GDB调试

【摘要】 做代码开发难免会出现bug,进而需要调试,相比一些大神只推崇通过阅读代码来debug,又或者通过打印日志来debug,借助强大的GDB能够更快速的发现和定位问题。本文前面着重GDB常用功能的讲解,后半部分总结了开发中碰到的常见问题。
约定:对gdb的命令,如果有缩写形式,会在第一次出现的时候小括号内给出缩写,比如运行命令写成run(r);本文中尖括号< >用来表达一类实体,比如<program>表示这个地方可以放置程序;中括号[]表示括号中的内容是可写可不写,比如[=<value>],表示“=<value>”可以有也可以没有(<value>本身又是一类实体);“|”表示或的关系。
GDB简介
GDB是GNU开原组织旗下一款强大的代码调试工具,初始作者是大神Richard Stallman,GNU项目就是他发起的,《Linux下C++程序员学习资料指南》中提到的编辑器Emacs也是他的杰作。
编译的时候加上-g参数,编译器就会在目标文件中添加调试信息(关于编译链接可参阅《从四个问题透析Linux下C++编译&链接》),对应的strip命令可以去除调试信息。通过objdump/readelf等工具可以看到目标文件中有很多包含“debug”字符的section。这些section里保存了调试信息,目前ELF文件采用DWARF 3(Debug With Arbitrary Record Format)标准的调试信息格式。
使用GDB你可以:
1. 自定义程序运行方式
2. 让程序停止在你指定的位置:设置断点
3. 在停止点查看当前程序的状态:变量、寄存器的值
4. 动态改变程序的状态
通常GDB命令都会有一个简短的表达,比如设置断点的break命令可以简写为b,方便减少输入,本文中对第一次出现的命令都会在括号内给出对应的简短表达。回车在GDB相当于重复上一个命令。
启动GDB运行程序
运行GDB调试a.out程序有以下几种方式:
方式一:直接运行gdb,然后在gdb中执行“file a.out”加载程序。
方式二:gdb <program>,命令行给出可执行程序运行,即运行“gdb a.out”
方式三:gdb <program> <core_file>,带core文件运行,“gdb a.out /tmp/core-19475”(假设a.out运行产生了/tmp/core-1975的core dump文件)
方式四:gdb <program> <pid>,对运行中的a.out假设pid为19475,则可以通过“gdb a.out 19475”来调试运行中的a.out。
方式五:对运行中的a.out,可以先按方式二启动,然后在gdb中中心“attach 19475”调试运行中的a.out
进入到GDB后,可以通过help命令来获取帮助,GDB对命令做了分类,要获取详细说明可以查看help的相关输出。
启动GDB后, 就可以运行a.out了,本例比较简单直接执行run(r)命令即可,但对于稍微复杂点的程序可能需要做一些额外的设置工作:
1. 设置运行参数:通过“set args <arguments>”设置命令行需要的参数,比如程序需要一个输入文件/tmp/input.txt,则可以“set args /tmp/input.txt”。设置完成后可以通过“show args”命令查看当前设置的参数。
2. 设置运行环境:
通过“path <dir>”设置可执行文件搜索路径,“show paths”显示当前配置。
通过“set environment <var>[=value]”设置环境变量,比如要设置用户名可以“set environment USER=wanggaofei”,show environment可以查看所有的环境变量。
通过cd命令可以更改目录,pwd显示当前所在目录
准备就绪后就可以真正开始用GDB来调试程序了。
暂停、恢复程序运行
调试程序,首先是要让程序是某些感兴趣的点上停下来,GDB有以下几种方式通知GDB暂停程序的运行:断点、观察点、捕捉点(GDB中这三种都统称为断点breakpoints)、信号、线程停止。
断点
设置断点:break(b)命令
break:在下一条指令上设置断点,GDB是基于机器指令工作。
break <function>:在指定函数设置断点,function可以是class::function/function(type, type)形式
break <line_number>:在当前文件的指定行号设置断点
break <file_name>:<line_number>:在指定文件的指定行号设置断点
break <file_name>:<function>:在指定个文件的指定函数设置断点,主要针对重载函数
break +<offset>:在往后数offset行设置断点
break -<offset>:在往前数offset行设置断点
break *<address>:在指定的虚拟地址上设置断点
break <break_args> if <condition>:条件断点,break_args可以是上面break后面的参数,condition是具有布尔值的条件表达式,如break 20 if i == 5,在i等于5的时候20行触发断点
tbreak <break_args>:临时断点,功能同break,区别是断点在第一次停住以后,自动被删除
查看断点:
