每日打卡签到任务的自动化处理

为积极响应信息报送工作,这几天有很多小伙伴来问我能不能实现每日信息报送任务的自动化处理,避免每日信息的漏报、延报。因此抽时间用 Java 写了一份,但是考虑到大家可能更加熟悉 Python,因此重写了一份 Python版本,有条件的童鞋可以尝试。
温馨提示:请对每日报送信息内容的真实性和完整性负责,如有信息变更请及时停止自动化报送,请大家遵守各项规定,配合并听从各项措施和要求。
打卡步骤梳理:
- 登录账号
- 获取定位
- 点击“报送”
- 收到服务器“提交信息成功”状态响应
基于上述分析,实现每日信息情况的自动报送思路有二,其一直接用 selenium 模拟浏览器操作实现动态HTML处理,完成报送(不推荐),实现方法较为简单,随手一打,未测试,仅供参考。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions
from selenium.common.exceptions import TimeoutException, WebDriverException
from time import sleep
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
zhanghao = ""
mima = ""
chrome_options = Options()
driver = webdriver.Chrome()
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get('https://app.cupl.edu.cn/ncov/wap/default/index')
wait = WebDriverWait(browser,10,0.5)
account = WebDriverWait(browser, 20).until(expected_conditions.visibility_of_element_located((By.XPATH, '//*[@id="app"]/div[2]/div[1]/input')))\
.send_keys(zhanghao)
password = browser.find_element_by_xpath('//*[@id="app"]/div[2]/div[2]/input').send_keys(mima)
sign_in = browser.find_element_by_class_name('btn').click()
wait.until(EC.visibility_of_element_located((By.XPATH,'/html/body/div[1]/div/div/section/div[4]/ul/li[7]/div/input'))).click()
sleep(3)
browser.find_element_by_xpath('/html/body/div[1]/div/div/section/div[5]/div/a').click()
sleep(1)
browser.find_element_by_xpath('//*[@id="wapcf"]/div/div[2]/div[2]').click()
sleep(1)
browser.close()
browser.quit()
上述方法实现起来很简单,勉强算个”半自动化“,但弊端很明显:
- 其一,上述方法需要
chromedriver.exe等环境依赖,体积大,运行慢,不便封装; - 其二,需要明文存储账户信息,安全性不可靠;
- 其三,每次报送需定位,过程慢,容错率低,且不支持异地主机自动化处理;
- 其四,除非每日手动开启,不易监听报送结果。
相比,第二个实现方案能够很好解决上述问题:即 不再依赖可视化的前端操作,根据数据特征直接封装有效的post包发至目标服务器,实现信息报送,并监听服务器响应,通过邮件接受报送结果。
(图示邮件为部署完成后”每日定时自动打卡执行情况“监听结果)

