【蓝桥杯】高频算法考点及真题详解小结

🙊🙊作者主页:🔗
📔📔 精选专栏:🔗
📋📋 精彩摘要:考前看一看,AC手拿软。蓝桥杯高频算法考点小结,包括各大算法、排序算法及图的优先遍历原则知识点小结。预祝大家取得优异成绩。
💞💞觉得文章还不错的话欢迎大家点赞👍➕收藏⭐️➕评论💬支持博主🤞
📚目录
📖【蓝桥杯】高频算法考点及例题详解小结
📝1️⃣贪心算法之区间问题详解
1.什么是贪心算法
基本思想
1)贪婪算法(贪心算法)是指在对问题进行求解时,在每一步选择中都采取最好或者最优(即最有利)的选择,从而希望能够导致结果是最好或者最优的算法。
2)贪婪算法所得到的结果不一定是最优的结果(有时候会是最优解),但是都是相对近似(接近)最优解的结果。局限性
贪心算法失效的很大一个原因在于它明显的局限性:它几乎只考虑局部最优解。 所谓局部最优,就是只考虑当前的最大利益,既不向前多看一步,也不向后多看一步,导致每次都只用当前阶段的最优解。 因此在绝大多数情况下,贪心算法不能得到整体最优解,但它的解是最优解的一个很好近似。
2.经典例题
区间问题
给定多个区间,计算让这些区间互不重叠所需要移除区间的最少个数。起止相连不算重叠。
输入输出样例
输入:是一个数组,数组由多个长度固定为2的数组组成,表示区间的开始和结尾。 输出:一个整数,表示需要移除的区间数量。
Input :[1,2],[2,4],[1,3]] Output :1 在这个样例中,我们可以移除区间[1,3],使得剩余的区间[1,2],[2,4]]互不重叠。
贪心策略
在选择要保留区间时,区间的结尾很重要:选择的区间结尾越小,余留给其它区间的空间
就越大,就越能保留更多的区间。
因此,我们采取的贪心策略为,优先保留结尾小且不相交的区间。具体实现方法为:1.先把区间按照结尾的大小进行增序排序,
2.每次选择结尾最小且和前一个选择的区间不重叠的区间。
在样例中,排序后的数组为[1,2],[1,3],[2,4]]。按照我们的贪心策略,首先初始化为区间[1,2];由于[1,3]与[1,2]相交,我们跳过该区间;由于[2,4]与[1,2]不相交,我们将其保留。因此最终保留的区间为[1,2],[2,4]。
3.代码实现
import java.util.Arrays; import java.util.Comparator; public class Solution { public static int merge(int[][] intervals) { //先按照区间结尾的大小进行升序排序 Arrays.sort(intervals, new Comparator<int[]>() { @Override public int compare(int[] o1, int[] o2) { return o1[1] - o2[1]; } }); int count =1;//区间不重合的个数,默认第一个满足题意,初始化为1 int cur = intervals[0][1];//排序完成后贪心选择的最小的区间结尾 for (int i = 1; i < intervals.length; i++) { if(intervals[i][0] >= cur) { count++; cur=intervals[i][1]; } } //所有区间的个数减去不重叠区间的个数,就是重叠区间的个数。 return intervals.length - count; } }
📝2️⃣动态规划之经典包子凑数
题目
小明几乎每天早晨都会在一家包子铺吃早餐。他发现这家包子铺有NN种蒸笼,其中第ii种蒸笼恰好能放A_iAi个包子。每种蒸笼都有非常多笼,可以认为是无限笼。
每当有顾客想买XX个包子,卖包子的大叔就会迅速选出若干笼包子来,使得这若干笼中恰好一共有XX个包子。比如一共有33种蒸笼,分别能放3、43、4和55个包子。当顾客想买1111个包子时,大叔就会选22笼33个的再加11笼55个的(也可能选出11笼33个的再加22笼44个的)。
当然有时包子大叔无论如何也凑不出顾客想买的数量。比如一共有33种蒸笼,分别能放4、54、5和66个包子。而顾客想买77个包子时,大叔就凑不出来了。
小明想知道一共有多少种数目是包子大叔凑不出来的。输入
第一行包含一个整数N。(1 <= N <= 100)
以下N行每行包含一个整数Ai。(1 <= Ai <= 100)2
4
5输出
一个整数代表答案。如果凑不出的数目有无限多个,输出INF。
6
动态规划思想
在讲动态规划思想前,本题还使用到了经典数论Ax+By=C(x,y>0)问题:若A,B互质,则有无限个C时的方程无解。否则可能有解。推广到a,b,...,n同时成立。可以利用这个思想求是否有无穷个包子数凑不出来。
所以本题中可以类似的用a1,a2,...an表示能放的包子的个数,找到合适的x,y,.......n凑出C。如果方程有解则能凑出,否则不能凑出。至于求最大公约数可以利用辗转相除法求。
然后本题就可以类似背包问题,使用到一个boolean[] dp,下标index表示index个包子是否能够凑出。当dp[i] 即i个包子可以凑出的话,那么j个包子+第i种蒸笼恰好能放Ai个包子:arr[i]也能够凑出来即index=(j+arr[i])个包子也能够凑出来:dp[j + arr[i]] = true;动态规划的思想就体现在这,另外为了节省时间,在录入数据的同时,就可以对dp[]数据进行更新。
具体代码