info breakpoints [n]:其中n是断点序号,是可选参数,不提供则显示所有断点
删除断点:delete(d)
delete [break_num_list] [range]:break_num_list是可选参数,可以是一个断点序号的列表,用空格分开,range可以是一个范围例如1-5,删除编号区间[1,5]的断点,如果不提供任何参数则删除所有的断点。
clear <break_args>:和break命令对应的反操作,根据位置清除断点,不指定参数则清除所有断点。
禁用断点:disable(dis)
有的时候你想临时让断点不起作用,又不想删除断点,否则过一会还要再设置这个断点,这时候可以暂时禁用断点。
disable [break_num_list] [range]:参数和delete的参数意义相同
启用断点:enable
当你想再次启用断点时可以enable它。
enable [break_num_list] [range]:参数意义同disable,enable有不少子命令,具体参考help enable
条件维护:condition
condition <break_num> <expression>:修改断点序号为break_num的条件为expression
condition <break_num>:清除断点break_num的条件
随着调试的进行,你可能需要修改停止条件,比如在for循环中,刚开始你会在循环变量等于N的时候停住程序,查看相关变量,发现没问题后,你会选取一个更大的M,让循环变量等于M的时候停住,看看有没有问题,这时候就需要更改条件,这就是condition大显身手的时候。
断点命令:commands
commands [break_num]
command_list
end
通常在断点处都是为了查看某些变量的值,如果能在断点处自动打印这些值,岂不爽歪歪?commands就是用来干这个的,省的你动手。如下示例
commands 1 slient printf “i is %d\n”, i end
在触发断点1时打印变量i的值,slient是让GDB安静的触发断点,不要打印一些没用的信息。
恢复执行:
continue [ignore_count]:continue(c)命令恢复程序运行直到下一个断点或者结束,参数ignore_count是个数字,代表忽略之后的断点次数。
step [count]:单步跟踪,碰到函数会进入,count参数相当于执行count次step的效果,对单步跟踪,有各选项step-mode可以通过set命令设置其为on或者off,设置为on后,对没有debug信息的函数会停止在函数的第一条指令上。否则step会跳过该函数。
next [count]:单步跟踪,跟step的区别是碰到函数时不会进入函数,count效果同step中参数。
finish:运行程序直到函数完成,打印返回的堆栈地址和返回值及参数信息。
util [break_args]:until(u)不带参数跳出循环,break_args同clear中参数。
stepi(si)、nexti(ni),这里的i代表指令级别,其他和step,next相同
观察点
观察点用来观察某个表达式的值是否发生了变化,如果有变化,则马上暂停程序。观察点和断点的一个显著区别是观察点由于是观察表达式的值,而表达式中变量是有作用域的,当离开作用域时观察点自动删除,但断点是和代码绑定,只要代码不变断点就一直存在。
设置观察点:
watch <expression>:为表达式expression设置一个观察点,一旦表达式值发生变化,马上停住程序。
rwatch <expression>:当表达式被读时,停住程序
awatch <expression>:当表达式被读或写时,停住程序
查看观察点:
info watchpoints:info breakpoints也可以把观察点列出,但这个命令会把所有breakpoints都列出来。
删除观察点:
通过delete命令
捕捉点
捕捉点用来捕捉程序运行中的一些事件,比如加载共享库或者异常
catch <event>:当event发生时,停住程序,具体event可以通过help catch查看各种事件类型。
tcatch <event>:只捕捉一次,程序停住后,捕捉点自动删除
信号
信号是unix/linux下的一项重要技术,GDB可以让你在收到指定信号时采取行动
处理信号:
handle <signals> [actions]:收到signals时采取行动actions,signals可以是一个信号范围,actions可以是:
stop:收到该信号时,GDB会停住程序
nostop:收到信号时,GDB不会停住程序,但是会打印消息告诉你收到该信号
print:收到信号时,打印一条消息
noprint:收到信号时,GDB不会高告诉你收到信号
pass/noignore:收到信号时,GDB不做处理,让程序的信号处理程序接手
nopass/ignore:收到信号时,GDB不会让程序看到整个信号
查询信号处理情况:
info signals
info handle
线程
info threads:显示所有线程
thread <thread_num>:切换到编号为thread_num的线程
break <break_args> thread <thread_num> [if <condition>]:线程断点和普通断点的区别就是多了个指定线程号的操作。