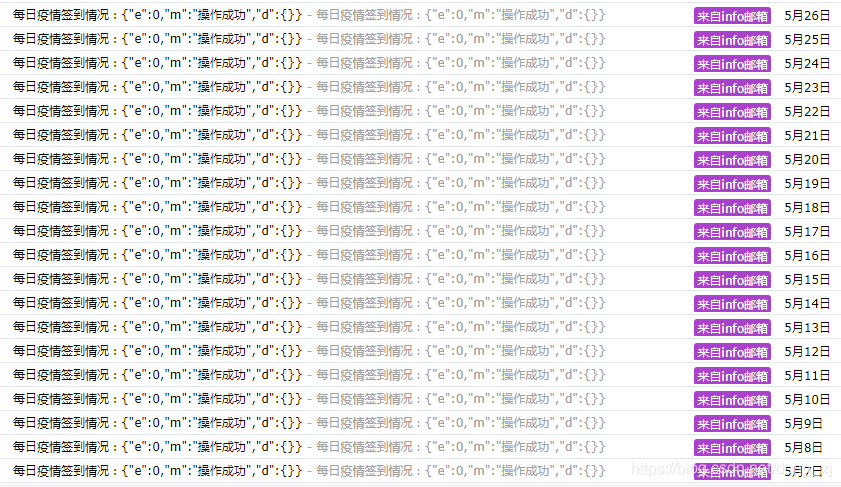
实现方法如下:
一、抓包与析包
(1)登陆账号验证cookie值有效期


(2)定位post请求与header头


(3)解析post包报文内容

经过报文分析,确定变量有3,分别是 created、date 以及 id

其中date 容易理解,进一步回到前端分析 created 和 id

分析后认为,created_uid 与 created 具有函数关系,id 应该是根据时间戳产生,id 与 created 每日变化且相互关联,但一组 id 与 created 不可复用。
同时我发现,每次页面载入 GET 数据库信息后将通过声明 def变量的形式体现在源码中。
基于上述分析,直接尝试组装数据包并发送 ————> 提交成功。

二、实现信息报送的自动化
在明白原理后,原本复杂的问题就已经迎刃而解了。先梳理清楚操作步骤和目标,并引入相关环境变量:
- 获取
created、date以及id的值; - 拼接 post 包
- 发包
- 获取服务器状态响应
- 每日邮件提醒响应内容
- 定时任务,每日自动运行
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import requests
import urllib.request
import urllib.parse
import re
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
(1)获取 created、date 以及 id 的值
前面我们已经发现,每次页面载入 GET 数据库信息后将通过声明 def变量的形式体现在源码中,那就直接用正则表达式截取内容:
首先,created、date 以及 id 的值只有在登陆后才能获取,因此获取网页源码时需要带上 Cookie 值和必要的请求头。
url = 'https://app.cupl.edu.cn/ncov/wap/default/index'
headers = {
'GET https': '//app.cupl.edu.cn/ncov/wap/default/index HTTP/1.1',
'Host': ' app.cupl.edu.cn',
'Connection': ' keep-alive',
'Upgrade-Insecure-Requests': ' 1',
'User-Agent': ' Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
'Accept': ' text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Referer':' https://app.cupl.edu.cn/ncov/wap/default/index',
'Accept-Language': ' zh-CN,zh;q=0.9',
'Cookie': 'Hm_lvt_48b682d4885d22a90111e46b...',
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
main = response.read().decode(encoding='UTF-8',errors='strict')
其次,上正则表达式,注意created、 id 与 date 间存在格式差异!!!
reg_id = r'"id":[\d]+'
reg_created = r'"created":[\d]+'
reg_date = r'"date":"[\d]+"'
reg_ques_id = re.compile(reg_id)
reg_ques_created = re.compile(reg_created)
reg_ques_date = re.compile(reg_date)
queslist_id = reg_ques_id.findall(main)
queslist_created = reg_ques_created.findall(main)
queslist_date = reg_ques_date.findall(main)
分别看一下返回结果:
#print(queslist_id)
#print(queslist_created)
#print(queslist_date)

我们可以看到,返回的数据类型是 <class ‘list’>,提取created、date 以及 id 的值,首先要将列表转化成 str,再行截取。
new_id = str(queslist_id[0])[5:11]
#print(new_id)
new_created = str(queslist_created[0])[10:20]
#print(new_created)
new_date = str(queslist_date[0])[8:16]
#print(new_date)

(2)拼接 post 包、发包、收包
new_body = "ismoved=0&j······&created="+new_created+"&date="+new_date+"&id="+new_id+"&gwszdd=&sfyqjzgc=&jcqzrq=&sfjcqz=&jrsfqzys=&jrsfqzfy=&sfsqhzjkk=&sqhzjkkys="
headers = {
"Host": "app.cupl.edu.cn",
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Origin": "https://app.cupl.edu.cn",
"X-Requested-With": "XMLHttpRequest",
"Sec-Fetch-Dest": "empty",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Sec-Fetch-Site": "same-origin",
"Sec-Fetch-Mode": "cors",
"Referer": "https://app.cupl.edu.cn/ncov/wap/default/index",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": "Hm_l······47797"
}
data = new_body
url2 = 'https://app.cupl.edu.cn/ncov/wap/default/save'
resp = requests.post(url2, headers=headers,data=data, allow_redirects=True)
# 获取服务器状态响应
print (resp.text)

