python数据分析基础001-利用pandas玩转excel表格(1)

🐚作者简介:苏凉(专注于网络爬虫,数据分析)
🐳博客主页:苏凉的博客
👑名言警句:海阔凭鱼跃,天高任鸟飞。
📰要是觉得博主文章写的不错的话,还望大家三连支持一下呀!!!
👉关注✨点赞👍收藏📂

🍺前言
在数据分析中我们可以利用pandas对excel表格进行操作,包括对excel的创建,修改和读取等等。接下来我们一起来学习如何利用pandas对excel表格操作吧!!
🍁(一)创建文件
平时我们创建excel文件时,通常是在文件夹内右击新建excel表格,在pandas中只需一行代码即可!!
注:excel表格的文件格式为.xlsx
运行时报错:No module named ‘openpyxl’
这是我们在使用openpyxl包时没有安装该模块!因此我们需要在控制台输入指令:
pip install openpyxl
此时问题就解决啦!!
import pandas as pd
df = pd.DataFrame()
df.to_excel('D:/Temp01/test.xlsx')
print('创建成功!!')
结果:
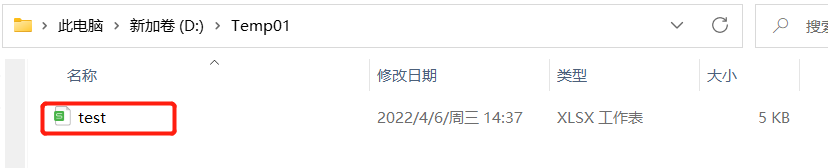
🍒1.在创建的表格内插入数据
只需将我们定义的数据传入Dataframe内即可:
import pandas as pd
numb_list = {
'ID':[1,2,3,4],
'name':['苏凉','jake','佚名','Tom'],
'age':[22,18,25,16],
'QQ_num':[787991021,2544722208,12545654,58456]
}
df = pd.DataFrame(numb_list)
