Java 正则表达式

第一章 概述
正则表达式,又称规则表达式,(Regular Expression,在代码中常简写为regex、regexp或RE),是一种【文本模式(Pattern)】。
正则表达式使用单个字符串来描述、匹配具有相同规则的字符串,通常被用来检索、替换那些符合某个模式(规则)的文本。正则表达式的核心功能就是处理文本。
正则表达式并不仅限于某一种语言,但是在每种语言中有细微的差别。
第二章 正则表达式基础语法
一、元字符
元字符是构造正则表达式的一种基本元素。
-
.:匹配除换行符以外的任意字符 -
\w:匹配字母或数字或下划线或汉字 -
\s:匹配任意的空白符 -
\d:匹配数字 -
\b:匹配单词的开始或结束 -
^:匹配字符串的开始 -
$:匹配字符串的结束
举例:
-
匹配8位数字的QQ号码:
^\d\d\d\d\d\d\d\d$ -
匹配1开头11位数字的手机号码:
^1\d\d\d\d\d\d\d\d\d\d$
二、重复限定符
正则表达式提供了对重复字符进行简写的方式:
-
*:重复零次或更多次 -
+:重复一次或更多次 -
?:重复零次或一次 -
{n}:重复n次 -
{n,}:重复n次或更多次 -
{n,m}:重复n到m次
有了这些限定符之后,我们就可以对之前的正则表达式进行改造了,比如:
-
匹配8位数字的QQ号码:
^\d{8}$ -
匹配1开头11位数字的手机号码:
^1\d{10}$ -
匹配银行卡号是14~18位的数字:
^\d{14,18}$ -
匹配以a开头的,0个或多个b结尾的字符串:
^ab*$
三、分组
限定符是作用在与他相邻的最左边的一个字符,那么问题来了,如果我想要ab同时被限定那怎么办呢?
正则表达式中用小括号()来做分组,也就是括号中的内容会作为一个整体。
如匹配字符串中包含0到多个ab开头:^(ab)*
四、转义
正则提供了转义的方式,也就是要把这些元字符、限定符或者关键字转义成普通的字符,做法很简答,就是在要转义的字符前面加个斜杠,也就是\即可。
匹配字符串中包含0到多个(ab)开头:^(\(ab\))*
匹配一个字符*:\*
五、条件
回到我们刚才的手机号匹配,我们都知道:国内号码都来自三大运营商,它们都有属于自己的号段。
比如联通有130/131/132/155/156/185/186/145/176等号段,假如让我们匹配一个联通的号码,那按照我们目前所学到的正则,应该无从下手的,因为这里包含了一些并列的条件,也就是“或”,那么在正则中是如何表示“或”的呢?
正则用符号 | 来表示或,也叫做分支条件,当满足正则里的分支条件的任何一种条件时,都会当成是匹配成功。
那么我们就可以用或条件来处理这个问题:
^(130|131|132|155|156|185|186|145|176)\d{8}$
六、区间
正则提供一个元字符中括号 [] 来表示区间条件。
-
限定0到9 可以写成[0-9]
-
限定A-Z 写成[A-Z]
-
限定某些数字 [165]
那上面的正则我们还改成这样:
^((13[0-2])|(15[56])|(18[5-6])|145|176)\d{8}$
七、反义
前面说到元字符的都是要匹配什么什么,当然如果你想反着来,不想匹配某些字符,正则也提供了一些常用的反义元字符:
| 元字符 | 解释 |
|---|---|
| \W | 匹配任意不是字母,数字,下划线,汉字的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开头或结束的位置 |
| [^x] | 匹配除了x以外的任意字符 |
| [^aeiou] | 匹配除了aeiou这几个字母以外的任意字符 |
八、常见的正则表达式
-
匹配中文字符的正则表达式:
[\u4e00-\u9fa5]
匹配形式:My name is Mary! -
匹配Email地址的正则表达式:
^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$
匹配形式: 51012324@qq.com 、abzzyi@163.com,yfavve@126.com -
匹配国内电话号码:
\d{3}-\d{8}|\d{4}-\d{7} -
匹配形式: 0511-4405222 或 021-87888822
-
匹配腾讯QQ号:
[1-9][0-9]{4,}
匹配形式:510180222 -
匹配身份证:
(^\d{15}$)|(^\d{18}$)|(^\d{17}(\d|X|x)$
