【推荐系统】推荐系统数据流的经典技术架构+微软、阿里、微软等10大深度学习CTR模型最全演化图谱

【摘要】 一、推荐、广告、搜索系统的区别? 1.1 根本问题区别广告:广告算法的目标就是为了直接增加公司的收入搜索:围绕搜索词的信息高效获取问题的回应推荐:增加用户的参与度,提高用户粘性和留存率 1.2 优化目标的区别广告:预估CTR和CVR,反向推导流量的价值搜索:看重能够把正确答案召回回来推荐:推荐算法目标不尽相同,视频类更倾向于视频播放市场,新闻类预测CTR点击率,电商类预估客单价等 1.3 ...
一、推荐、广告、搜索系统的区别?
1.1 根本问题区别
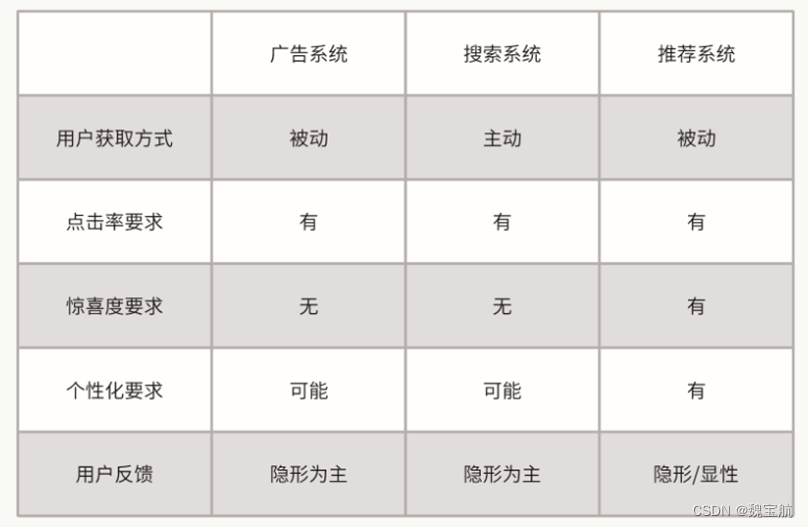
