别再说难了,年轻小伙教你如何爬取“新一线城市”二手房信息

写在前面
身为一名快要步入社会的菜鸟程序员,每次在各大网站看到房价的时候,都感到头皮一凉(不是头发少哈),再抬手看看手机里的余额,瞬间泪目。。

既然如此,那就先瞅瞅目前二手房的情况,瞅瞅又不要钱,看看目前都是什么行情,各地区房价的差异等。本文主要爬取链家中武汉二手房信息,包括默认排序和最新发布中的二手房信息,共 6000 条左右(可能有重复)。由于爬取的信息列有些多,数据分析及可视化的部分就留在下一篇文章中。
文中主要涉及的Python库:
lxml:页面解析提取所需内容。asyncio:提供了完善的异步IO支持,可以将多个coroutine封装成一组Task然后并发执行。aiohttp:可以实现单线程并发 IO 操作。如果仅用在客户端,发挥的威力不大,只是为了搭配asyncio来使用,因为requests不支持异步。如果把asyncio用在服务器端,例如 Web 服务器,由于 HTTP 连接就是 IO 操作,因此可以用 单线程 +coroutine实现多用户的高并发支持。pandas:将爬取的数据转为DataFrame类型,并生成csv文件。pathlib:面向对象的编程方式来表示文件系统路径。
话不多说,进入正题。

主页面信息爬取
主页面分析
首先进入 链家武汉二手房,界面如下:
