浅入浅出 JVM 特性

先赞后看,Java进阶一大半
JDK 的版本目前已经规划到了 Java SE 25,将于 2025 年 9 月发布~

各位hao,我是南哥,相信对你通关面试、拿下Offer有所帮助。
⭐⭐⭐一份南哥编写的《Java学习/进阶/面试指南》:https://github/JavaSouth
1. JVM内存布局
1.1 堆内存
我们Java程序员相对C语言老哥来说,南友们不需要写内存管理这些东西。具体什么东西呢?不需要为每个对象去写繁琐的释放内存代码。
以下是一个C语言示例,C语言需要显式地使用free函数来释放内存。
#include <stdio.h>
#include <stdlib.h>
int main() {
// 分配内存以存储一个整数
int *ptr = malloc(sizeof(int));
if (ptr == NULL) {
printf("内存分配失败\n");
return 1;
}
// 使用分配的内存
*ptr = 123;
printf("存储的整数是: %d\n", *ptr);
// 完成使用后释放内存
free(ptr);
return 0;
}
我们把重要的内存管理最高权力交给了JVM虚拟机,总得多多了解JVM虚拟机是如何处理内存管理的、包括JVM内存区域包含了什么,否则线上出了什么故障,不了解原理连解决的思路都没有。
JVM内存布局包含了五部分,分别是堆内存、本地方法栈、虚拟机栈、方法区、程序计数器。南哥画画图,给你加深理解。

堆内存的作用很方便记忆,它的唯一目的就是存放对象实例。成员变量的变量值无论是基本类型、还是引用类型都存储在堆内存中,而局部变量的变量值如果是引用类型则存储在堆内存中。这点下文南哥会继续讲到。
public class JavaSouth {
// 成员变量:无论是基本类型、还是引用类型都存储在堆内存中
private int memberInt = 10;
// 成员变量:无论是基本类型、还是引用类型都存储在堆内存中
private String memberString = "Hello, World!";
public void displayInfo() {
// 局部变量:如果是引用类型则存储在堆内存中
String localString = new String("Local String");
System.out.println("Member int: " + memberInt);
System.out.println("Member String: " + memberString);
System.out.println("Local String: " + localString);
}
}
JVM的堆内存,在国内也被称为GC堆。说到GC回收,目前主流垃圾回收器都使用了分代收集算法,GC堆被分为了新生代、老年代。
新生代、老年代又使用了不同的垃圾回收算法,如新生代的对象特点就是存活时间短,更适合把内存一分为二的复制算法;而老年代的对象存活时间就相对较长了,各种大对象、小对象也比较复杂,可以使用标记清除算法、标记整理算法。这些南哥在JVM垃圾回收章节有提到过。
1.2 虚拟机栈
虚拟机栈是和Java中的方法相关的,因为每个方法在被一个线程执行时,都会去创建一个栈帧,因此虚拟机栈的生命周期也和线程相同,虚拟机栈也属于线程私有。
虚拟机栈的栈帧包含了这么些东西:局部变量表、操作数栈、动态链接、方法返回地址。难记吧?南哥是这么觉得。
在Oracle官方文档中,我们可以了解到虚拟机栈一共会报出StackOverflowError、OutOfMemoryError两个异常。
- If the computation in a thread requires a larger Java Virtual Machine stack than is permitted, the Java Virtual Machine throws a
StackOverflowError.- If Java Virtual Machine stacks can be dynamically expanded, and expansion is attempted but insufficient memory can be made available to effect the expansion, or if insufficient memory can be made available to create the initial Java Virtual Machine stack for a new thread, the Java Virtual Machine throws an
OutOfMemoryError.
翻译过来。
- 如果线程中的计算需要比允许值更大的 Java 虚拟机堆栈,则 Java 虚拟机将抛出
StackOverflowError,也就是堆栈溢出。 - 如果 Java 虚拟机堆栈可以动态扩展,并且尝试扩展但没有足够的内存来实现扩展,或者没有足够的内存来为新线程创建新的初始 Java 虚拟机堆栈,则 Java 虚拟机将抛出
OutOfMemoryError,也就是内存溢出。
1.3 本地方法栈
本地方法栈和虚拟机栈的作用相差不大,都是为方法的运行提供一个栈帧。众所周知Java很多关于数学计算、系统调用等操作,都利用了C语言的本地方法,这些本地方法也叫Native方法。
南哥给一段由C语言实现的Native方法代码。
下面是String类的intern方法,该方法使用的便是本地方法。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/**
* 返回字符串对象的规范表示。
*/
public native String intern();
}
1.4 方法区
上文跟着南哥我们知道虚拟机栈、本地方法栈提供栈帧,而堆内存提供内存区域。其实方法区也起到提供一个内存区域的作用,方法区存放了类相关的数据:类结构信息、常量、静态变量等。
在Oracle官方文档中,我们可以知道方法区会出现OutOfMemoryError异常。
If memory in the method area cannot be made available to satisfy an allocation request, the Java Virtual Machine throws an
OutOfMemoryError.