import java.util.Scanner; public class _包子凑数 { public static void main(String[] args) { Scanner scanner = new Scanner(System.in); int n = scanner.nextInt();//N种蒸笼 int yueshu = 0;//最大公约数 int[] arr = new int[n + 1];//以下N行每行包含一个整数Ai boolean[] dp = new boolean[10000];//下标index表示index个包子是否能够凑出 dp[0] = true;//默认0个包子可以凑出来 //在录入数据的同时,即可对dp[index]index个包子是否能够凑出来进行更新处理。 for (int i = 1; i <= n; i++) { arr[i] = scanner.nextInt();//录入数据 /** * 下面if-else语句动态求输入的数据的最大公约数 * 求当前第i种蒸笼恰好能放Ai个包子和前一个蒸笼能放的包子个数的最大公约数 */ if (i == 1) yueshu = arr[1]; else yueshu = yue(arr[i], yueshu); //更新dp[]数组 for (int j = 0; j < 10000; j++) { /** * 如果dp[j],即j个包子能够凑出来, * 那么j个包子+第i种蒸笼恰好能放Ai个包子:arr[i]也能够凑出来 * 即index=(j+arr[i])个包子也能够凑出来。 */ if (dp[j]) dp[j + arr[i]] = true;//向后递推,动态规划的体现 } } //当最大公约数!=1 说明Ai不互质,则有无限个包子数凑不出来 if (yueshu != 1) System.out.println("INF"); else { //否则统计个数 int sum = 0; for (int i = 0; i < dp.length; i++) { if (!dp[i]) sum++; } System.out.println(sum); } } /** * 辗转相除法求a,b两个数的最大公约数 * @param a * @param b * @return */ public static int yue(int a, int b) { if (b == 0) return a; else return yue(b, a % b); } }
📝3️⃣动态规划解决最大乘积系列问题(碾压暴力枚举)
1.例题
题目描述
输入n个元素组成的子串S,你需要找出一个乘积最大的连续的子串。
如果这个最大的乘积不是正数,应输出0(表示无解)。
输入
第一行是一个整数n(1<=n<=18)。
第二行是n个整数。其中每个整数的范围是[-10,10]。
输出
输出一行包含一个整数,输出最大乘积。
测试数据
见代码。
2. 思路分析
基本思想
题目类似背包问题,,其基本思想可以使用动态规划:记住已经解决过的子问题的解。求解,即在遍历数据的时候,将遍历过程中求得的最大乘积记录下来,再继续遍历,通过每次遍历,动态的更新最大乘积,最终求得的就是最终解。
对于此类题目可以定义两个变量max和min,用来记录过程中的最大值和最小值。cur表示计算过程中的当前要计算的数据。每次计算过程中,max取Max.(cur,cur*max,cur*min)中的最大值,min取Min.(cur,cur*max,cur*min)中的最小值。
具体步骤
1) 初始化cur,max,min数据,默认都为第一个数。
2)循环计算数组元素。
3)每次循环max,min都乘以当前元素cur。并用临时变量保存。
4)计算新的max和min并重新赋值。
5)计算过程中新的最大值ans=Max(max,ans)。
6)遍历完后打印ans。
3.代码实现
import java.util.Scanner; public class Main { static long[] nums;// 用来存放数据 public static void main(String[] args) { Scanner scanner = new Scanner(System.in); int m = scanner.nextInt(); /** * long cur 当前数据 long max 最大数 long min 最小数 long ans 最终结果 */ long cur, max, min, ans = 0; // 录入数据 for (int i = 0; i < m; i++) nums[i] = scanner.nextLong(); // 初始化数据,默认都为第一个数 cur = nums[0]; max = nums[0]; min = nums[0]; for (int i = 1; i < m; i++) { cur = nums[i];// 当前处理的数 long tempmax = max * cur;// 当前数cur乘以最大数max,定义一个临时变量tempmax储存 long tempmin = min * cur;// 当前数cur乘以最小数min,定义一个临时变量tempmin储存 // 新的max在上面三个数中产生 /* 因为max在下一步求min时还要用到,因此这里定义一个临时变量储存newmax */ long newmax = Math.max(cur, Math.max(tempmax, tempmin)); min = Math.min(cur, Math.min(tempmax, tempmin)); max = newmax;// max使用完后,将新的newmax赋值给max ans = Math.max(ans, max);// 数据处理过程中的答案在ans和max中产生 } System.out.println(ans); } }
4.DP小结
注意
动态规划( Dynamic Programming )算法的核心思想是:将大问题划分为小问题进行解决,从而一步步获取最优解的处理算法
动态规划算法与分治算法类似,其基本思想也是将待求解问题分解成若干个子问题,先求解子问题,然后从这些子问题的解得到原问题的解。
与分治法不同的是,适合于用动态规划求解的问题,经分解得到子问题往往不是互相独立的。(即下一个子阶段的求解是建立在上一个子阶段的解的基础上,进行进一步的求解)
动态规划可以通过填表的方式来逐步推进,得到最优解.
