经典/最新计算机视觉论文及代码推荐

今日推荐几篇最新计算机视觉方向的论文,涉及诸多方面,具体内容详见论文原文和代码链接。
文本到图像生成

-
论文题目:Zero-Shot Text-to-Image Generation
-
论文链接:https://arxiv.org/pdf/2102.12092v2.pdf
-
代码链接:https://github.com/openai/DALL-E
文本到图像的生成传统上侧重于寻找更好的建模假设,以便在固定数据集上进行训练。这些假设可能涉及复杂的体系结构、辅助损失或辅助信息,如训练期间提供的目标部分标签或分割掩码。我们描述了一种基于transformer的简单方法,其将文本和图像标记自动回归建模为单个数据流。由于有足够的数据和规模,当以零拍方式进行评估时,我们的方法与以前的领域特定模型具有竞争力。

跨模态3D目标检测框架
-
论文题目:Voxel Field Fusion for 3D Object Detection
-
论文链接:https://arxiv.org/pdf/2205.15938v1.pdf
-
代码链接:https://github.com/dvlab-research/vff

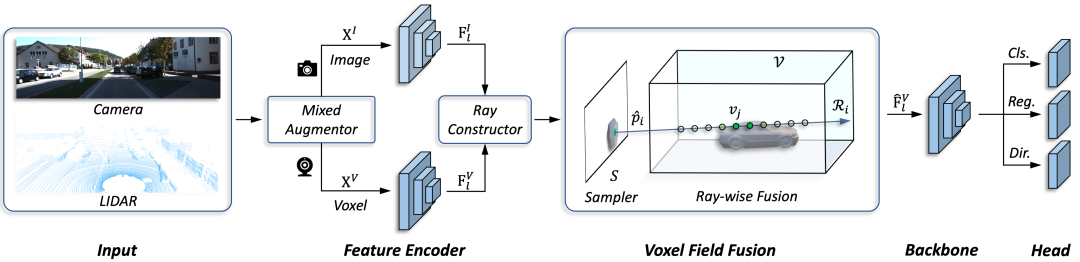
作者提出了一个概念简单但有效的跨模态三维目标检测框架,称为Voxel Field Fusion。提出的方法旨在通过在Voxel field中将增强图像特征表示为ray并进行融合来保持跨模态一致性。为此,可学习采样器首先被设计用于从图像平面中采样重要特征,这些特征以点到射线的方式投影到体素网格,从而保持特征表示与空间上下文的一致性。此外,在构建的voxel field中进行光线融合,将特征与补充上下文进行融合。我们进一步开发了混合增强器来对齐特征变量转换,从而弥补了数据增强器中的模态差异。所提出的框架在各种基准测试中取得了一致的收益,并且优于以前基于KITTI和nuScenes数据集的融合方法。下图是基于voxel field融合的三维目标检测框架结构图:
OnePose:无CAD模型的姿态估计
-
论文题目:OnePose: One-Shot Object Pose Estimation without CAD Models
-
论文链接:https://arxiv.org/pdf/2205.12257v1.pdf
-
代码链接:https://github.com/zju3dv/OnePose

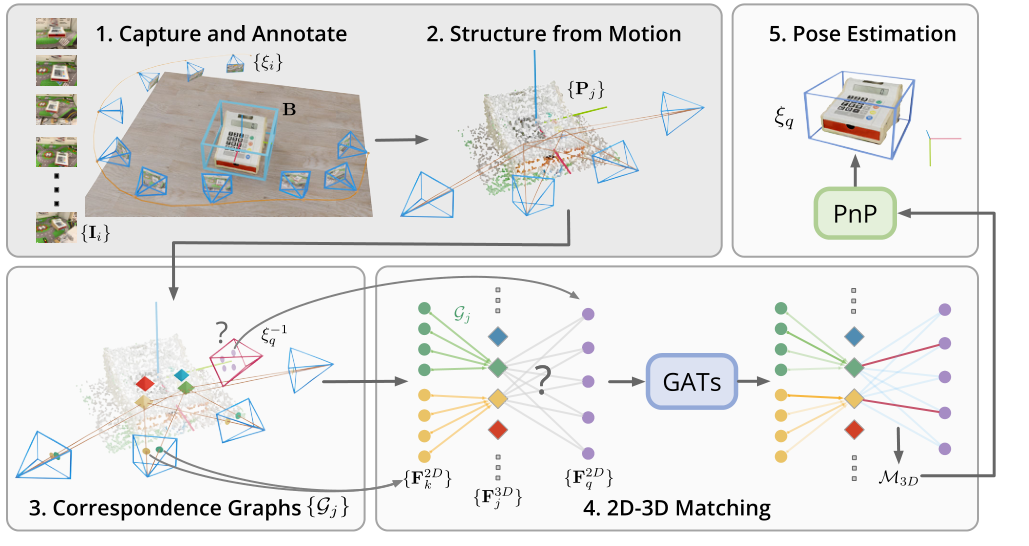
作者提出了一种新的物体姿态估计方法OnePose。与现有实例级或类别级方法不同,OnePose不依赖CAD模型,可以处理任意类别中的对象,而无需实例或特定类别的网络训练。OnePose借鉴了视觉定位的思想,只需对对象进行简单的RGB视频扫描即可构建对象的稀疏SfM模型。然后,使用通用特征匹配网络将该模型注册到新的查询图像中。为了缓解现有视觉定位方法运行缓慢的问题,我们提出了一种新的图形注意网络,该网络将查询图像中的2D兴趣点与SfM模型中的3D点直接匹配,从而实现高效、鲁棒的姿势估计。结合基于特征的姿势跟踪器,OnePose能够实时稳定地检测和跟踪日常家居对象的6D姿势。我们还收集了一个由150个对象的450个序列组成的大规模数据集。下图是OnePose的模型框架图:
后续
下一期最新/经典视觉论文敬请期待!
文章来源: blog.csdn.net,作者:小小谢先生,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/xiewenrui1996/article/details/125233155

- 点赞
- 收藏
- 关注作者
评论(0)