匹配形式:142228199108252125 -
匹配ip地址:
\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}
匹配形式:127.0.0.1 -
匹配国内的手机号:
^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\d{8}$
匹配形式:1388888888
第三章Java正则表达式
小知识:
有些语言中,\ 表示:我就是一个普通的【反斜杠】,请不要给我任何特殊的意义。
在 Java 中,\ 表示:我不是一个普通的【反斜杠】,我必须对紧随其后的字符进行转义,如果想将我视为普通反斜杠,请转义我。
我们可以看以下的输出内容:
System.out.print("\\"); // 输出为 \
System.out.print("\\\\"); // 输出为 \\
Java中正则表达式的执行流程:
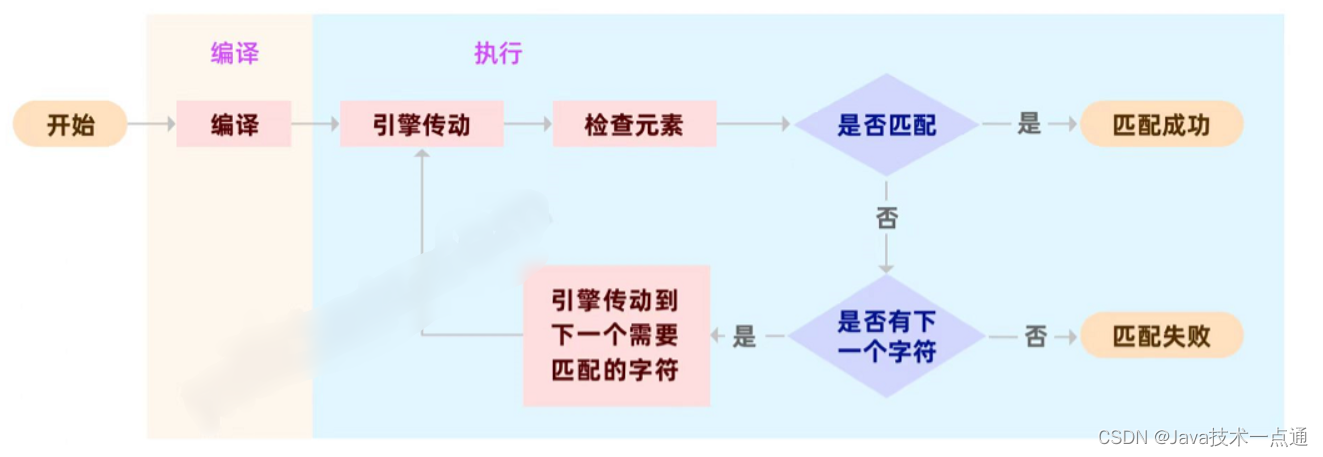
一、正则表达式实例
java.util.regex 包主要包括以下三个类:
-
Pattern 类:
正则表达式的编译表示形式。若要使用正则表达式必须将其【编译到此类】的实例中。然后,可以使用生成的模式对象创建 Matcher 对象。 -
Matcher 类:
Matcher 对象是对输入字符串进行【解释和匹配】操作的引擎。与Pattern 类一样,Matcher 也没有公共构造方法。你需要调用 Pattern 对象的 matcher 方法来获得一个 Matcher 对象。 -
PatternSyntaxException:
PatternSyntaxException 是一个非强制异常类,它表示一个正则表达式模式中的语法错误。
以下实例中使用了正则表达式 . *china.*用于查找字符串中是否包了 china子串:
@Test
public void testRegex{
String content = "I am itnanls,I'm from ydlclass.";
String pattern = ".*itnanls.*";
boolean isMatch = Pattern.matches(pattern, content);
System.out.println(isMatch);
}
运行结果:
true
二、Matcher 类的方法
1. 匹配方法
该方法可以精确表明输入字符串中在哪能找到与之匹配的内容:
| 序号 | 方法及 | 说明 |
|---|---|---|
| 1 | start() | 返回匹配的起始索引 |
| 2 | start(int group) | 返回在匹配操作期间,由给定组所捕获的子序列的起始索引 |
| 3 | end() | 返回匹配字符末尾索引 |
| 4 | end(int group) | 返回在匹配操作期间,由给定组所捕获的子序列的末尾索引 |
下面是一个对单词 “cat” 出现在输入字符串中出现次数进行计数的例子:
@Test
public void testStart() {
String regex = "cat";
String content = "cat cat dog dog cat";
Pattern pattern = Pattern.compile(regex);
Matcher m = pattern.matcher(content); // 获取 matcher 对象
int count = 0;
while (m.find()) {
count++;
System.out.println("Match number " + count);
System.out.println("start(): " + m.start());
System.out.println("end(): " + m.end());
}
}
运行结果如下:
Match number 1
start(): 0
end(): 3
Match number 2
start(): 4
end(): 7
Match number 3
start(): 16
end(): 19
2. 查找方法
查找方法用来检查输入字符串并返回一个布尔值,表示是否找到该模式:
| 序号 | 方法 | 说明 |
|---|---|---|
| 1 | lookingAt() | 返回目标字符串前面部分与 Pattern 是否匹配 |
