Java并行流指北

【摘要】 Java并行流,方便了 并发操作,但是不注意可能会导致问题。如 最大线程数,怎么控制并发数,类加载器,线程上下文变化,ForkJoinPool 的 execute、submit、invoke 方法的区别 等。
一、前言
- Java并行流,方便了 并发操作,但是不注意可能会导致问题。
- 如 最大线程数,怎么控制并发数,类加载器,线程上下文变化,ForkJoinPool 的 execute、submit、invoke 方法的区别 等。
- 注意:本文以 openjdk 11.0.10 为例,没有特殊说明时,都是指 ForkJoinPool.commonPool()
二、注意点
1. 并行度
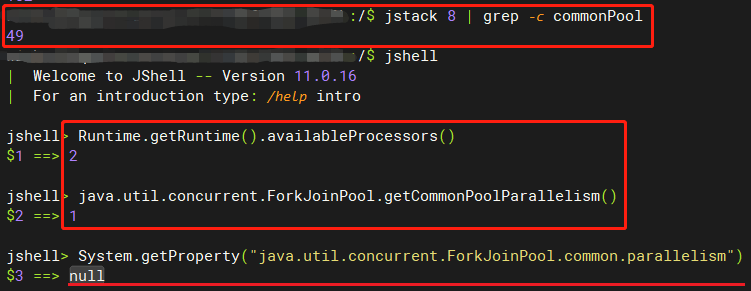
- ***并行度 不等于 最大线程数(maximumPoolSize)***,下图 commonPool 有49个线程,但是 并行度为1
- 默认的 并行度为 CPU核数 - 1,最小为 1
- 可通过 -Djava.util.concurrent.ForkJoinPool.common.parallelism=数量 设置