- 广告:广告算法的目标就是为了直接增加公司的收入
- 搜索:围绕搜索词的信息高效获取问题的回应
- 推荐:增加用户的参与度,提高用户粘性和留存率
1.2 优化目标的区别
- 广告:预估CTR和CVR,反向推导流量的价值
- 搜索:看重能够把正确答案召回回来
- 推荐:推荐算法目标不尽相同,视频类更倾向于视频播放市场,新闻类预测CTR点击率,电商类预估客单价等
1.3 模型本身的差异
经典的Attention推荐模型
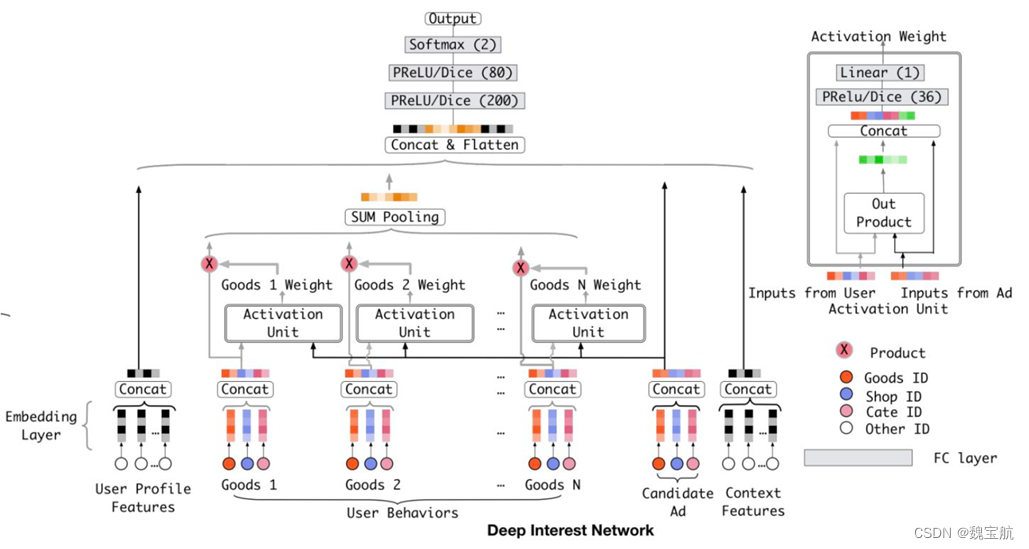
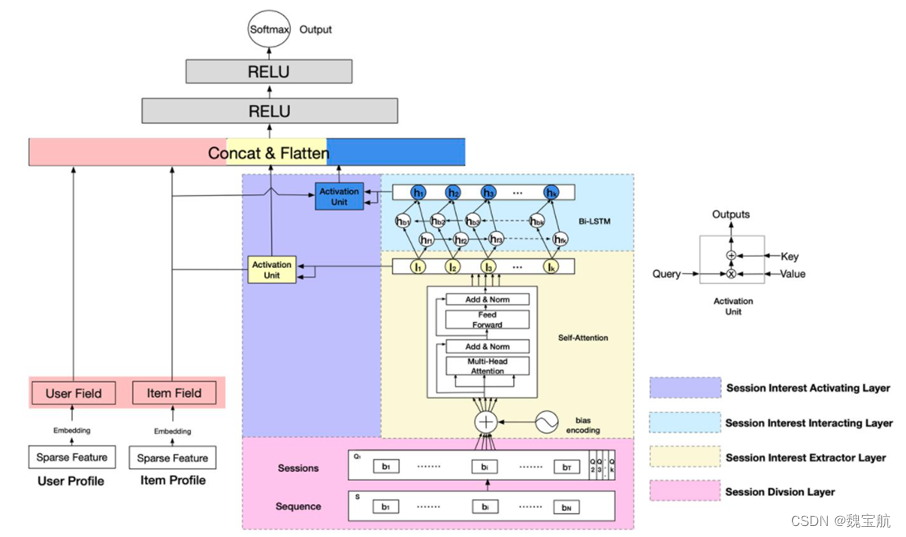
融合序列结构的DSIN
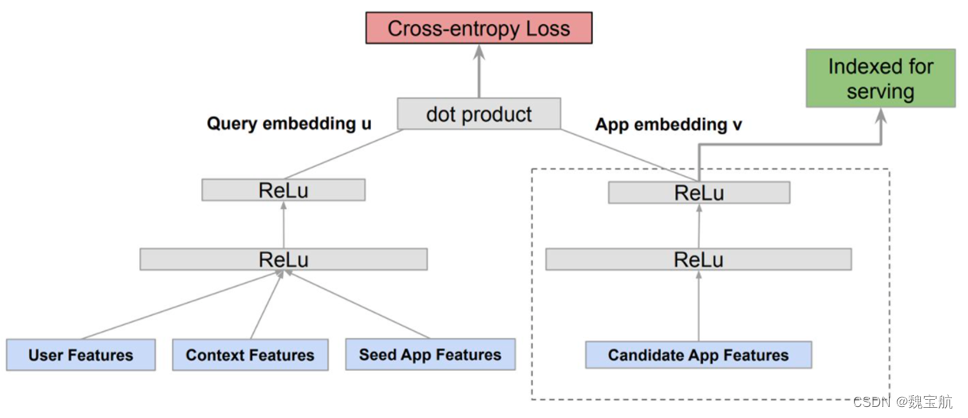