| 2 | find() | 返回目标字符串中是否包含与 Pattern 匹配的子串 |
| 3 | find(int start) | 从指定索引开始匹配查找。 |
| 4 | matches() | 尝试将整个区域与模式匹配 |
matches 和 lookingAt 方法都用来尝试匹配一个输入序列模式。它们的不同是 matches 要求整个序列都匹配,而lookingAt 不要求。
lookingAt 方法虽然不需要整句都匹配,但是需要从第一个字符开始匹配。
实例:
@Test
public void testMatches() {
String regex = "Mary";
String content1 = "Mary";
String content2 = "Mary is very handsome !";
String content3 = "My name is Mary.";
Pattern pattern = Pattern.compile(regex);
Matcher matcher1 = pattern.matcher(content1);
Matcher matcher2 = pattern.matcher(content2);
Matcher matcher3 = pattern.matcher(content3);
System.out.println("matches1(): " + matcher1.matches());
System.out.println("lookingAt1(): " + matcher1.lookingAt());
System.out.println("matches2(): " + matcher2.matches());
System.out.println("lookingAt2(): " + matcher2.lookingAt());
System.out.println("matches3(): " + matcher3.matches());
System.out.println("lookingAt3(): " + matcher3.lookingAt());
}
运行结果如下:
matches(): true
lookingAt(): true
matches(): false
lookingAt(): true
matches(): false
lookingAt(): false
3. 替换方法
替换方法是替换输入字符串里文本的方法:
| 序号 | 方法 | 说明 |
|---|---|---|
| 1 | public String replaceAll(String replacement) | 替换模式与给定替换字符串相匹配的输入序列的每个子序列。 |
| 2 | public String replaceFirst(String replacement) | 替换模式与给定替换字符串匹配的输入序列的第一个子序列。 |
| 3 | public Matcher appendReplacement(StringBuffer sb, String replacement) | 实现非末尾的添加和替换步骤。 |
| 4 | public StringBuffer appendTail(StringBuffer sb) | 实现末尾的添加和替换步骤。 |
下面的例子来解释replaceAll和replaceFirst:
@Test
public void testReplace(){
String regex = "Mary";
String context = "My name is Mary, Mary is very handsome. ";
String replacement = "Lucy";
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(context);
String result1 = m.replaceAll(replacement);
System.out.println(result1);
String result2 = m.replaceFirst(replacement);
System.out.println(result2);
}
运结果 如下:
My name is Lucy, itlils is very handsome.
My name is Lucy, itnanls is very handsome.
