【深度学习 | Transformer】释放注意力的力量:探索深度学习中的 变形金刚,一文带你读通各个模块


🤵♂️ 个人主页: @AI_magician
📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。
👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!🐱🏍
🙋♂️声明:本人目前大学就读于大二,研究兴趣方向人工智能&硬件(虽然硬件还没开始玩,但一直很感兴趣!希望大佬带带)

摘要: 本系列旨在普及那些深度学习路上必经的核心概念,文章内容都是博主用心学习收集所写,欢迎大家三联支持!本系列会一直更新,核心概念系列会一直更新!欢迎大家订阅
该文章收录专栏
[✨— 《深入解析机器学习:从原理到应用的全面指南》 —✨]
Transformer
注意力(Attention)机制由Bengio团队与2014年提出并在近年广泛的应用在深度学习中的各个领域,例如在计算机视觉方向用于捕捉图像上的感受野,或者NLP中用于定位关键token或者特征。谷歌团队近期提出的用于生成词向量的BERT算法在NLP的11项任务中取得了效果的大幅提升,堪称2018年深度学习领域最振奋人心的消息。而BERT算法的最重要的部分便是本文中提出的Transformer的概念。
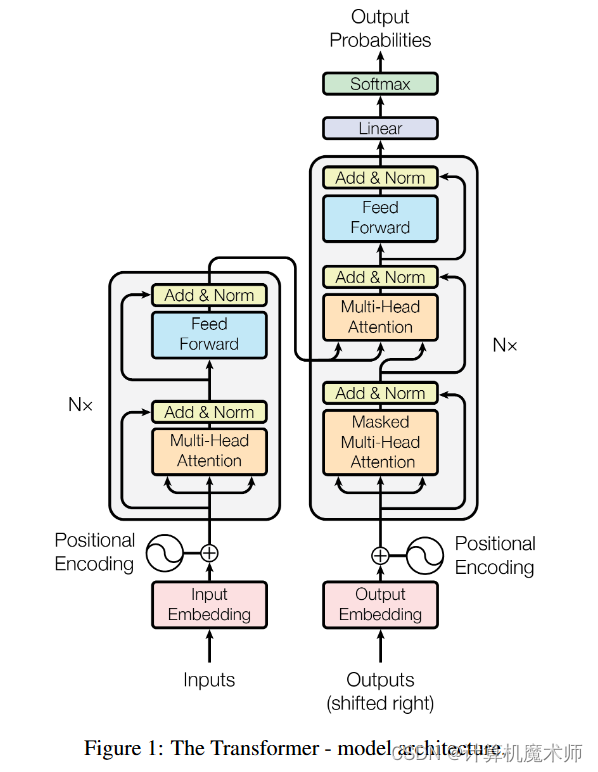
背景和动机
作者采用Attention机制的原因是考虑到RNN(或者LSTM,GRU等)的计算限制为是顺序的,也就是说RNN相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
时间片 t 的计算依赖 t−1 时刻的计算结果,这样限制了模型的并行能力;
传统的序列模型(如循环神经网络)存在着长期依赖问题,难以捕捉长距离的依赖关系。顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力。故提出了用CNN来代替RNN的解决方法(平行化)。