Google Play的搜索双塔模型
二、推荐系统技术架构
2.1 数据部分
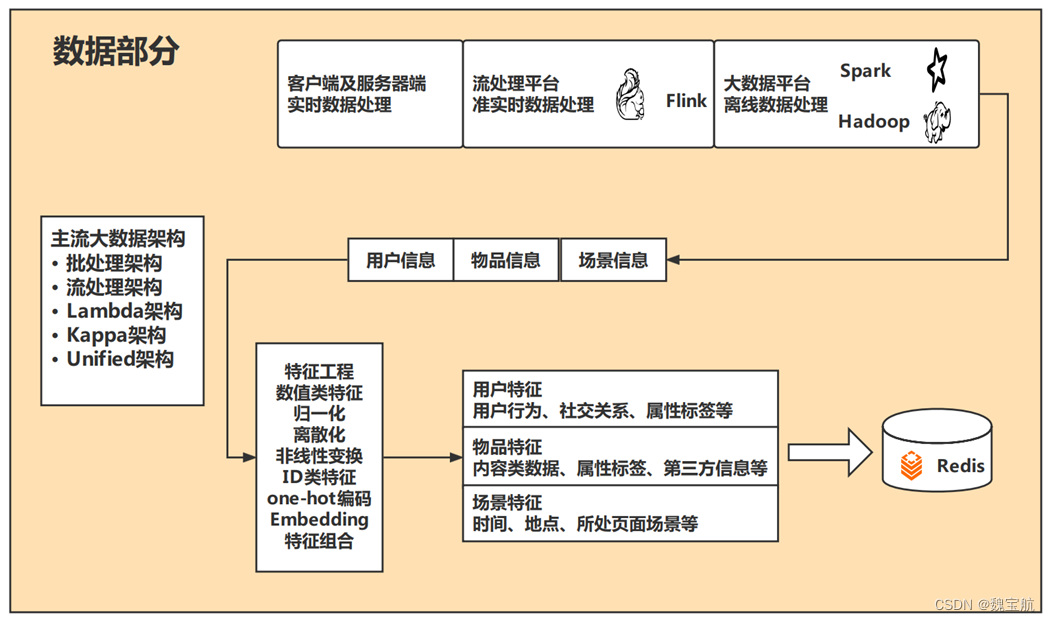
主流大数据架构
- 批处理架构
- 流处理架构
- Lambda架构
- Kappa架构
- Unified架构
2.2 模型部分
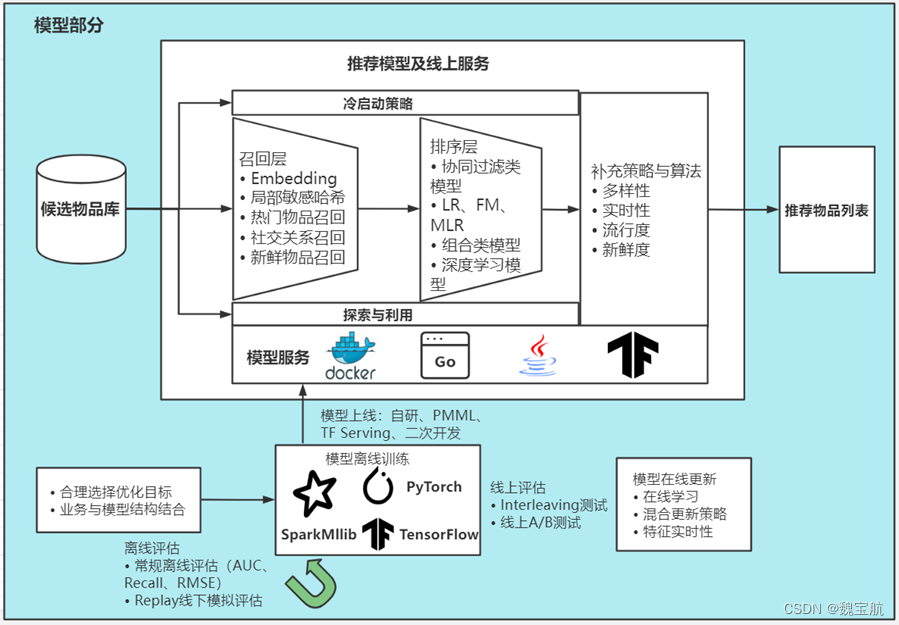
召回层:
- Embedding
- 局部敏感哈希
- 热门物品召回
- 社交关系召回
- 新鲜物品召回
排序层:
- 协同过滤类模型
- LR、FM、MLR
- 组合类模型
- 深度学习模型
补充策略与算法:
- 多样性
- 实时性
- 流行度
- 新鲜度