下面的例子来解释appendReplacement和appendTail:
@Test
public void testAppend() {
String REGEX = "a*b";
String INPUT = "aabfooaabfooabfooabkkk";
String REPLACE = "-";
Pattern p = Pattern.compile(REGEX);
// 获取 matcher 对象
Matcher m = p.matcher(INPUT);
StringBuffer sb = new StringBuffer();
m.find();
m.appendReplacement(sb, REPLACE);
System.out.println(sb);
m.find();
m.appendReplacement(sb, REPLACE);
System.out.println(sb);
m.appendTail(sb);
System.out.println(sb);
}
运行结果如下:
-
-foo-
-foo-fooabfooabkkk
4. PatternSyntaxException 类的方法
PatternSyntaxException 是一个异常类,它指示一个正则表达式模式中的语法错误。
PatternSyntaxException 类提供了下面的方法来帮助我们查看发生了什么错误。
| 序号 | 方法 | 说明 |
|---|---|---|
| 1 | getDescription() | 获取错误的描述。 |
| 2 | getIndex() | 获取错误的索引。 |
| 3 | getPattern() | 获取错误的正则表达式模式。 |
| 4 | getMessage() | 返回多行字符串,包含语法错误及其索引的描述、错误的正则表达式模式和模式中错误索引的可视化指示。 |
String REGEX = "a*b[er";

第四章 正则表达式进阶语法
一、零宽断言
【断言】就是说正则可以【断定】在指定内容的前面或后面会出现满足指定规则的内容。
【零宽】 断言部分只确定位置不匹配任何内容,只是一种模式。内容宽度为零。
我们来举个栗子:假设我们要用爬虫抓取csdn里的文章阅读量。通过查看源代码可以看到文章阅读量这个内容是这样的结构:
"<span class="read-count">阅读数:641</span>"
其中也就【641】这个是变量,也就是说不同文章不同的值,当我们拿到这个字符串时,需要获得这里边的【641】有很多种办法,但如果正则应该怎么匹配呢?下面先来讲几种类型的断言:
几个概念:
| 概念 | 功能 |
|---|---|
| 预测/先行 | (模式在前),要求后面的符合匹配 |
| 回顾/后发 | (模式在后),要求前面的符合匹配 |
| 正 | 符合匹配 |
| 负 | 不符合匹配 |
1. 正向先行断言
零宽度正预测先行断言
-
语法:(?=pattern)
-
作用:匹配pattern表达式的前面内容,不返回本身。
【正向先行断言】可以匹配表达式前面的内容,那意思就是(?=) 就可以匹配到前面的内容了。
如果我们要匹配所有内容那就是:
@Test
public void testAssert1(){
String regex = ".+(?=</span>)";
String context = "<span class=\"read-count\">阅读数:641</span>";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(context);
while (matcher.find()){
System.out.println(matcher.group());
}
}
//匹配结果:<span class="read-count">阅读数:641
//可是我们要的只是前面的数字呀,那也简单咯,匹配数字 \d,那可以改成:
@Test
public void testAssert2(){
String regex = "\\d+(?=</span>)";
String context = "<span class=\"read-count\">阅读数:641</span>";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(context);
while (matcher.find()){
System.out.println(matcher.group());
}
}
//匹配结果:
//641
2. 正向后行断言
零宽度正回顾后发断言,断言在前,模式在后
-
语法:(?<=pattern)
-
作用:匹配pattern表达式的后面的内容,不返回本身。
有先行就有后行,先行是匹配前面的内容,那后行就是匹配后面的内容啦。
上面的例子,我们也可以用后行断言来处理:
@Test
public void testAssert3(){
String regex = "(?<=<span class=\"read-count\">阅读数:)\\d+";
String context = "<span class=\"read-count\">阅读数:641</span>";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(context);