如果方法区中的内存不足以满足分配请求,则 Java 虚拟机将抛出OutOfMemoryError。
1.5 程序计数器
程序计数器的主要作用是存储指向当前线程正在执行的JVM指令的地址。
而程序计数器在整个JVM内存布局中,是唯一一个不会出现OutOfMemoryError的区域。
1.6 变量存储位置
南哥在上文有提到堆内存、方法区具体存放了什么内容,现在我们整理整理Java各种变量的变量名、变量值所存储的位置。
这一点,面试官考得细的话会考到。
- 成员变量
- 变量名作为类的一部分,其结构定义存储在方法区。
- 而变量值无论是基本数据类型还是引用类型,都是存储在堆内存中的对象实例内。
- 类变量
- 变量名作为类的一部分,其结构定义也存储在方法区。
- 变量值无论是基本数据类型还是引用类型,都存储在方法区中,因为它们属于类级别的数据。
- 局部变量
- 局部变量是存在于方法中的变量,变量名存储在虚拟机栈的栈帧中。
- 而变量值如果是基本数据类型,存储在虚拟机栈的栈帧中;如果是引用类型,变量值存储在栈中,但引用所指向的对象本身存储在堆内存中。
2. 垃圾回收器
2.1 引用计数法
面试官:JVM为什么不采用引用计数法?
每个Java对象在引用计数法里都有一个引用计数器,引用失效则计数器 - 1,有新的引用则计数器 + 1,通过计数器的数值来判断该对象是否是可回收对象。
大家看下这个例子,如果对象A和对象B没有被任何对象引用,也没有被任何线程访问,这两个对象按理应该被回收。但如果对象A的成员变量引用了对象B,对象B的成员变量引用了对象A,它们的引用计数器数值都不为0,通过引用计数法并不能将其视为垃圾对象。
class A {
B b = new B();
}
class B {
A a = new A();
}
就因为引用计数法很难解决对象之间相互循环引用的问题,所以目前JVM采用可达性分析算法来判断Java对象是否是可回收对象。
2.2 可达性分析算法
面试官:那你讲讲可达性分析算法?
可达性分析顾名思义就是以某个起始点来判断它是否可达,这个起始点称为GC Roots。如果Java对象不能从GC Roots作为起始点往下搜索到,那该对象就被视为垃圾对象,即可回收对象。
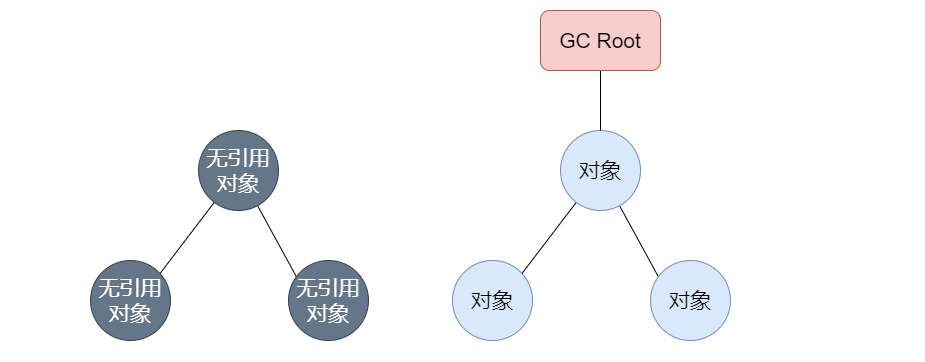
可以作为GC Roots对象一共包括以下四种,这点也是面试官常问的:
- 虚拟机栈中引用的对象。
- 本地方法栈中引用的对象。
- 方法区中类静态属性引用的对象。
- 方法区中常量引用的对象。
2.3 垃圾回收区域
面试官:垃圾回收器回收的是哪个区域?
JVM由五大区域组成:堆内存、方法区、程序计数器、虚拟机栈、本地方法栈。先说结论,垃圾回收器回收的是堆内存和方法区两大区域。
程序计数器、虚拟机栈、本地方法栈的内存分配和回收都具备确定性,都是随着线程销毁而销毁,因此不需要进行回收。
但在堆内存、方法区中,内存分配和回收都是动态的,我们只有在运行期间才能知道会创建哪些对象;另外这些垃圾对象不会自动销毁,如果任由这两部分区域的垃圾对象不管,势必造成内存的浪费甚至有内存泄漏的可能。
垃圾回收器存在的意义就是通过自动检测和回收这些垃圾对象,来减少内存泄漏的风险。
2.4 回收永久代
面试官:那永久代不会进行垃圾回收对吧?