📝4️⃣分治算法实现经典归并排序
1.什么是分治算法
分治法
分治法,字面意思是“分而治之”,就是把一个复杂的1问题分成两个或多个相同或相似的子问题,再把子问题分成更小的子问题直到最后子问题可以简单地直接求解,原问题的解即子问题的解的合并,这个思想是很多高效算法的基础,例如排序算法(快速排序,归并排序),傅里叶变换(快速傅里叶变换)等。
基本思想
分治法的基本思想:将一个难以直接解决的大问题,分割成一些规模较小的相同问题,以便各个击破,分而治之。
2.分治算法的体现:归并排序
归并排序
归并排序( MERGE - SORT )是利用归并的思想实现的排序方法,该算法采用经典的分治( divide - and - conquer )策略(分治法将问题分( divide )成一些小的问题然后递归求解,而治( conquer )的阶段则将分的阶段得到的各答案”修补”在一起,即分而治之)。
基本思想
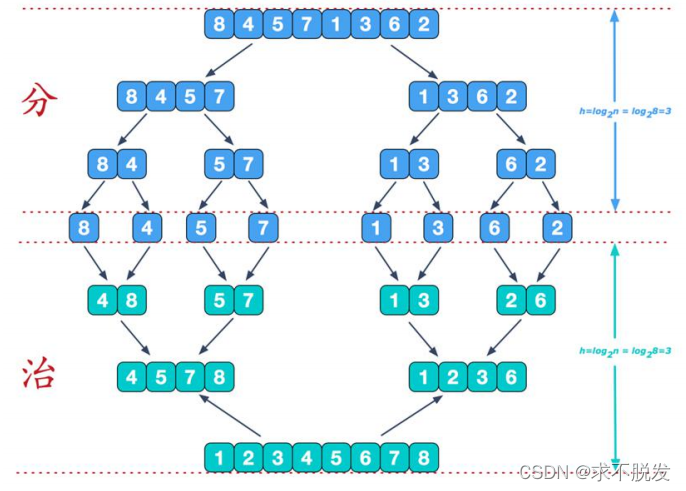
流程图(以对数组[8,4,5,7,1,3,6,2]排序为例)
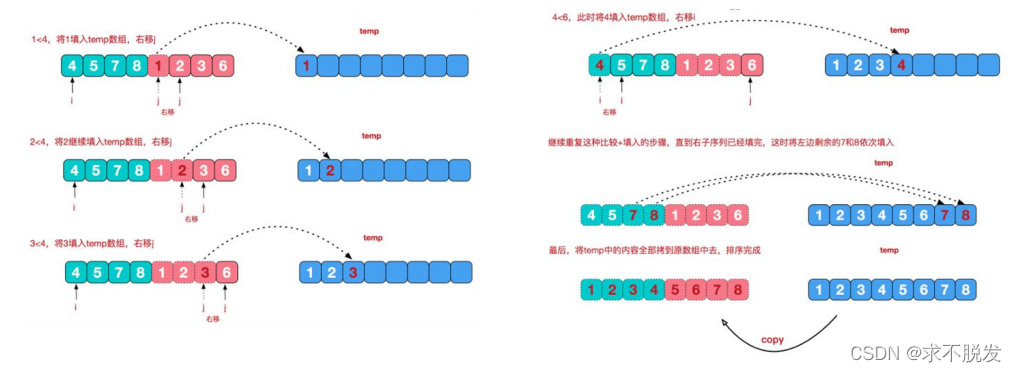
再来看看治阶段,我们需要将两个已经有序的子序列合并成一个有序序列,比如上图中的最后一次合并,要将
[4,5,7,8]和[1,2,3,6]两个已经有序的子序列,合并为最终序列[1,2,3,4,5,6,7,8],来看下实现步骤。
3.代码实现
package Sort; import java.util.Arrays; /** * 归并排序: * * 利用归并的思想实现的排序方法,该算法采用经典的分治(divide-and-conquer)策略(分治法将问题分(divide)成一些小的问题然后递归求解, * * 而治(conquer)的阶段则将分的阶段得到的各答案"修补"在一起,即分而治之)。 * @author lenovo * */ public class MergeSort { public static void main(String[] args) { int[] a= {5,8,6,3,9,8,7,1,4,21,-8,46}; int[] temp=new int[a.length]; mergeSort(a, 0, a.length-1, temp); System.out.println(Arrays.toString(a)); } public static void mergeSort(int[] arr,int left,int right,int[] temp) { if(left<right) { int mid=(left+right)/2; mergeSort(arr, left, mid, temp); mergeSort(arr, mid+1,right, temp); merge(arr, left, mid, right, temp); } } public static void merge(int[] arr,int left,int mid,int right,int[] temp) { int l=left;//左边序列的起始位置 int r=mid+1;//右边序列的起始位置 int t=0;//中间数组的当前元素下标 while(l<=mid &&r<=right ) {//左边或右边没结束 //那边小就将那边的元素放入到临时数组中 if(arr[l]<=arr[r]) { temp[t++]=arr[l++]; }else { temp[t++]=arr[r++]; } } //while循环结束,说明有一边已经遍历完毕,将另一边剩余的元素放入到临时数组中 while(l<=mid) { temp[t++]=arr[l++]; } while(r<=right) { temp[t++]=arr[r++]; } //将临时数组中的有序序列copy到原数组中 t=0; int templeft=left; while(templeft<=right) { arr[templeft++]=temp[t++]; } } }
📝5️⃣枚举算法经典日期问题详解
枚举算法
枚举算法是我们在日常中使用到的最多的一个算法,它的核心思想就是:枚举所有的可能。 枚举法的本质就是从所有候选答案中去搜索正确的解。
使用该算法需要满足两个条件:(1)可预先确定候选答案的数量;(2)候选答案的范围在求解之前必须有一个确定的集合。
枚举算法简单粗暴,他暴力的枚举所有可能,尽可能地尝试所有的方法。虽然枚举算法非常暴力,而且速度可能很慢,但确实我们最应该优先考虑的!因为枚举法变成实现最简单,并且得到的结果总是正确的。
日期问题
题目链接
题目描述
小明正在整理一批历史文献。这些历史文献中出现了很多日期。小明知道这些日期都在1960年1月1日至2059年12月31日。令小明头疼的是,这些日期采用的格式非常不统一,有采用年/月/日的,有采用月/日/年的,还有采用日/月/年的。更加麻烦的是,年份也都省略了前两位,使得文献上的一个日期,存在很多可能的日期与其对应。