2.3 推荐系统数据流的技术架构图
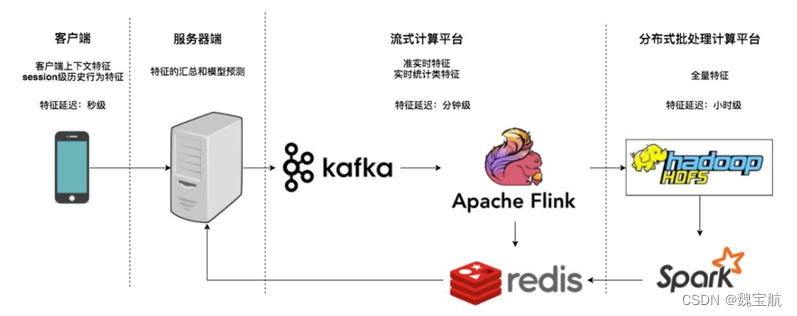
-
客户端实时特征:经常利用客户端收集时间、地点、推荐场景等上下文特征,然后让这些特征随http请求一起到达服务器端,参与模型预测。
-
流处理平台的准实时特征处理:所谓流处理平台,是将日志以流的形式进行mini batch处理的准实时计算平台,流处理平台计算出的特征可以立马存入特征数据库供推荐系统模型使用,虽然无法实时的根据用户行为改变用户结果,但分钟级别的延迟基本可以保证用户的推荐结果准实时地受到之前行为的影响。
-
分布式批处理平台的全量特征处理:随着数据最终到达以HDFS为主的分布式存储系统。Spark等分布式计算平台终于能够进行全量特征的计算和抽取。在这个阶段着重进行的还有多个数据源的数据join和以及延迟信号的合并。
