HDFS系列(1) | HDFS文件系统的简单介绍

在Hadoop分布式环境搭建(简单高效~)这篇博客中,博主在最后为大家带来了HDFS的初体验。但是当时只是尝试测试一下集群是否有错误,因此,本篇博文为大家带来HDFS的文件系统介绍。
在介绍文件系统之前我们首先需要了解HDFS的作用。我们都知道HDFS是Hadoop的一个核心组件,那在Hadoop中HDFS扮演着怎样的一个角色呢?我们可以通过下图直观的了解。

- 上图中个部分的作用:
- HDFS:一个高可靠、高吞吐量的分布式文件系统,对海量数据的存储。
- MapReduce:一个分布式的资源调度和离线并行计算框架。
- Yarn:基于HDFS,用于作业调度和集群资源管理的框架。
话不多说,开始进入正题
一. HDFS基本介绍
HDFS 是 Hadoop Distribute File System 的简称,意为:Hadoop 分布式文件系统。是 Hadoop 核心组件之一,作为最底层的分布式存储服务而存在。
分布式文件系统解决的问题就是大数据存储。它们是横跨在多台计算机上的存储系统。分布式文件系统在大数据时代有着广泛的应用前景,它们为存储和处理超大规模数据提供所需的扩展能力。

可以把HDFS理解为将多个节点上的容量汇总到一起,拼接成一个大的文件系统,在一个节点上上传数据,在其他的节点上都能够访问使用。
二. HDFS的组成架构及作用
- 1. 在HDFS中,使用主从节点的方式,即使用Master和Slave结构对集群进行管理。一般一个 HDFS 集群只有一个Namenode 和一定数目的Datanode 组成。Namenode 是 HDFS 集群主节点,Datanode 是 HDFS集群从节点,两种角色各司其职,共同协调完成分布式的文件存储服务。

那么如何生动的理解这一过程呢,博主准备如下图片使大家能够使大家能够能加容易的理解这一概念:
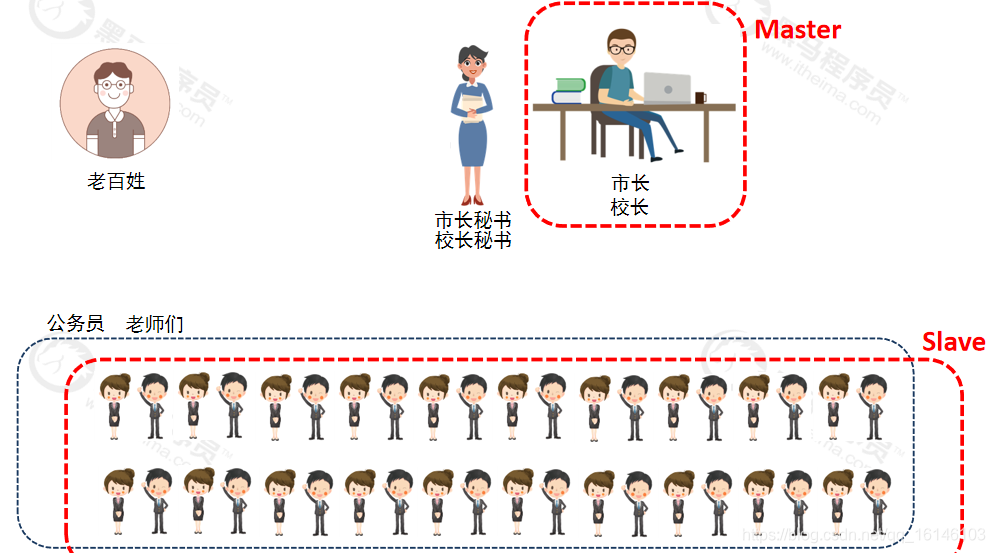


由上图可知: NameNode(Master)管理者 - 只负责管理,管理集群内各个节点。 SecondaryNameNode 辅助管理 – 只负责辅助NameNode管理工作。 DataNode(Slave) 工作者,是负责工作,周期向NameNode汇报,进行读写数据。
- 1
- 2
- 3
- 4
- 2. HDFS集群包括,NameNode,DataNode,clent以及Secondary Namenode(在第九部分有图解)
①NameNode(Master)
- 1.管理HDFS的名称空间
- 2.配置副本策略
- 3.管理数据块(Block)映射信息
- 4.处理客户端读写请求
②DataNode(Slave)
- 1.存储实际的数据块
- 2.执行数据块的读/写操作
③ Client
- 1.文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行上传
- 2.与NaneNode交互,获取文件的位置信息
- 3.与DataNode交互,读取或者写入数据
- 4.Client提供一些命令来管理HDFS,比如NameNode格式化
- 5.Client可以通过一些命令来访问HDFS,比如对HDFS增删查改操作
④SecondaryNameNode:
- 1.辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode
- 2.在紧急情况下,可辅助恢复NameNode
三. HDFS分块存储
HDFS将所有的文件全部抽象成为block块来进行存储,不管文件大小,全部一视同仁都是以block块的统一大小和形式进行存储,方便我们的分布式文件系统对文件的管理。
块的默认大小在Hadoop2.x版本中是128M,老版本为64M。block块的大小可以通过hdfs-site.xml当中的配置文件进行指定。
<property> <name>dfs.block.size</name> <value>块大小 以字节为单位</value>//只写数值就可以 </property>
- 1
- 2
- 3
- 4
- 5