比如02/03/04,可能是2002年03月04日、2004年02月03日或2004年03月02日。
给出一个文献上的日期,你能帮助小明判断有哪些可能的日期对其对应吗?输入
一个日期,格式是"AA/BB/CC"。 (0 <= A, B, C <= 9)
输出
输出若干个不相同的日期,每个日期一行,格式是"yyyy-MM-dd"。多个日期按从早到晚排列。
样例
输入 02/03/04 输出 2002-03-04
2004-02-03
2003-03-02
枚举思想
日期问题一般思路都是根据我们的尝试枚举判断日期是否合法等,例如月份1-12,日期1-31或闰年的判断等等。重点在于枚举出所有日期的情况去判断,找出正确答案,避免重复枚举或缺项。
具体代码
package Test; import java.util.Iterator; import java.util.Scanner; import java.util.TreeSet; public class _日期问题 { public static void main(String[] args) { Scanner scanner = new Scanner(System.in); String data = scanner.next(); String[] str = data.split("/");//以字符 ' / ' 分割成字符串数组 TreeSet<String> ans = new TreeSet<String>();//存放正确答案的集合,利用set集合去重 // 01/02/03 //枚举三种情况日/月/年 ,年/月/日,月/日/年 String case1 = f(str[0], str[1], str[2]); String case2 = f(str[2], str[0], str[1]); String case3 = f(str[2], str[1], str[0]); //如果case字符串合法则加入结果集 if (case1.length() > 0) ans.add(case1); if (case2.length() > 0) ans.add(case2); if (case3.length() > 0) ans.add(case3); //遍历输出结果 Iterator<String> iterator = ans.iterator(); for (String anser : ans) { System.out.println(anser); } } /** * 判断是否合法, * @param year * @param month * @param day * @return 空字符串"" 表示不合法 */ private static String f(String year, String month, String day) { int _year = Integer.parseInt(year); int _month = Integer.parseInt(month); int _day = Integer.parseInt(day); if (_year <= 59)//0-59表示2000年以后,要加上2000 _year += 2000; else //60-99表示1960 - 1999年,加上1900 _year += 1900; if (_month > 12 || _month < 1)//判断月份是否合法 <1或者>12均不合法 return ""; if (_day > 31 || _day < 1)//判断日期是否合法<1或者>31均不合法 return ""; /** * 接下来判断每个月份对应的日期是否合法(前面已经保证月份1-31) * 1,3,5,7,8,10,12每个月固定31天,一定合法 * 因此要判断其他月份的时候是否合法 */ if(_month == 2) { //闰年>29不合法 if ((_year % 4 == 0 && _year % 100 != 0) || _year % 400 == 0) { if (_day > 29) return ""; } }else { //其他月份>30不合法 if (_day > 30) return ""; } //月份和日期不足10 要补0 if (_month < 10) { month = "0" + _month; } if (_day < 10) { day = "0" + _day; } return _year + "-" + month + "-" + day; } }
📝6️⃣BFS广搜解决迷宫问题
1.例题
题目描述
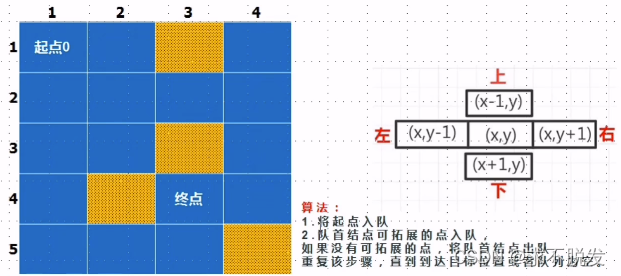
