CNN模型合集 | Resnet变种-WideResnet解读

所要解决的问题
Resnet被证明能够扩展到数千层,并且仍然具有改进的性能。然而,每提高一个百分点的精确度,就要花费将近两倍的层数,因此训练非常深的Resnet存在着减少特征重用的问题,这使得这些网络的训练速度非常慢。为所以该篇论文提出了一种新的体系结构,减少了网络的深度,增加了网络的宽度,这种结构称为宽残差网络(WRN),宽度即网络输出通道数,并通过实验证明它们远远优于常用的薄而深的网络结构。
设计思想
-
提出了一种新的加宽网络,以提高模型性能;
-
增加深度和宽度都有好处,但都会参数太大,导致正则化不够容易过拟合,wide-resnet使用
dropout来正则化,防止模型训练过拟合; -
提高训练速度,相同参数,WideResNet的训练速度快于ResNet。
简介
网络

如上图所示,wide-resnet只比Resnet多了一个加宽因子k,原来架构相当于K=1,N表示组中的块数。
网络由一个初始卷积层conv1组成,然后是residual block的conv2、conv3和conv4的3组(每个大小为N),然后是平均池和最终分类层。在实验中,conv1的大小都是固定的,而引入的加宽因子k缩放了三组conv2-4中剩余块的宽度。
与原始架构相比,residual block中的批量归一化、激活和卷积的顺序从conv-BN-ReLU更改为BN-ReLU-conv。 卷积核都用3*3;正则化使用dropout,而ResNet用的BN在这里不好用了。
结构单元
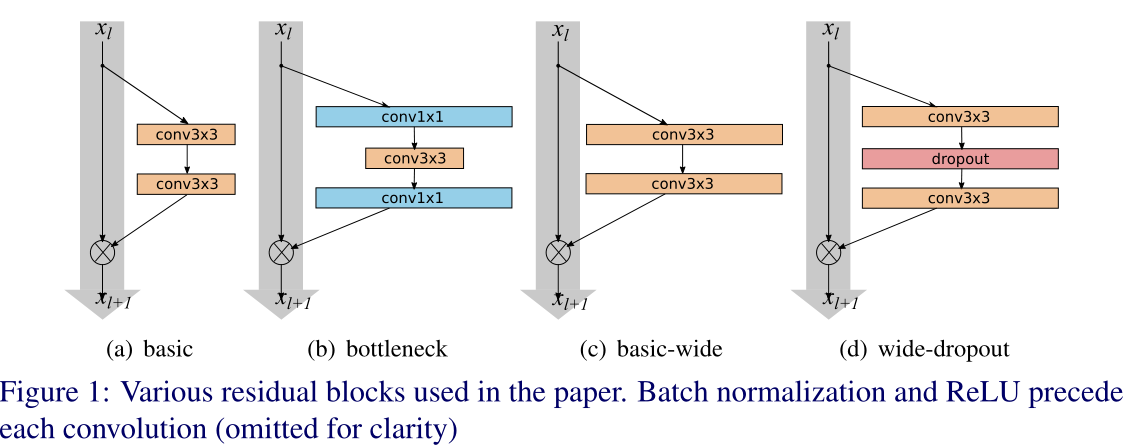
结构单元
-
a是最基本的ResNet结构,b 是用了bottleneck(瓶颈)的ResNet结构;
-
d是在最基本的ResNet结构上加入dropout层的WideResNet结构。
增加Conv的Output channels数目即使用更多的conv filters进行计算,所谓的增宽block;
Residual block里面使用的conv层次结构
设B(M)表示剩余块结构,其中M是块中卷积层的核大小列表。例如,B(3,1)表示具有3×3和1×1两个卷积层的剩余块,B(3,1,1)表示3×3和1×1和1×1三个卷积层组成,以此类推;作者做实验设计了几个不同的conv层次,以此来验证residual block中最佳的conv结构。