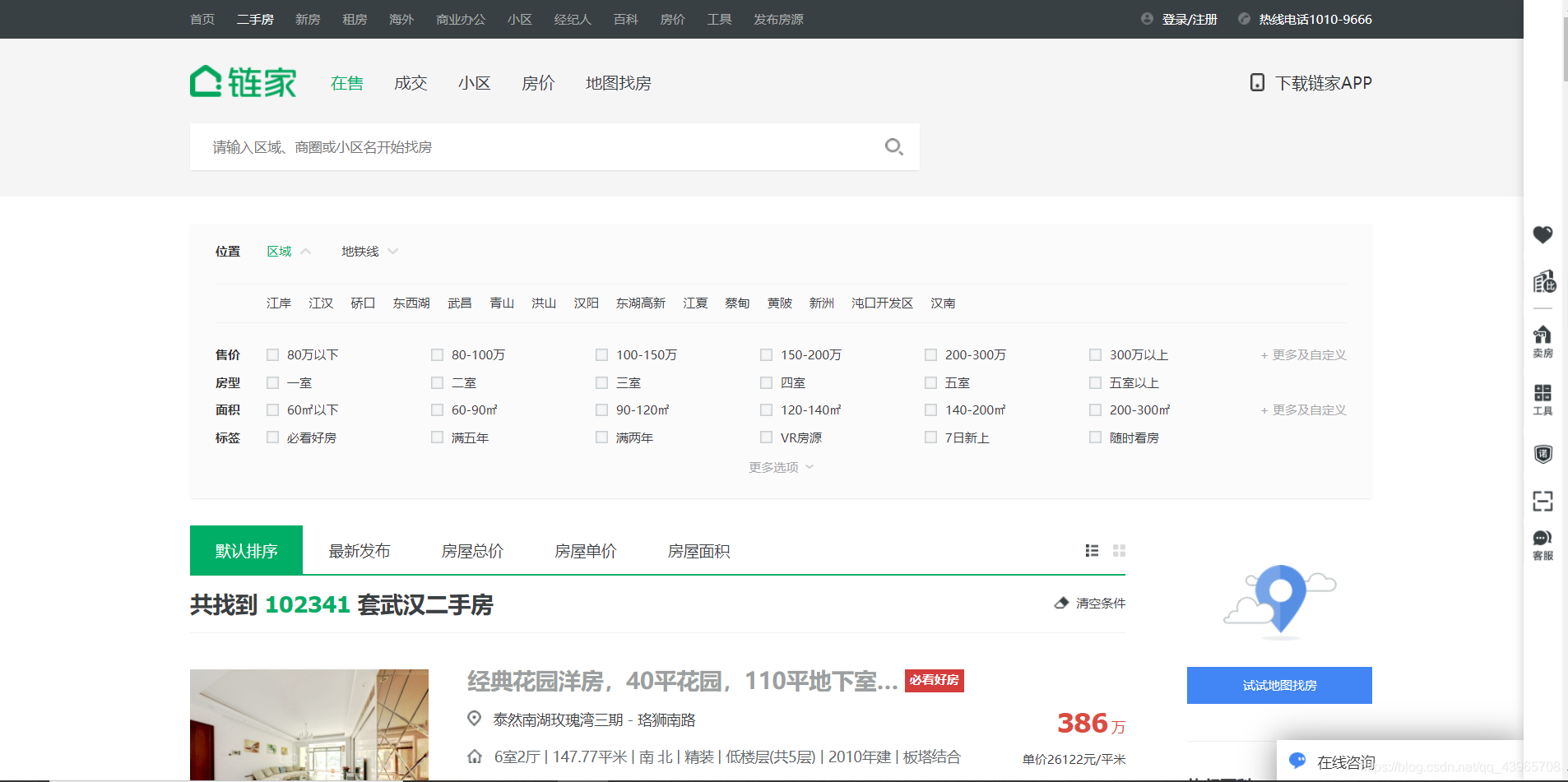
通过观察,我们发现页面中的二手房信息并不完整,因此我们在主页面中可以只爬取 详情页 的链接,其余房屋信息在详情页中再进行爬取。
当我们下拉滚动条,可以发现,页面中的数据是打开页面时就已经加载好的,而不是“懒加载”(当我们拖动界面,才会对相应资源进行请求和加载)。为了检测我们的想法是否正确可以做一个小测试。
对当前页面发出请求,将相应数据保存到 test.html 文件。
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
}
page_text = requests.get(url='https://wh.lianjia.com/ershoufang/rs/', headers=headers).text
with open('test.html', 'w', encoding='utf-8') as fp:
fp.write(page_text)
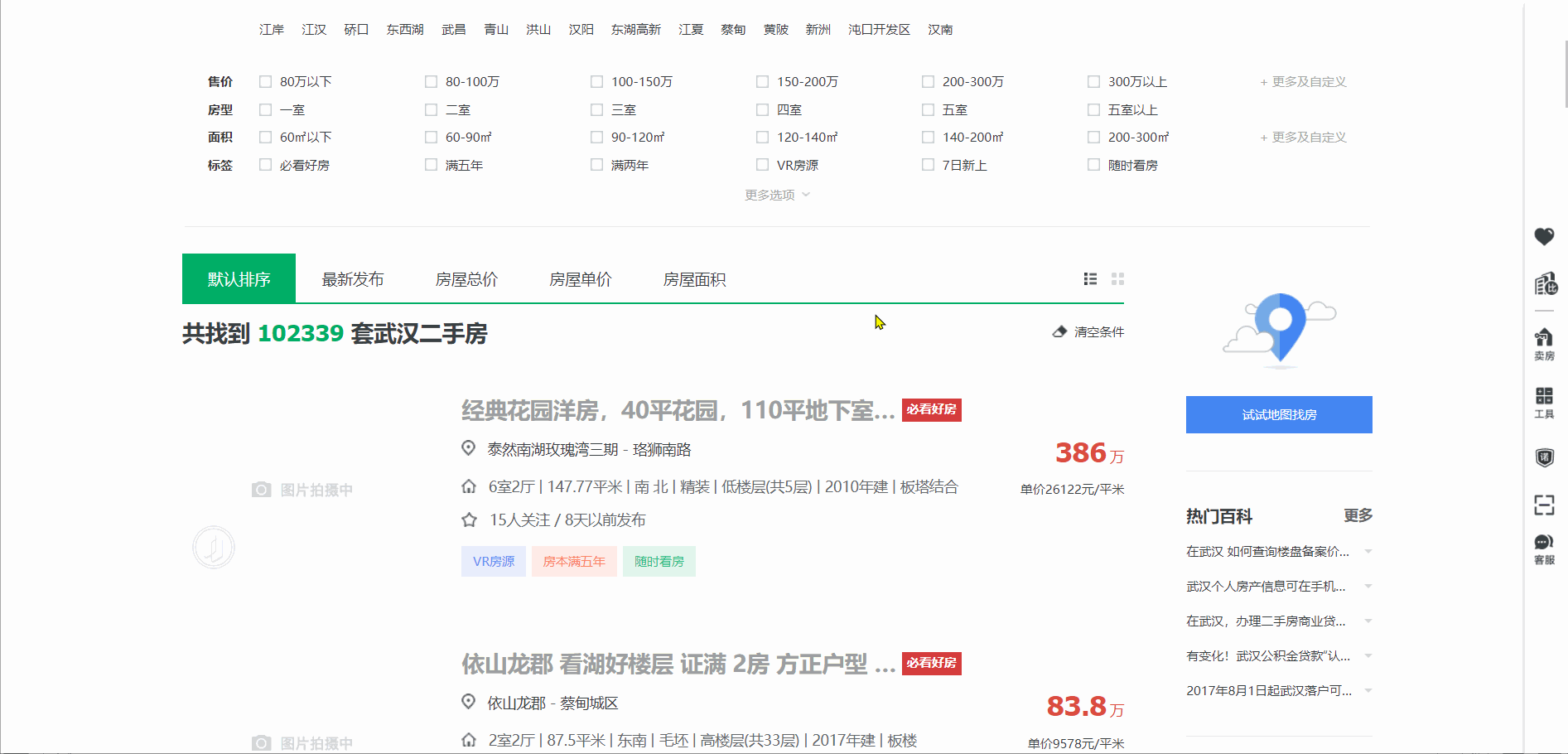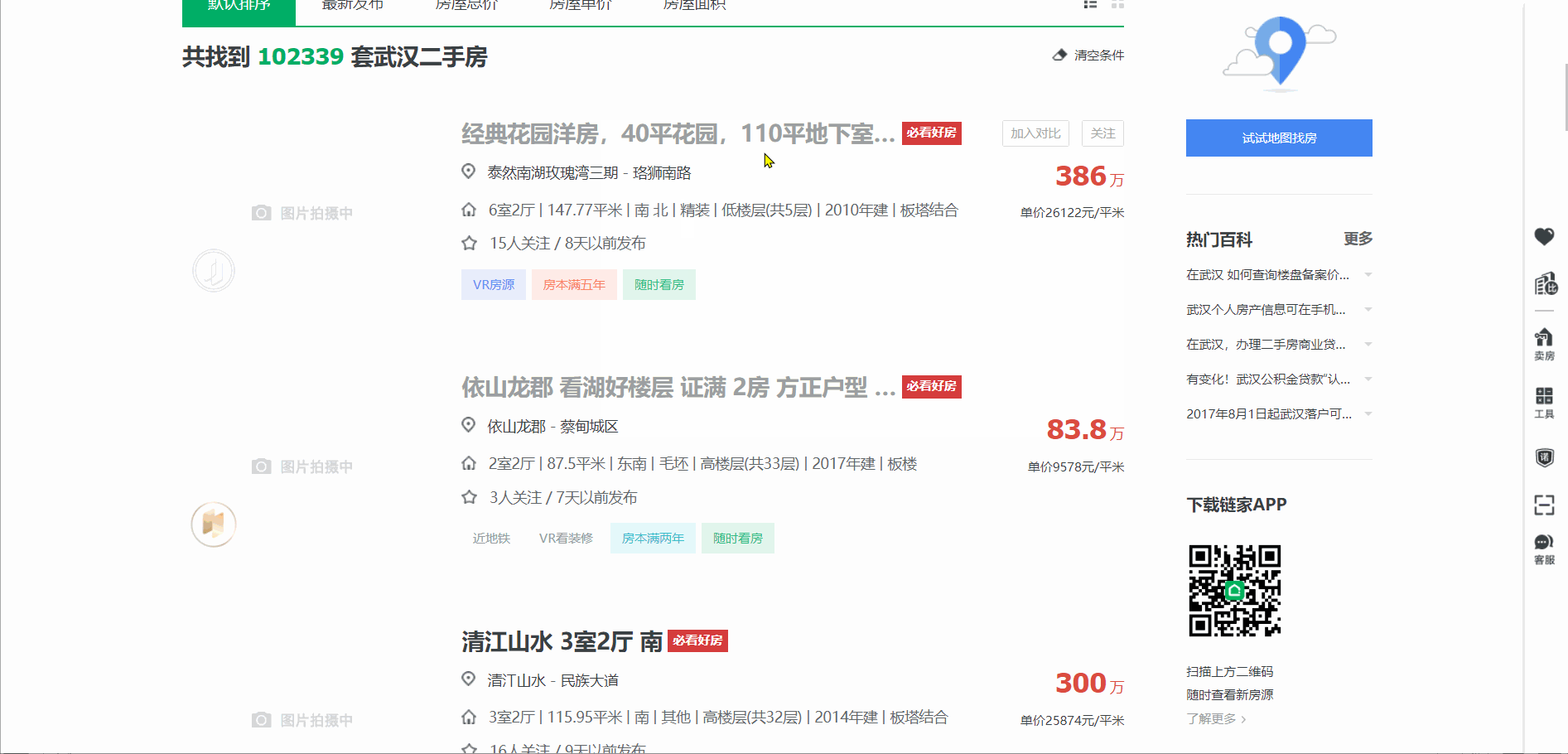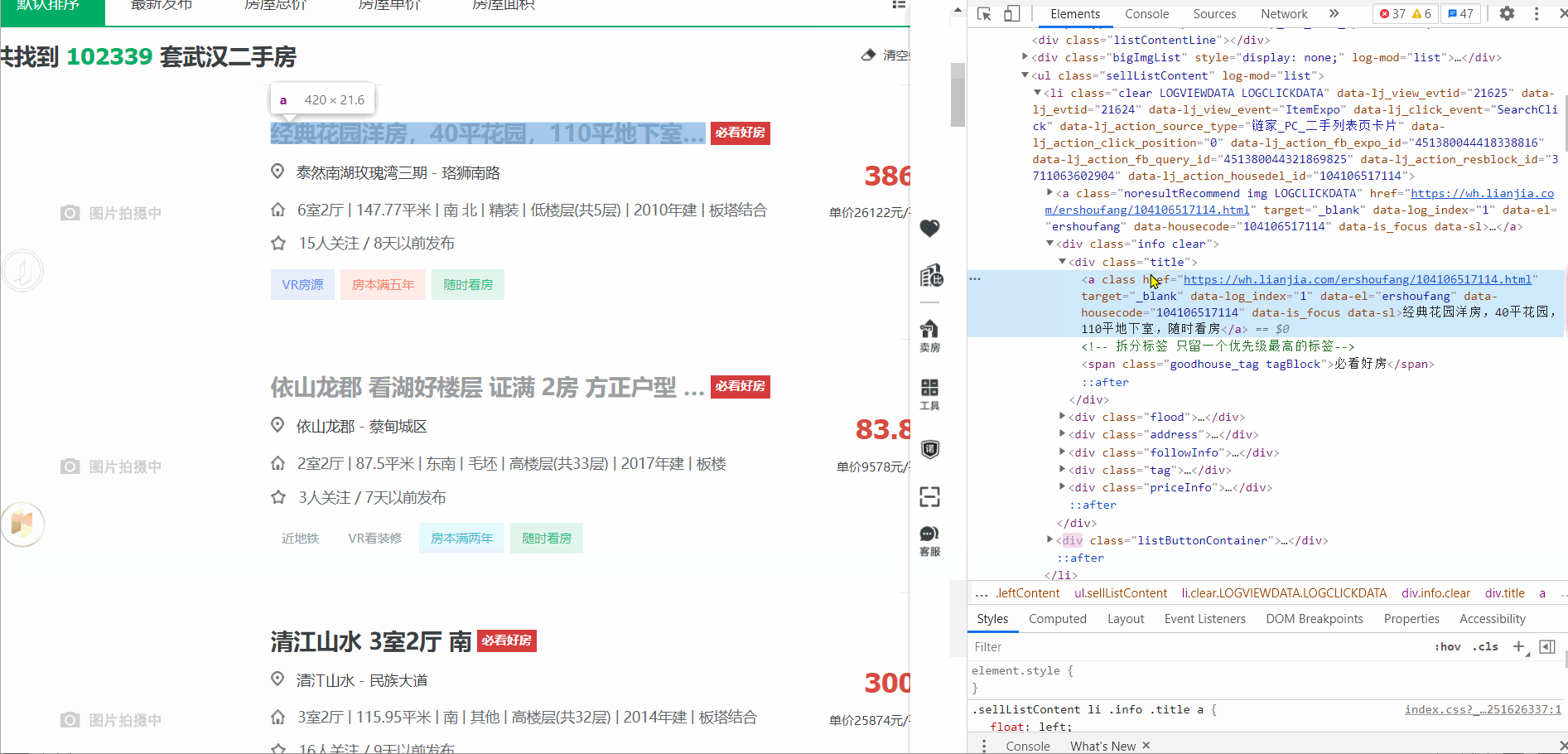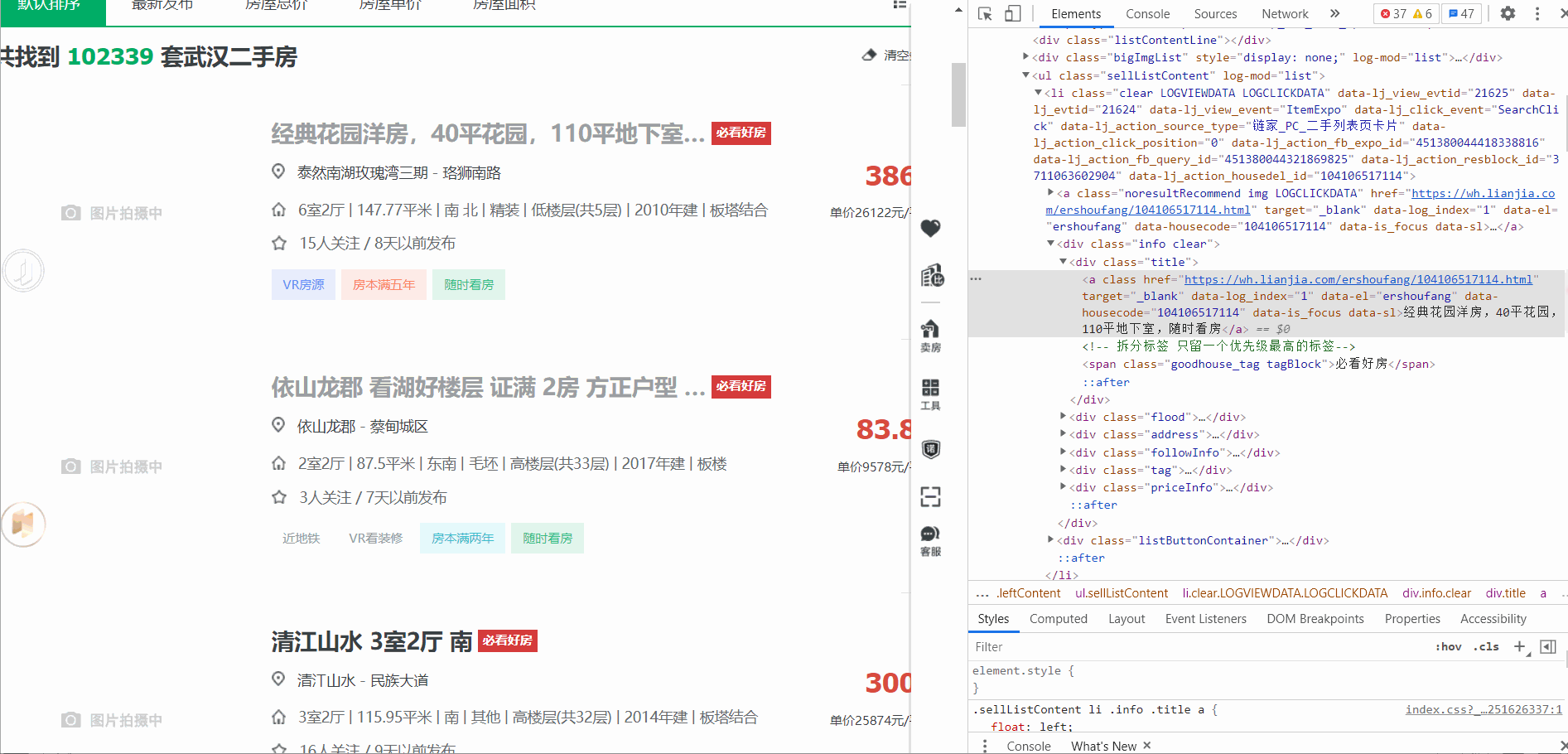
