决实际问题,以激发读者对这门脚本语言的学习兴趣。在开始Python自动化相关实战的学习前,建议对 Python语言本身 以及 Python 爬虫 的相关知识展开一定的学习与了解。对此博客已开设相关专栏,可直达。
关于对Python自动化的运用,此前的文章中也曾有过使用,对需求感兴趣的读者可以先行阅读,能够整体的了解到Python自动化在需求实现过程中扮演的角色和作用:
- 【Python实战】疫情期间每日健康报送任务的自动化处理
- 【Python实战】教务管理系统:成绩、课表查询接口设计及抢课、监控功能实现
这篇文章,将从Python自动化最基础的selenium实战展开,关于selenium的基础知识,可参见Python爬虫专栏下的文章:动态HTML处理之Selenium与PhantomJS
无论是作为学生在学校,还是作为打工人在职场,网课学习往往挤占了宝贵的休息时间,特别对于已经掌握的知识,出于形式化需求,需要刷满固定学时,这个时候,selenium可谓是低学习成本工具,以解近忧。
温馨提示:网课学习,请对自己负责,本文仅建议对于已掌握的网课采用自动化方式处理学习,不提倡也不建议恶意躲避网课学习,浪费学习资源,请配合并听从单位或部门要求,按时按量完成学习任务。
从自动化角度看,Selenium 类似于我们玩游戏用的按键精灵,可以按指定的命令自动操作网页,替代人工操作。采用Selenium实现网课学习的自动化,并非最为理想的实现方式,但确是门槛较低的自动化方式。文章将以一具体学习需求为例,手把手带读者入门Selenium实战,讲透在纯使用 Selenium 工具下,如何通过机器图像识别(验证码)、解决状态弹出框等事件。
网课学习基本步骤梳理:
- 登录账号
- 进入课程
- 学习完毕后进入下一课
- 全部学习完毕后退出
思路分析:
刷网课,首先需要明确网课地址,弄清账号和密码。在此基础上需要经过登陆、跳转、学习三个步骤,最终完成网课的学习任务。
一、基本依赖引入和环境设置
(1)基本依赖引入
import requests
import time
import urllib
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from urllib import request
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.action_chains import ActionChains
from selenium.common.exceptions import TimeoutException, WebDriverException
from datetime import datetime
from time import sleep
from datetime import datetime
(2)基本环境设置
明确网课登陆页面和学习页面
class_list = [
"https://www.******.cn/home/",
"https://*****.cn/portal/play.do?id=15010830"
]
弄清网课学习账号和密码
username = "***********"
pwd = "***********"
调用selenium浏览器
browser = webdriver.Firefox(executable_path='geckodriver')
wait = WebDriverWait(browser, 10, 0.5)
二、登陆
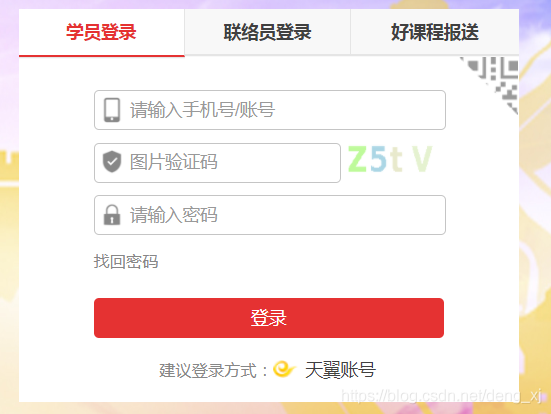
在本例中,登陆页面需要通过机器图像识别(验证码),对于这类一次性环节,为节省学习成本,这里采用手动输入的形式通过图像识别。
def Login():
print('***************正在加载必要元素,请耐心等待***************')
browser.get('https://www.******.cn/home/')
browser.find_element_by_xpath('//*[@id="accountFrom"]/label[1]/input').send_keys(username)
browser.find_element_by_xpath('//*[@id="accountFrom"]/label[3]/input').send_keys(pwd)
input("请输入验证码登陆后回车确认:")
账号密码框通过正则表达式定位后填充变量。
三、进入课程展开学习
在成功登陆账号后,课程学习的展开离不开课程的定位。定位课程的方法有二, 其一通过网页元素定位后跳转,其二直接通过browser.get方式跳转至课程url。元素定位因站制宜,本次实战采用第二种方式展开。
(1)进入课堂
进入学习平台后,一般而言首先需要进入课堂,再具体开始课程的学习。如若不进入课堂,直接通过browser.get方式跳转时常无法直接进入课程。
def First_Link_log():
browser.get('https://*****.cn/student/class_register.do?cid=90&type=1&url=learn')
print("进入课堂")
(2)明确需要自动化处理的课程url
一般而言,课程url有一定的规律所遵循,如有序url:
https://*****.com.cn/portal/play.do?id=15010830
https://*****.com.cn/portal/play.do?id=15010831
https://*****.com.cn/portal/play.do?id=15010832
https://*****.com.cn/portal/play.do?id=15010833
https://*****.com.cn/portal/play.do?id=15010834
https://*****.com.cn/portal/play.do?id=15010835
再如无序url:
https://*****.com.cn/portal/play.do?id=15010779
https://*****.com.cn/portal/play.do?id=15010784
https://*****.com.cn/portal/play.do?id=15010826
https://*****.com.cn/portal/play.do?id=15010828
https://*****.com.cn/portal/play.do?id=15010829
https://*****.com.cn/portal/play.do?id=15010831
(3)形成课程url列表
对于有序url:
def study():
number = 15010830 + i
list = "https://*****.com.cn/portal/play.do?id=" + str(number)
browser.get(list)
print("当前课程编号:", number)
对于无序url:
def study():
class_lists = [
'0779',
'0784'
'0826',
'0828',
'0829',
'0831'
]
number_list = '1501' + str(class_lists[i])
list_new = "https://*****.com.cn/portal/play.do?id=" + str(number_list)
browser.get(list_new)
print("当前课程编号:",number_list)
(4)课程验证
每次新课程的学习,首先需要通过弹出框的验证。关于如何定位弹窗中的弹窗元素,这里选用适用性最强的鼠标元素点击的方式处理。

def study():
sleep(5)
action = ActionChains(browser)
action.move_by_offset(600, 290).click().perform()
ActionChains(browser).move_by_offset(10, 10).context_click().perform() # 鼠标左键点击
(5)课程跳转
关于课程跳转,主要有两种思路。其一是统一时间跳转,其二是识别单个课程时长,时满后跳转。这里选用第一中方法。
def study():
#print('开始上课')
sleep(1800) #每堂课等待30分钟
print("课程学习完毕")
关于课程跳转方法,使用循环即可实现。
if __name__ == '__main__':
#experience()
Login()
First_Link_log()
i = 0
while i < 6: #根据总课程数决定
study()
i += 1
print('即将进入下一课')
else:
print("检测到任务已全部完成,等待确认后退出")
input()
至此,本文也就进入尾声了。本文的撰写来自于开发中的一点心得体会,主要目的在于通过实践提高读者Python学习兴趣,解决实际问题。供对这一领域感兴趣的读者以参考借鉴。希望本文能够起到抛砖引玉之效,也欢迎大家的批评交流。
如果您有任何疑问或者好的建议,期待你的留言、评论与关注!

- 点赞
- 收藏
- 关注作者
评论(0)