机器学习算法

我们可能生活在技术最具决定性的时期。计算从大型主机转移到 PC 再到自动驾驶汽车和机器人的时期。但是,定义它的不是发生了什么,而是到达这里的过程。使这一时期令人兴奋的是资源和技术的民主化。曾经需要几天的数据处理,今天只需几分钟,这一切都归功于机器学习算法。
这就是数据科学家每年获得高达 124,000 美元的收入,从而增加对数据科学认证的需求的原因。
机器学习算法:什么是机器学习?
机器学习 是一个概念,它允许机器从示例和经验中学习,而且无需明确编程。
我给你打个比方,让你更容易理解。
假设有一天你去买苹果。供应商有一个装满苹果的推车,您可以从那里挑选水果,称重并根据固定费率(每公斤)付款。
任务:你将如何选择最好的苹果?
下面给出了人类从他购买苹果的经验中获得的一系列学习,您可以深入了解它以进一步详细了解。通读一遍,您将很容易将其与机器学习联系起来。
学习一:鲜红的苹果比淡红的苹果甜
学习2:小而亮的红苹果只有一半是甜的
学习3:小而苍白的一点都不甜
学习4:脆苹果多汁
学习5:青苹果比红苹果好吃
学习6:你不再需要苹果了

如果您必须为它编写代码怎么办?
现在,假设您被要求编写一个计算机程序来选择您的苹果。您可以编写以下规则/算法:
如果 (亮红色) 和 如果(尺寸很大):苹果是甜的。
如果(脆皮):苹果多汁
您将使用这些规则来选择苹果。
但是每次从实验中进行新的观察时(如果您不得不选择橙子呢),您都必须手动修改规则列表。
您必须了解影响水果质量的所有因素的详细信息。如果问题变得足够复杂,您可能很难手动制定涵盖所有可能类型水果的准确规则。这将需要大量的研究和努力,并不是每个人都有这么多时间。
这就是机器学习算法出现的地方。
因此,您无需编写代码,而是将数据提供给通用算法,然后算法/机器根据给定数据构建逻辑。
机器学习算法:什么是机器学习算法?
机器学习算法是常规算法的进化。它使您的程序“更智能”,允许它们自动从您提供的数据中学习。算法主要分为:
- 训练阶段
- 测试阶段
因此,在我之前给出的示例的基础上,让我们稍微谈谈这些阶段。
训练阶段
你从市场上随机选择一个苹果样本(训练数据),制作一个表格,列出每个苹果的所有物理特征,比如颜色、大小、形状、生长在国家的哪个地区、由哪个供应商销售等(features),以及那个苹果的甜度、多汁度、成熟度(输出变量)。您将这些数据提供给机器学习算法(分类/回归),它会学习一个平均苹果物理特征与其质量之间相关性的模型。
测试阶段
下次购物时,您将测量您购买的苹果的特征(测试数据)并将其提供给机器学习算法。它将使用之前计算的模型来预测苹果是甜的、成熟的和/或多汁的。该算法可能会在内部使用这些规则,类似于您之前手动编写的规则(例如, 决策树)。最后,您现在可以满怀信心地购买苹果,而不必担心如何选择最好的苹果的细节。
结论
你知道吗!你可以让你的算法随着时间的推移而改进(强化学习),这样随着它在越来越多的训练数据集上得到训练,它就会提高它的准确性。如果它做出错误的预测,它将自行更新其规则。
最好的部分是,您可以使用相同的算法来训练不同的模型。您可以分别创建一个来预测芒果、葡萄、香蕉或任何您想要的水果的质量。
让我们将机器学习算法分为几个子部分,看看它们是什么,它们是如何工作的,以及它们在现实生活中是如何使用的。
机器学习算法:机器学习算法有哪些类型?
因此,机器学习算法可以分为以下三种类型。

机器学习算法:什么是监督学习?
这个类别被称为监督学习,因为从训练数据集学习算法的过程可以被认为是 老师教他的学生。算法根据训练数据不断预测结果,并由教师不断修正。学习一直持续到算法达到可接受的性能水平。
让我用简单的术语重新表述:
在监督机器学习算法中,训练数据集的每个实例都由输入属性和预期输出组成。训练数据集可以将任何类型的数据作为输入,例如数据库行的值、图像的像素,甚至音频直方图。
示例:在 生物识别考勤中, 您可以使用您的生物识别身份输入来训练机器 - 可以是您的拇指、虹膜或耳垂等。一旦机器被训练,它可以验证您未来的输入并可以轻松识别您。
机器学习算法:什么是无监督学习?
