给自己搭个陪聊机器人

【摘要】 周末被隔离在酒店,难得清闲,不由得想给自己搞个陪聊机器人。也许python就是这个诞生的,只是他的创造者太牛,哈哈。。。先上成果,有兴趣的可以上我的个人网站体验下http://www.gchatst.club:8050/,顶部单选框选闲聊机器人。1. 对话的生成实事上通用的闲聊,现在技术已经非常成熟了。1.1. 技术选型玩玩嘛,也不需要比较了,我们直接选择百度飞浆吧。百度飞浆一共有三个预训练...
周末被隔离在酒店,难得清闲,不由得想给自己搞个陪聊机器人。也许python就是这个诞生的,只是他的创造者太牛,哈哈。。。
先上成果,有兴趣的可以上我的个人网站体验下http://www.gchatst.club:8050/,顶部单选框选闲聊机器人。

1. 对话的生成
实事上通用的闲聊,现在技术已经非常成熟了。
1.1. 技术选型
玩玩嘛,也不需要比较了,我们直接选择百度飞浆吧。
百度飞浆一共有三个预训练模型:
-
unified_transformer-12L-cn:在大规模中文会话数据集上训练得到; -
unified_transformer-12L-cn-luge:unified_transformer-12L-cn在千言对话数据集上进行微调得到; -
plato-mini:使用十亿级别的中文闲聊对话数据进行训练得到。
有兴趣的同学也可以自己去微调。
正式使用前,首先要安装飞浆的NLP模块。
pip install paddlenlp
然后还需要安装一个依赖。
pip install sentencepiece
1.2. 对话生成流程
简单地说,对话的生成流程包括三步。第一步,把冰箱门打开;第二步,把大象装进去;第三步,把冰箱门关上。
这当然是开玩笑,但确实非常像。第一步是让机器人理解我们说了什么,即把我们的语言翻译成机器人能够理解的语言;第二步是让机器人进行处理,生成它想说的话;第三步是将机器人的语言转化为我们的语言,从而让我们能够看懂机器人说了什么。
下面我们分三步来实现。
1.3. 让机器人理解我们的语言
这一步也可以叫做NLU,自然语言理解。哈哈,帽子戴大了。。
飞浆的框架让这一步的实现非常简单。这里,我们选择用plato-mini模型。
from paddlenlp.transformers import UnifiedTransformerTokenizer
model_name = 'plato-mini'
tokenizer = UnifiedTransformerTokenizer.from_pretrained(model_name)
然后,通过tokenizer就可以将我们的语言转化为机器人能理解的语言。比如:”你懂财务吗?“
user_input = ['你懂财务吗?']
encoded_input = tokenizer.dialogue_encode(
user_input,
add_start_token_as_response=True,
return_tensors=True,
is_split_into_words=False)
机器人收到的将是这样的
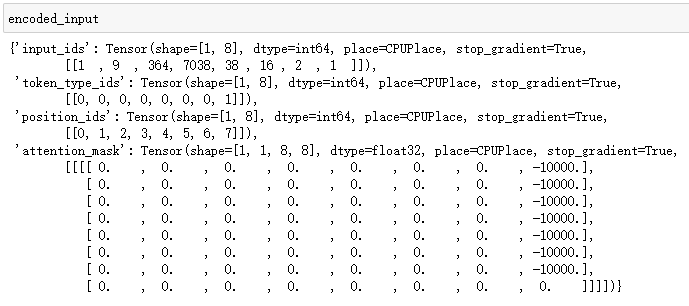
1.4 让机器人生成它的回复
ids, scores = model.generate(
input_ids=encoded_input['input_ids'],
token_type_ids=encoded_input['token_type_ids'],
position_ids=encoded_input['position_ids'],
attention_mask=encoded_input['attention_mask'],
max_length=64,
min_length=1,
decode_strategy='sampling',
top_k=5,
num_return_sequences=20)
生成也很简单,但正常人肯定看不懂它的回复

因此,我们不得不需要第三步。
1.5. 将机器人的语言翻译成我们的语言
这一步也很简单,大部分文献上用如下代码就实现了
from utils import select_response
# 简单根据概率选取最佳回复
result = select_response(ids, scores, tokenizer, keep_space=False, num_return_sequences=20)
print(result)
但可惜我的utils模块里没有select_response这个方法,而且我实在找不到哪里有这个方法,只能用了个相对笨一点的方法
generated_ids = ids[0].numpy().tolist()
# 使用tokenizer将生成的id转为文本
generated_text = tokenizer.convert_ids_to_string(generated_ids).replace('[SEP]', '').replace('[UNK]','').replace(' ', '')
print(generated_text)

这个结果我们就能看懂了。
而且,多试几次我们可以看到,机器人的回答并不是唯一的,而是有一定随机性的。
参考文献:
-
https://mp.weixin.qq.com/s/R2sWlo66OGP2iFeRmSH-rg -
https://blog.csdn.net/m0_63642362/article/details/121220376 -
https://aistudio.baidu.com/aistudio/projectdetail/2249579
【版权声明】本文为华为云社区用户原创内容,转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息, 否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)