这里回显内容分别为
created、id、date的值;拼接后完整的body; 以及服务器响应状态,可以看到信息已提交成功。

(3)报送情况监听
全自动化的信息报送是否每天都有正常运行是自动化报送中需要关注的问题,这里选择通过简单邮件传输协议方式监听报送结果。
my_sender = '···' # 发件人邮箱账号
my_pass = '···' # 发件人邮箱密码
my_user = '···' # 收件人邮箱账号,我这边发送给自己
def mail():
ret = True
try:
msg = MIMEText('每日信息报送情况:'+resp.text, 'plain', 'utf-8')
msg['From'] = formataddr(["···", my_sender]) # 括号里的对应发件人邮箱昵称、发件人邮箱账号
msg['To'] = formataddr(["···", my_user]) # 括号里的对应收件人邮箱昵称、收件人邮箱账号
msg['Subject'] = "每日信息报送情况:"+resp.text # 邮件的主题,也可以说是标题
server = smtplib.SMTP_SSL("smtp.qq.com", 465) # 发件人邮箱中的SMTP服务器,端口是25
server.login(my_sender, my_pass) # 括号中对应的是发件人邮箱账号、邮箱密码
server.sendmail(my_sender, [my_user, ], msg.as_string()) # 括号中对应的是发件人邮箱账号、收件人邮箱账号、发送邮件
server.quit() # 关闭连接
except Exception: # 如果 try 中的语句没有执行,则会执行下面的 ret=False
ret = False
return ret
ret = mail()
if ret:
print("邮件发送成功")
else:
print("邮件发送失败")
模拟测试错误态:




(4)设置定时任务,每日自动执行
考虑到计算机开机的不定期性以及局域网小型服务器面临的断电风险,我选择将程序放置我自己的公网服务器上运行,这里以Linux服务器定时任务为例:
- 检查服务器时间是否同步:
date -R

# 使用crontab新建定时任务:
crontab -e
usage: crontab [-u user] file
crontab [-u user] [ -e | -l | -r ]
(default operation is replace, per 1003.2)
-e (edit user's crontab)
-l (list user's crontab)
-r (delete user's crontab)
-i (prompt before deleting user's crontab)
-s (selinux context)

设置每天00:01分自动签到,> /dev/null 2>&1目的在于拒收程序指定时间执行后系统自动寄送的信件。
* * * * * /root/rats.sh #前5个*指时间,后面为命令
分钟:0-59
小时:1-23
日期:1-31
月份:1-12
星期:0-6(0表示周日)
*: 表示任何时刻
,: 表示分割
-:表示一个段,如:1-5,就表示1到5点
/n : 表示每个n的单位执行一次,如:*/1, 就表示每隔1个小时执行一次命令。也可以写成1-23/1
1.注意环境变量问题,例如crontab不能识别Java的环境变量,所以在编写shell时,最好使用export重新声明变量,确保脚本执行。
2.命令的执行最好用脚本
3.脚本权限加/bin/sh,规范路径/server/scripts
4.时间变量用反斜线转义,最好用脚本
5.定时任务添加注释
6.>/dev/null 2>&1 ==>&>/dev/null,别随意打印日志文件
7.定时任务里面的程序脚本尽量用全路径
8.避免不必要的程序以及命令输出
9.定时任务之前添加注释
10.打包到文件目录的上一级
#定时任务设置举例:
43 21 * * * #21:43 执行
15 05 * * * #05:15 执行
0 17 * * * #17:00 执行
0 17 * * 1 #每周一的17:00 执行
0,10 17 * * 0,2,3 #每周日,周二,周三的17:00和17:10 执行
0-10 17 1 * * #毎月1日从17:00到7:10毎隔1分钟 执行
0 0 1,15 * 1 #毎月1日和15日和一日的0:00 执行
42 4 1 * * #毎月1日的4:42分 执行
0 21 * * 1-6 #周一到周六21:00 执行
0,10,20,30,40,50 * * * * #每隔10分 执行
*/10 * * * * #每隔10分 执行
* 1 * * * #从1:0到1:59每隔1分钟 执行
0 1 * * * #1:00 执行
0 */1 * * * #毎时0分每隔1小时 执行
0 * * * * #毎时0分 执行
2 8-20/3 * * * #8:02,11:02,14:02,17:02,20:02 执行
30 5 1,15 * * #1日和15日的5:30 执行