虽然永久代的垃圾回收效率是比较低的,但永久代里的废弃常量和无用的类仍然会被回收。
例如创建一个字符串常量name,该字符串会存在于常量池中。如果该字符串没有任何String对象去引用它,当发生内存回收时有必要会清除该废弃常量。
private static final String name = "JavaGetOffer";
2.5 垃圾回收器
面试官:你说说都有哪些垃圾回收器?
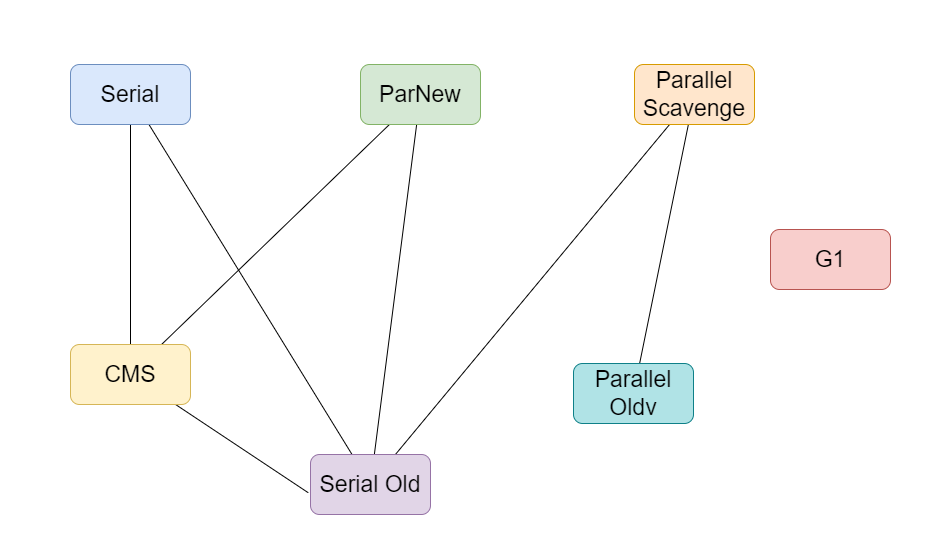
目前市面上共有七种垃圾回收器。
-
Serial是一个作用在新生代的单线程垃圾回收器。在垃圾回收期间系统的所有线程都会阻塞,因此垃圾回收效率也相对较高。
-
ParNew则是Serial的多线程版本。这也是第一款并发的垃圾回收器,相比Serial来说垃圾回收不需要阻塞所有线程,第一次实现了让垃圾回收线程和用户线程同时工作。
-
Serial Old是Serial的老年代版本。
-
Parallel Scavenge同样是作用在新生代且是多线程,不过它的设计目标是达到一个可控制的吞吐量。
-
Parallel Old是Parallel Scavenge收集器的老年代版本,我们可以把它和Parallel Scavenge搭配一起使用。
-
CMS是一种以最短停顿时间为目标的多线程收集器,下文我会介绍CMS实现最短停顿的原理。
-
G1收集器可以说是CMS的升级版。
我们可以根据业务实际情况来为各个年代搭配不同的垃圾回收器,以下的垃圾回收器如果有线连接,说明它们之间可以搭配使用。
2.6 CMS原理
面试官:你说的CMS为什么有较短的停顿?
CMS采用了标记-清除算法,整个运作过程分为了初始标记、并发标记、重新标记、并发清除四个阶段。
其中初始标记、重新标记的停顿时间是比较短的,而耗时最长的并发标记、并发清除能够和用户线程一起并发工作不需要停顿,可以说CMS只需要造成初始标记、重新标记带来的短时间停顿。
2.7 CMS的缺点
面试官:那它有什么缺点?
- CMS是多线程的,在垃圾回收时会占用一部分线程,可能会使系统变得相对较慢。
- CMS并发清理时用户线程还在运行着,也就是说还会有新的垃圾不断产生,这些垃圾被称为浮动垃圾。因为浮动垃圾产生在标记阶段后,很明显CMS本次收集是无法处理这些浮动垃圾的,只能等到下一次GC回收。
- CMS采用标记-清除算法,标记-清除算法的缺点是会产生空间碎片,有可能造成大对象找不到足够的连续空间而发生OOM的情况。
2.8 G1垃圾回收器
面试官:你说G1是CMS的升级版,为什么?
G1垃圾回收器设计之初被赋予的使命是未来可以替换掉JDK1.5中发布的CMS垃圾回收器。所以大家可想而知,CMS垃圾回收器的优点G1垃圾回收器都有,另外G1垃圾回收器也避免了CMS的一些不足。
- G1采用的垃圾回收算法是标记-整理算法,避免了CMS采用标记-清除可能产生的空间碎片。
- 其他收集器在新生代、老年代分别采用不同收集器进行配合,而G1垃圾回收器可以不需要其他收集器配合就能独立管理整个GC。
2.9 垃圾回收算法
面试官:垃圾回收算法都有什么?
