深度学习入门之神经网络

神经网络的一个重要性质是可以自动地从数据中学习到合适的权重参数
从感知机到神经网路
神经网络与上一章的感知机有很多共同点,主要以两者差异为中心,介绍神经网络的结构
神经网络的例子

左边一列为输入层,最右边一列称为输出层,中间的一列称为中间层(隐藏层)
改写之前的感知数学式
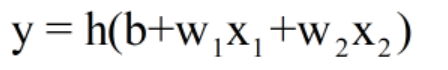
引入新函数h(x)
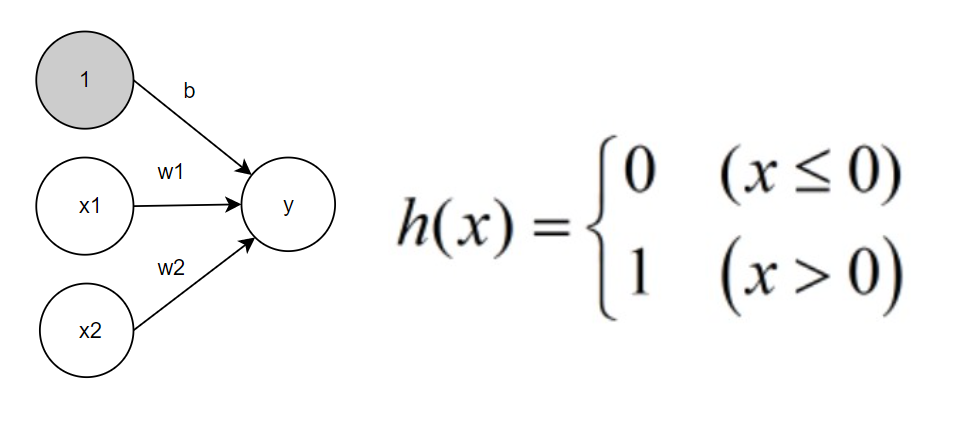
输入信号的总和会被h(x)转换,转换后的值就是输出y
激活函数出场
上面的h(x)函数就是激活函数(activation function)
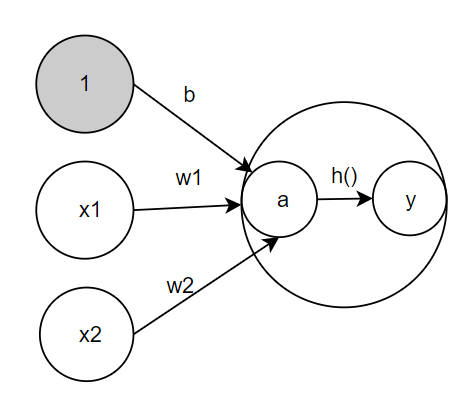
信号的加权总和为节点a,然后节点a被激活函数h()转换成节点y。
神经元和节点两个术语含义相同
激活函数
上面的激活函数以阈值为界,输入一超过阈值,就切换输出,这样的函数称为“阶跃函数”,神经网络用的是其他的激活函数
sigmoid函数
经常使用的就是这一个sigmoid函数
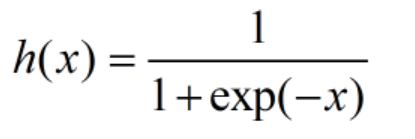
更常见的是这个写法
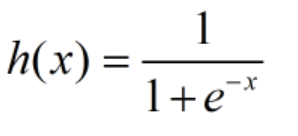
e是纳皮尔常数2.718281828459045…
阶跃函数的实现
def step_func(x):
if x > 0:
return 1
else:
return 0
实现简单,但参数x只接受实数,将其修改为支持numpy数组的实现
import numpy as np
def step_func(x):
y = x > 0
return y.astype(np.int)
阶跃函数的图形
import numpy as np
import matplotlib.pyplot as plt
def step_func(x):
return np.array(x>0,dtype=np.int)
x = np.arange(-5.0,5.0,0.1)
y = step_func(x)
plt.plot(x,y)
plt.ylim(-0.1,1.1)