df.to_excel('D:/Temp01/test.xlsx')
print('创建成功!!')
运行结果:
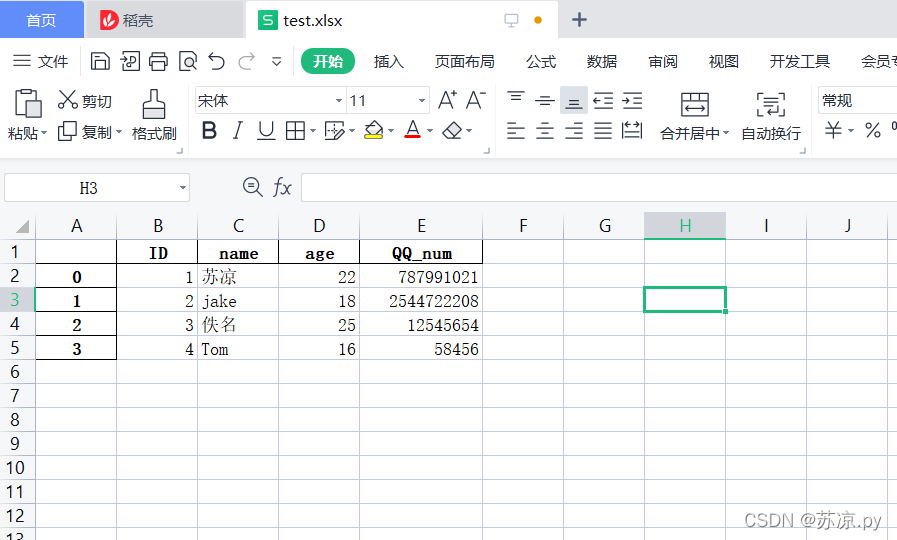
🍒2.修改索引
利用set_index设置索引
df = df.set_index('ID')
结果:
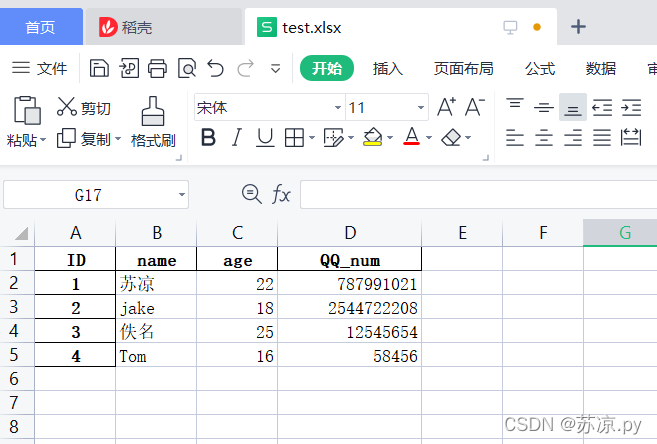
🍁(二)读取文件
🍒1.导入excel表格
people = pd.read_excel('./People.xlsx') #导入excel表格
🍒2.查看表格形状
print(people.shape) #查看有多少行多少列
🍒3.查看列名
x = people.columns
for i in x:
print(i)
结果:

✨3.1 当第一行为空或有其他数据


遇到上述两种情况在读取列名时,pandas默认第一行为列名,当第一行为空时则需要设置header=某行
import pandas as pd
people = pd.read_excel('./People.xlsx',header = 1)
print(people.columns)
✨3.2 自定义列名
当打开的文件没有列名时,我们需要设置列名。
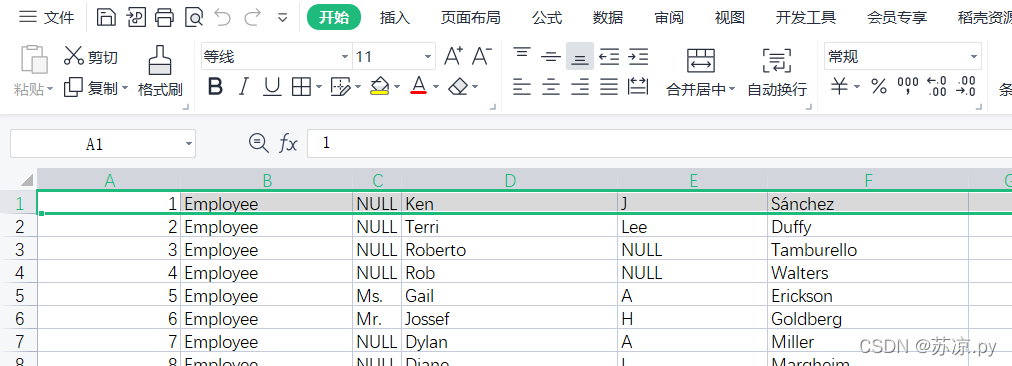
import pandas as pd
people = pd.read_excel('./People.xlsx',header=None)
# 自定义列名
people.columns=['ID','Type','Title','FirstName','MiddleName','LastName']