垃圾回收算法一共有四种,其中最基础的垃圾回收算法是标记-清除算法,其他算法其实都是对标记-清除算法的优化而产生的,我们继续往下看。
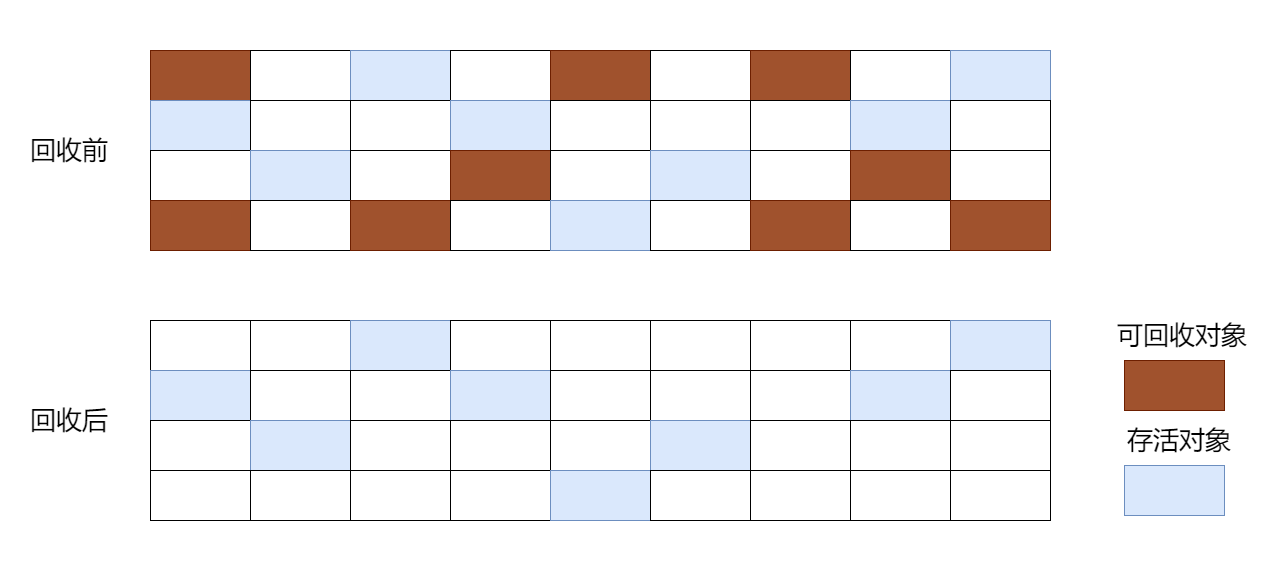
(1)标记-清除算法。
标记-清除算法顾名思义分为标记和清除两个阶段,首先标记出所有可回收的对象,标记完成后统一进行清除。但该算法有一个缺点,被标记和未标记的对象都是分散存储在内存中的,当清除标记对象后会出现空间碎片的情况,如下图:
(2)复制算法。
复制算法把内存划分为容量相等的两块,每次只使用一块,当这一块内存不足时就将存活的对象复制到另一块中,同时清除当前块的内存空间。这种算法实现简单且运行高效,也不会产生空间碎片的情况,因为新生代的GC是比较频繁的,所以复制算法也广泛用于新生代的垃圾回收。但缺点很明显是浪费了50%的内存空间。
(3)标记-整理算法。
标记-整理算法是对标记-清除算法的优化。该算法在内存到达一定量后,会把所有已标记的垃圾对象都向一端里移动,然后以存活对象所在的一端为边界,清除边界内所有内存,避免了标记-清除算法可能产生的空间碎片。
(4)分代收集算法。
一般实际业务系统都是采用分代收集算法。分代顾名思义把JVM内存拆分,分为了新生代、老年代,对不同年代的垃圾回收采用不同的垃圾回收算法来确保回收效率。
大家可以看下自己公司的JDK使用了什么垃圾回收器,加深下对本篇的理解。
# 打印JVM启动时的命令行标志
java -XX:+PrintCommandLineFlags -version
2.91 优化复制算法
面试官:复制算法可以怎么优化吗?
复制算法把内存划分为容量相等的两块,也就是按1:1分配内存,但这也浪费了50%空间。
可以把内存分为一块较大的Eden空间和两块较小的Survivor空间,每次只使用Eden空间和其中一块Survivor空间,而另一块Survivor空间用来保存回收时还存活的对象。这样就只浪费了其中一块Survivor空间的内存。
我是南哥,南就南在Get到你的点赞点赞点赞。

看了就赞,Java进阶一大半。点赞 | 收藏 | 关注,各位的支持就是我创作的最大动力❤️

- 点赞
- 收藏
- 关注作者
评论(0)