plt.show()
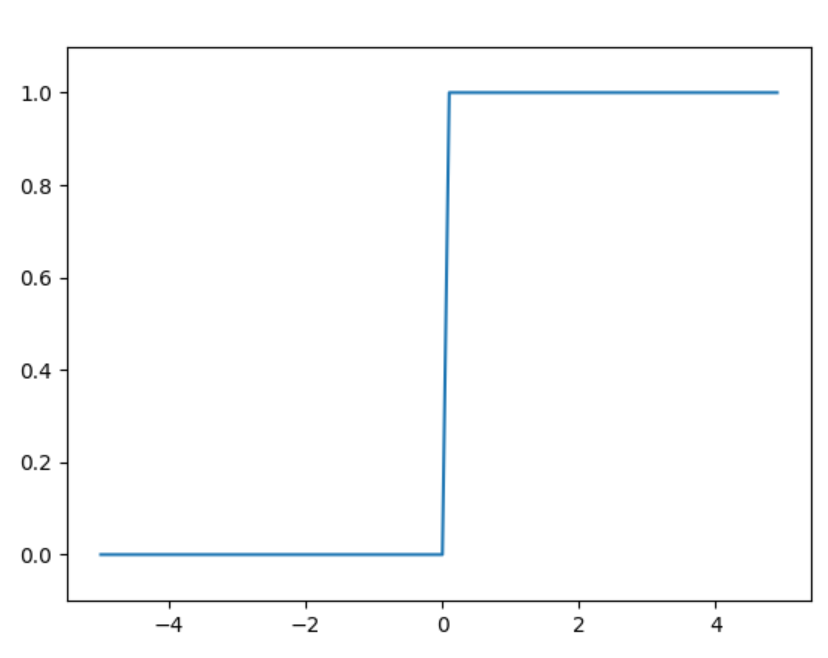
以0为界,输出从0换到1,值呈阶梯式变化,所以称为阶梯函数
sigmoid函数的实现
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.arange(-5.0,5.0,0.1)
y = sigmoid(x)
plt.plot(x,y)
plt.ylim(-0.1,1.1)
plt.show()
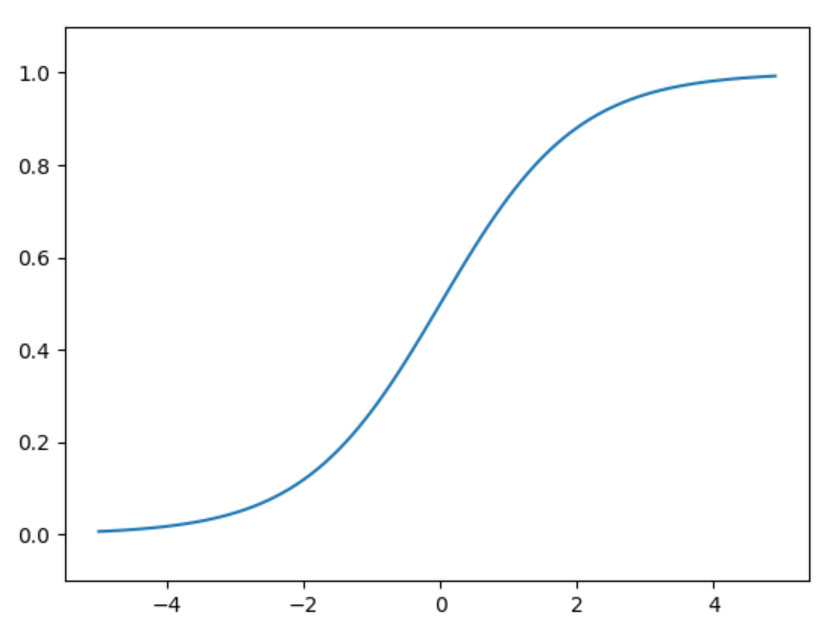
sigmoid函数和阶跃函数的比较
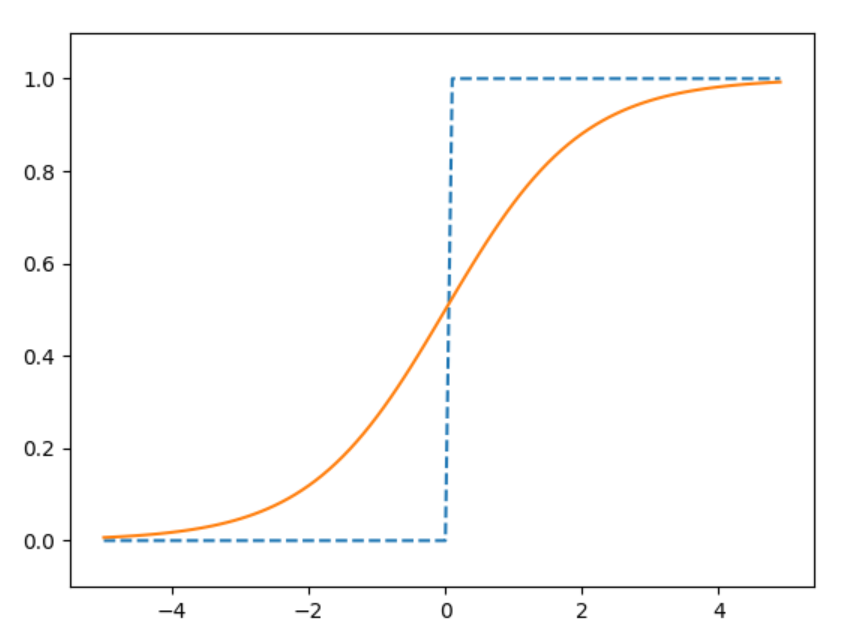
sigmoid是一条平滑的曲线,输出随着输入发生连续性的变化。而阶跃函数以0为界,输出发生急剧性的变化。sigmoid函数的平滑性对神经网络的学习具有重要意义。
非线性函数
sigmoid函数与阶跃函数还有个共同点,就是两者均为非线性函数。神经网络的激活函数必须使用非线性函数,因为线性函数进行神经网络的叠层没有意义。
ReLU函数
最近的激活函数有ReLU(Rectified Linear Unit)函数
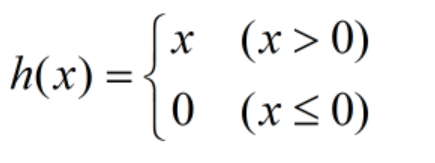
也是一个非常简单的函数
import numpy as np
import matplotlib.pyplot as plt
def relu(x):
return np.maximum(0,x)
x = np.arange(-5.0,5.0,0.1)
y = relu(x)
plt.plot(x,y)
plt.ylim(-0.1,6)
plt.show()
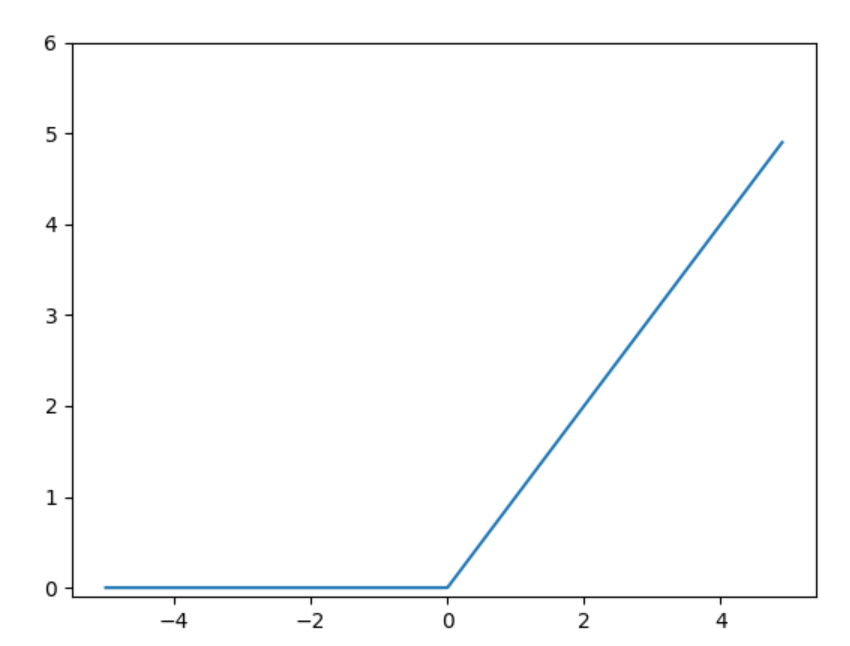
这里使用了numpy的maximum函数。maximum函数会从输入的数值中选择较大的那个值进行输出
多维数组的运算
掌握numpy多维数组的运算,就能高效的实现神经网络
多维数组
多维数组就是数字的集合,例如下面的一维数组
import numpy as np
A = np.array([1,2,3,4])