三、深度学习推荐模型的演化趋势
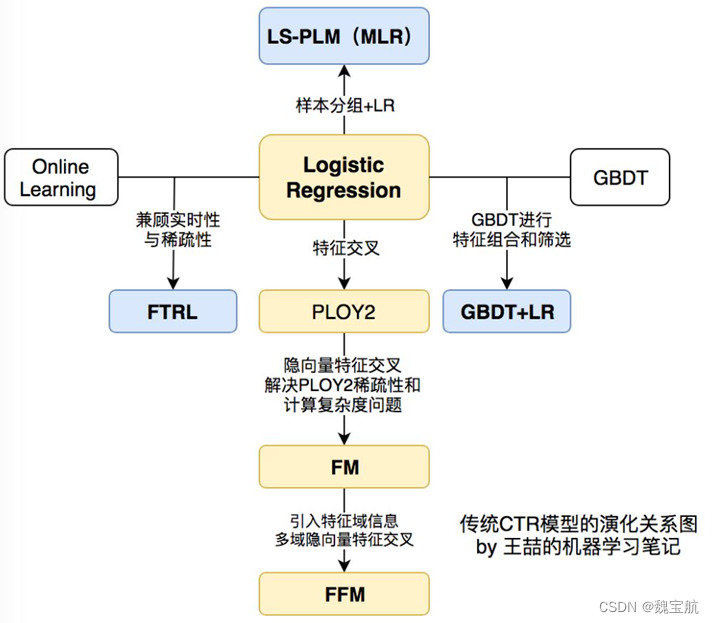
3.1 前深度学习时代CTR预估模型的演化之路
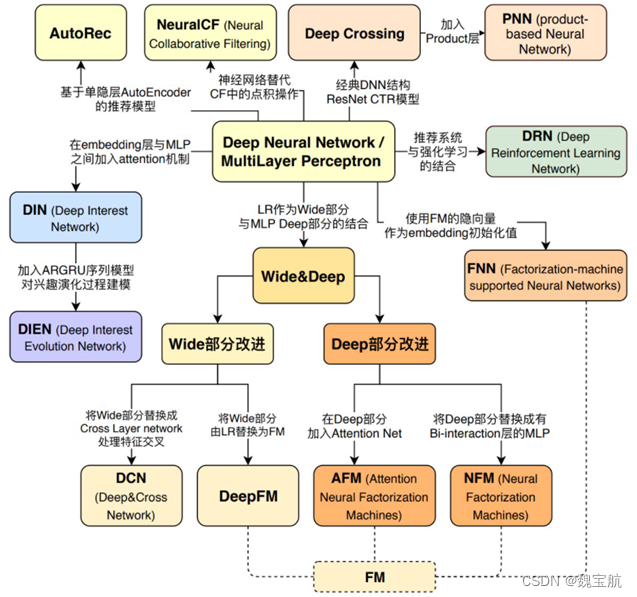
3.2 谷歌、阿里、微软等10大深度学习CTR模型最全演化图谱【推荐、广告、搜索领域】
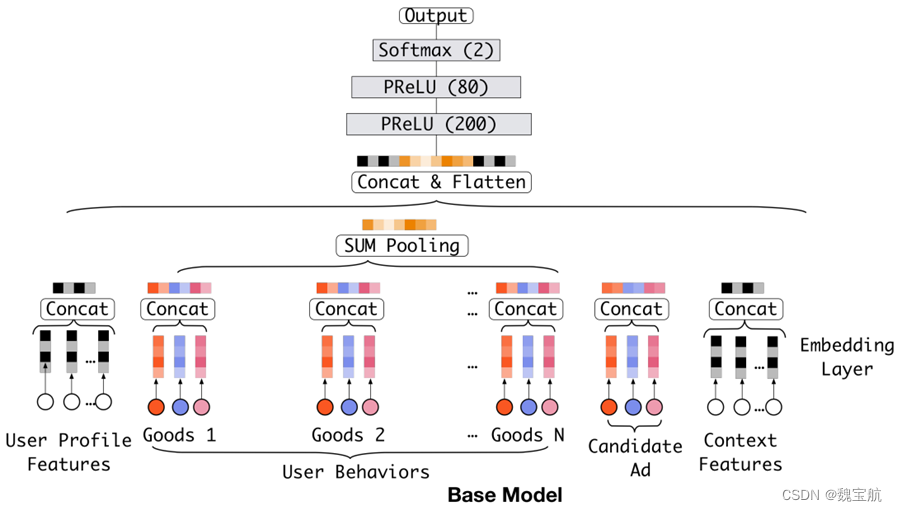
3.3 CTR基本模型结构
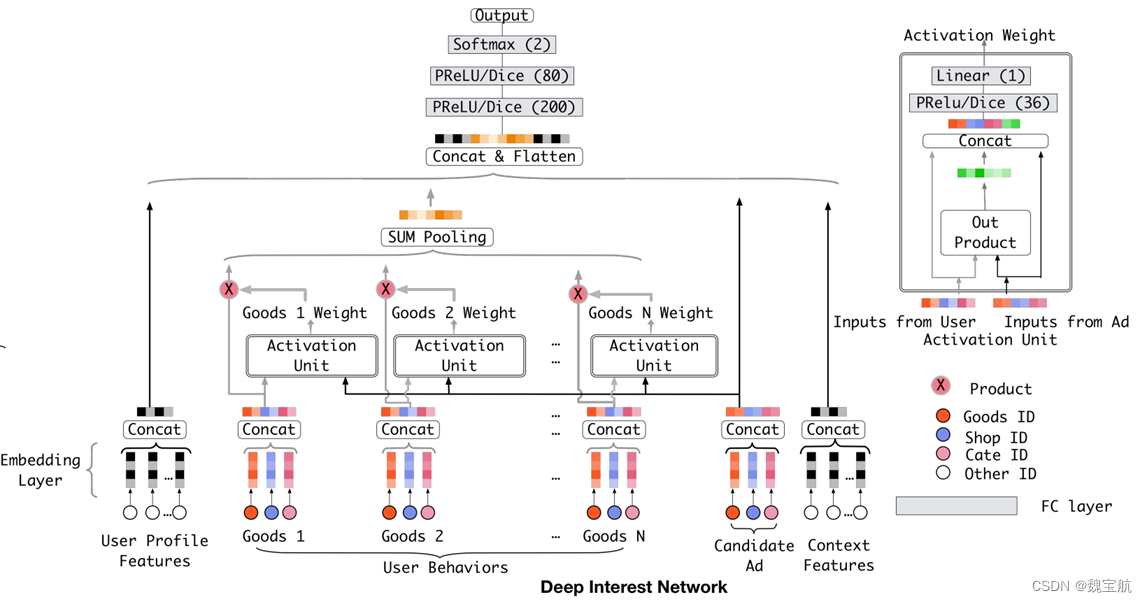
3.4 DIN网络