我们打开 test.html 文件,点击看是否能够进入详情页。或者通过开发者工具查找详情页的 url 。
主页面url获取
通过上面的验证,我们可以直接对页面发起请求,请求的数据中包含进入详情页的 url 。
默认排序和最新发布的菜单中各有 100 页数据。

前三页 url 比较:
默认排序:
https://wh.lianjia.com/ershoufang/rs/
https://wh.lianjia.com/ershoufang/pg2/
https://wh.lianjia.com/ershoufang/pg3/
最新发布:
https://wh.lianjia.com/ershoufang/co32/
https://wh.lianjia.com/ershoufang/pg2co32/
https://wh.lianjia.com/ershoufang/pg2co32/
通过测试发现使用下面url也可以进入第一页。
https://wh.lianjia.com/ershoufang/pg1/
https://wh.lianjia.com/ershoufang/pg1co32/
现在就可以通过代码生成待爬取的 url_list 。
def get_url_list():
url_list = []
# 默认排序
url = 'https://wh.lianjia.com/ershoufang/pg%d/'
# 最新发布
url_new = 'https://wh.lianjia.com/ershoufang/pg%dco32/'
for i in range(1, 101):
url_list.append(url%i)
url_list.append(url_new%i)
return url_list
获取页面数据
有了 url_list 我们就可以按照里面的 url ,爬取页面数据了。下面使用异步协程的方式对页面发出请求,并将获取的相应数据作为参数,传给 get_detail_url 函数(获取详情页 url )。
async def get_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
}
async with aiohttp.ClientSession(connector=aiohttp.TCPConnector(ssl=False), trust_env=True) as session:
while True:
try:
async with session.get(url=url, headers=headers, timeout=8) as response:
# 更改相应数据的编码格式
response.encoding = 'utf-8'