print(np.ndim(A))
print(A.shape)
print(A.shape[0])
数组的维数可以通过np.ndim()函数获得,数组的形状通过实例变量shape获得
B = np.array([[1,2],[3,4],[5,6]])
print(np.ndim(B))
print(B.shape)
print(B.shape[0])
3×2的数组B表示第一个维度有3个元素,第二个维度有2个元素。二维数组也被称为矩阵,数组的横向排列称为行(row),纵向排列称为列(column)
矩阵乘法
线性代数的知识
import numpy as np
A = np.array([[1,2,3],[4,5,6]])
B = np.array([[1,2],[3,4],[5,6]])
print(np.dot(A,B))
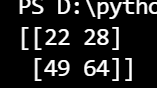
运行结果矩阵的形状是由矩阵A的行数和矩阵B的列数构成的
3层神经网络的实现
符号确认
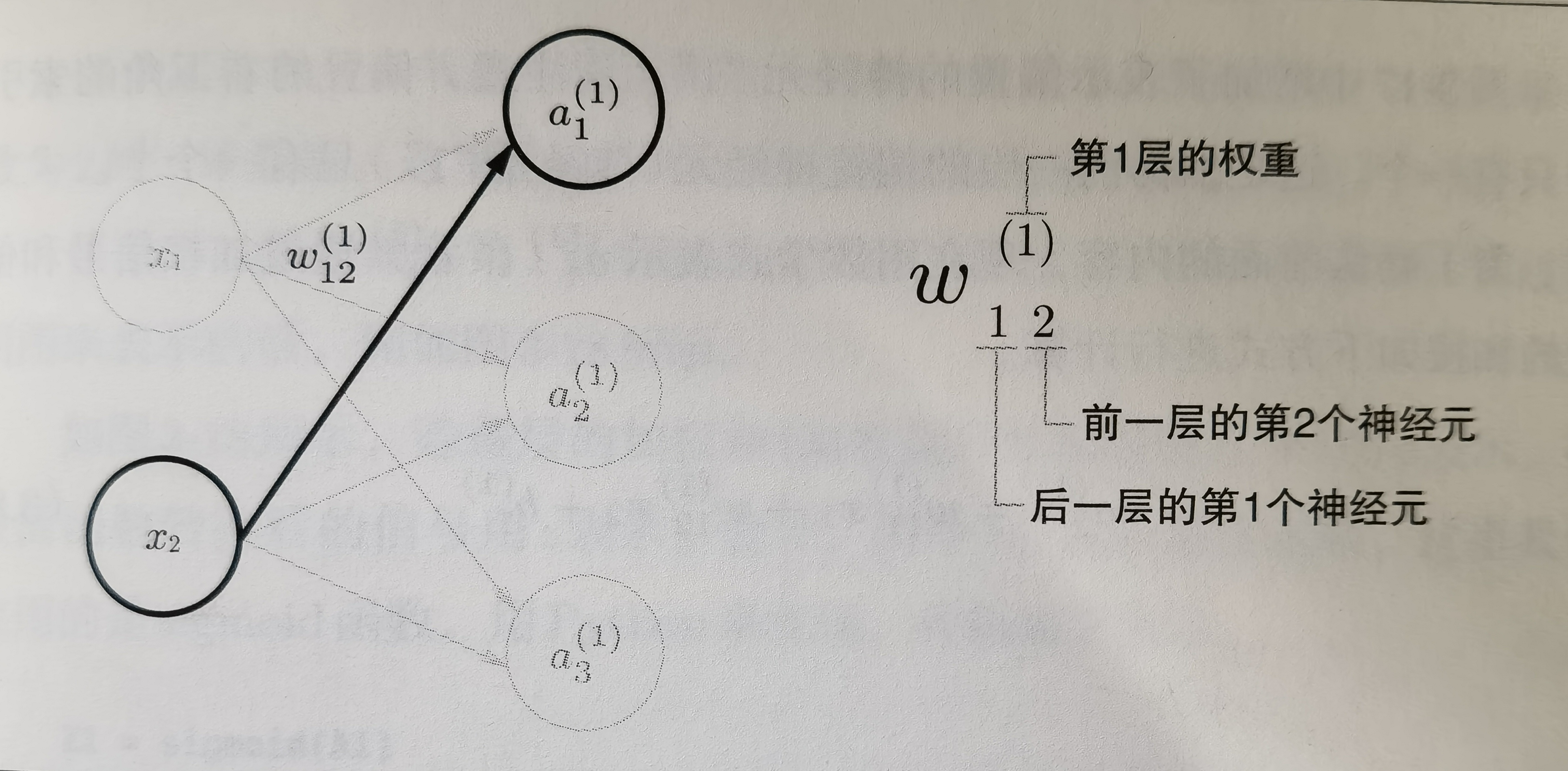
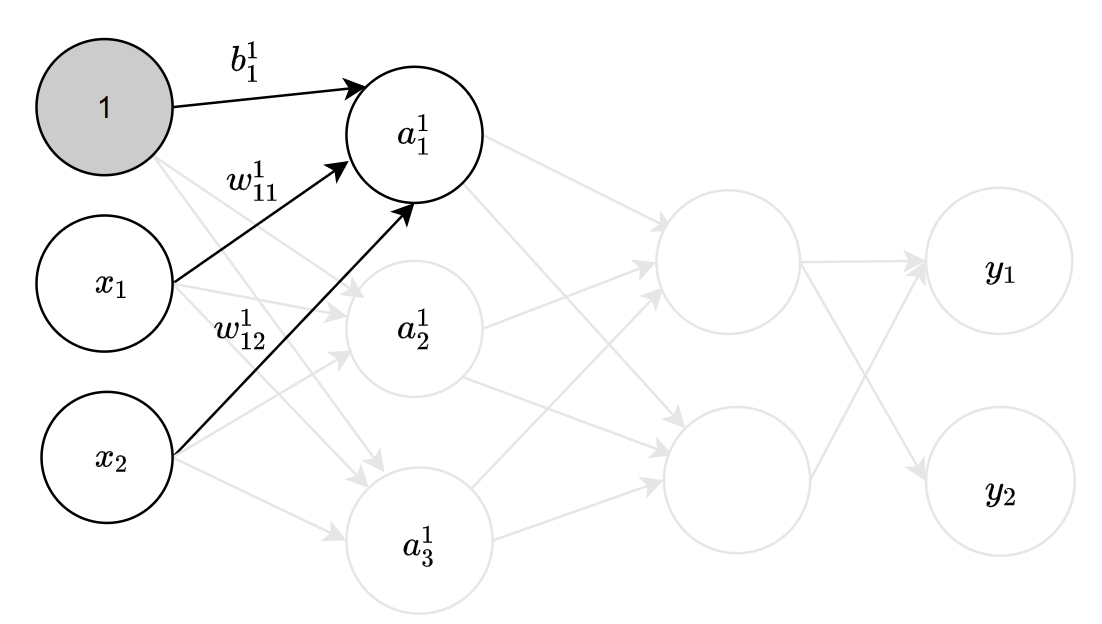
各层间信号传递的实现
从输入层到第一层的第一个神经元的信号传递过程
通过加权信号和偏置的和按如下方式进行计算:
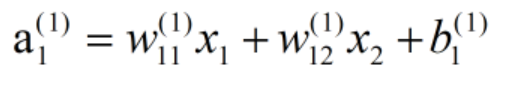
使用矩阵的乘法运算,可以将第一层的加权和表示成以下的式子:
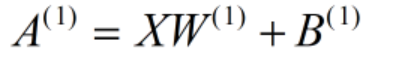
用numpy多维数组来实现式
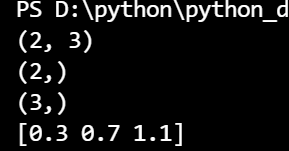
import numpy as np
X = np.array([1.0,0.5])
W1 = np.array([[0.1,0.3,0.5],[0.2,0.4,0.6]])
B1 = np.array([0.1,0.2,0.3])
print(W1.shape)
print(X.shape)
print(B1.shape)
A1 = np.dot(X,W1)+B1
print(A1)
代码实现小结