设计的不同conv层次结构
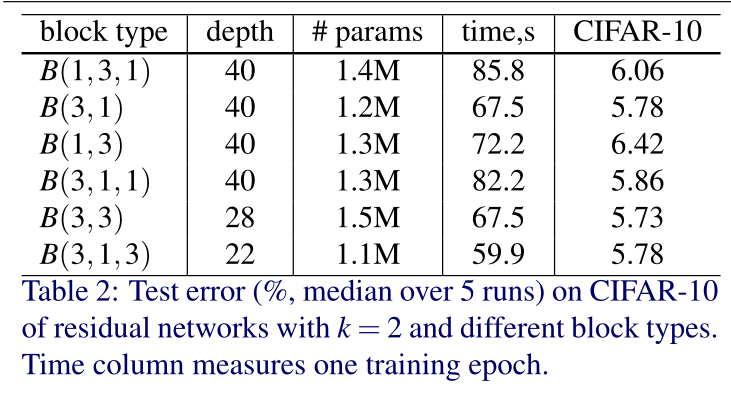
实验结果
下图为以上各个结构最终能够获得的分类结果比较(注意在实验时作者为保证训练所用参数相同,因此不同类型block构成的网络的深度会有不同)。可见B(3,3)能取得最好的结果,这也证明了常用Residual block的有效性接下来的实验中,作者保持了使用B(3,3)这种Residual block结构。
Residual block中的conv层数
以l表示单个Residual block里面conv层的数目,以d表示整体网络所具有的residual blocks的数目。通过保持整体训练所用参数不变,作者研究、分析了residual block内conv层数目不同所带来的性能结果差异。从中我们能够看出residual block里面包含2个conv层分类性能可达最优。

l数目对比结果
Residual block内宽度
k表示wide-resnet加宽因子,当我们增加加宽参数k时,必须保持总参数不变。为了找到一个最佳的数值,我们用k从2到12,深度从16到40进行实验。结果如下表所示。可以看出,当宽度因子从1增加到12时,所有具有40、22和16层的网络都可以看到精度上升。另一方面,当保持相同的固定加宽系数k=8或k=10且深度从16变为28时,也能提升相关性能,但是当我们进一步将深度增加到40时,精度会降低(例如,WRN-40-8的精度会降低到WRN-22-8)。

Residual block中Dropout的引入
加宽Residual block势必会带来训练参数的增加,为了避免模型陷入过拟合,作者在Residual block中引入了dropout。另外作者实验表明将Dropout加入在conv层之后比加入在identity mapping连接上可带来更好的效果。因此这里引入的Dropout被放在了Conv出来后的ReLu之后。下图中的结果反映出了Dropout带来的性能提升。

Dropout引入对网络性能的影响
如下图所示,总的来说,dropout显示出其自身是一种有效的正则化技术。它可以用来进一步改善加宽的结果,同时也是对加宽因子的补充。与传统的细高Resnet相比,矮胖WRN可具有更好的精度。