经测试,运行正常:

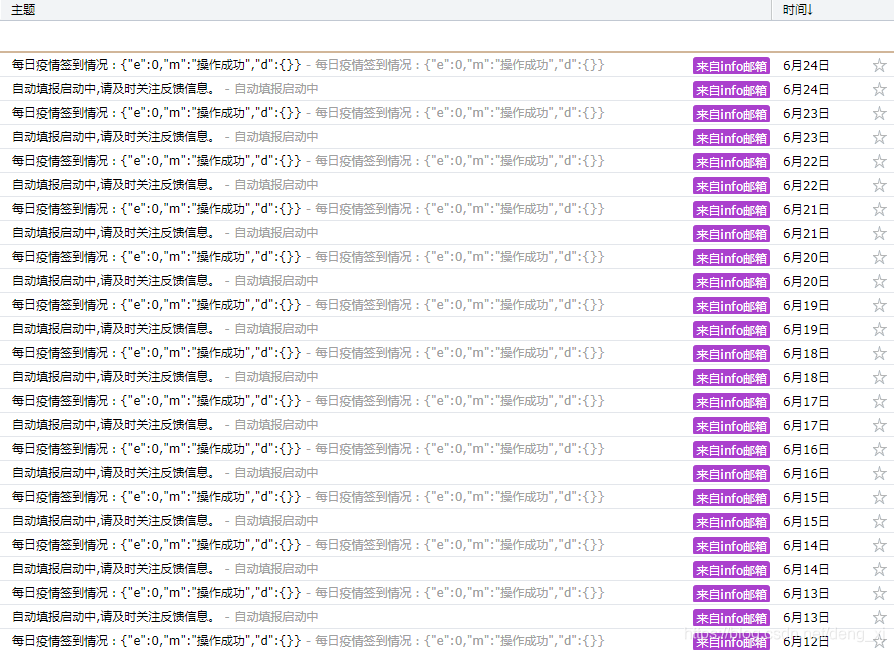
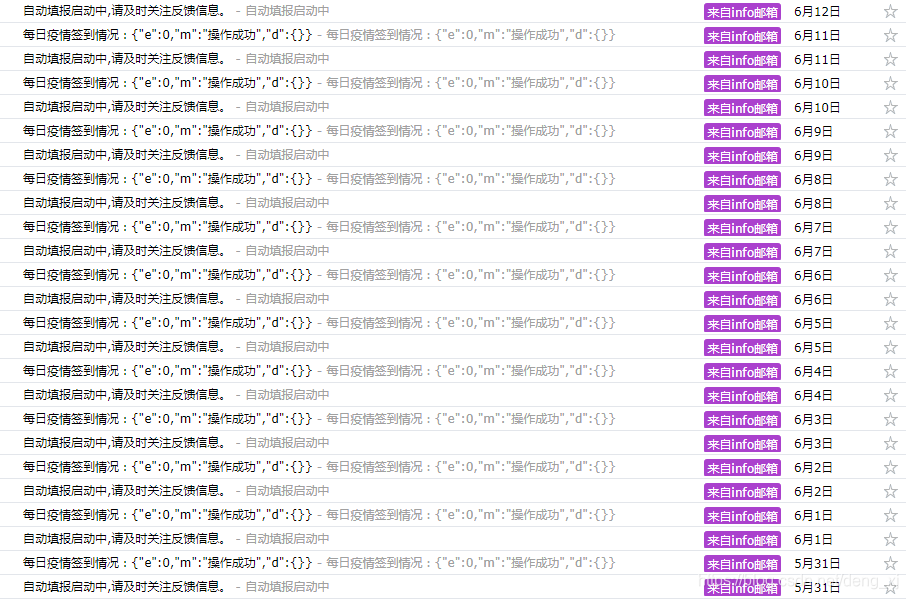
再次提示:请对每日报送信息内容的真实性和完整性负责,如有信息变更请及时停止自动化报送,请大家遵守各项规定,配合并听从各项措施和要求。
如果您有任何疑问或者好的建议,期待你的留言与评论!

- 点赞
- 收藏
- 关注作者
评论(0)