while (matcher.find()){
System.out.println(matcher.group());
}
}
3. 负向先行断言
零宽度负预测先行断言
-
语法:(?!pattern)
-
作用:匹配非pattern表达式的前面内容,不返回本身。
有正向也有负向,负向在这里其实就是非的意思。
举个栗子:比如有一句 “我爱祖国,我是祖国的花朵”。现在要找到不是’的花朵’前面的祖国。
用正则就可以这样写:祖国(?!的花朵)
4. 负向后行断言
零宽度负回顾后发断言
-
语法:(?<!pattern)
-
作用:匹配非pattern表达式的后面内容,不返回本身。
举个例子:比如有一句 “我爱祖国,我是祖国的花朵”。现在要找到不是’我爱’后面的祖国。
用正则就可以这样写:(?<!我爱)祖国
二、捕获和非捕获
捕获组: 我们匹配子表达式的内容,并把匹配结果【以数字编号或组名的方式】保存到内存中,之后可以通过序号或名称来使用这些匹配结果。
而根据命名方式的不同,又可以分为两种组:
1. 数字编号捕获组:
语法:(exp)
解释:从表达式左侧开始,每出现一个左括号和它对应的右括号之间的内容为一个分组,在分组中,第0组为整个表达式,第一组开始为分组。
- 比如固定电话的:020-85653333
- 正则表达式为:(0\d{2})-(\d{8})
按照左括号的顺序,这个表达式有如下分组:
| 序号 | 编号 | 分组 | 内容 |
|---|---|---|---|
| 0 | 0 | (0\d{2})-(\d{8}) | 020-85653333 |
| 1 | 1 | (0\d{2}) | 020 |
| 2 | 0 | (\d{8}) | 85653333 |
String test = "020-85653333";
String reg="(0\\d{2})-(\\d{8})";
Pattern pattern = Pattern.compile(reg);
Matcher mc= pattern.matcher(test);
if(mc.find()){
System.out.println("分组的个数有:"+mc.groupCount());
for(int i=0;i<=mc.groupCount();i++){
System.out.println("第"+i+"个分组为:"+mc.group(i));
}
}
输出结果:
分组的个数有:2
第0个分组为:020-85653333
第1个分组为:020
第2个分组为:85653333
可见,分组个数是2,但是因为第0个为整个表达式本身,因此也一起输出了。
2. 命名编号捕获组:
语法:(?exp)
解释:分组的命名由表达式中的name指定,比如区号也可以这样写:
(?<quhao>0\\d{2})-(?<haoma>\\d{8})
按照左括号的顺序,这个表达式有如下分组:
| 序号 | 名称 | 分组 | 内容 |
|---|---|---|---|
| 0 | 0 | (0\d{2})-(\d{8}) | 020-85653333 |
| 1 | quhao | (0\d{2}) | 020 |
| 2 | haoma | (\d{8}) | 85653333 |
用代码来验证一下:
String test = "020-85653333";
String reg="(?<quhao>0\\d{2})-(?<haoma>\\d{8})";
Pattern pattern = Pattern.compile(reg);
Matcher mc= pattern.matcher(test);
if(mc.find()){
System.out.println("分组的个数有:"+mc.groupCount());
System.out.println(mc.group("quhao"));
System.out.println(mc.group("haoma"));
}
输出结果:
分组的个数有:2
分组名称为:quhao,匹配内容为:020
分组名称为:haoma,匹配内容为:85653333
3. 非捕获组:
- 语法:(?:exp)
- 解释:和捕获组刚好相反,它用来标识那些不需要捕获的分组。
比如上面的正则表达式,程序不需要用到第一个分组,那就可以这样写:(?:0\\d{2})-(\\d{8})
| 序号 | 名称 | 分组 | 内容 |
|---|---|---|---|
| 0 | 0 | (0\d{2})-(\d{8}) | 020-85653333 |
| 1 | 1 | (\d{8}) | 85653333 |
String test = "020-85653333";
String reg="(?:0\\d{2})-(\\d{8})";
Pattern pattern = Pattern.compile(reg);
Matcher mc= pattern.matcher(test);
if(mc.find()){
System.out.println("分组的个数有:"+mc.groupCount());
for(int i=0;i<=mc.groupCount();i++){
System.out.println("第"+i+"个分组为:"+mc.group(i));
}
}
输出结果:
分组的个数有:1
