Splunk 架构:转发器、索引器和搜索头教程

对 Splunk 认证专业人员的需求出现了巨大的增长,这主要是由于机器生成的日志数据不断增加,这些数据来自几乎所有塑造当今世界的先进技术。 如果您想在您的基础设施中实施 Splunk,那么了解 Splunk 的内部工作方式非常重要。我写这篇博文是为了帮助您了解 Splunk 架构,并告诉您不同的 Splunk 组件如何相互交互。
如果您想更清楚地了解什么是 Splunk,它 会让您了解 Splunk 并告诉您为什么它对于拥有庞大基础设施的公司来说是必不可少的。
在讨论不同 Splunk 组件的功能之前,让我先提一下每个组件所属的数据管道的各个阶段。
数据管道中的不同阶段
Splunk 主要有 3 个不同的阶段:
- 数据输入阶段
- 数据存储阶段
- 数据搜索阶段

数据输入阶段
在此阶段,Splunk 软件使用来自其源的原始数据流,将其分解为 64K 块,并使用元数据键对每个块进行注释。元数据键包括数据的主机名、来源和来源类型。键还可以包括内部使用的值,例如数据流的字符编码和在索引阶段控制数据处理的值,例如应将事件存储到的索引。
数据存储阶段
数据存储包括两个阶段:解析和索引。
- 在解析阶段,Splunk 软件检查、分析和转换数据以仅提取相关信息。这也称为事件处理。在此阶段,Splunk 软件将数据流分解为单个事件。解析阶段有许多子阶段:
- 将数据流分成单独的行
- 识别、解析和设置时间戳
- 使用从源范围内的键复制的元数据注释单个事件
- 根据正则表达式转换规则转换事件数据和元数据
- 在索引阶段,Splunk 软件将解析的事件写入磁盘上的索引。它写入压缩的原始数据和相应的索引文件。索引的好处是可以在搜索过程中轻松访问数据。
数据搜索阶段
此阶段控制用户如何访问、查看和使用索引数据。作为搜索功能的一部分,Splunk 软件存储用户创建的知识对象,例如报告、事件类型、仪表板、警报和字段提取。搜索功能还管理搜索过程。
Splunk 组件
如果您查看下图,您将了解各种 Splunk 组件所属的不同数据管道阶段。

Splunk 有 3 个主要组件:
- Splunk Forwarder,用于数据转发
- Splunk Indexer,用于解析和索引数据
- Search Head,是一个用于搜索、分析和报告的图形用户界面
Splunk 转发器
Splunk Forwarder 是您必须用于收集日志的组件。假设您想从远程机器收集日志,那么您可以通过使用独立于主 Splunk 实例的 Splunk 远程转发器来完成该任务。
事实上,您可以在多台机器上安装多个这样的转发器,它们会将日志数据转发到 Splunk Indexer 进行处理和存储。如果您想对数据进行实时分析怎么办?Splunk 转发器也可用于此目的。您可以配置转发器以实时向 Splunk 索引器发送数据。您可以将它们安装在多个系统中,并实时从不同机器同时收集数据。
要了解数据的实时转发是如何发生的,您可以阅读我的博客,了解 Domino's 如何使用 Splunk 来提高运营效率。
与其他传统监控工具相比,Splunk Forwarder 消耗的 CPU 非常少~1-2%。您可以轻松地将它们扩展到数以万计的远程系统,并在对性能影响最小的情况下收集数 TB 的数据。
现在,让我们了解不同类型的 Splunk 转发器。

通用转发器- 如果您想转发在源收集的原始数据,您可以选择通用转发器。它是一个简单的组件,它在将传入数据流转发到索引器之前对其进行最少的处理。
数据传输是市场上几乎所有工具的主要问题。由于在转发数据之前对数据进行了最少的处理,因此还会将大量不必要的数据转发到索引器,从而导致性能开销。
为什么要费力地将所有数据传输到索引器,然后只过滤掉相关数据?仅将相关数据发送到索引器并节省带宽、时间和金钱不是更好吗?这可以通过使用我在下面解释的重型转发器来解决。