2. 容器里面的并行度
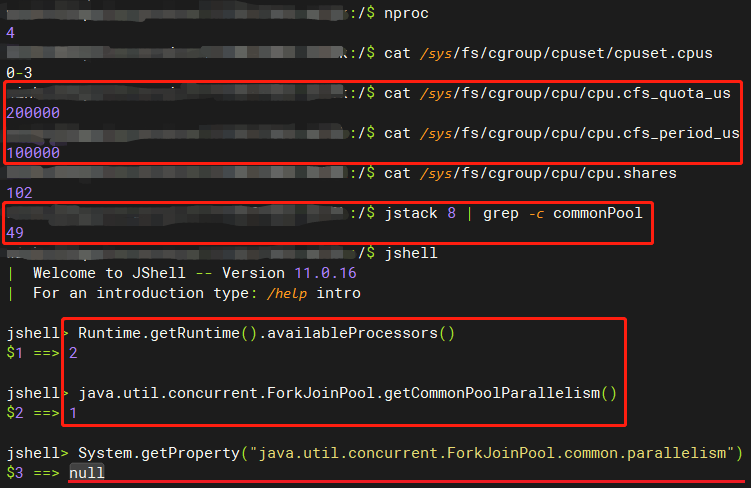
- 下图中,/sys/fs/cgroup/cpu/cpu.cfs_quota_us 除以 /sys/fs/cgroup/cpu/cpu.cfs_period_us = cpu核数
- 不等于 nproc,更不等于 获得宿主机的 lscpu | grep ‘CPU(s):’
3. 最大线程数
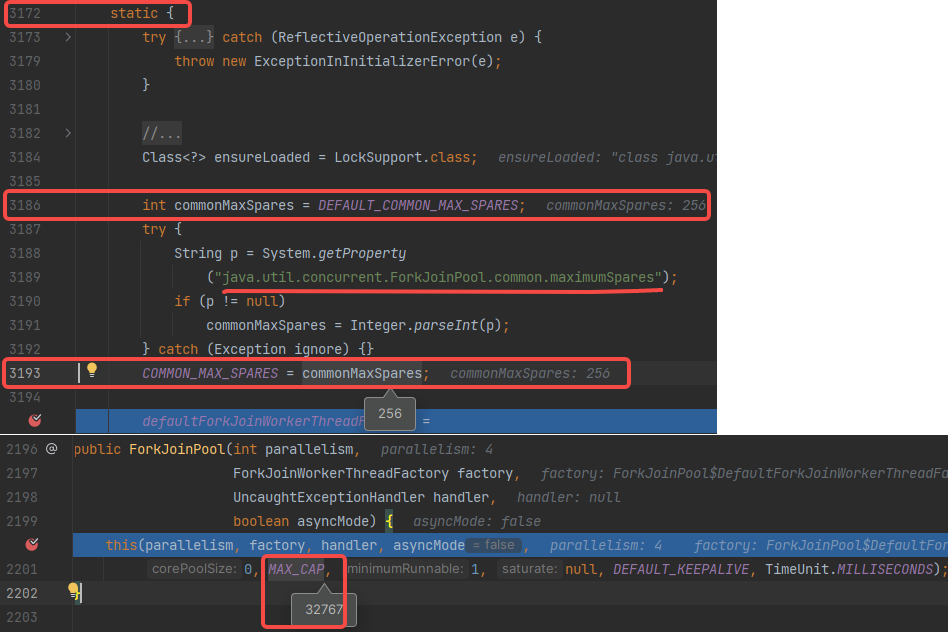
- 并行度 不等于 最大线程数(maximumPoolSize)
- 即使 并行度 parallelism 为1,还有 备用线程(maximumPoolSize、COMMON_MAX_SPARES)
- commonPool 默认 256,自定义 ForkJoinPool() 默认 32767。这样看,比较少会出现 线程数不够的情况。
4. 并发太大,压垮后端
- 假如 ForkJoinPool.commonPool() 线程比较多,并行流集合的元素也比较多时,给下游较大压力
- jstack pid | grep -c commonPool
5. 线程上下文变化
如:获取不到用户信息了,可以获取到用户信息以后,传到并行流使用
final String deviceUdid = RequestUtils.getDeviceUdid();
data.parallelStream().forEach(d -> {
// use deviceUdid instead of RequestUtils.getDeviceUdid() do something
});
6. ForkJoinPool 的 execute、submit、invoke 方法的区别
- 有些简单的任务,不想单独创建线程池,可以用 ForkJoinPool.commonPool()
- execute():异步执行,没有返回值,不能等待执行完成
- submit():异步执行,返回 ForkJoinTask,需增加 .join() 等待完成
- invoke():等于 submit() + join()
7. spring boot使用Java并行流发送kafka消息报错
- 类加载器不一样,详见 spring boot 使用 Java 并行流发送 kafka 消息报错
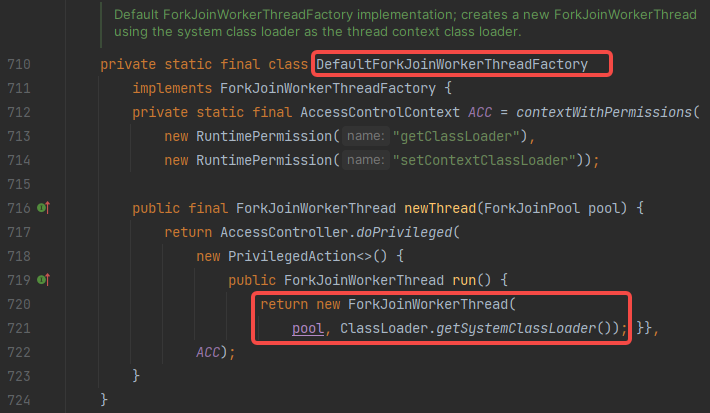
- 使用 spring-boot-maven-plugin 打包以后,依赖在 jar里面自定义位置(BOOT-INF/lib/),使用 org.springframework.boot.loader.LaunchedURLClassLoader 加载
- ForkJoinPool.commonPool 默认使用 DefaultForkJoinWorkerThreadFactory,用的 系统ClassLoader,所以 并行流加载不到依赖的 class
- 可通过 -Djava.util.concurrent.ForkJoinPool.common.threadFactory 设置 自定义线程工厂,使用当前 ClassLoader 解决
8. 自定义并行流线程池
参考 concurrency - Custom thread pool in Java 8 parallel stream - Stack Overflow
- 方案一(各种情况都有效)
CompletableFuture.runAsync(list.parallelStream().forEach(), new ForkJoinPool(2)).join()
- 方案二(部分场景似乎没有效果)
// 第4个参数 asyncMode,默认 false,设置为 true 适用于 FIFO
ForkJoinPool forkJoinPool = new ForkJoinPool(2, pool -> new ForkJoinWorkerThread(pool) {
}, null, false);
forkJoinPool.invoke(() -> list.parallelStream().forEach());
9. 控制并发数
- 可考虑把 集合切分成需要的份数,然后 parallelStream()
List<String> list = List.of("a", "b", "c");
CollUtil.split(list, list.size() / 2 + 1).parallelStream().forEach(b -> {
b.stream().forEach(System.out::println);
});
10. 顺序消费
- 如 forEachOrdered 会导致没有并发效果
- 需要并行,还要使用输入顺序的,可考虑把 集合切分成需要的份数,然后 parallelStream()
三、总结
- Java并行流,方便了 并发操作,同时需要 了解底层实现、限制,避免不注意可能导致的问题
- 参考:ForkJoinPool 源码分析 - 竺旭东 - 博客园 (cnblogs.com)
- https://github.com/agile6v/container_cpu_detection
- https://stackoverflow.com/questions/21163108/custom-thread-pool-in-java-8-parallel-stream
本文遵守【CC BY-NC】协议,转载请保留原文出处及本版权声明,否则将追究法律责任。
本文首先发布于 https://www.890808.xyz/ ,其他平台需要审核更新慢一些。


【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)