机器学习(八):模型选择与调优


📢📢📢📣📣📣
🌻🌻🌻Hello,大家好我叫是Dream呀,一个有趣的Python博主,多多关照😜😜😜
🏅🏅🏅作者简介:Python领域优质创作者🏆 CSDN年度博客之星🏆 阿里云专家博主🏆 华为云享专家🏆 51CTO专家博主🏆
💕入门须知:这片乐园从不缺乏天才,努力才是你的最终入场券!🚀🚀🚀
💓最后,愿我们都能在看不到的地方闪闪发光,一起加油进步🍺🍺🍺
🍉🍉🍉一万次悲伤,依然会有Dream,我一直在最温暖的地方等你~🌈🌈🌈
🌟🌟🌟✨✨✨
前言:
❤️本文选自: 【零基础学Python】本课程是针对Python入门&进阶打造的一全套课程,在这里,我将会一 一更新Python基础语法、Python爬虫、Web开发、 Django框架、Flask框架以及人工智能相关知识,帮助你成为Python大神,如果你喜欢的话就抓紧收藏订阅起来吧~💘💘💘
1、为什么需要交叉验证
交叉验证目的:为了让被评估的模型更加准确可信
2、什么是交叉验证(cross validation)
交叉验证:将拿到的训练数据,分为训练和验证集。以下图为例:将数据分成5份,其中一份作为验证集。然后经过5次(组)的测试,每次都更换不同的验证集。即得到5组模型的结果,取平均值作为最终结果。又称5折交叉验证。
2.1 分析
我们之前知道数据分为训练集和测试集,但是为了让从训练得到模型结果更加准确。做以下处理
- 训练集:训练集+验证集
- 测试集:测试集

问题:那么这个只是对于参数得出更好的结果,那么怎么选择或者调优参数呢?
3、超参数搜索-网格搜索(Grid Search)
通常情况下,有很多参数是需要手动指定的(如k-近邻算法中的K值),这种叫超参数。但是手动过程繁杂,所以需要对模型预设几种超参数组合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型。

3.1 模型选择与调优
sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
- 对估计器的指定参数值进行详尽搜索
- estimator:估计器对象
- param_grid:估计器参数(dict){“n_neighbors”:[1,3,5]}
- cv:指定几折交叉验证
- fit:输入训练数据
- score:准确率
- 结果分析:
最佳参数:best_params_
print(“最佳参数:\n”, estimator.best_params_)
最佳结果:best_score_
print(“最佳结果:\n”, estimator.best_score_)
最佳估计器:best_estimator_
print(“最佳估计器:\n”, estimator.best_estimator_)
交叉验证结果:cv_results_
print(“交叉验证结果:\n”, estimator.cv_results_)
3.2鸢尾花案例增加K值调优
def knn_iris_gscv():
"""
用KNN算法对鸢尾花进行分类,添加网格搜索和交叉验证
:return:
"""
# 1)获取数据
iris = load_iris()
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
# 3)特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)KNN算法预估器
estimator = KNeighborsClassifier()
# 加入网格搜索与交叉验证
# 参数准备
param_dict = {"n_neighbors": [1, 3, 5, 7, 9, 11]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=10)
estimator.fit(x_train, y_train)
# 5)模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
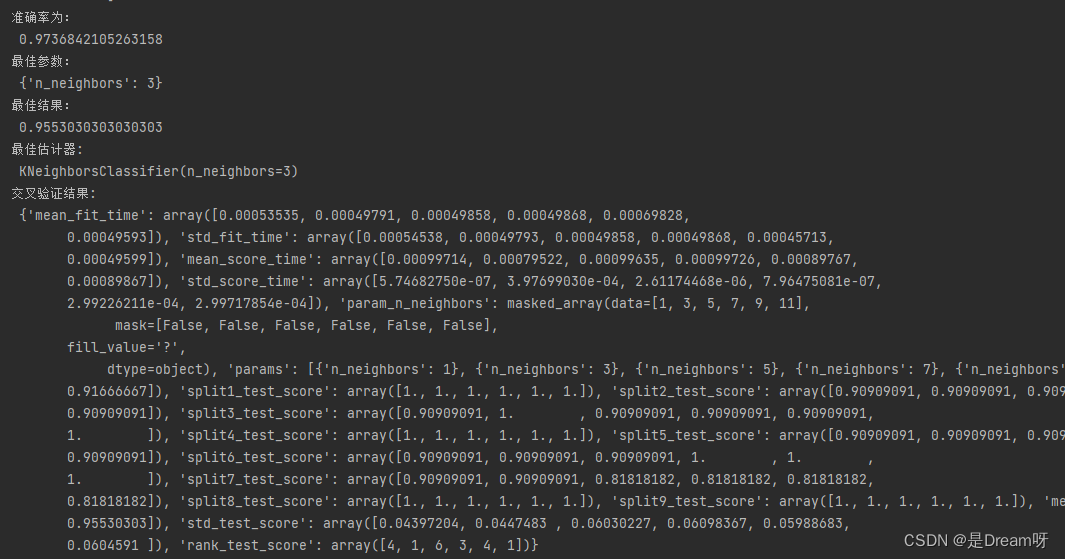
print("准确率为:\n", score)
# 最佳参数:best_params_
print("最佳参数:\n", estimator.best_params_)
# 最佳结果:best_score_
print("最佳结果:\n", estimator.best_score_)
# 最佳估计器:best_estimator_
print("最佳估计器:\n", estimator.best_estimator_)
# 交叉验证结果:cv_results_
print("交叉验证结果:\n", estimator.cv_results_)
return None

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
💕💕💕 好啦,这就是今天要分享给大家的全部内容了,我们下期再见!✨ ✨ ✨
🍻🍻🍻如果你喜欢的话,就不要吝惜你的一键三连了~


⬇️⬇️ ⬇️ 商务合作|交流学习|粉丝福利|Python全套资料⬇️ ⬇️ ⬇️ 欢迎联系~
文章来源: xuyipeng.blog.csdn.net,作者:是Dream呀,版权归原作者所有,如需转载,请联系作者。
原文链接:xuyipeng.blog.csdn.net/article/details/126402555
- 点赞
- 收藏
- 关注作者
评论(0)