嗯,这类机器学习被称为无监督,因为与监督学习不同,没有老师。算法自行发现并返回数据中有趣的结构。
无监督学习的目标是对数据中的底层结构或分布进行建模,以便更多地了解数据。
在无监督学习方法中,训练数据集的样本没有与其相关的预期输出。使用无监督学习算法,您可以根据输入数据的典型特征检测模式。聚类可以被视为使用无监督学习方法的机器学习任务的一个例子。然后机器将相似的数据样本分组并识别数据中的不同集群。
示例:欺诈检测可能是无监督学习最流行的用例。利用过去关于欺诈索赔的历史数据,可以根据新索赔与指示欺诈模式的集群的接近程度来隔离新索赔。
此外,请参加人工智能和机器学习课程,以精通此人工智能和机器学习。
机器学习算法:什么是强化学习?
强化学习可以被认为是一种尝试性的学习方法。机器执行的每个动作都会获得奖励或惩罚点数。如果选项正确,机器将获得奖励积分或在错误响应的情况下获得惩罚积分。
强化学习算法是关于环境和学习代理之间的交互。学习代理基于探索和开发。
探索是学习代理根据反复试验而采取行动,而开发是根据从环境中获得的知识执行行动。环境奖励智能体的每一个正确动作,这是强化信号。为了收集更多获得的奖励,代理改进其环境知识以选择或执行下一个动作。
让我们看看巴甫洛夫如何使用强化训练训练他的狗?
巴甫洛夫将他的狗的训练分为三个阶段。
第一阶段:第一部分,巴甫洛夫给狗吃肉,对肉的反应,狗开始流口水。
第 2 阶段:在下一个阶段,他用铃铛发出声音,但这次狗没有任何反应。
第三阶段:在第三阶段,他尝试通过使用铃铛然后给它们食物来训练他的狗。看到食物,狗开始流口水。
最终,狗一听到铃声就开始流口水,即使没有喂食,狗也被强化了,只要主人按铃,他就会得到食物。强化学习是一个持续的过程,无论是通过刺激还是反馈。
机器学习算法:机器学习算法列表
这里列出了 5 种最常用的机器学习算法。
- 线性回归
- 逻辑回归
- 决策树
- 朴素贝叶斯
- 神经网络
1. 线性回归
它用于根据连续变量估计实际价值(房屋成本、通话次数、总销售额等)。在这里,我们通过拟合最佳线来建立自变量和因变量之间的关系。这条最佳拟合线称为回归线,由线性方程Y= aX + b 表示。
理解线性回归的最好方法是重温这种童年的经历。比方说,你让一个五年级的孩子按照体重增加的顺序排列班级里的人,而不是问他们的体重!你觉得孩子会怎么做?他/她可能会查看(视觉分析)人的身高和体格,并使用这些可见参数的组合来安排他们。这是现实生活中的线性回归!孩子实际上已经发现身高和体格会通过一种关系与体重相关,这看起来像上面的等式。
在这个等式中:
- Y - 因变量
- a – 斜率
- X – 自变量
- b – 拦截
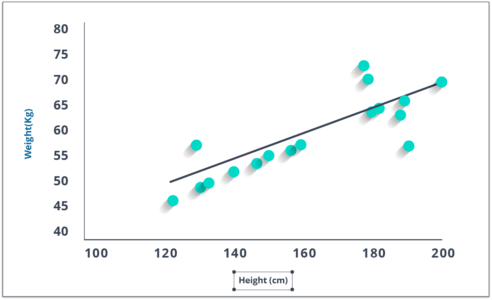
这些系数a和b是基于最小化数据点和回归线之间距离的“平方差总和”得出的。
看看给出的情节。在这里,我们确定了具有线性方程y=0.2811x+13.9的最佳拟合 。现在使用这个方程,我们可以找到体重,知道一个人的身高。
R-代码:
#Load Train and Test datasets
#Identify feature and response variable(s) and values must be numeric and numpy arrays
x_train <- input_variables_values_training_datasets
y_train <- target_variables_values_training_datasets
x_test <- input_variables_values_test_datasets
x <- cbind(x_train,y_train)