# 遇到IO请求挂起当前任务,等IO操作完成执行之后的代码,当协程挂起时,事件循环可以去执行其他任务。
page_text = await response.text()
# 未成功获取数据时,更换ip继续请求
if response.status != 200:
continue
print(f"{url}爬取完成!")
break
except Exception as e:
print(e)
# 捕获异常,继续请求
continue
return get_detail_url(page_text)
页面数据解析及保存
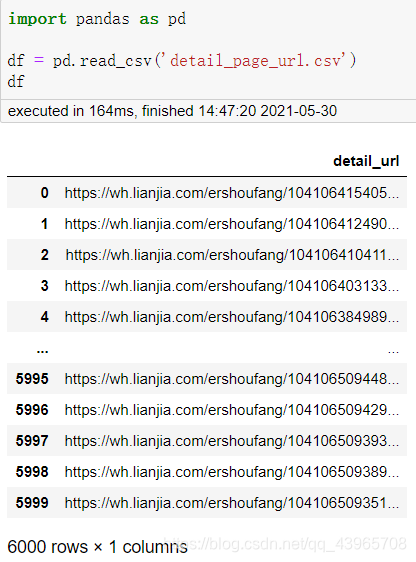
现在我们将获取的页面数据进行解析,通过 xpath 提取详情页的 url ,将详情页的 url 保存到 detail_page_url.csv 中。
def get_detail_url(page_text):
tree = etree.HTML(page_text)
li_list = tree.xpath('//*[@id="content"]/div[1]/ul/li')
detail_url_list = []
for li in li_list:
detail_url_list.append(li.xpath('./div[1]/div[1]/a/@href')[0])