长期依赖关系见笔记本 [classical concept.md](classical concept.md)
但是卷积神经网络只能感受到部分的感受野,需要多层叠加才能感受整个图像,而transformer注意力机制可以一层感受到全部序列,并提出了 Multi-Head Attention 实现和卷积网络多个输出识别不同模式的效果 ,故提出了自注意力机制
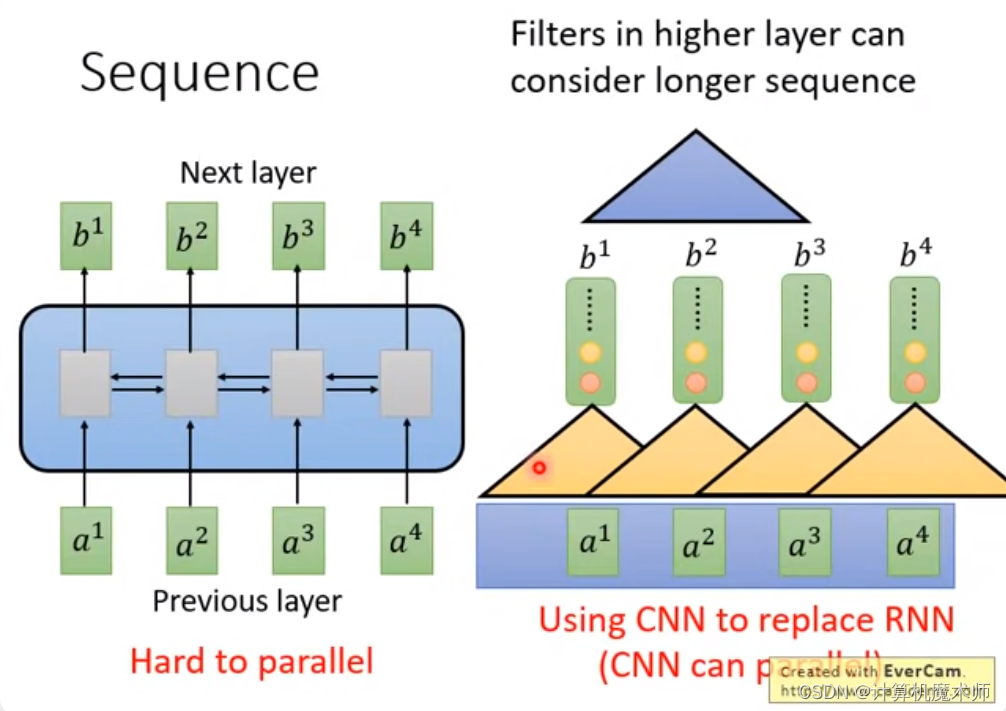
我们下面的内容依次按照模型的顺序讲解,首先讲解Positional Encoding,在讲解自注意力机制和多头注意力机制,再到全连接和跳跃连接
Positional Encoding
由于 Transformer 模型没有显式的顺序信息(没有循环神经网络的迭代操作),为了保留输入序列的位置信息&顺序关系,需要引入位置编码。位置编码是一种向输入嵌入中添加的特殊向量(不被训练的),用于表示单词或标记在序列中的位置。
相比起直接 concatenate ,直接相加似乎看起来会被糅合在输入中似乎位置信息会被擦除,我们可以假设concatenate 一个独热向量p_i , 代表其位置信息,
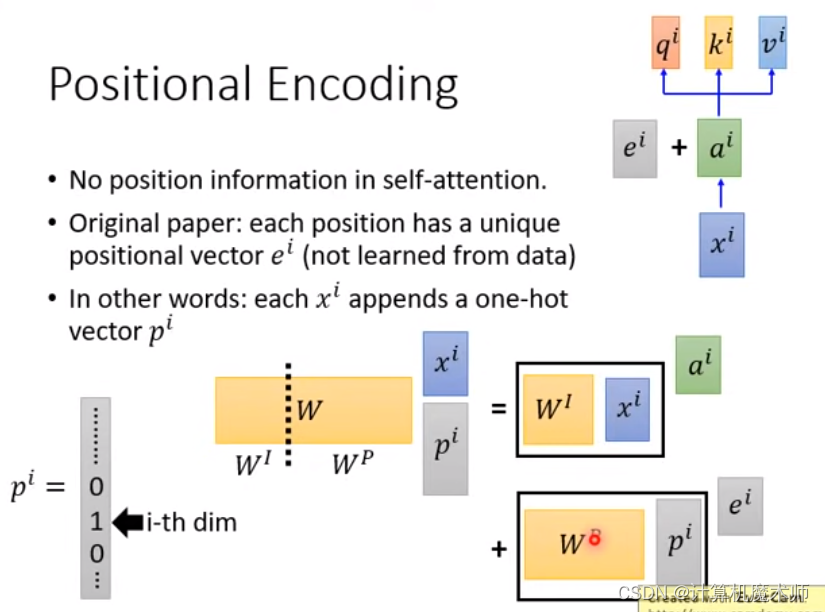
如图所示,最后也可以看为二者相加,但是此时的e^i 的权重W_P是可以被learn的 W^P^,根据研究表明这个W^P^ learn 有人做过了在convolution中seq to seq中类似的学习参数做法效果并不是很好,还有说其实会添加很多的不必要的参数学习等(issue地址:https://github.com/tensorflow/tensor2tensor/issues/1591,https://datascience.stackexchange.com/questions/55901/in-a-transformer-model-why-does-one-sum-positional-encoding-to-the-embedding-ra 不过我觉得实验才是真理,但似乎目前我还没有看到相关实验,如果有请在评论区留言!!),所以有一个人手设置的非常奇怪的式子产生确定W^P^ (其中W^P^ 绘图如图所示)
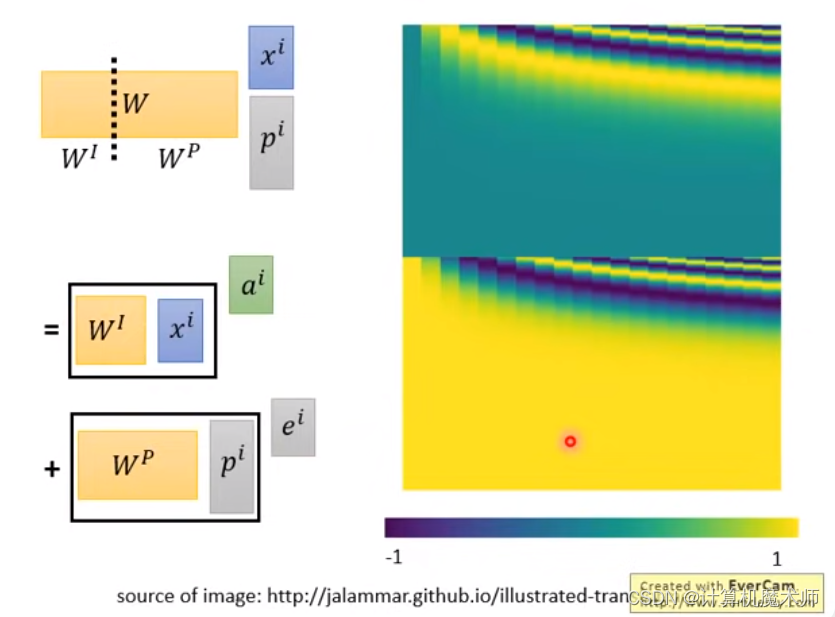
Transformer 模型一般以字为单位训练,论文中使用了 sin(罪) 和 cos 函数的线性变换来提供给模型位置信息.
理想情况下,信息编码(piece of information)的设计应该满足以下条件:
- 它应该为每个字(时间步)输出唯一的编码
- 不同长度的句子之间,任何两个字(时间步)之间的差值应该保持一致
- 我们的模型应该无需任何努力就能推广到更长的句子。它的值应该是有界的。
- 它必须是确定性的
在Transformer中,位置编码器的函数可以由以下公式表示:
其中, 表示输入序列中的位置, 表示位置编码中的维度索引, 表示Transformer模型的隐藏单元大小。
您可能想知道正弦和余弦的这种组合如何表示位置 / 顺序?其实很简单,假设你想用二进制格式来表示一个数字,会怎样可以发现不同位之间的变化,在每个数字上交替,第二低位在每两个数字上轮换,依此类推。但在浮点数世界中使用二进制值会浪费空间。因此,我们可以使用它们的浮点连续对应物 - 正弦函数。事实上,它们相当于交替位。
这个公式中的分数部分将位置 进行了缩放,并使用不同的频率( )来控制不同维度的变化速度。这样,不同位置和不同维度的位置编码会得到不同的数值,形成一个独特的向量表示,