重型转发器- 您可以使用重型转发器并消除一半的问题,因为在将数据转发到索引器之前,源本身会进行一层数据处理。Heavy Forwarder 通常在源头进行解析和索引,并智能地将数据路由到 Indexer,从而节省带宽和存储空间。所以当重型转发器解析数据时,索引器只需要处理索引段。
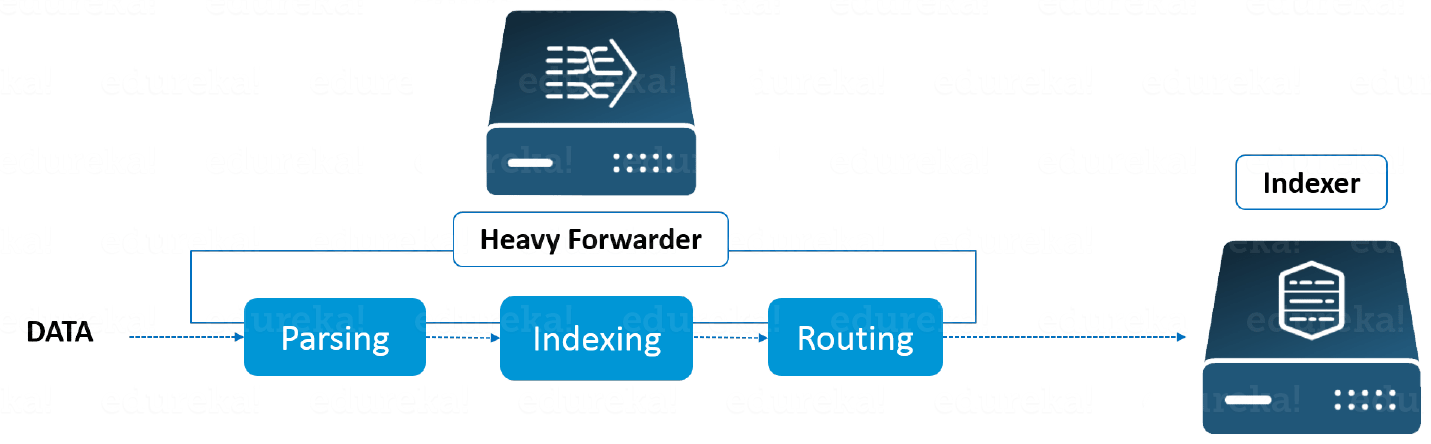
Splunk 索引器

索引器是 Splunk 组件,您必须使用它来索引和存储来自转发器的数据。Splunk 实例将传入的数据转换为事件并将其存储在索引中以高效执行搜索操作。如果您从通用转发器接收数据,则索引器将首先解析数据,然后对其进行索引。完成数据解析以消除不需要的数据。但是,如果您从重型转发器接收数据,索引器将只索引数据。
当 Splunk 实例索引您的数据时,它会创建许多文件。这些文件包含以下内容之一:
- 压缩形式的原始数据
- 指向原始数据的索引(索引文件,也称为 tsidx 文件),以及一些元数据文件
这些文件驻留在称为桶的目录集中。
现在让我告诉你索引是如何工作的。
Splunk 处理传入数据以实现快速搜索和分析。它以各种方式增强数据,例如:
- 将数据流分成单独的、可搜索的事件
- 创建或识别时间戳
- 提取主机、源和源类型等字段
- 对传入数据执行用户定义的操作,例如识别自定义字段、屏蔽敏感数据、写入新的或修改过的密钥、应用多行事件的破坏规则、过滤不需要的事件以及将事件路由到指定的索引或服务器
此索引过程也称为事件处理。
Splunk Indexer 的另一个好处是数据复制。您无需担心数据丢失,因为 Splunk 会保留索引数据的多个副本。这个过程称为索引复制或索引器集群。这是在索引器集群的帮助下实现的,索引器集群是一组配置为复制彼此数据的索引器。
Splunk 搜索头

搜索头是用于与 Splunk 交互的组件。它为用户提供图形用户界面以执行各种操作。您可以通过输入搜索词来搜索和查询Indexer 中存储的数据,您将得到预期的结果。
您可以在单独的服务器上安装搜索头,也可以在同一服务器上与其他 Splunk 组件一起安装。搜索头没有单独的安装文件,您只需要在Splunk服务器上启用splunkweb服务即可启用它。
Splunk 实例既可以用作搜索头,也可以用作搜索对等体。仅执行搜索而不执行索引的搜索头被称为专用搜索头。而搜索对等点执行索引并响应来自其他搜索头的搜索请求。
在 Splunk 实例中,搜索头可以将搜索请求发送到一组索引器或搜索对等点,后者对其索引执行实际搜索。然后搜索头合并结果并发回给用户。这是一种更快的数据搜索技术,称为分布式搜索。
搜索头集群是协调搜索活动的搜索头组。集群协调搜索头的活动,根据当前负载分配作业,并确保所有搜索头都可以访问相同的知识对象集。
具有部署服务器/管理控制台主机的高级 Splunk 架构