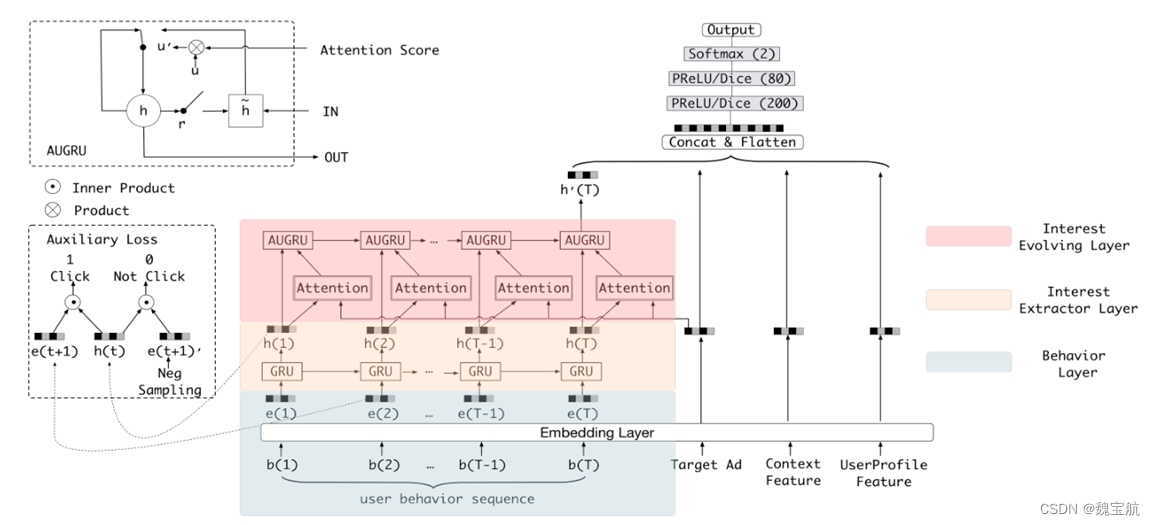
3.5 DIEN网络
3.6 如何根据用户历史行为数据计算CTR?
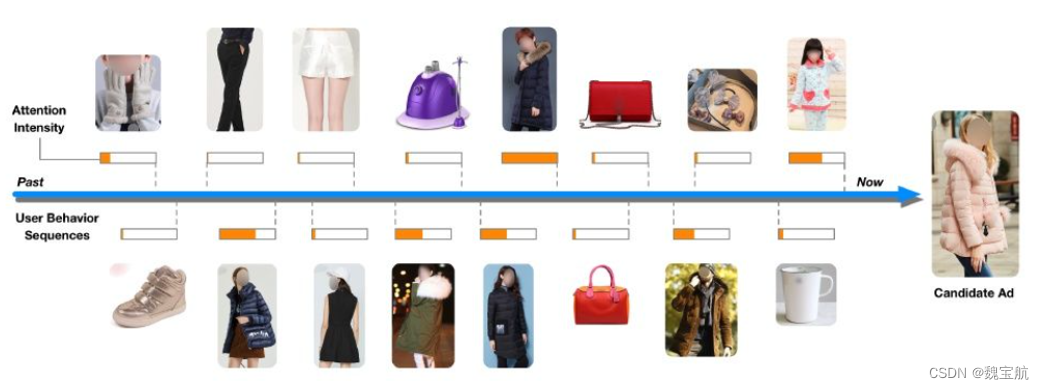
-
方式一:考虑所有行为记录的影响,利用average pooling将embedding vector平均一下形成这个用户的user vector
-
方式二:使用time decay,让最近的行为产生的影响大一些,在做average pooling的时候按时间调整一下权重
-
方式三:引入attention机制,对不同的行为兴趣增加不同的权重

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)