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def identity_function(x):
return x
def init_network():
network = {}
network['W1'] = np.array([[0.1,0.3,0.5],[0.2,0.4,0.6]])
network['b1'] = np.array([0.1,0.2,0.3])
network['W2'] = np.array([[0.1,0.4],[0.2,0.5],[0.3,0.6]])
network['b2'] = np.array([0.1,0.2])
network['W3'] = np.array([[0.1,0.3],[0.2,0.4]])
network['b3'] = np.array([0.1,0.2])
return network
def forword(network,x):
W1,W2,W3 = network['W1'],network['W2'],network['W3']
b1,b2,b3 = network['b1'],network['b2'],network['b3']
a1 = np.dot(x,W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1,W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2,W3) + b3
y = identity_function(a3)
return y
network = init_network()
x = np.array([1.0,0.5])
y = forword(network,x)
print(y)

init_network()函数会进行权重和偏置的初始化,并将其保存在字典变量network中,字典变量network中保存了每一层所需的参数(权重和偏置)。forward()函数中封装了将输入信号转换为输出信号的处理过程。
输出层的设计
神经网络可以用在分类问题和回归问题上,需要根据情况改输出层的激活函数。
一般来说,回归问题用恒等函数,分类问题用softmax函数。
恒等函数和softmax函数
恒等函数对于输入的信息,会不加以任何改动地直接输出
分类问题中使用的softmax函数可以用以下式表示
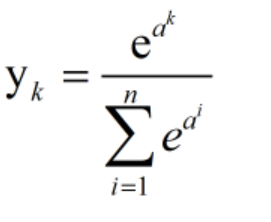
分子是输入信号
的指数函数,分母是所有输入信号的指数函数的和
import numpy as np
a = np.array([0.3,2.9,4.0])
exp_a = np.exp(a)
print(exp_a)
sum_exp_a = np.sum(exp_a)
print(sum_exp_a)
y = exp_a / sum_exp_a
print(y)

修改成函数
def softmax(a):
exp_a = np.exp(a)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
实现softmax函数时的注意事项
softmax函数在计算机运行上会出现溢出的缺陷,指数运算的值会变得很大,可以进行以下的修改:
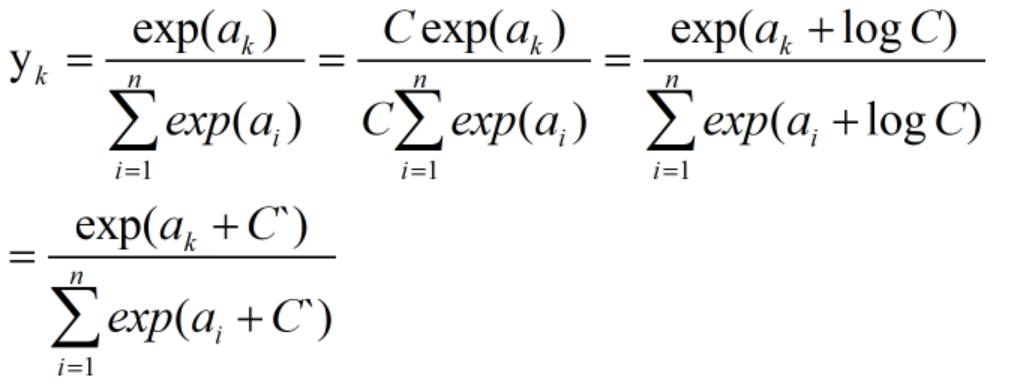
def softmax(a):
c = np.max(a)
exp_a = np.exp(a-c) # 溢出对策
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
softmax函数的特征
a = np.array([0.3,2.9,4.0])
y = softmax(a)
print(y)
print(np.sum(y))

softmax函数的输出是0.0到1.0之间的实数,并且softmax函数的输出值的总和为1,这也是该函数的一个重要性质,才可以把函数的输出解释为概率
输出层的神经元数量
根据待解决的问题来决定。对于分类问题,输出层的神经元数量一般设定为类别的数量。例如预测手写数字就是将输出层的神经元设定为10个。
手写数字识别
介绍完结构,来解决实际问题。进行手写数字图像的分类,先进行神经网络的推理处理,这个推理处理也称为神经网络的前向传播(forward propagation)
MNIST数据集