迷宫由 n 行 m 列的单元格组成,每个单元格要么是空地,要么是障碍物。其中1表示空地,可以走通,2表示障碍物。给定起点坐标startx,starty以及终点坐标endx,endy。现请你找到一条从起点到终点的最短路径长度。
输入
第一行包含两个整数n,m(1<=n,m<=1000)。接下来 n 行,每行包含m个整数(值1或2),用于表示这个二维迷宫。接下来一行包含四个整数startx,starty,endx,endy,分别表示起点坐标和终点坐标。
输出
如果可以从给定的起点到终点,输出最短路径长度,否则输出NO。
测试数据
输入
5 4
1 1 2 1
1 1 1 1
1 1 2 1
1 2 1 1
1 1 1 2
输出7
2. 思路分析
基本思想
这道题属于一道较为经典的BFS图的广度优先搜索算法例题。类似于一个分层搜索的过程,广度优先搜索需要使用一个队列以保持访问过的结点的顺序,以便按这个顺序访问这些结点的邻接结点。即从给定的起点开始向四周扩散,判断是否能够到达终点,如果不能,就继续BFS广搜,直到能够到达终点或者将所有结点遍历完一遍。在搜索前定义一个flag变量用来标记是否到达终点。
具体步骤
1)访问初始结点 p 并标记结点 p 为已访问。
2)结点 p 入队列
3)当队列非空时,继续执行,否则算法结束。
4)出队列取得队头结点 first
5)查找结点 first 的第一个方向的邻接结点 newp 。
6)若结点 first 的邻接结点 newp 不存在,则转到步骤3:否则循环执行以下三个步骤:
6.1若结点 newp 尚未被访问并且可以走通,则访问结点 newp 并标记为已访问。
6.2结点 newp 入队列
6.3查找结点 first 的继 newp 邻接结点后的下个邻接结点 newp .转到步骤6代码实现
import java.util.LinkedList; import java.util.Scanner; public class Main { //n*m的地图,(startx,starty)起点坐标,(endx,endy)终点坐标 static int n, m, startx, starty, endx, endy; static int[][] map;//地图 static boolean[][] vistied;//标记当前点是否已经走过 static int[][] step = { { 1, 0 }, { 0, 1 }, { -1, 0 }, { 0, -1 } }; /* * 上下左右移动遍历搜索 1 ,0 表示 x + 1 ,y + 0 向右移动,其他同理 如果为八向连通 则加上, { 1, 1 }, { 1, -1 }, { * -1, 1 }, { -1, -1 } 代表斜向移动 */ public static void main(String[] args) { Scanner sc = new Scanner(System.in); n = sc.nextInt(); m = sc.nextInt(); map = new int[n + 2][m + 2];//+2是为了防止点在边界时,四方向移动造成下标出现-1越界。 vistied = new boolean[n + 2][m + 2]; // 录入数据图 下标(1~n)*(1~m) for (int i = 1; i <= n; i++) { for (int j = 1; j <= m; j++) { map[i][j] = sc.nextInt(); } } //录入起点和终点坐标 startx = sc.nextInt(); starty = sc.nextInt(); endx = sc.nextInt(); endy = sc.nextInt(); bfs(startx, starty);//BFS广搜 } private static void bfs(int x, int y) { point p = new point(x, y, 0);//初始化point类封装x,y坐标以及step步数 LinkedList<point> queue = new LinkedList<point>();//需要用到的队列 queue.add(p);//将当前点入队列 vistied[x][y] = true;//标记成已访问 boolean flag = false;//是否达到终点标记 //只要队列不为空,就说明还有路可走 while (!queue.isEmpty()) { point first = queue.getFirst();//取出队列的第一个点 if (first.x == endx && first.y == endy) {//判断当前点是否与终点坐标重合 System.out.println(first.step);//打印需要走的步数 flag = true;//标记已经到达终点 break;//结束BFS } //未到达终点则进行上下左右四个方向移动 for (int i = 0; i < 4; i++) { //横纵坐标变换实现位置移动 int newx = first.x + step[i][0]; int newy = first.y + step[i][1]; int newstep = first.step + 1;//每一动一次步数要+1 //判断移动后的新位置可以走,并且没走过 if (map[newx][newy] == 1 && vistied[newx][newy] == false) { point newp = new point(newx, newy, newstep);//封装数据 queue.add(newp);//入队列 vistied[newx][newy] = true;//标记已经走过 } } queue.removeFirst();//四个方向判断完成后,要将队首元素出列 } if (!flag)//如果无法到达终点提示 System.out.println("NO"); } } //定义一个位置点的class,方便封装数据入队列 class point { int x; int y; int step;//从起点走到当前点需要走的步数 public point(int x, int y, int step) { this.x = x; this.y = y; this.step = step; } }3.BFS小结
求解思路:
将队首结点可拓展的点入队,如果没有可拓展的点,将队首结点出队。重复以上步骤,直到到达目标位置或者队列为空。
注意
bfs先找到的一定是最短的。但是如果是加权边的话这样就会出问题了,bfs传回的是经过 边数 最少的解,但是因为加权了,这个解到根节点的 距离 不一定最短。 比如1000+1000是只有两段,1+1+1+1有4段,由于bfs返回的经过边数最少的解,这里会返回总长度2000的那个解,显然不是距离最短的路径 。BFS 运用到了队列。
📝7️⃣DFS连通块问题
前言
连通块问题属于图的深度优先遍历dfs,本文章通过求连通块的个数简单案例,来介绍dfs解决连通块问题。
例题链接
例题中给到的是char类型地图,' . ' 代表不通路,' W ' 代表可连通,具体情况根据题目给的进行修改。
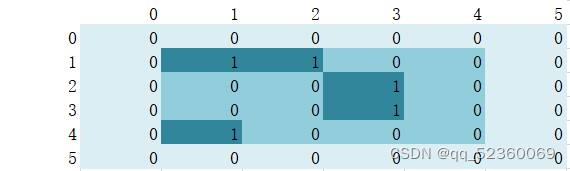
什么是连通块
如图整个表格为一个5*5二维数组,用来表示整个地图,白色填充为二维数组下标,最外层浅绿色代表地图的边界(为什么创建边界下文有提到),较为深颜色的为存放数据的二维数组,即下标(1~4)*(1~4)。而颜色最深的块就是连通块,图中给出的就有三个连通块(上下左右连通,不考虑斜对连通)。
具体思路
除了行数列数以及开辟二维数组地图,还需要一个与地图同样大小的二维数组visitied,用来表示当前节点是否已经被访问过了。具体思路同图的dfs类似,当遍历到一个结点为1表示该节点可以连通(根据题目给的可能不同)并且没被访问过就进行深度遍历。
具体看代码。
代码
import java.util.Scanner; /** * 注意本例题中 * char[][]map地图 值为' . ' 代表不通,' W '代表可以连通 * int[][] visitied访问标记,初始值0未访问,1已访问 * @author lenovo * */ public class Main { static int n,m,ans; static char[][] map; static int[][] vistied; static int[][] step= {{1,0},{0,1},{-1,0},{0,-1}}; /* * 上下左右移动遍历搜索 * 1 ,0 表示 x + 1 ,y + 0 向右移动,其他同理 * 如果为八向连通 则加上, { 1, 1 }, { 1, -1 }, { -1, 1 }, { -1, -1 } 代表斜向移动 */ public static void main(String[] args) { Scanner sc=new Scanner(System.in); n=sc.nextInt(); m=sc.nextInt(); map=new char[n+2][m+2]; vistied=new int[n+2][m+2]; //初始化地图,创建边界 for (int i = 0; i <= n+1; i++) { map[i][0] = '.'; map[i][m+1] = '.'; } for (int i = 0; i <= m+1; i++) { map[0][i] = '.'; map[n+1][i] = '.'; } //录入数据图(1~n)*(1~m) for (int i = 1; i <= n; i++) { String s=sc.next(); int k=0; for (int j = 1; j <= m; j++) { map[i][j]=s.charAt(k++); } } //从1-n 1-m一次遍历整张数据图 for (int x = 1; x <=n; x++) { for (int y =1; y <=m; y++) { //如果当前节点为'W'可以连通 并且为被访问则说明存在一个连通块 if(vistied[x][y] ==0 && map[x][y] == 'W') { ans++;//连接块数量+1 vistied[x][y] = 1;//当前节点标记为已经访问,以免重复判断 dfs(x,y);//进行深度优先遍历,将与其连通的所有节点都标记为已经访问。 //遍历完后从(1,1)到下一个节点(1,2)继续遍历,一次类推,直到所有节点全遍历完。 } } } System.out.println(ans); } private static void dfs(int x, int y) { /** * step.length - 1 = 3 * 0 1 2 3 四步代表上下左右均走一遍 */ for (int i = 0; i <=(step.length - 1); i++) { int newx=x+step[i][0]; //x移动 int newy=y+step[i][1];//y移动 //如果移动后的节点 为 'W'可连通,并且未访问,则以移动后的节点为起点继续移动 if(map[newx][newy] =='W' && vistied[newx][newy] ==0) { vistied[newx][newy] = 1;//标记为已访问 dfs( newx, newy); } } } }注意
在实际应用时,为了防止当结点位于边界时,例如结点下标为(0,0),其左结点下标为(-1,0),这时-1会越界。因此开辟二维数组的大小总是比题目中给到的n*m多两行,即开辟(n+2)*(m+2)大小的二维数组。
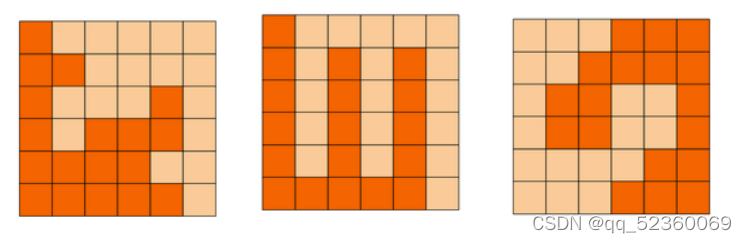
📝8️⃣DFS方格分割
问题描述
6x6的方格,沿着格子的边线剪开成两部分。
要求这两部分的形状完全相同。
试计算:
一共有多少种不同的分割方法。
注意:旋转对称的属于同一种分割法。
请提交该整数,不要填写任何多余的内容或说明文字。
具体思路
既然要求剪下来的两部分完全相同,那么剪的路线一定通过图的中心点,并且分割线一定关于中心点对称。因此可以以图中的交点为元素,将6*6的方格转换成7*7的网格,从中心点开始对称的向边界dfs深度遍历,即从中心点开始向上下左右标记的同时,对称的位置也要标记。例如(3,3)->(4,3)的同时,(3,3) -> (2,3)也要标记。当遍历到网格的边界即剪完成,然后进行回溯。
代码
public class _方格分割 { static int[][] map = new int[7][7];//网格线 static int[][] v = new int[7][7];//标记当前点是否访问过,即当前位置是否已经剪过 static int ans = 0;//最终答案 static int[][] step = { { 1, 0 }, { 0, 1 }, { -1, 0 }, { 0, -1 } };//上下左右坐标变换 static void dfs(int x, int y) { // 首先判断是否到达边界 if (x == 0 || y == 0 || x == 6 || y == 6) { ans++; return; } // 对称标记已经剪过该位置 v[x][y] = 1; v[6 - x][6 - y] = 1; // 依次上下左右剪 for (int i = 0; i < 4; i++) { int newx = x + step[i][0]; int newy = y + step[i][1]; // 判断当前位置是否剪过并且没有越界 if (v[newx][newy] == 0 && newx >= 0 && newx <= 6 && newy >= 0 && newy <= 6) { dfs(newx, newy);// 向下一步剪 } } // 剪完过后记得回溯 v[x][y] = 0; v[6 - x][6 - y] = 0; } public static void main(String[] args) { dfs(3, 3);// 从(3,3)开始中心对称位置剪 System.out.println(ans / 4);// 因为中心对称剪的话,每条路线可绕中心点旋转一周,因此一条路线重复了4次,所以要将最后结果/4 } }
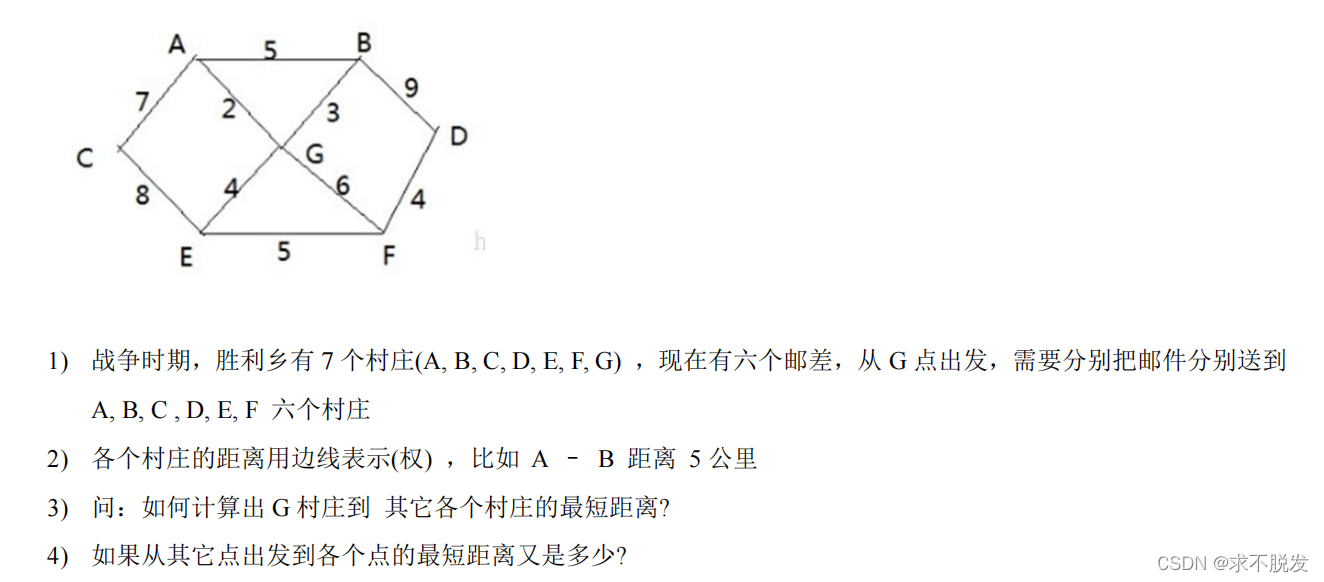
📝9️⃣迪杰斯特拉 (Dijkstra)算法求最短路径问题
算法介绍
迪杰斯特拉( Dijkstra )算法是典型最短路径算法,用于计算一个结点到其他结点的最短路径。它的主要特点是以起始点为中心向外层层扩展(广度优先搜索思想),直到扩展到终点为止。
应用实例
算法步骤