df = pd.DataFrame({'detail_url': detail_url_list})
header = False if Path.exists(Path(current_path, 'detail_page_url.csv')) else True
df.to_csv(Path(current_path, 'detail_page_url.csv'), index=False, mode='a', header=header)
详情页 url 数据
详情页信息爬取
详情页分析
我们先看看详情页的信息有哪些是我们所需要的。
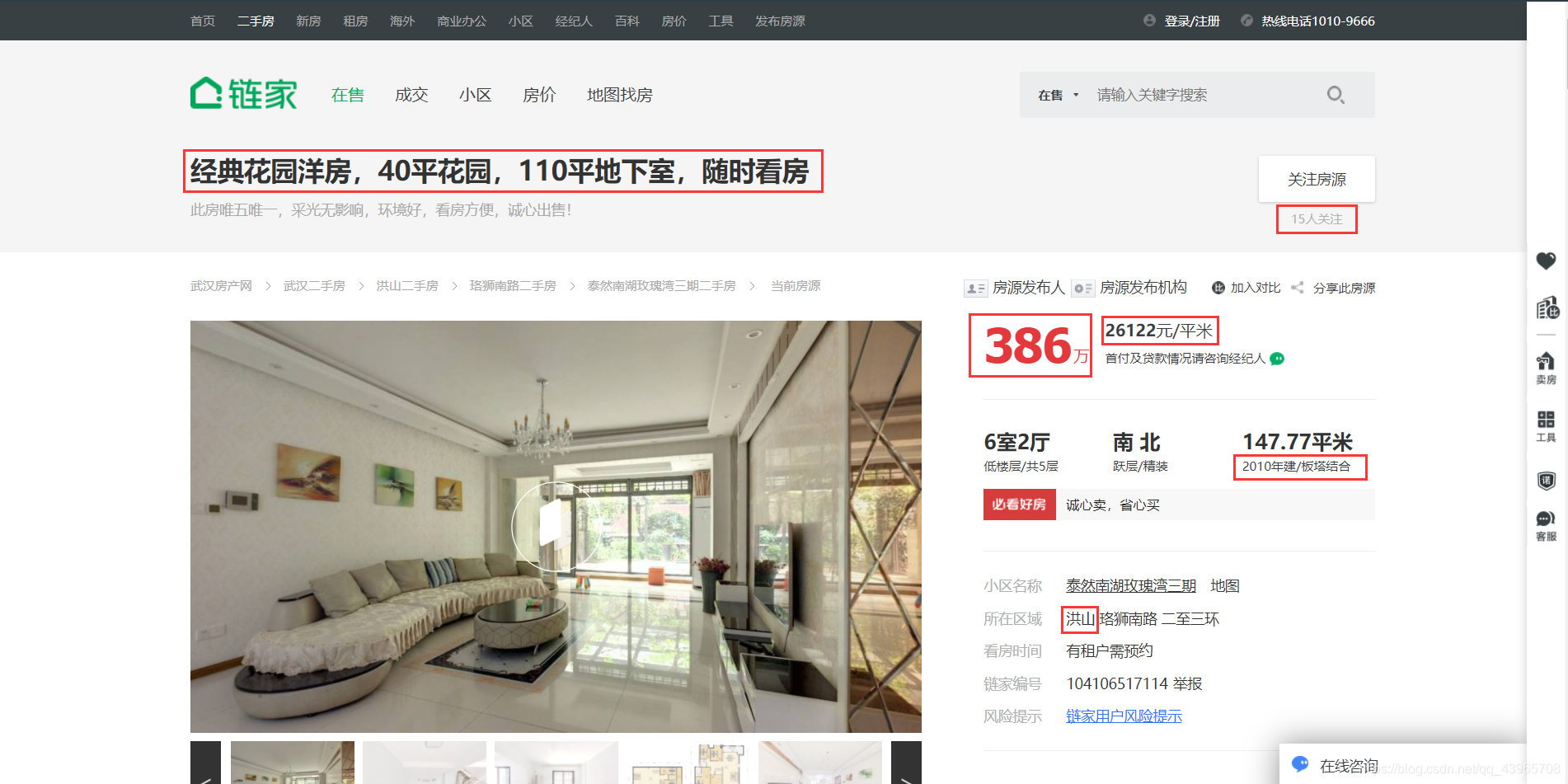

上面红框框出的均需要进行爬取,信息当然是多多益善啦。
加载详情页url
由于 6000 条详情页的 url 中有重复的详情页,经过去重后取 5500 条 url 保存到待爬取列表中。
def get_url_list():
df = pd.read_csv(Path(current_path, 'detail_page_url.csv'))
df.drop_duplicates(keep='first', inplace=True)
url_list = df['detail_url'].values.tolist()
# 取url_list中的前5500条
return url_list[: 5500]
获取页面数据
与主页面的获取方式相同。
async def get_detail_page(url, semaphore):
async with semaphore:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
}
async with aiohttp.ClientSession(connector=aiohttp.TCPConnector(ssl=False), trust_env=True) as session:
while True:
try:
async with session.get(url=url, headers=headers, timeout=8) as response:
# 更改相应数据的编码格式
response.encoding = 'utf-8'
# 遇到IO请求挂起当前任务,等IO操作完成执行之后的代码,当协程挂起时,事件循环可以去执行其他任务。
page_text = await response.text()
# 未成功获取数据时,更换ip继续请求
if response.status != 200:
continue
print(f"{url}爬取完成!")