查看上图以了解 Splunk 的端到端工作。图像显示了一些将数据发送到索引器的远程转发器。根据索引器中存在的数据,您可以使用搜索头执行搜索、分析、可视化和创建操作智能知识对象等功能。
管理控制台主机充当集中配置管理器,负责向部署客户端分发配置、应用程序更新和内容更新。部署客户端是转发器、索引器和搜索头。
Splunk 架构
如果您已经理解了上面解释的概念,您就可以轻松地将 Splunk 架构联系起来。查看下图,全面了解流程中涉及的各种组件及其功能。
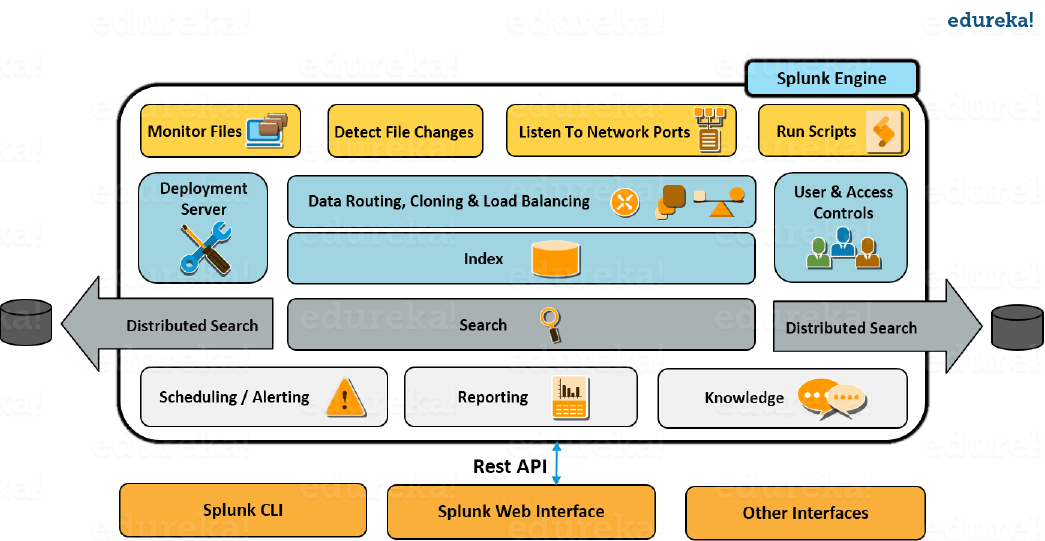
- 您可以通过运行自动化数据转发脚本来接收来自各种网络端口的数据
- 您可以监控进来的文件并实时检测变化
- 该转发器有能力来智能地路线数据,克隆的数据,并做负载均衡上的数据到达之前索引。克隆是为了在数据源上创建一个事件的多个副本,当负载平衡完成时,即使一个实例失败,数据也可以转发到另一个托管索引器的实例
- 正如我之前提到的,部署服务器用于管理整个部署、配置和策略
- 收到此数据后,将其存储在Indexer 中。然后将索引器分解为不同的逻辑数据存储区,您可以在每个数据存储区设置权限,这些权限将控制每个用户查看、访问和使用的内容
- 一旦数据进入,您可以搜索索引数据并将搜索分发给其他搜索对等点,结果将合并并发回搜索头
- 除此之外,您还可以进行预定搜索并创建警报,当某些条件与保存的搜索匹配时将触发警报
- 您可以使用已保存的搜索来创建报告并使用可视化仪表板进行分析
- 最后,您可以使用Knowledge 对象来丰富现有的非结构化数据
- 可以从Splunk CLI或Splunk Web 界面访问搜索头和知识对象。此通信通过REST API连接发生
我希望您喜欢阅读有关 Splunk 架构的博客,其中讨论了各种 Splunk 组件及其工作原理。请继续关注我关于 Splunk 知识对象的下一篇博客,同时您可以点击下面的链接阅读我之前在 Splunk 教程系列中的博客。

- 点赞
- 收藏
- 关注作者
评论(0)