1)设置出发顶点为 v ,顶点集合 VfvI ,v2, vi .), v 到 V 各顶点的距离构成距离集合 Dis , Dis ( dI ,d2, di .), Dis 集合记录着 v 到图中各顶点的距离(到自身可以看作0, v 到 vi 距离对应为 di )
2)从 Dis 中选择值最小的 di 并移出 Dis 集合,同时移出 V 集合中对应的项点 vi ,此时的 v 到 vi 即为最短路径
3)更新 Dis 集合,更新规则为:比较 v 到 V 集合中顶点的距离值,与 v 通过 vi 到 V 集合中顶点的距离值,保留
值较小的一个(同时也应该更新顶点的前驱节点为 vi ,表明是通过 vi 到达的)
4)重复执行两步骤,直到最短路径顶点为目标顶点即可结束。代码实现
import java.util.Arrays; public class _最短路{ static int[] vis;//标记已经访问的顶点 0未访问 1 访问 static int[] dis;//出发顶点到各个下标对应顶点的最短距离 static int[] pre;//每个下标对应的上一个顶点下标 static char[] vertex;//顶点 static int[][] matrix;//邻接矩阵 public static void main(String[] args) { vertex= new char[]{'A','B','C','D','E','F','G'}; matrix = new int[vertex.length][vertex.length]; chushihua(matrix);//初始化邻接矩阵 djstl(vertex.length,6);//调用算法 } public static void djstl(int length,int start) { vis=new int[length]; dis=new int[length]; pre=new int[length]; Arrays.fill(dis, 9999);//初始化距离为较大值 dis[start] = 0;//初始化出发顶点到自身的距离0 /* 先将起始点到与其连通的顶点的路径及pre前一个顶点进行更新*/ update(start); //在以与起始点相连的顶点为起点 更新距离和路径 for (int i = 1; i < vertex.length; i++) { int minIndex = -1; int mindis=9999; //找到一个最短路径 for (int j = 0; j < vertex.length; j++) { if(vis[j]==0 && dis[j] < mindis) { minIndex = j; mindis = dis[j]; } } vis[minIndex] = 1; update(minIndex);//继续更新 } System.out.println(Arrays.toString(dis)); } /** * 以index顶点向下查找!!!以起点start到index附近的邻接结点的最短路径!!! * @param index */ public static void update(int index) { vis[index] = 1;//index标记为已访问 int len= 0;//len:从start顶点到index顶点的距离+上从index再到i顶点的距离 //循环遍历每个邻接结点顶点,找到真正意义上的最短路径 for (int i = 0; i < matrix[index].length; i++) { //记录从start顶点到index顶点的距离+上从index再到i顶点的距离 len = dis[index] + matrix[index][i]; //将dis[i] 即从start直接到i 的距离 与len进行比较 if(vis[i] == 0 && len < dis[i]) { dis[i] = len;//更新最短路径 pre[i] = index;//更新前置顶点 } } } /** * 初始化邻接矩阵 * @param matrix */ public static void chushihua(int[][] matrix) { final int N = 9999; matrix[0]=new int[]{N,5,7,N,N,N,2}; matrix[1]=new int[]{5,N,N,9,N,N,3}; matrix[2]=new int[]{7,N,N,N,8,N,N}; matrix[3]=new int[]{N,9,N,N,N,4,N}; matrix[4]=new int[]{N,N,8,N,N,5,4}; matrix[5]=new int[]{N,N,N,4,5,N,6}; matrix[6]=new int[]{2,3,N,N,4,6,N}; } }

- 点赞
- 收藏
- 关注作者
评论(0)