# Train the model using the training sets and check score
linear <- lm(y_train ~ ., data = x)
summary(linear)
#Predict Output
predicted= predict(linear,x_test) 2.逻辑回归
不要被它的名字迷惑了!它是一种分类算法,而不是回归算法。它用于根据给定的一组自变量估计离散值(二进制值,如 0/1、yes/no、true/false)。简单来说,它通过将数据拟合到logit 函数来预测事件发生的概率 。因此,它也被称为 logit 回归。由于它预测概率,因此其输出值介于 0 和 1 之间。
再次,让我们通过一个简单的例子来尝试理解这一点。
假设你的朋友给你一个谜题来解决。只有两种结果场景——要么你解决它,要么你不解决。现在想象一下,您正在接受各种各样的谜题/测验,试图了解您擅长哪些科目。这项研究的结果将是这样的——如果给你一个基于三角学的十年级问题,你有 70% 的可能会解决它。另一方面,如果是五年级历史题,得到答案的概率只有30%。这就是逻辑回归为您提供的。
在数学上,结果的对数几率被建模为预测变量的线性组合。
odds= p/ (1-p) = probability of event occurrence / probability of not event occurrence ln(odds) = ln(p/(1-p)) logit(p) = ln(p/(1-p)) = b0+b1X1+b2X2+b3X3....+bkXk上面,p是存在感兴趣特征的概率。它选择使观察样本值的可能性最大化而不是最小化平方误差总和的参数(如在普通回归中)。
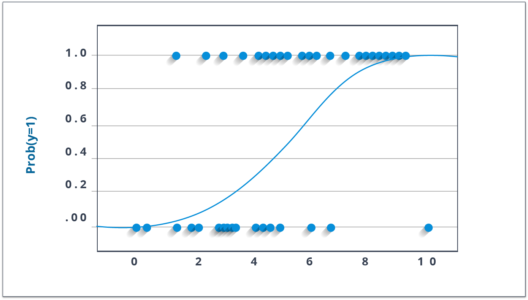
现在,您可能会问,为什么要记录日志?为简单起见,我们只说这是复制阶跃函数的最佳数学方法之一。我可以详细介绍,但这会超出本博客的目的。
R-代码:
x <- cbind(x_train,y_train)
# Train the model using the training sets and check score
logistic <- glm(y_train ~ ., data = x,family='binomial')
summary(logistic)
#Predict Output
predicted= predict(logistic,x_test)可以尝试许多不同的步骤来改进模型:
- 包括交互项
- 去除特征
- 正则化技术
- 使用非线性模型
3. 决策树
现在,这是我最喜欢的算法之一。它是一种监督学习算法,主要用于分类问题。令人惊讶的是,它适用于分类和连续因变量。在这个算法中,我们将种群分成两个或多个同质集。这是基于最重要的属性/自变量来完成的,以尽可能区分不同的组。
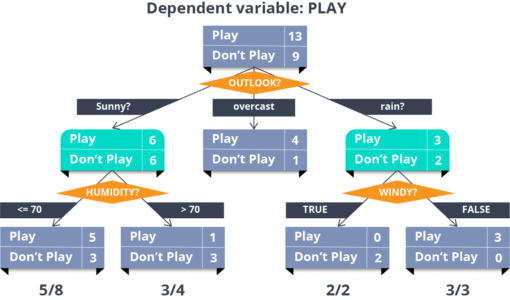
在上图中,您可以看到人口根据多个属性分为四个不同的组,以识别“他们是否会玩”。
R-代码:
library(rpart)
x <- cbind(x_train,y_train)
# grow tree
fit <- rpart(y_train ~ ., data = x,method="class")
summary(fit)
#Predict Output
predicted= predict(fit,x_test)4. 朴素贝叶斯
这是一种基于贝叶斯定理的分类技术 ,假设预测变量之间具有独立性。简单来说,朴素贝叶斯分类器假设类中某个特定特征的存在与任何其他特征的存在无关。