第0个分组为:020-85653333
第1个分组为:85653333
三、反向引用
我们知道:捕获会返回一个捕获组,这个分组是保存在内存中,不仅可以在正则表达式外部通过程序进行引用,也可以【在正则表达式内部进行引用】,这种引用方式就是【反向引用】。
根据捕获组的命名规则,反向引用可分为:
普通捕获组反向引用:\k<number>,通常简写为\number
命名捕获组反向引用:\k<name>,或者\k’name’
我们可以举一个例子:
比如要查找一串字母"aabbbbgbddesddfiid"里成对的字母,如果按照我们之前学到的正则,什么区间啊限定啊断言啊可能是办不到的。
现在我们先用程序思维理一下思路:
1)匹配到一个字母
2)匹配第下一个字母,检查是否和上一个字母是否一样
3)如果一样,则匹配成功,否则失败
这里的思路中,在匹配下一个字母时,需要用到上一个字母进行比较,但是目前的知识实在办不到。
这下子捕获就有用处啦,我们可以利用捕获把上一个匹配成功的内容用来作为本次匹配的条件即可。
- 首先匹配一个字母:\w。我们需要做成分组才能捕获,因此写成这样:(\w)
- 那这个表达式就有一个捕获组:(\w)
- 然后我们要用这个捕获组作为条件,那就可以:(\w)\1
这里的\1是什么意思呢?根据反向引用的数字命名规则,就需要 \k<1>或者\1,当然,通常都是是后者。
我们来测试一下:
@Test
public void testRef(){
String context = "aabbxxccdddsksdhfhshh";
String regex = "(\\w)\\1";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(context);
while (matcher.find()){
System.out.println(matcher.group());
}
}
输出结果:
aa
bb
xx
cc
dd
hh
再举个替换的例子,假如想要把字符串中abc换成a
@Test
public void testReplaceAll(){
String context = "abc aabc bc xxx mm";
String regex = "(a*)(b)(c)";
String res = context.replaceAll(regex, "$1");
System.out.println(res);
}
输出结果:
a aa xxx mm
四、贪婪和非贪婪
1. 贪婪匹配
贪婪匹配: 当正则表达式中包含能接受重复的限定符时,该方式会匹配尽可能多的字符,这匹配方式叫做贪婪匹配。
前面我们讲过重复限定符,其实这些限定符就是贪婪量词,比如表达式:\d{3,6}。
用来匹配3到6位数字,在这种情况下,它是一种贪婪模式的匹配,也就是假如字符串里有6个数字可以匹配,那它就是全部匹配到。
@Test
public void testGreed(){
String regex = "\\d{3,6}";
String context ="61762828 176 2991 871";
System.out.println("文本:" + context);
System.out.println("贪婪模式:"+ regex);
Pattern pattern =Pattern.compile(regex);
Matcher matcher = pattern.matcher(context);
while(matcher.find()){
System.out.println("匹配结果:" + matcher.group(0));
}
}
输出结果:
文本:61762828 176 2991 44 871
贪婪模式:\d{3,6}
匹配结果:617628
匹配结果:176
匹配结果:2991
匹配结果:871
由结果可见:本来字符串中的“61762828”这一段,其实只需要出现3个(617)就已经匹配成功了的,但是他并不满足,而是匹配到了最大能匹配的字符,也就是6个。
多个贪婪量词在一起时,如果字符串能满足他们各自最大程度的匹配时,就互不干扰,但如果不能满足时,会优先满足最大数量的匹配,剩余再分配下一个量词匹配。
@Test
public void testGreed2(){
String regex = "\\d{1,2}\\d{3,5}";
String context ="61762828 176 2991 871";
System.out.println("文本:" + context);
System.out.println("贪婪模式:"+ regex);
Pattern pattern =Pattern.compile(regex);
Matcher matcher = pattern.matcher(context);
while(matcher.find()){
System.out.println("匹配结果:" + matcher.group(0));
}
}
输出结果:
文本:61762828 176 2991 871
贪婪模式:\d{1,2}\d{3,5}
匹配结果:6176282
匹配结果:2991
2. 懒惰匹配
懒惰匹配:当正则表达式中包含能接受重复的限定符时,会匹配尽可能少的字符,这匹配方式叫做懒惰匹配。
懒惰量词是在贪婪量词后面加个“?”