正弦位置编码的另一个特点是它允许模型毫不费力地关注相对位置。以下是原论文的引用:
We chose this function because we hypothesized it would allow the model to easily learn to attend by relative positions, since for any fixed offset k, PEpos+k can be represented as a linear function of PEpos.
https://kazemnejad.com/blog/transformer_architecture_positional_encoding/ 这篇文章就很好的讲解了,这是因为其实这个添加的位置offset可以通过PEpos本身dot product 一个矩阵M得到对应offset后的结果PEpos+k(相当于线性变换,独立于时间变量t)

总结来看:位置编码器采用正弦和余弦函数的函数形式是为了满足一些重要特性,以便在Transformer模型中有效地表示位置信息。
- 周期性: 使用正弦和余弦函数能够使位置编码具有周期性。使得位置编码的值在每个维度上循环变化。这对于表示序列中的不同位置非常重要,因为不同位置之间可能存在重要的依赖关系。
- 连续性: 正弦和余弦函数在输入空间中是连续的。这意味着相邻位置之间的位置编码也是连续的,有助于保持输入序列中的顺序信息的连贯性。
- 维度关联: 位置编码中的维度与Transformer模型的隐藏单元大小相关联。这意味着不同维度的位置编码会以不同的频率变化,从而能够捕捉不同尺度的位置信息。较低维度的位置编码可以更好地表示较短距离的依赖关系,而较高维度的位置编码可以更好地表示较长距离的依赖关系。

🤞到这里,如果还有什么疑问🤞
🎩欢迎私信博主问题哦,博主会尽自己能力为你解答疑惑的!🎩
🥳如果对你有帮助,你的赞是对博主最大的支持!!🥳

- 点赞
- 收藏
- 关注作者
评论(0)