例如,如果水果是红色的、圆形的且直径约 3 英寸,则可以将其视为苹果。即使这些特征相互依赖或依赖于其他特征的存在,朴素贝叶斯分类器也会考虑所有这些属性来独立影响这个水果是苹果的概率。
朴素贝叶斯模型易于构建,尤其适用于非常大的数据集。除了简单之外,朴素贝叶斯的性能甚至优于高度复杂的分类方法。
贝叶斯定理提供了一种从P(c)、P(x)和P(x|c)计算后验概率P(c|x ) 的方法。看看下面的等式:

这里,
- P ( c|x ) 是给定预测变量 ( attribute )的类 ( target ) 的后验概率 。
- P ( c ) 是类的先验概率 。
- P ( x|c ) 是可能性,它是 给定 类别的预测变量的概率 。
- P ( x ) 是预测变量的先验概率 。
例子: 让我们通过一个例子来理解它。下面我有一个天气训练数据集和相应的目标变量“播放”。现在,我们需要根据天气状况对玩家是否会玩进行分类。让我们按照以下步骤来执行它。
第一步:将数据集转换为频数表
第 2 步:通过查找诸如Overcast 概率 = 0.29和播放概率为 0.64 之类的概率来创建似然表。
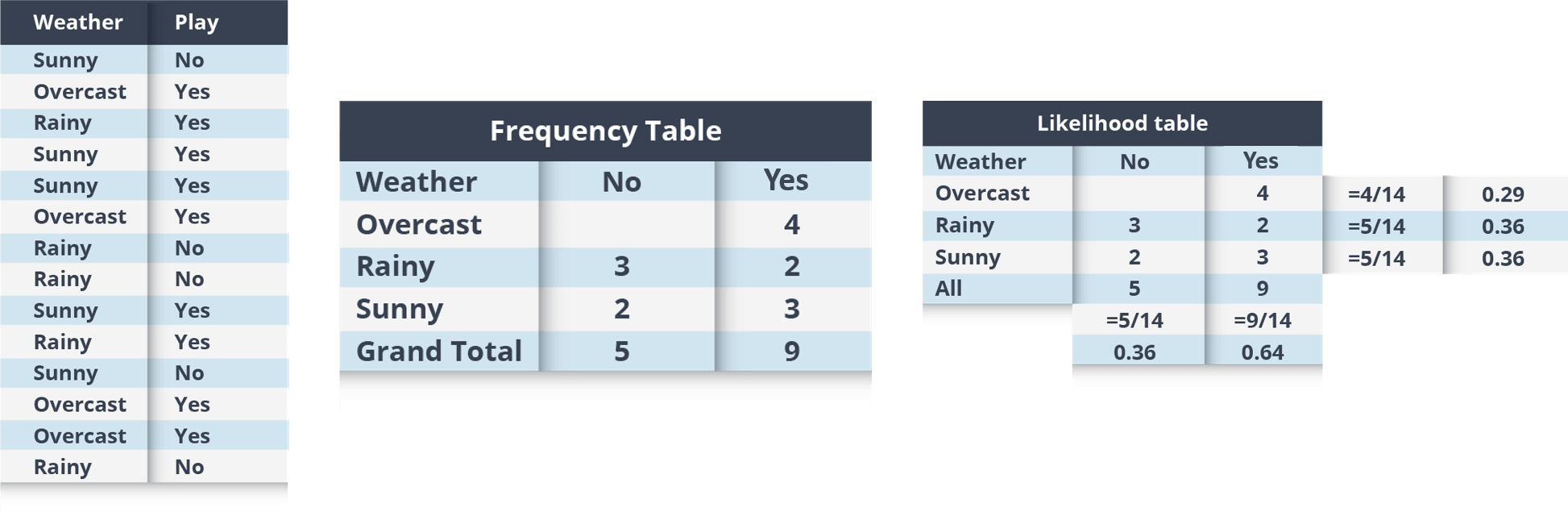
第 3 步:现在,使用朴素贝叶斯方程计算每个类的后验概率。具有最高后验概率的类别是预测的结果。
问题: 如果天气晴朗,玩家会付费,这种说法正确吗?
我们可以使用上面讨论的方法解决它,所以P(Yes | Sunny) = P( Sunny | Yes) * P(Yes) / P (Sunny)
这里我们有P (Sunny |Yes) = 3/9 = 0.33 , P(Sunny) = 5/14 = 0.36 , P(Yes)= 9/14 = 0.64
现在,P (Yes | Sunny) = 0.33 * 0.64 / 0.36 = 0.60,概率更高。
朴素贝叶斯使用类似的方法根据各种属性预测不同类别的概率。该算法主要用于文本分类和多类问题。
R-代码:
library(e1071)
x <- cbind(x_train,y_train)
# Fitting model
fit <-naiveBayes(y_train ~ ., data = x)
summary(fit)
#Predict Output
predicted= predict(fit,x_test)5. kNN(k-最近邻)
它可以用于分类和回归问题。但是,它在行业中更广泛地用于分类问题。 K 个最近邻 是一种简单的算法,它存储所有可用案例并通过其 k 个邻居的多数票对新案例进行分类。分配给该类的案例在由距离函数测量的 K 个最近邻中最为常见。
这些距离函数可以是欧几里得距离、曼哈顿距离、闵可夫斯基距离和汉明距离。前三个函数用于连续函数,第四个 (Hamming) 用于分类变量。如果K = 1,则将案例简单地分配给其最近邻居的类。有时,在执行 kNN 建模时选择 K 是一个挑战。
KNN 可以很容易地映射到我们的现实生活中。如果您想了解一个您没有信息的人,您可能想了解他的密友和他所在的圈子,并获得他/她的信息!
R-代码:
library(knn)
x <- cbind(x_train,y_train)
# Fitting model
fit <-knn(y_train ~ ., data = x,k=5)
summary(fit)
#Predict Output
predicted= predict(fit,x_test)选择 KNN 前需要考虑的事项:
- KNN 的计算成本很高
- 变量应该归一化,否则更高范围的变量会使它产生偏差
- 在使用 kNN 之前更多地进行预处理阶段,如异常值、噪声去除
这让我结束了这篇博客。请继续关注有关机器学习和数据科学的更多内容!

- 点赞
- 收藏
- 关注作者
评论(0)