注意:
你需要了解知识点:
一个文件100M,上传到HDFS占用几个快?一个块128M,剩余的28M怎么办?
事实上,128只是个数字,数据超过128M,便进行切分,如果没有超过128M,就不用切分,有多少算多少,不足128M的也是一个块。这个块的大小就是100M,没有剩余28M这个概念。
四. 抽象成数据块的好处
为什么要要将数据抽象成数据块呢?又有哪些好处?
- 一个文件有可能大于集群中任意一个磁盘
10T*3/128 = xxx块 2T,2T,2T 文件方式存—–>多个block块,这些block块属于一个文件- 使用块抽象而不是文件可以简化存储子系统
- 块非常适合用于数据备份进而提供数据容错能力和可用性
通常DataNode从磁盘中读取块,但对于访问频繁的文件,其对应的块可能被显示的缓存在DataNode的内存中,以堆外块缓存的形式存在。默认情况下,一个块仅缓存在一个DataNode的内存中,当然可以针对每个文件配置DataNode的数量。作业调度器通过在缓存块的DataNode上运行任务,可以利用块缓存的优势提高读操作的性能。
例如:
连接(join)操作中使用的一个小的查询表就是块缓存的一个很好的候选。
用户或应用通过在缓存池中增加一个cache directive来告诉namenode需要缓存哪些文件及存多久。缓存池(cache pool)是一个拥有管理缓存权限和资源使用的管理性分组。
例如一个文件 130M,会被切分成2个block块,保存在两个block块里面,实际占用磁盘130M空间,而不是占用256M的磁盘空间
五. HDFS副本机制
HDFS视硬件错误为常态,硬件服务器随时有可能发生故障。为了容错,文件的所有 block 都会有副本。每个文件的 block 大小和副本系数都是可配置的。应用程序可以指定某个文件的副本数目。副本系数可以在文件创建的时候指定,也可以在之后改变。
数据副本默认保存三个副本,我们可以更改副本数以提高数据的安全性,怎样修改副本数呢?
vim hdfs-site.xml
<property> <name>dfs.replication</name> # 这里填写副本数,修改完毕之后记得重启集群生效 <value>3</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
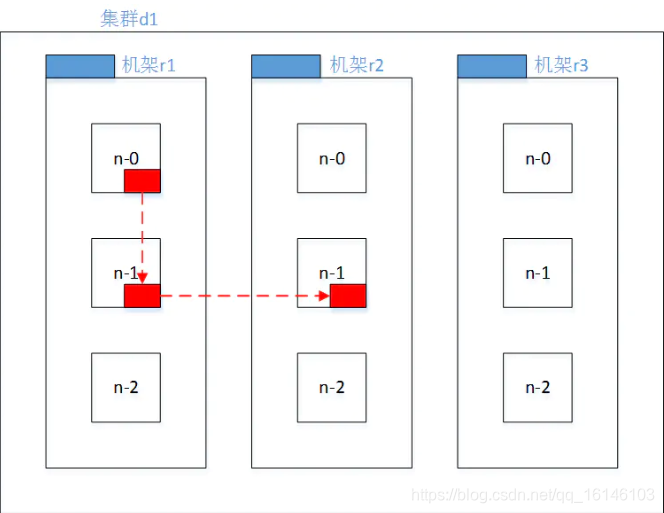
六. Hadoop2.7.2副本节点选择
第一个副本在client所处的节点上。如果客户端在集群外,随机选一个。
第二个副本和第一个副本位于相同机架,随机节点。
第三个副本位于不同机架,随机节点。
- 1
- 2
- 3
七. 名字空间(NameSpace)
HDFS 支持传统的层次型文件组织结构。用户或者应用程序可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动或重命名文件。
Namenode 负责维护文件系统的名字空间,任何对文件系统名字空间或属性的修改都将被Namenode 记录下来。
HDFS 会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,
形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data。