MNIST数据集是由0到9的数字图像构成,训练图像有6万张,测试图像有1万张,这些图像可以用于学习和推理。一般是先用训练图像进行学习,再用学习到的模型度量能在多大程度上对测试图像进行正确的分类。
# coding: utf-8
try:
import urllib.request
except ImportError:
raise ImportError('You should use Python 3.x')
import os.path
import gzip
import pickle
import os
import numpy as np
url_base = 'http://yann.lecun.com/exdb/mnist/'
key_file = {
'train_img':'train-images-idx3-ubyte.gz',
'train_label':'train-labels-idx1-ubyte.gz',
'test_img':'t10k-images-idx3-ubyte.gz',
'test_label':'t10k-labels-idx1-ubyte.gz'
}
dataset_dir = os.path.dirname(os.path.abspath(__file__))
save_file = dataset_dir + "/mnist.pkl"
train_num = 60000
test_num = 10000
img_dim = (1, 28, 28)
img_size = 784
def _download(file_name):
file_path = dataset_dir + "/" + file_name
if os.path.exists(file_path):
return
print("Downloading " + file_name + " ... ")
urllib.request.urlretrieve(url_base + file_name, file_path)
print("Done")
def download_mnist():
for v in key_file.values():
_download(v)
def _load_label(file_name):
file_path = dataset_dir + "/" + file_name
print("Converting " + file_name + " to NumPy Array ...")
with gzip.open(file_path, 'rb') as f:
labels = np.frombuffer(f.read(), np.uint8, offset=8)
print("Done")
return labels
def _load_img(file_name):
file_path = dataset_dir + "/" + file_name
print("Converting " + file_name + " to NumPy Array ...")
with gzip.open(file_path, 'rb') as f:
data = np.frombuffer(f.read(), np.uint8, offset=16)
data = data.reshape(-1, img_size)
print("Done")
return data
def _convert_numpy():
dataset = {}
dataset['train_img'] = _load_img(key_file['train_img'])
dataset['train_label'] = _load_label(key_file['train_label'])
dataset['test_img'] = _load_img(key_file['test_img'])
dataset['test_label'] = _load_label(key_file['test_label'])
return dataset
def init_mnist():
download_mnist()
dataset = _convert_numpy()
print("Creating pickle file ...")
with open(save_file, 'wb') as f:
pickle.dump(dataset, f, -1)
print("Done!")