thead apply <thread_num_list>|all <command>:thread_num_list是线程列表,如果要对所有线程操作可以用all代替,command可以是之前的任何调试命令
set scheduler-locking off|on|step:默认是off,也就是调试的时候所有线程都会执行;on表示只有当前线程执行;step表示在step单步执行的话只有当前线程执行,只有在next跨过函数的时候其他线程可能运行
查看栈信息
程序停住后,你可以查看程序的当前状态,比如目前程序现在执行到哪了?是执行了哪条路径的代码?GDB通过几个命令帮助你分析栈信息,以及在栈间切换。
backtrace [n]:backtrace(bt)命令打印当前调用栈的信息,n为可选参数,既可以是整数也可以是负数,表示只打印栈顶上n层的栈信息或栈底n层信息。
frame [n]:frame(f)切换帧,n为一个从0开始的数,表示栈中的层次编号,0代表栈顶。
up [n]:向栈的上面移动n层
down [n]:向栈的下面移动n层
info frame:打印详细的栈信息,主要以程序的虚拟地址信息为主
info args:打印当前函数参数和对应值
info locals:打印当前函数局部变量和对应值
查看源代码
在查看栈信息的同时,你可能会对源代码感兴趣,以帮助你更好的理解程序的来龙去脉(如果你用的是Emacs编辑器,这种需求就会大大减少,因为Emacs和GDB配合的非常好),GDB提供了相应的命令来显示和查找源代码。
显示源码:
list [list_args]:list(l)显示源代码,list_args类似break中的break_args参数,可以是行号,函数等,详细参考help list。有一个参数listsize控制一次显示源代码的行数,可以通过show listsize显示该值,通过set listsize <count>来重新设置该值。
查找源码:
forward-search <regexp>:regexp是正则表达式,下同,关于正则表达式请参与相关资料。
search <regexp>:两个命令都是向前搜索
reverse-search <regexp>:向后搜索
指定源代码搜索路径:
directory <dirs>:对多个路径,可以用冒号“:”连接,directory不带参数时表示清除自定义的源码搜索路径。
show directories:显示当前源码搜索路径。
显示源代码虚拟地址:
info line [line_args]:显示源码虚拟地址,line_args和前面的list_args类似,详细参考help info line。
disassemble:反汇编代码,细节查看help disassemble
检查和设置变量
调试最终要查看程序运行的状态,通过观察当前各个变量或者表达式的值来判断程序当前是否符合预期,如果不符合预期,及时分析原因,从而排查bug。GDB提供了相关命令查看和设置变量。
查看变量类型:
ptype type_name|expression:type_name可以是一个类型名,比如结构体或者类名,expression可以是某个变量
whatis expression:可以理解为精简版ptype,ptype会展开所有类型定义,whatis则不会
打印表达式:
print [/<format>] <expression>:print(p)打印命令有两部分,可选的/<format>表示输出格式,expression是要打印的表达式。在GDB中当前可见的变量(全局变量、全局静态变量、当前作用域的局部变量)可以随时打印。format详细说明如下。
打印数组:
print *pArr@10:pArr是指向数组的指针,10表示要打印的元素的个数
通过“::”打印文件、函数或者C++类的变量:
print main::value
打印内存:
x [/<n/f/u>] <addr>:x命令第二部分是可选的,可以分成三块,n是要打印内存的数目,f是打印格式,详见print部分的format说明,u表示每个对象占用的字节数,默认是4字节,其他值包括b表示单字节,h表示双字节,w表示四字节,g表示八字节。
x /10dw pArr:表示从内存地址pArr开始打印10个元素,每个元素占用4字节(w控制),以十进制显示(d控制)
自动打印:
要是在每次程序停住的时候,能自动帮你打印变量的值,可以大大减少手工输入,display就可以做到。
display [/format] <expression>:参数意义同print
undisplay <display_num>:删除自动显示,display_num类似断点的编号。
delete display <display_num_list>:display_num_list是空格分开的display_num列表
disable display <display_num>:和断点类似
enable display <display_num>:和断点类似
历史记录:
用GDB的print命令查看状态时,GDB会以$1,$2这样的编号标记之前的表达式,这些编号称为值历史。对于那种很长的表达式,通过值历史查看可以省去很多输入
设置变量:
调试的过程中,可能需要人为的设置变量的值,从而可以快速的了解,当变量是这个值的时候,程序是什么表现,通过set命令可以很简单的实现。