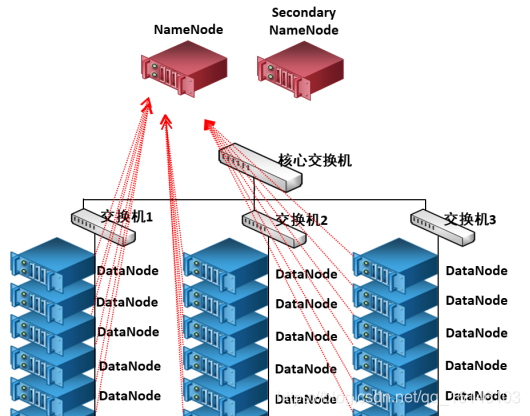
八. Namenode 元数据管理
- 1.我们把目录结构及文件分块位置信息叫做元数据。Namenode负责维护整个hdfs文件系统的目录树结构,以及每一个文件所对应的 block 块信息(block 的id,及所在的datanode服务器)。

- 2. Namenode节点负责确定指定的文件块到具体的Datanode结点的映射关系。在客户端与数据节点之间共享数据。
- 3.管理Datanode结点的状态报告,包括Datanode结点的健康状态报告和其所在结点上数据块状态报告,以便能够及时处理失效的数据结点。


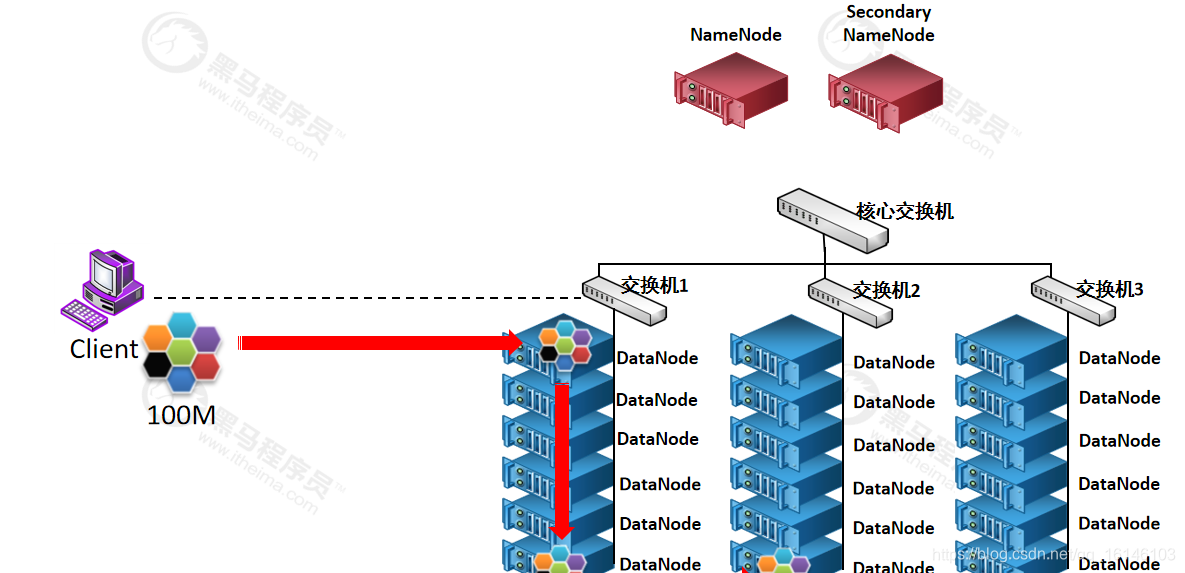
九. Datanode 数据存储
- 1. 文件的各个 block 的具体存储管理由 datanode 节点承担。每一个 block 都可以在多个datanode
上。Datanode 需要定时向 Namenode 汇报自己持有的 block信息。 存储多个副本(副本数量也可以通过参数设置
dfs.replication,默认是 3)。
- 2.向Namenode结点报告状态。每个Datanode结点会周期性地向Namenode发送心跳信号和文件块状态报告。

心跳是每3秒一次,心跳返回结果带有namenode给该datanode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个datanode的心跳,则认为该节点不可用。
DataNode启动后向namenode注册,通过后,周期性(1小时)的向namenode上报所有的块信息。

- 3.执行数据的流水线复制。当文件系统客户端从Namenode服务器进程获取到要进行复制的数据块列表后,完成文件块及其块副本的流水线复制。
一个数据块在datanode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
本次的分享就到这里了,喜欢的各位小伙伴们希望你们能够点赞和关注呀
文章来源: buwenbuhuo.blog.csdn.net,作者:不温卜火,版权归原作者所有,如需转载,请联系作者。
原文链接:buwenbuhuo.blog.csdn.net/article/details/105665463

- 点赞
- 收藏
- 关注作者
评论(0)