def _change_one_hot_label(X):
T = np.zeros((X.size, 10))
for idx, row in enumerate(T):
row[X[idx]] = 1
return T
def load_mnist(normalize=True, flatten=True, one_hot_label=False):
"""读入MNIST数据集
Parameters
----------
normalize : 将图像的像素值正规化为0.0~1.0
one_hot_label :
one_hot_label为True的情况下,标签作为one-hot数组返回
one-hot数组是指[0,0,1,0,0,0,0,0,0,0]这样的数组
flatten : 是否将图像展开为一维数组
Returns
-------
(训练图像, 训练标签), (测试图像, 测试标签)
"""
if not os.path.exists(save_file):
init_mnist()
with open(save_file, 'rb') as f:
dataset = pickle.load(f)
if normalize:
for key in ('train_img', 'test_img'):
dataset[key] = dataset[key].astype(np.float32)
dataset[key] /= 255.0
if one_hot_label:
dataset['train_label'] = _change_one_hot_label(dataset['train_label'])
dataset['test_label'] = _change_one_hot_label(dataset['test_label'])
if not flatten:
for key in ('train_img', 'test_img'):
dataset[key] = dataset[key].reshape(-1, 1, 28, 28)
return (dataset['train_img'], dataset['train_label']), (dataset['test_img'], dataset['test_label'])
if __name__ == '__main__':
init_mnist()
使用脚本mnist.py,读入MNIST数据
import sys, os
sys.path.append(os.pardir)
from mnist import load_mnist
# 第一次调用会花费几分钟...
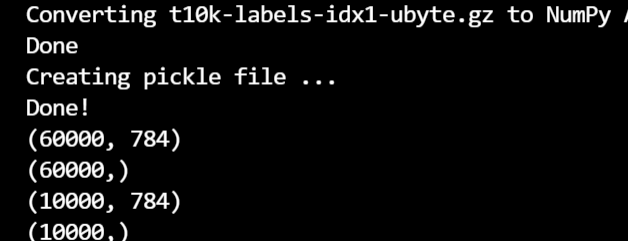
(x_train,t_train),(x_test,t_test) = load_mnist(flatten=True,normalize=False)
# 输出各个数据的形状
print(x_train.shape)
print(t_train.shape)
print(x_test.shape)
print(t_test.shape)
使用PIL(Python Image Library)模块显示mnist图像
import sys, os
sys.path.append(os.pardir)
import numpy as np
from mnist import load_mnist
from PIL import Image
def img_show(img):
pil_img = Image.fromarray(np.uint8(img))
pil_img.show()
(x_train,t_train),(x_test,t_test) = load_mnist(flatten=True,normalize=False)
img = x_train[0]
label = t_train[0]
print(label)
print(img.shape)
img = img.reshape(28,28)
print(img.shape)
flatten=True读入图像是以一维numpy数组形式保存,显示时要变为原来的28×28像素形状,比如通过reshape方法,fromarray()是将保存的numpy数组的图像数据转换为PIL用的数据对象
神经网络的推理处理
输入层有784(28×28)个神经元,输出层有10(0~9的10类别)个神经元
此外这个神经网络有2个隐藏层,第一个隐藏层有50个神经元,第二个有100个神经元
定义三个函数:
def get_data():
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False)
return x_test, t_test
def init_network():
with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f)
return network
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = softmax(a3)
return y
用这三个函数来实现神经网络的推理过程,并评价识别精度
x, t = get_data()
network = init_network()
accuracy_cnt = 0
for i in range(len(x)):
y = predict(network, x[i])
p= np.argmax(y) # 获取概率最高的元素的索引
if p == t[i]:
accuracy_cnt += 1
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))
批处理
用来打包输入多张图片,例如输入100×784形状的数据,输出数据的形状为100×10,打包式的输入数据称为批(batch)
x,t = get_data()
network = init_network()
batch_size = 100
accuracy_cnt = 0
for i in range(0,len(x),batch_size):
x_batch = x[i:i+batch_size]
y_batch = predict(network,x_batch)
p = np.argmax(y_batch,axis=1)
accuracy_cnt += np.sum(p == t[i:i+batch_size])
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))

- 点赞
- 收藏
- 关注作者
评论(0)