set value=11:设置变量value的值为11
方便变量:
有时候想挨个打印数组的值,如果GDB能提供一个变量作为数组的下标,随着循环的进行变量值也随着变化,这样查看数组元素的值就非常方便了。
(gdb) set $i = 0 (gdb) p arr[$i++]
$i就是方便变量,后面通过回车就可以不断打印arr中的值。
查看寄存器:
有时候可能会关心寄存器中的值,比如在core dump后,想查看下当时现场。
info registers [register_name]:查看寄存器,如果给出具体的register_name则只显示指定寄存器的值
info all-registers:比上面显示更多的寄存器值,比如浮点寄存器
改变程序的运行
在用GDB不断调试的过程中,你慢慢已经掌握了程序的执行脉络,这时候你肯定希望按照自己的调试策略来改变程序的路径,有了这个能力,在调试中对程序就可以为所欲为,一次走完程序的所有路径。
修改变量:
上节在设置变量中提到可以通过set命令来设置变量的值,但当你代码中的变量和GDB中的参数名字一样时,需要如下设置。
(gdb) set var width=80
另外通过print命令也可以方便的设置变量
(gdb) print value=11
跳转执行:
jump <location>:location可以是行号或者地址(*address,同break中参数)
产生信号:
在前面信号一节中只提到了处理信号,我们也可以在GDB中随时产生一个信号。
signal <signal>:给程序产生一个信号signal和handle命令中参数意义相同
强制函数返回:
return [<expression>]:强制函数返回,如果提供了expression则会当做返回值。
强制调用函数:
call <expression>:调用函数,expression为函数名及其参数
开发常见问题
调试是一种事后补救措施,最好是尽可能避免调试,或者尽可能将调试的工作压缩在开发阶段,在线上出问题和调试,那种酸爽只有经历过的人才知道。因此开发阶段务必加强对测试的重视,代码都需要单元测试来覆盖,各个模块集成测试,线上的性能和稳定性压测等都必不可少。
下面我们针对开发过程中常见的问题做一个梳理:
问题一:编译问题
在写一个稍微大一点的cpp时,由于括号没有匹配导致很奇怪的报错,这个时候可以采用二分法来注释代码,从而快速定位问题发生的区域。这给我们一个启示,在写代码的时候注意保持良好的输入习惯:在输入括号的时候先把左右括号都输完整,再在中间填代码;在写一个新函数的时候首先把return语句写上;在写if语句的时候最好else语句也先填上,后面如果用卫语句的话,直接删掉else就好了,这样不会漏掉逻辑;调用函数的时候也立刻写代码假设函数返回出错的处理。
问题二:段错误
写C、C++代码最常见的问题是对内存的不当处理,最常见的莫过于段错误,典型的如访问不存在的内存地址、访问了不允许访问的地址(试图往只读的位置写数据)。常见产生的原因:1. 访问空指针;2. 内存越界访问;3. 栈溢出;4. 地址保护。
空指针:我们先来看一下64位Linux下运行时虚拟地址的分布情况如图,可以看到有效的虚拟地址是从0X400000开始的,对任何低于该地址的虚拟地址都是非法的,因此访问空指针(地址为0X0)会引发段错误,另外在调试过程中有一些地址虽然不是0地址,比如查看某个对象的成员,但实际上this指针已经是0地址,但由于访问成员的时候加上了地址偏移,这种地址和0地址没什么区别。
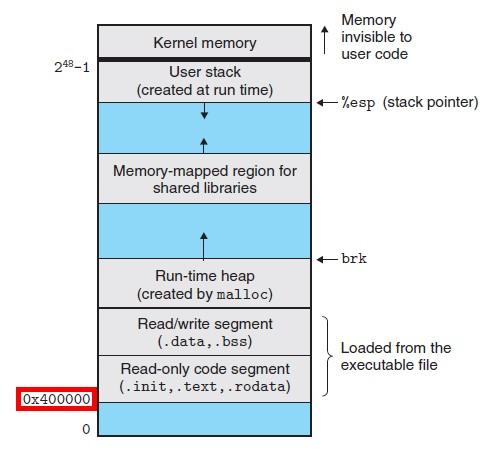
内存越界:并非所有的越界访问都会导致段错误,因为Linux系统分配内存都以页(一个页通常是4K大小)的方式进行,当你有内存越界时,虽然超出了你代码预期的内存空间,但如果还在当前页面内,你访问的内存空间还是一个有效的空间,并不会引发段错误。对这类问题最好在单元测试中用4.8.5以上的gcc打开地址消毒,或者用valgrind进行检测。
栈溢出:当在栈上分配很大的数组时很容易导致栈溢出,对于较大内存的使用最好是通过动态内存分配来获取。
地址保护:在mmap做内存映射时,如果尝试往只读的映射区写入数据会导致段错误。
问题三:总线错误
在开发中出发总线错误的两个常见场景:1. 内存地址不满足对齐要求,比如Intel的intrinsic接口中很多对地址有对齐要求,如果不满足对齐要求就会报总线错误;2. 在mmap时,映射了一个文件,但其他进程将底层的文件截短,当访问到这部分截掉的内容时,会发生总线错误。
问题四:全局符号介入
在《从四个问题透析Linux下C++编译&链接》中提到全局符号介入,这种问题通常会引起core dump,要定位相关问题需要对代码执行路径有一定了解,通过GDB反馈的当前帧符号来源来定位符号是否来自非预期的库中。对于某些飘忽不定的core dump,还要看是不是由于当前这次发布引入了错误版本的动态库?由于接口的变化导致类似全局符号介入的效果。
问题五:无源码调试
在没有源代码的时候strace就可以发挥神威了,strace会记录程序所产生的每次系统调用,系统调用的名字,参数,返回值会在同一行显示,通过观察返回值的异常对于快速定位问题非常有帮助。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)