people.set_index('ID',inplace=True)
print(people.columns)
# 保存
people.to_excel('./test.xlsx')
print('save success')
结果:
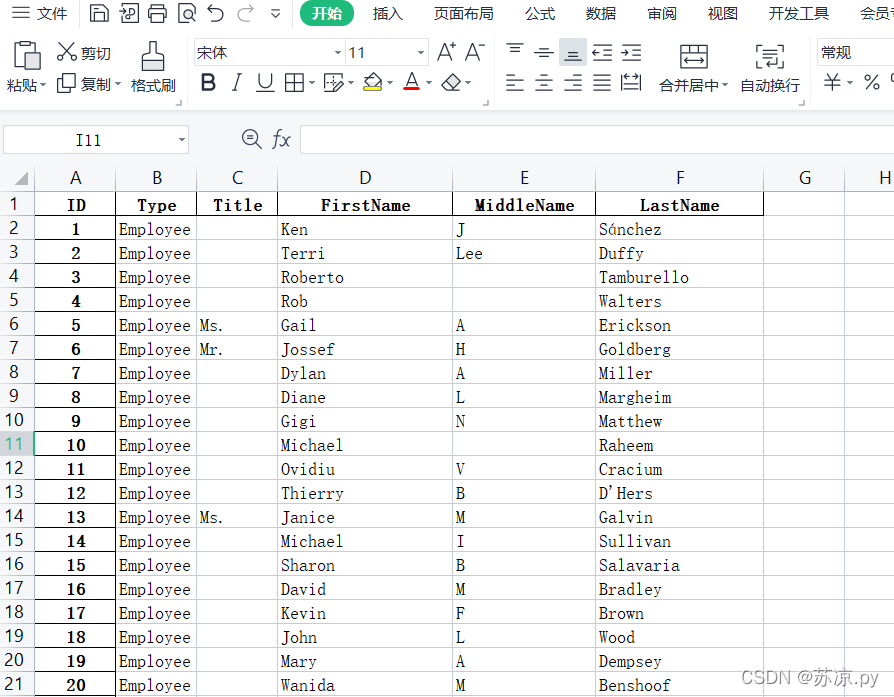
✨3.3 指定索引
在上面我们创建了一个test文件。当我们再次打开时,pandas会给我们重新创建一个索引,如下图:
这时我们需要指定索引
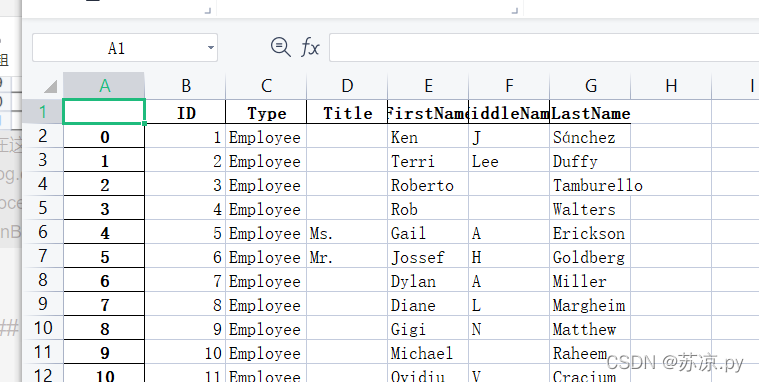
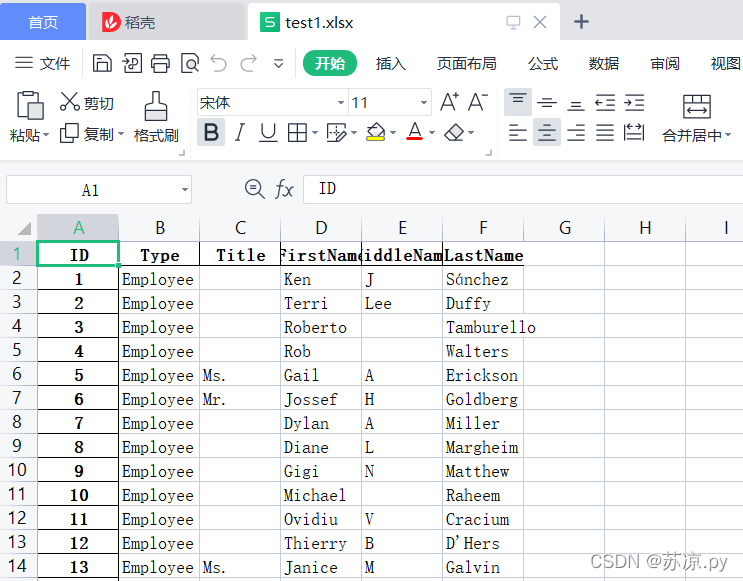
import pandas as pd
people = pd.read_excel('./test.xlsx',index_col="ID")
people.to_excel('./test1.xlsx')
print('save success')
结果:
🍒4.用Series创建行,列,单元格
import pandas as pd
d1 = pd.Series([10,20,30],index=[1,2,3],name='a')
d2 = pd.Series([40,50,60],index=[1,2,3],name='b')
d3 = pd.Series([100,200,300],index=[2,3,4],name='c')
df = pd.DataFrame({d1.name:d1,d2.name:d2,d3.name:d3})
df2 = pd.DataFrame([d1,d2,d3])
print(df)
print('*'*100)
print(df2)
结果:
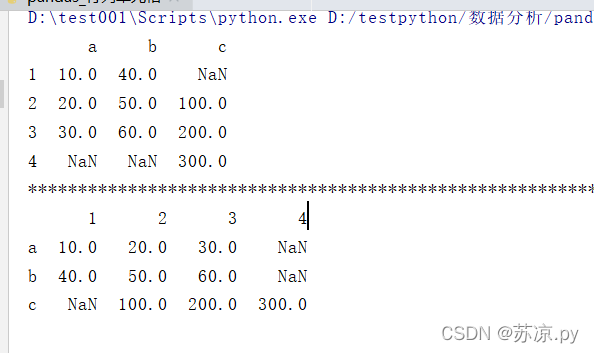
从上述结果可以看出通过Series创建的值传到Dataframe时需要用字典的形式,否则索引会自动转换为列。
🍒5.利用pandas实现excel自动填充
✨5.1 填充普通序列
实例:填充ID,InStore,Date
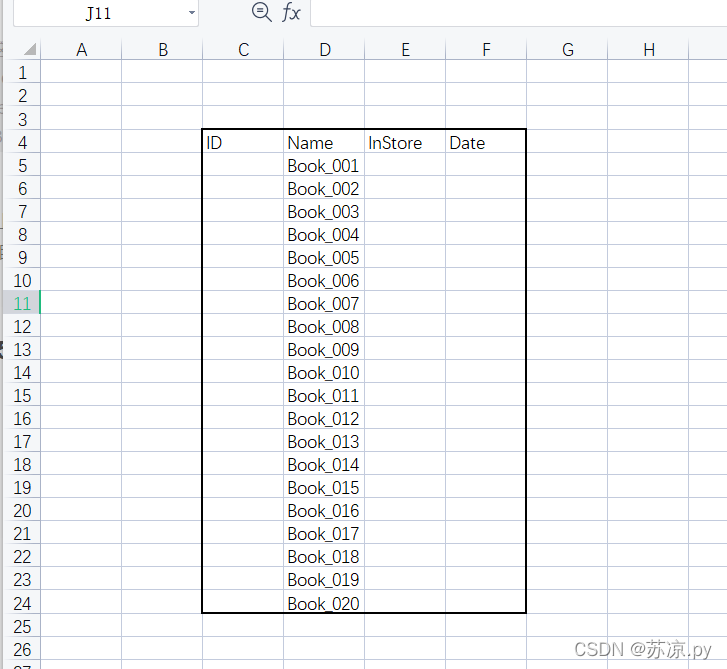
import pandas as pd
books = pd.read_excel('./Books.xlsx',skiprows=3,usecols='C:F',dtype={'ID':str})
df = pd.DataFrame(books)
for i in books.index:
# 对id自动填充
books['ID'].at[i] = i+1
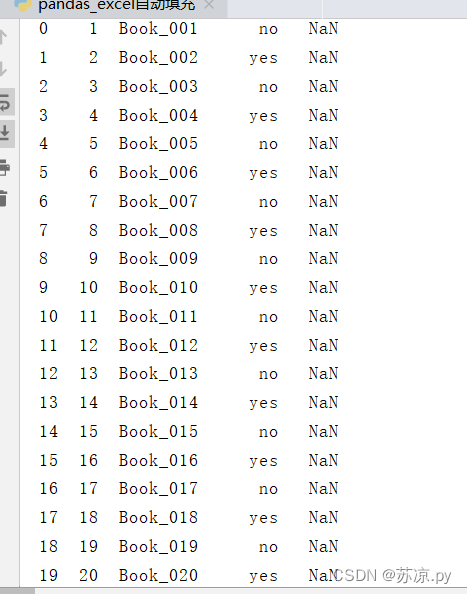
# 对Instore自动填充
books['InStore'].at[i] = 'no' if i%2==0 else 'yes'
print(books)
结果:
✨5.2 填充日期序列
填充日期序列时,我们需要事先从datetime中导入date,timedelda模块
from datetime import date,timedelta
设置初始日期
start_time = date(2019,1,25)
🎐5.2.1 填充日
books['Date'].at[i] = start_time + timedelta(days=i)
结果:
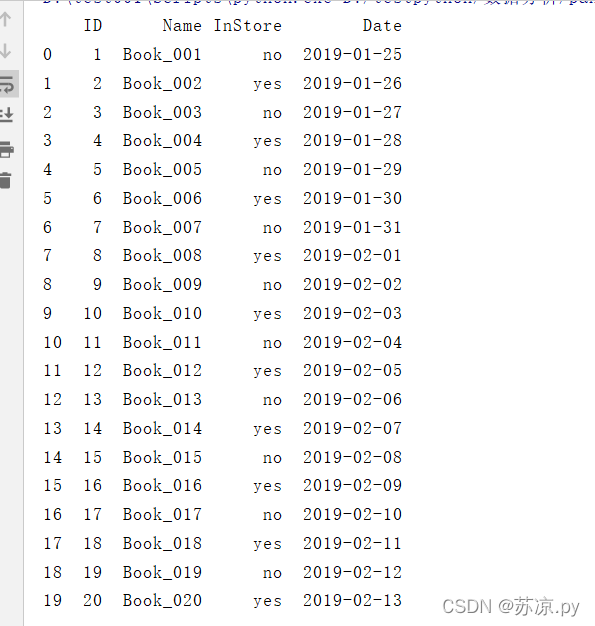
注:timedelda最多只能加到日期,无法加年以及月!!