| 代码 | 说明 |
|---|---|
| *? | 重复任意次,但尽可能少重复 |
| +? | 重复1次或更多次,但尽可能少重复 |
| ?? | 重复0次或1次,但尽可能少重复 |
| {n,m}? | 重复n到m次,但尽可能少重复 |
| {n,}? | 重复n次以上,但尽可能少重复 |
@Test
public void testNotGreed(){
String reg="(\\d{1,2}?)(\\d{3,4})";
String test="61762828 176 2991 87321";
System.out.println("文本:"+test);
System.out.println("贪婪模式:"+reg);
Pattern p1 =Pattern.compile(reg);
Matcher m1 = p1.matcher(test);
while(m1.find()){
System.out.println("匹配结果:"+m1.group(0));
}
}
输出结果:
文本:61762828 176 2991 87321
懒惰匹配:(\d{1,2}?)(\d{3,4})
匹配结果:61762
匹配结果:2991
匹配结果:87321
- “61762” 是左边的懒惰匹配出6,右边的贪婪匹配出1762。
- “2991” 是左边的懒惰匹配出2,右边的贪婪匹配出991。
- “87321” 左边的懒惰匹配出8,右边的贪婪匹配出7321。
第五章 作业
-
通过scanner输入一个字符串,判断是否是一个邮箱?
public class TestEmail { public static void main(String[] args) { Scanner scanner = new Scanner(System.in); String email = scanner.next(); String regex = "^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\\.[a-zA-Z0-9_-]+)+$"; Pattern pattern = Pattern.compile(regex); Matcher matcher = pattern.matcher(email); boolean matches = matcher.matches(); if(matches){ System.out.println("您输入的是一个邮箱!"); } else { System.out.println("您输入的不是邮箱!"); } } } -
将一个文件中的邮箱全部查找出来?
@Test public void findEmail() throws IOException { StringBuilder sb = new StringBuilder(); // 1、将文件的内容读取到内存 InputStream in = new FileInputStream("D:\\user.txt"); byte[] buf = new byte[1024]; int len; while ((len = in.read(buf)) > 0){ sb.append(new String(buf,0,len)); } // 2、进行正则匹配 String regex = "[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\\.[a-zA-Z0-9_-]+)+"; Pattern pattern = Pattern.compile(regex); Matcher matcher = pattern.matcher(sb.toString()); while (matcher.find()){ System.out.println(matcher.group()); } } -
将一个文件中的电话的中间四个数字替换成xxxx? 例子 15236985456 --> 152xxxx5456
文本如下:姓名 年龄 邮箱 电话 张小强 23 526845845@163.com 13759685424 丁新新 20 238011792@qq.com 18011023709 李银龙 20 liyinl1199w@163.com 17308811441 赵资本 19 anhuo69579@126.com 18234417225 李成刚 21 19713318@qq.com 13279906620 王铁柱 20 ykl3987671@163.com 18802836971 张龙虎 22 zh199715@gmail.com 13888906654 李洁一 18 nl897665@yahoo.com 19762297581 刘大志 20 197685551@qq.com 15299744196 杨天天 19 86765ytian@126.com 17663999002 陈承成 21 rr796232@hotmail.com 18137541864@Test public void hidePhoneNumber() throws IOException { StringBuilder sb = new StringBuilder(); // 1、将文件的内容读取到内存 InputStream in = new FileInputStream("D:\\user.txt"); byte[] buf = new byte[1024]; int len; while ((len = in.read(buf)) > 0){ sb.append(new String(buf,0,len)); } // 2、进行正则匹配 String regex = "(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])(\\d{4})(\\d{4})"; Pattern pattern = Pattern.compile(regex); Matcher matcher = pattern.matcher(sb.toString()); String result = matcher.replaceAll("$1xxxx$3"); System.out.println(result); }
创作不易,如果有帮助到你,请给文章==点个赞和收藏==,让更多的人看到!!!
==关注博主==不迷路,内容持续更新中。

- 点赞
- 收藏
- 关注作者
评论(0)