break
except Exception as e:
print(e)
# 捕获异常,继续请求
continue
return parse_page_text(page_text)
页面数据解析及保存
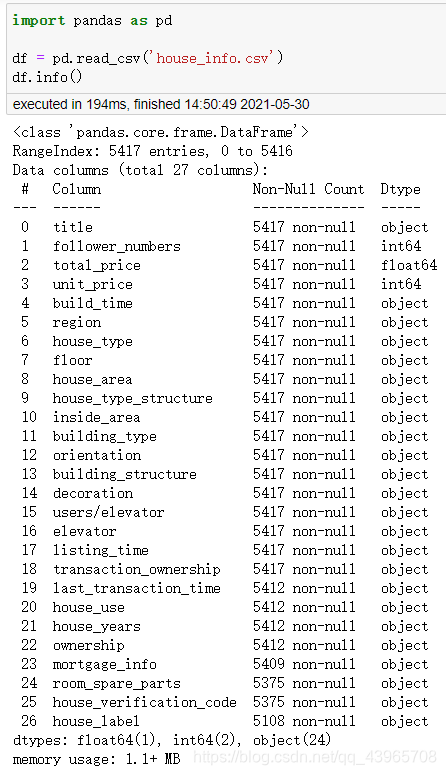
由于需要提取的信息较多,所以代码量有些多,整体思路:建立保存房屋信息的字典 house_info_dict ,通过 xpath 解析获取各部分信息,简单处理后(更改数据类型,提取数字,截取部分等)将其保存到 house_info_dict ,最后将 house_info_dict 的信息保存到 csv 中。
def parse_page_text(page_text):
tree = etree.HTML(page_text)
house_info_dict = {}
house_info_dict['title'] = tree.xpath('/html/body/div[3]/div/div/div[1]/h1/text()')[0] # 标题
house_info_dict['follower_numbers'] = int(tree.xpath('//*[@id="favCount"]/text()')[0]) # 关注人数
div = tree.xpath('/html/body/div[5]/div[2]/div')
house_info_dict['total_price'] = float(div[2].xpath('./span[1]/text()')[0]) # 房价(万)
house_info_dict['unit_price'] = int(div[2].xpath('./div[1]/div[1]/span//text()')[0]) # 单位房价(元/平米)
house_info_dict['build_time'] = div[3].xpath('./div[3]/div[2]/text()')[0][:4] # 建造时间
house_info_dict['region'] = div[4].xpath('./div[2]/span[2]/a[1]/text()')[0] # 房屋地区
# 基本信息提取
li_list1 = tree.xpath('//*[@id="introduction"]/div/div/div[1]/div[2]/ul/li')
info_name1 = ['house_type', 'floor', 'house_area', 'house_type_structure', 'inside_area', 'building_type',
'orientation', 'building_structure', 'decoration', 'users/elevator', 'elevator']
for i in range(len(li_list1)):
house_info_dict[info_name1[i]] = li_list1[i].xpath('./text()')[0]
# 交易信息提取
li_list2 = tree.xpath('//*[@id="introduction"]/div/div/div[2]/div[2]/ul/li')
info_name2 = ['listing_time', 'transaction_ownership', 'last_transaction_time', 'house_use', 'house_years',
'ownership', 'mortgage_info', 'room_spare_parts', 'house_verification_code']
for i in range(len(li_list2)):
house_info_dict[info_name2[i]] = li_list2[i].xpath('./span[2]/text()')[0]
# 去除抵押贷款信息中的换行符和两边的空格
house_info_dict['mortgage_info'] = house_info_dict['mortgage_info'].replace('\n', '')
house_info_dict['mortgage_info'] = house_info_dict['mortgage_info'].strip()
house_label_list = []
div_list = tree.xpath('/html/body/div[7]/div[1]/div[2]/div/div[1]/div[2]/a')
for div in div_list:
house_label = div.xpath('./text()')[0]
house_label = house_label.replace('\n', '') # 去换行符
house_label = house_label.strip() # 去除两边空格
house_label_list.append(house_label)
house_info_dict['house_label'] = ','.join(house_label_list)
df = pd.DataFrame(house_info_dict, index=[0])
header = False if Path.exists(Path(current_path, 'house_info.csv')) else True
df.to_csv(Path(current_path, 'house_info.csv'), index=False, mode='a', header=header)
详情页房屋数据
由于部分房屋详情页中部分信息缺失,导致实际爬取的数量略少于 < 5500 条。
❤完整代码及数据集:github地址❤
下一篇,将针对爬取的武汉二手房数据进行分析,寻找武汉各地区二手房热门区域,热门户型,房价信息,与房价相关的一些因素等(很快更新)。
- 点赞
- 收藏
- 关注作者
评论(0)