🎐5.2.2 填充年
books['Date'].at[i] = date(start_time.year+i,start_time.month,start_time.day)
结果:

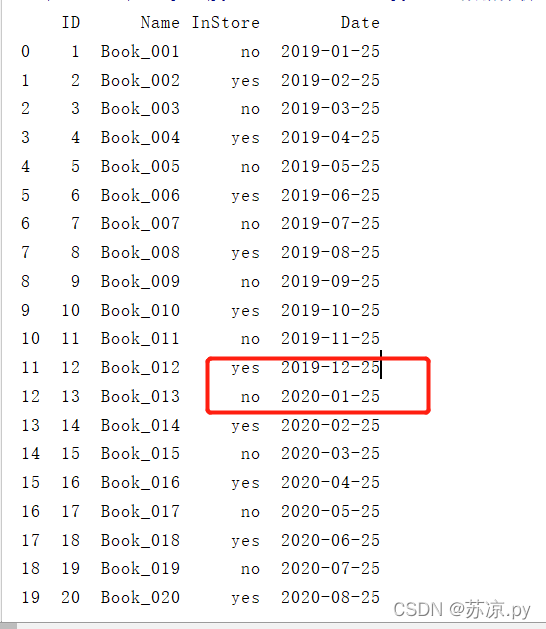
🎐5.2.3 填充月(难点!!!)
在填充月份时我们需要注意月份最高为12月,若>12月则从1月开始
定义月份的时间函数:
# d -日期 ,md—月的该变量
def add_month(d,md):
# 得到含有多少年
yd = md//12
# 获取月份
m = d.month +md%12
# 判断是否满足条件
if m != 12:
yd += m//12
m = m%12
return date(d.year +yd ,m ,d.day)
下面自动填充月份时调用函数:
books['Date'].at[i] = add_month(start_time ,i)
结果:
✨5.3 源码及保存
import pandas as pd
from datetime import date,timedelta
# d -日期 ,md—月的该变量
def add_month(d,md):
# 得到含有多少年
yd = md//12
# 获取月份
m = d.month +md%12
# 判断是否满足条件
if m != 12:
yd += m//12
m = m%12
return date(d.year +yd ,m ,d.day)
books = pd.read_excel('./Books.xlsx',skiprows=3,usecols='C:F',dtype={'ID':str})
df = pd.DataFrame(books)
start_time = date(2019,1,25)
for i in books.index:
# 对id自动填充
books['ID'].at[i] = i+1
# 对Instore自动填充
books['InStore'].at[i] = 'no' if i%2==0 else 'yes'
# 对日自动填充
# books['Date'].at[i] = start_time
# 对年自动填充
books['Date'].at[i] = date(start_time.year+i,start_time.month,start_time.day)
# 对月份自动填充
books['Date'].at[i] = add_month(start_time ,i)
books.set_index('ID',inplace=True)
books.to_excel('./book1.xlsx')
print('save success')
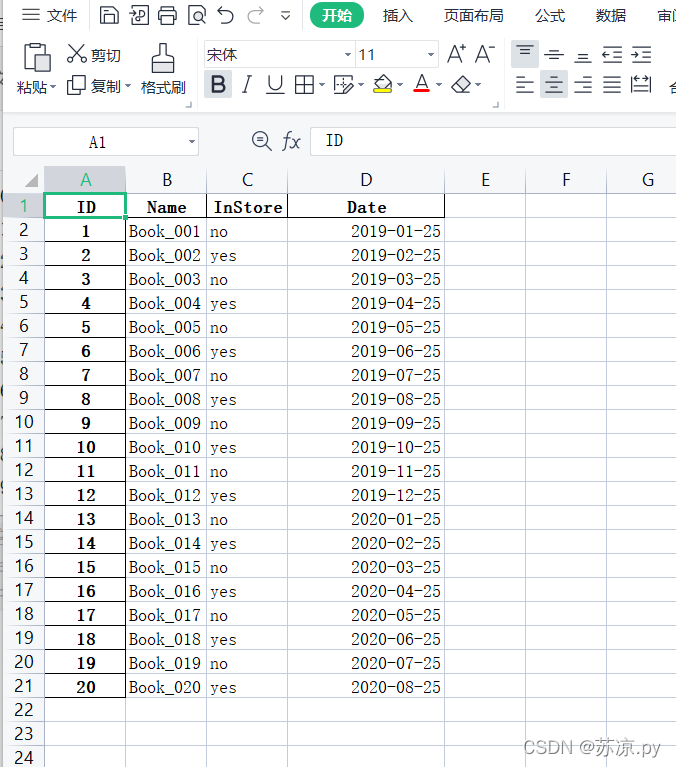
结果:
🍻结语
今天的学习到这里就结束啦,下期内容要点:
1.函数填充
2.排序
3.数据筛选
4.数据可视化
关注我,咱们下期再见!!


- 点赞
- 收藏
- 关注作者
评论(0)