绿色的线表示wide-resnet损失误差曲线,红色表示原resnet损失曲线
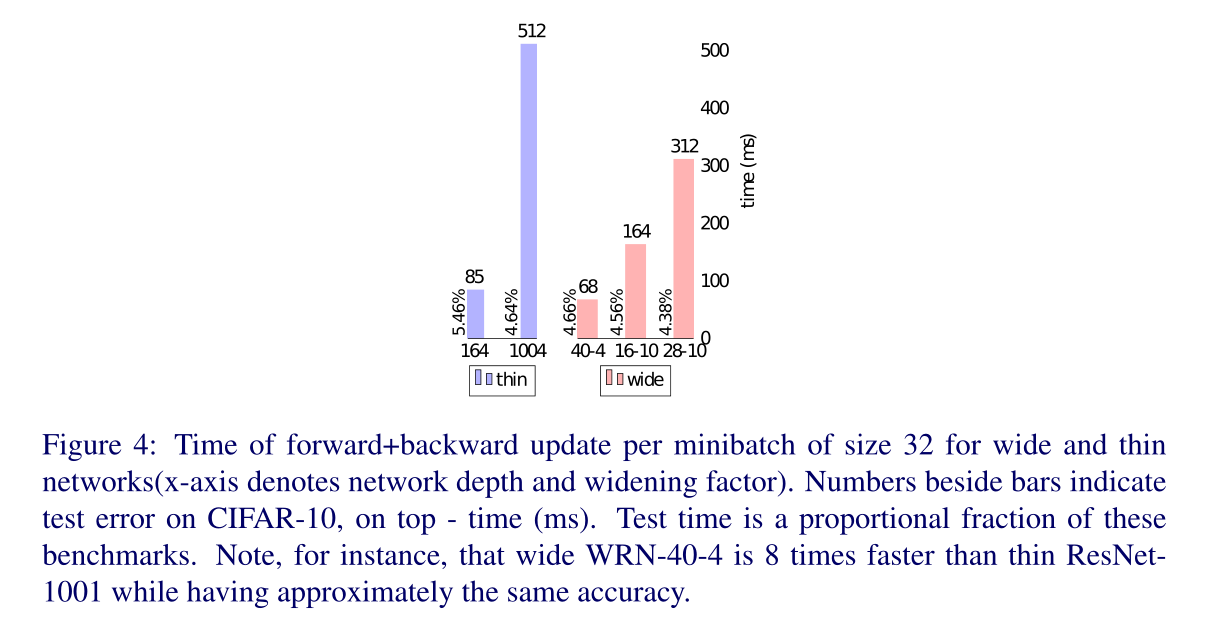
计算效率
如下图所示,条形图旁边的数字表示CIFAR-10上的测试错误,顶部时间(ms)。测试时间是这些基准的比例分数。例如,宽WRN-40-4的速度是薄ResNet1001的8倍,同时具有大致相同的精度。
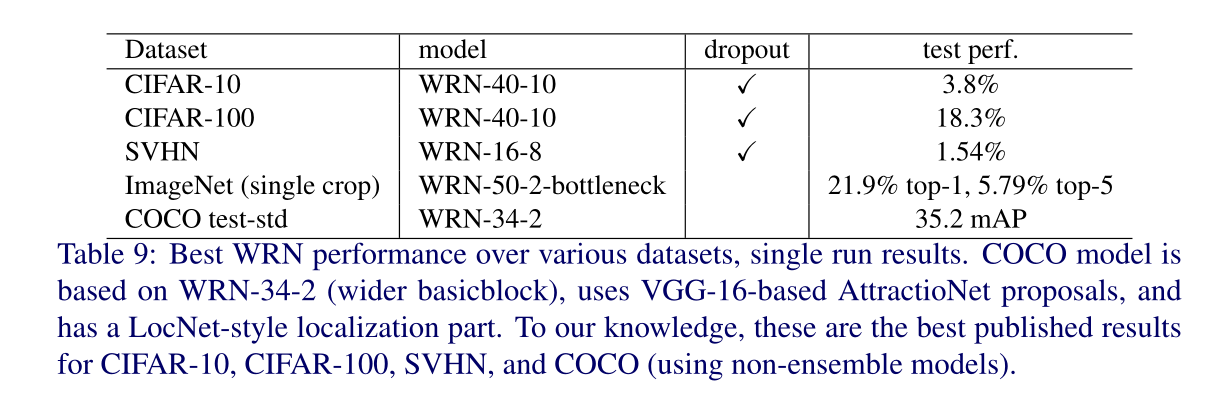
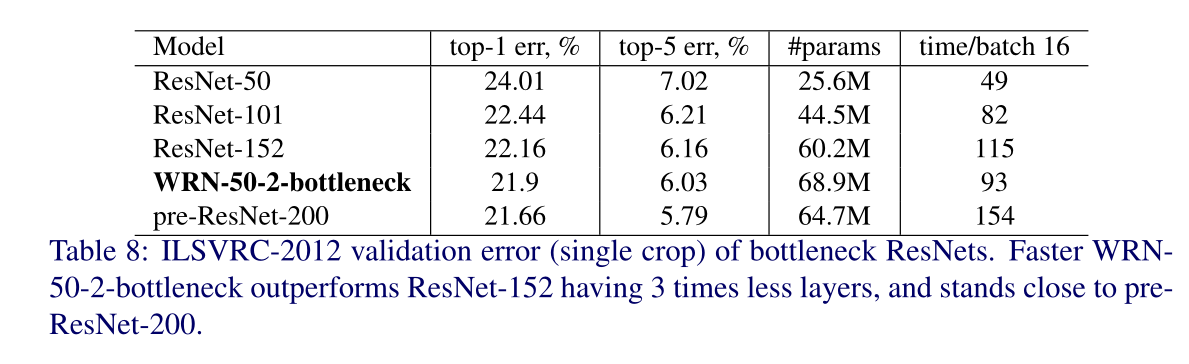
一些对比实验结果
文章来源: blog.csdn.net,作者:小小谢先生,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/xiewenrui1996/article/details/125356309

- 点赞
- 收藏
- 关注作者
评论(0)